
此页面指的是属于衡量指标的
type参数。
type还可以用作维度、过滤条件和参数类型文档页面中所述的维度或过滤条件的一部分。
type还可以用作维度组的一部分,如dimension_group参数文档页面中所述。
用法
view: view_name {
measure: field_name {
type: measure_field_type
}
}
|
层次结构
type |
可能的字段类型
测量
接受
一种衡量类型
|
本页面详细介绍了可分配给指标的各种类型。一个指标只能有一种类型,如果未指定类型,则默认为 string。
某些衡量类型具有支持参数,这些参数将在相应部分中进行说明。
度量类型类别
每种衡量类型都属于以下类别之一。这些类别决定了度量类型是否执行聚合、度量类型可以引用的字段类型,以及您是否可以使用 filters 参数过滤度量类型:
- 汇总度量:汇总度量类型会执行聚合,例如
sum和average。汇总度量只能引用维度,而不能引用其他度量。这是唯一可与filters参数搭配使用的指标类型。 - 非汇总型衡量指标:顾名思义,非汇总型衡量指标是指不执行汇总的衡量指标类型,例如
number和yesno。这些衡量类型会执行基本转换,并且由于它们不执行汇总,因此只能引用汇总衡量或之前汇总的维度。您无法将filters参数与这些衡量类型搭配使用。 - Post-SQL 度量:Post-SQL 度量是一种特殊的度量类型,可在 Looker 生成查询 SQL 后执行特定计算。它们只能引用数值指标或数值维度。您无法将
filters参数与这些衡量类型搭配使用。
类型定义列表
| 类型 | 类别 | 说明 |
|---|---|---|
average |
汇总 | 生成列中值的平均值 |
average_distinct |
汇总 | 在使用非规范化数据时,正确生成值的平均值(平均数)。如需查看完整说明,请参阅 average_distinct 部分。 |
count |
汇总 | 生成行数 |
count_distinct |
汇总 | 生成列中唯一值的数量 |
date |
非汇总 | 对于包含日期的指标 |
list |
汇总 | 生成列中唯一值的列表 |
max |
汇总 | 生成列中的最大值 |
median |
汇总 | 生成列中值的中间值(中点值) |
median_distinct |
汇总 | 当联接导致扇出时,正确生成值的中间值(中点值)。如需查看完整说明,请参阅 median_distinct 部分。 |
min |
汇总 | 生成列中的最小值 |
number |
非汇总 | 对于包含数字的指标 |
percent_of_previous |
Post-SQL | 生成所显示行之间的百分比差异 |
percent_of_total |
Post-SQL | 生成每个显示行的总百分比 |
percentile |
汇总 | 生成列中指定百分位处的值 |
percentile_distinct |
汇总 | 当联接导致扇出时,正确生成指定百分位的值。如需查看完整说明,请参阅 percentile_distinct 部分。 |
running_total |
Post-SQL | 为每个显示的行生成累计总数 |
period_over_period |
汇总 | 引用了较早时间段的汇总 |
string |
非汇总 | 对于包含字母或特殊字符的衡量指标(例如 MySQL 的 GROUP_CONCAT 函数) |
sum |
汇总 | 生成列中值的总和 |
sum_distinct |
汇总 | 在使用非规范化数据时,正确生成值总和。如需查看完整说明,请参阅 sum_distinct 部分。 |
yesno |
非汇总 | 对于将显示 true 或 false 的字段 |
int |
非汇总 |
移除了 5.4
已替换为 type: number |
average
type: average 用于计算指定字段中值的平均值。它类似于 SQL 的 AVG 函数。不过,与原始 SQL 不同的是,即使查询的联接包含扇出,Looker 也会正确计算平均值。
type: average 度量的 sql 参数可以采用任何有效的 SQL 表达式,该表达式会生成数值表列、LookML 维度或 LookML 维度的组合。
可以使用 value_format 或 value_format_name 参数设置 type: average 字段的格式。
例如,以下 LookML 通过对 sales_price 维度求平均值来创建名为 avg_order 的字段,然后以货币格式(1,234.56 美元)显示该字段:
measure: avg_order {
type: average
sql: ${sales_price} ;;
value_format_name: usd
}
average_distinct
type: average_distinct 适用于非规范化数据集。它会根据 sql_distinct_key 参数定义的唯一值,计算指定字段中非重复值的平均值。
这是一个高级概念,通过示例可以更清楚地说明。假设有一个如下所示的反规范化表:
| 订单项 ID | 订单 ID | 订单配送 |
|---|---|---|
| 1 | 1 | 10.00 |
| 2 | 1 | 10.00 |
| 3 | 2 | 20.00 |
| 4 | 2 | 20.00 |
| 5 | 2 | 20.00 |
在这种情况下,您可以看到每个订单都有多行。因此,如果您为 order_shipping 列添加一个基本的 type: average 度量,您会得到 16.00 的值,即使实际平均值为 15.00 也是如此。
# Will NOT calculate the correct average
measure: avg_shipping {
type: average
sql: ${order_shipping} ;;
}
为了获得准确的结果,您可以使用 sql_distinct_key 参数为 Looker 定义应如何识别每个唯一实体(在本例中为每个唯一订单)。此代码将计算出正确的 15.00 金额:
# Will calculate the correct average
measure: avg_shipping {
type: average_distinct
sql_distinct_key: ${order_id} ;;
sql: ${order_shipping} ;;
}
sql_distinct_key 的每个唯一值在 sql 中都必须只有一个对应的值。换句话说,上述示例之所以有效,是因为 order_id 为 1 的每行的 order_shipping 均为 10.00,而 order_id 为 2 的每行的 order_shipping 均为 20.00。
可以使用 value_format 或 value_format_name 参数设置 type: average_distinct 字段的格式。
count
type: count 执行表计数,类似于 SQL 的 COUNT 函数。不过,与原始 SQL 不同的是,即使查询的联接包含扇出,Looker 也会正确计算数量。
type: count 指标会根据表的主键执行表计数,因此 type: count 指标不支持 sql 参数。
如果您想对表的主键以外的字段执行表计数,请使用 type: count_distinct 度量。或者,如果您不想使用 count_distinct,可以使用 type: number 指标(如需了解详情,请参阅社区帖子如何统计非主键)。
例如,以下 LookML 会创建一个字段 number_of_products:
view: products {
measure: number_of_products {
type: count
drill_fields: [product_details*] # optional
}
}
定义 type: count 度量时,通常会提供 drill_fields(针对字段)参数,以便用户在点击该度量时,能够看到构成相应计数的各个记录。
如果您在探索中使用
type: count的度量,可视化图表会使用视图名称而非“数量”一词来标记结果值。为避免混淆,我们建议您将视图名称改为复数形式,在图表设置的序列下选择显示完整字段名称,或使用包含视图名称复数形式的view_label。
您可以使用 filters 参数为 type: count 的衡量指标添加过滤条件。
count_distinct
type: count_distinct 用于计算给定字段中不同值的数量,它使用 SQL 的 COUNT DISTINCT 函数。
type: count_distinct 度量的 sql 参数可以采用任何有效的 SQL 表达式,该表达式会生成一个表列、LookML 维度或 LookML 维度的组合。
例如,以下 LookML 会创建一个用于统计唯一客户 ID 数量的字段 number_of_unique_customers:
measure: number_of_unique_customers {
type: count_distinct
sql: ${customer_id} ;;
}
您可以使用 filters 参数为 type: count_distinct 的衡量指标添加过滤条件。
date
type: date 与包含日期的字段搭配使用。
type: date 指标的 sql 参数可以采用任何可生成日期的有效 SQL 表达式。实际上,这种类型很少使用,因为大多数 SQL 聚合函数不会返回日期。一个常见的例外情况是日期维度的 MIN 或 MAX。
使用 type: date 创建最大日期度量或最小日期度量
如果您想创建最大日期或最小日期指标,最初可能会认为使用 type: max 或 type: min 指标即可。不过,这些衡量类型仅与数值字段兼容。您可以改为定义 type: date 的度量,并将 sql 参数中引用的日期字段封装在 MIN() 或 MAX() 函数中,从而捕获最晚日期或最早日期。
假设您有一个值为 type: time 的维度组,名为 updated:
dimension_group: updated {
type: time
timeframes: [time, date, week, month, raw]
sql: ${TABLE}.updated_at ;;
}
您可以创建 type: date 的度量,以捕获相应维度组的最大日期,如下所示:
measure: last_updated_date {
type: date
sql: MAX(${updated_raw}) ;;
convert_tz: no
}
在此示例中,我们没有使用 type: max 指标来创建 last_updated_date 指标,而是在 sql 参数中应用了 MAX() 函数。last_updated_date 指标的 convert_tz 参数也设置为 no,以防止在指标中进行双重时区转换,因为时区转换已在维度组 updated 的定义中进行。如需了解详情,请参阅有关 convert_tz 参数的文档。
在 last_updated_date 度量的 LookML 示例中,type: date 可以省略,并且该值将被视为字符串,因为 string 是 type 的默认值。不过,如果您使用 type: date,则可以为用户提供更出色的过滤功能。
您可能还会注意到,last_updated_date 度量定义引用的是 ${updated_raw} 时段,而不是 ${updated_date} 时段。由于 ${updated_date} 返回的值是字符串,因此必须使用 ${updated_raw} 来引用实际的日期值。
您还可以将 datatype 参数与 type: date 搭配使用,通过指定数据库表使用的日期数据类型来提升查询性能。
为日期时间列创建最大值或最小值度量
计算 type: datetime 列的最大值略有不同。在这种情况下,您需要创建一个不声明类型的度量,如下所示:
measure: last_updated_datetime {
sql: MAX(${TABLE}.datetime_string_field) ;;
}
list
type: list 可创建给定字段中不同值的列表。它类似于 MySQL 的 GROUP_CONCAT 函数。
您无需为 type: list 指标添加 sql 参数。不过,您可以使用 list_field 参数指定要从中创建名单的维度。
用法如下:
view: view_name {
measure: field_name {
type: list
list_field: my_field_name
}
}
例如,以下 LookML 会基于 name 维度创建度量 name_list:
measure: name_list {
type: list
list_field: name
}
请注意以下有关 list 的事项:
list指标类型不支持过滤。您无法在type: list度量上使用filters参数。- 无法使用替换运算符 ($) 引用
list度量类型。您无法使用${}语法来引用type: list度量。
list 支持的数据库方言
为了让 Looker 在您的 Looker 项目中支持 type: list,您的数据库方言也必须支持它。下表显示了 Looker 最新版本中哪些方言支持 type: list:
| 方言 | 是否支持? |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13+ | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |
max
type: max 用于查找指定字段中的最大值。它使用 SQL 的 MAX 函数。
对于 type: max 的度量,sql 参数可以采用任何有效的 SQL 表达式,该表达式会生成数值表列、LookML 维度或 LookML 维度的组合。
由于 type: max 的衡量指标仅与数字字段兼容,因此您无法使用 type: max 的衡量指标来查找最晚日期。不过,您可以在 type: date 度量的 sql 参数中使用 MAX() 函数来捕获最晚日期,如之前在 date 部分的示例中所示。
可以使用 value_format 或 value_format_name 参数设置 type: max 字段的格式。
例如,以下 LookML 通过查看 sales_price 维度创建了一个名为 largest_order 的字段,然后以货币格式(1,234.56 美元)显示该字段:
measure: largest_order {
type: max
sql: ${sales_price} ;;
value_format_name: usd
}
您无法将 type: max 度量用于字符串或日期,但可以手动添加 MAX 函数来创建此类字段,如下所示:
measure: latest_name_in_alphabet {
type: string
sql: MAX(${name}) ;;
}
median
type: median 返回指定字段中各值的中间值。当数据中存在一些非常大或非常小的离群值,这些值会使数据的基本平均值(平均数)出现偏差时,此方法尤其有用。
假设有一个如下所示的表格:
| 订单项 ID | 费用 | 中点? |
|---|---|---|
| 2 | 10.00 | |
| 4 | 10.00 | |
| 3 | 20.00 | 中间点值 |
| 1 | 80.00 | |
| 5 | 90.00 |
该表按费用排序,但这不会影响结果。虽然 average 类型会返回 42(将所有值相加并除以 5),但 median 类型会返回中点值:20.00。
如果值的数量为偶数,则中位数值的计算方法是取最接近中点的两个值的平均值。假设有一个包含偶数行的表格,如下所示:
| 订单项 ID | 费用 | 中点? |
|---|---|---|
| 2 | 10 | |
| 3 | 20 | 中点前最接近的 |
| 1 | 80 | 中点后的最近位置 |
| 4 | 90 |
中位数(中间值)为 (20 + 80)/2 = 50。
中位数也等于第 50 百分位的值。
type: median 度量的 sql 参数可以采用任何有效的 SQL 表达式,该表达式会生成数值表列、LookML 维度或 LookML 维度的组合。
可以使用 value_format 或 value_format_name 参数设置 type: median 字段的格式。
示例
例如,以下 LookML 通过对 sales_price 维度求平均值来创建名为 median_order 的字段,然后以货币格式(1,234.56 美元)显示该字段:
measure: median_order {
type: median
sql: ${sales_price} ;;
value_format_name: usd
}
median 的注意事项
如果您将 median 用于涉及 扇出的字段,Looker 会尝试改用 median_distinct。不过,medium_distinct 仅支持某些方言。如果您的方言不支持 median_distinct,Looker 会返回错误。由于 median 可以视为第 50 百分位,因此该错误表明相应方言不支持不同的百分位。
median 支持的数据库方言
为了让 Looker 项目支持 median 类型,您的数据库方言也必须支持该类型。下表显示了 Looker 最新版本中哪些方言支持 median 类型:
| 方言 | 是否支持? |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13+ | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |
如果查询中涉及扇出,Looker 会尝试将 median 转换为 median_distinct。仅在支持 median_distinct 的方言中成功。
median_distinct
当您的联接涉及扇出时,请使用 type: median_distinct。它会根据 sql_distinct_key 参数定义的唯一值,计算指定字段中非重复值的平均值。如果度量没有 sql_distinct_key 参数,Looker 会尝试使用 primary_key 字段。
假设某个查询联接了“订单项”表和“订单”表,结果如下:
| 订单项 ID | 订单 ID | 订单配送 |
|---|---|---|
| 1 | 1 | 10 |
| 2 | 1 | 10 |
| 3 | 2 | 20 |
| 4 | 3 | 50 |
| 5 | 3 | 50 |
| 6 | 3 | 50 |
在这种情况下,您可以看到每个订单都有多行。此查询涉及扇出,因为每个订单都映射到多个订单项。median_distinct 会将此情况考虑在内,并找到不同值 10、20 和 50 之间的中位数,因此您会得到值 20。
为了获得准确的结果,您可以使用 sql_distinct_key 参数为 Looker 定义应如何识别每个唯一实体(在本例中为每个唯一订单)。这样就能计算出正确的金额:
measure: median_shipping {
type: median_distinct
sql_distinct_key: ${order_id} ;;
sql: ${order_shipping} ;;
}
sql_distinct_key 的每个唯一值都必须在指标的 sql 参数中有一个对应的值。换句话说,上述示例之所以有效,是因为 order_id 为 1 的每行的 order_shipping 均为 10,而 order_id 为 2 的每行的 order_shipping 均为 20。
可以使用 value_format 或 value_format_name 参数设置 type: median_distinct 字段的格式。
median_distinct 的注意事项
medium_distinct 衡量类型仅支持某些方言。如果方言不支持 median_distinct,Looker 会返回错误。由于 median 可以视为第 50 百分位,因此该错误表明相应方言不支持不同的百分位。
median_distinct 支持的数据库方言
为了让 Looker 项目支持 median_distinct 类型,您的数据库方言也必须支持该类型。下表显示了 Looker 最新版本中哪些方言支持 median_distinct 类型:
| 方言 | 是否支持? |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13+ | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |
min
type: min 用于查找指定字段中的最小值。它使用 SQL 的 MIN 函数。
对于 type: min 的度量,sql 参数可以采用任何有效的 SQL 表达式,该表达式会生成数值表列、LookML 维度或 LookML 维度的组合。
由于 type: min 的衡量指标仅与数字字段兼容,因此您无法使用 type: min 的衡量指标来查找最早日期。不过,您可以在 type: date 指标的 sql 参数中使用 MIN() 函数来捕获最小值,就像您可以使用 MAX() 函数来捕获 type: date 指标的最大日期一样。如本页面的 date 部分所示,其中包含在 sql 参数中使用 MAX() 函数查找最晚日期的示例。
可以使用 value_format 或 value_format_name 参数设置 type: min 字段的格式。
例如,以下 LookML 通过查看 sales_price 维度创建了一个名为 smallest_order 的字段,然后以货币格式(1,234.56 美元)显示该字段:
measure: smallest_order {
type: min
sql: ${sales_price} ;;
value_format_name: usd
}
您无法将 type: min 度量用于字符串或日期,但可以手动添加 MIN 函数来创建此类字段,如下所示:
measure: earliest_name_in_alphabet {
type: string
sql: MIN(${name}) ;;
}
number
type: number 可与数字或整数搭配使用。值为 type: number 的指标不执行任何汇总,旨在对其他指标执行基本转换。如果您要定义的指标基于另一个指标,则新指标必须为 type: number,以避免出现嵌套的聚合错误。
type: number 指标的 sql 参数可以采用任何有效的 SQL 表达式,只要该表达式的结果为数字或整数即可。
可以使用 value_format 或 value_format_name 参数设置 type: number 字段的格式。
例如,以下 LookML 会基于 total_sale_price 和 total_gross_margin 汇总度量创建一个名为 total_gross_margin_percentage 的度量,然后以百分比格式显示该度量,并保留两位小数 (12.34%):
measure: total_sale_price {
type: sum
value_format_name: usd
sql: ${sale_price} ;;
}
measure: total_gross_margin {
type: sum
value_format_name: usd
sql: ${gross_margin} ;;
}
measure: total_gross_margin_percentage {
type: number
value_format_name: percent_2
sql: ${total_gross_margin}/ NULLIF(${total_sale_price},0) ;;
}
此示例还使用 NULLIF() SQL 函数来消除除以零错误的可能。
type: number 的注意事项
使用 type: number 指标时,请注意以下几点重要事项:
type: number的衡量指标只能对其他衡量指标执行算术运算,而不能对其他维度执行算术运算。- 当跨联接计算时,Looker 的对称聚合不会保护度量
type: number的 SQL 中的聚合函数。 filters参数不能与type: number度量一起使用,但filters文档中介绍了解决方法。type: number衡量不会向用户提供建议。
percent_of_previous
type: percent_of_previous 用于计算某个单元格与其所在列中前一个单元格之间的百分比差值。
type: percent_of_previous 指标的 sql 参数必须引用另一个数值指标。
您可以使用 value_format 或 value_format_name 参数设置 type: percent_of_previous 字段的格式。不过,value_format_name 参数的百分比格式不适用于 type: percent_of_previous 指标。这些百分比格式会将值乘以 100,从而使“占上期百分比”计算结果出现偏差。
此 LookML 示例创建了一个基于 count 指标的 count_growth 指标:
measure: count_growth {
type: percent_of_previous
sql: ${count} ;;
}
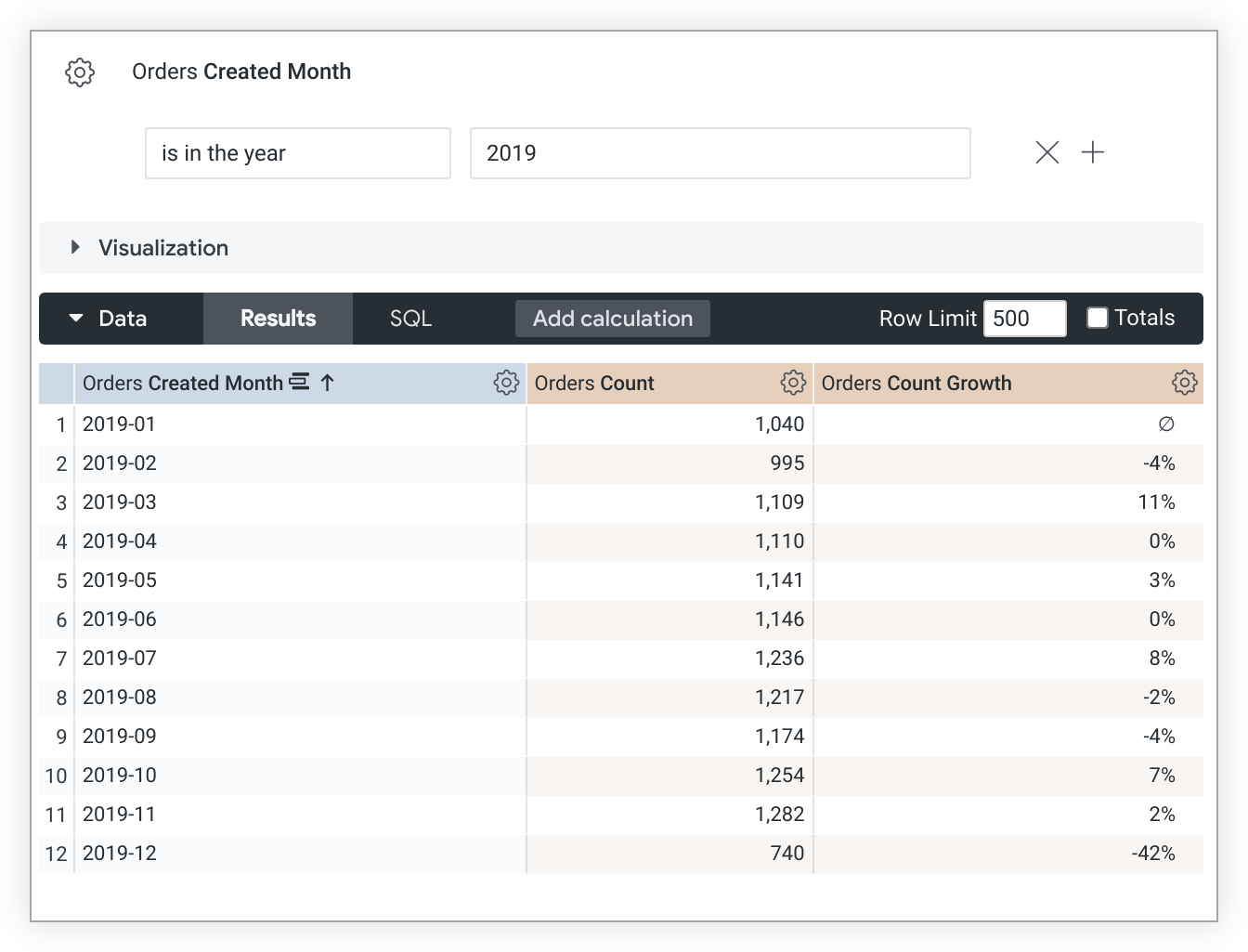
请注意,percent_of_previous 值取决于排序顺序。如果您更改了排序,则必须重新运行查询以重新计算 percent_of_previous 值。如果查询进行了透视,percent_of_previous 会在行中运行,而不是在列中运行。您无法更改此行为。
此外,percent_of_previous 指标是在从数据库返回数据后计算的。这意味着您不应在一个指标内引用另一个 percent_of_previous 指标;由于它们可能在不同时间计算,因此您可能无法获得准确的结果。这也意味着,无法根据 percent_of_previous 指标进行过滤。
此类指标的一个应用是同比 (PoP) 分析,这是一种分析模式,用于衡量当前的情况,并将其与过去可比较时间段内的相同衡量结果进行比较。如需详细了解 PoP,请参阅 Looker 社区文章如何进行同比分析和 Looker 中的同比 (PoP) 分析方法。
percent_of_total
type: percent_of_total 用于计算单元格在列总计中所占的比例。该百分比是根据查询返回的行总数计算的,而非所有可能的行总数。不过,如果查询返回的数据超出行数限制,该字段的值将显示为 null,因为系统需要完整的结果才能计算出占总数的百分比。
type: percent_of_total 指标的 sql 参数必须引用另一个数值指标。
您可以使用 value_format 或 value_format_name 参数设置 type: percent_of_total 字段的格式。不过,value_format_name 参数的百分比格式不适用于 type: percent_of_total 指标。这些百分比格式会将值乘以 100,从而导致 percent_of_total 计算结果出现偏差。
此 LookML 示例创建了一个基于 total_gross_margin 指标的 percent_of_total_gross_margin 指标:
measure: percent_of_total_gross_margin {
type: percent_of_total
sql: ${total_gross_margin} ;;
}
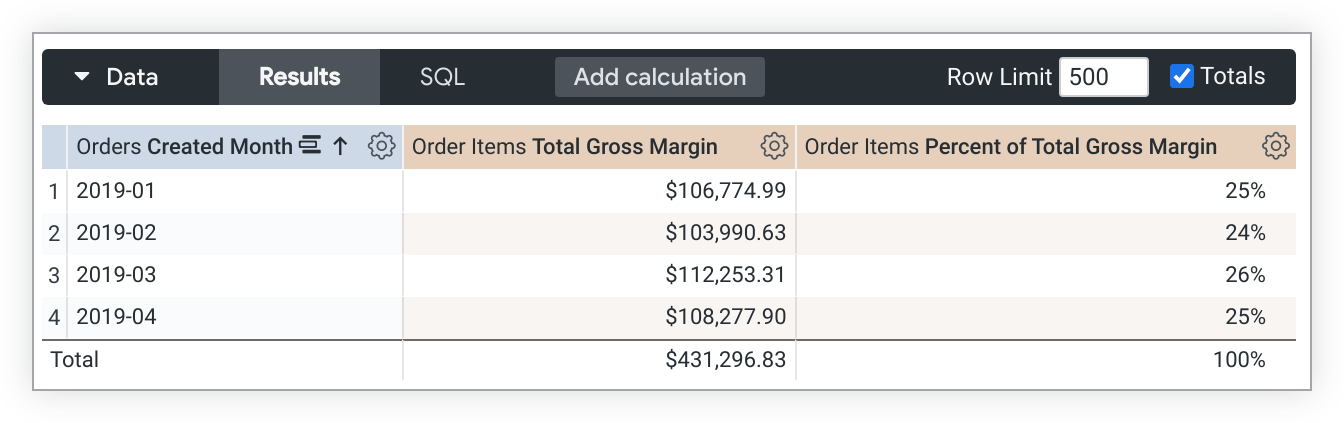
如果查询进行了透视,percent_of_total 会在行中运行,而不是在列中运行。如果这不是您想要的结果,请将 direction: "column" 添加到指标定义中。
此外,percent_of_total 指标是在从数据库返回数据后计算的。这意味着您不应在一个指标内引用另一个 percent_of_total 指标;由于它们可能在不同时间计算,因此您可能无法获得准确的结果。这也意味着,无法根据 percent_of_total 指标进行过滤。
percentile
type: percentile 返回指定字段中指定百分位的值。例如,指定第 75 百分位将返回大于数据集中 75% 其他值的值。
为了确定要返回的值,Looker 会计算数据值的总数,然后将指定的百分位数乘以数据值的总数。无论数据的实际排序方式如何,Looker 都会按值递增的顺序确定数据值的相对顺序。Looker 返回的数据值取决于计算结果是否为整数,如以下两个部分中所述。
如果计算出的值不是整数
Looker 会将计算出的值向上舍入,并使用该值来确定要返回的数据值。在此示例中,有一组包含 19 个考试分数的数据,第 75 百分位数为 19 * 0.75 = 14.25,这意味着 75% 的值位于前 14 个数据值中,即低于第 15 个位置。因此,Looker 会返回第 15 个数据值 (87),因为该值大于 75% 的数据值。

如果计算出的值为整数
在这种稍复杂的情况下,Looker 会返回该位置的数据值和后续数据值的平均值。为了便于理解,我们以一组包含 20 个考试分数的数据为例:第 75 百分位数为 20 * 0.75 = 15,这意味着第 15 个位置的数据值属于第 75 百分位数,我们需要返回一个高于 75% 的数据值。通过返回第 15 位 (82) 和第 16 位 (87) 值的平均值,Looker 可确保 75%。该平均值 (84.5) 不存在于数据值集中,但会大于 75% 的数据值。

必需参数和可选参数
使用 percentile: 关键字指定分数值,即应低于返回值的百分比数据。例如,使用 percentile: 75 可指定按数据顺序排列的第 75 百分位的值,使用 percentile: 10 可返回第 10 百分位的值。如果您想查找第 50 百分位的值,可以指定 percentile: 50,也可以直接使用中位数类型。
type: percentile 度量的 sql 参数可以采用任何有效的 SQL 表达式,该表达式会生成数值表列、LookML 维度或 LookML 维度的组合。
可以使用 value_format 或 value_format_name 参数设置 type: percentile 字段的格式。
示例
例如,以下 LookML 会创建一个名为 test_scores_75th_percentile 的字段,该字段会返回 test_scores 维度中第 75 百分位的值:
measure: test_scores_75th_percentile {
type: percentile
percentile: 75
sql: ${TABLE}.test_scores ;;
}
percentile 的注意事项
如果您将 percentile 用于涉及扇出的字段,Looker 会尝试改用 percentile_distinct。如果方言不支持 percentile_distinct,Looker 会返回错误。如需了解详情,请参阅percentile_distinct 支持的方言。
percentile 支持的数据库方言
为了让 Looker 项目支持 percentile 类型,您的数据库方言也必须支持该类型。下表显示了 Looker 最新版本中哪些方言支持 percentile 类型:
| 方言 | 是否支持? |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13+ | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |
percentile_distinct
type: percentile_distinct 是 百分位数的一种特殊形式,当您的联接涉及扇出时应使用它。它会根据 sql_distinct_key 参数定义的唯一值,使用指定字段中的非重复值。如果度量没有 sql_distinct_key 参数,Looker 会尝试使用 primary_key 字段。
假设某个查询联接了“订单项”表和“订单”表,结果如下:
| 订单项 ID | 订单 ID | 订单配送 |
|---|---|---|
| 1 | 1 | 10 |
| 2 | 1 | 10 |
| 3 | 2 | 20 |
| 4 | 3 | 50 |
| 5 | 3 | 50 |
| 6 | 3 | 50 |
| 7 | 4 | 70 |
| 8 | 4 | 70 |
| 9 | 5 | 110 |
| 10 | 5 | 110 |
在这种情况下,您可以看到每个订单都有多行。此查询涉及扇出,因为每个订单都映射到多个订单项。percentile_distinct 会考虑到这一点,并使用不同的值 10、20、50、70 和 110 查找百分位数值。第 25 百分位将返回第二个不同的值(即 20),而第 80 百分位将返回第四个和第五个不同的值的平均值(即 90)。
必需参数和可选参数
使用 percentile: 关键字指定小数值。例如,使用 percentile: 75 可指定按数据顺序排列的第 75 百分位的值,使用 percentile: 10 可返回第 10 百分位的值。如果您要查找第 50 百分位的值,可以改用 median_distinct 类型。
为了获得准确的结果,请使用 sql_distinct_key 参数指定 Looker 应如何识别每个唯一实体(在本例中为每个唯一订单)。
以下示例展示了如何使用 percentile_distinct 返回第 90 百分位的值:
measure: order_shipping_90th_percentile {
type: percentile_distinct
percentile: 90
sql_distinct_key: ${order_id} ;;
sql: ${order_shipping} ;;
}
sql_distinct_key 的每个唯一值都必须在指标的 sql 参数中有一个对应的值。换句话说,上述示例之所以有效,是因为 order_id 为 1 的每行的 order_shipping 均为 10,而 order_id 为 2 的每行的 order_shipping 均为 20。
可以使用 value_format 或 value_format_name 参数设置 type: percentile_distinct 字段的格式。
percentile_distinct 的注意事项
如果方言不支持 percentile_distinct,Looker 会返回错误。如需了解详情,请参阅percentile_distinct 支持的方言。
percentile_distinct 支持的数据库方言
为了让 Looker 项目支持 percentile_distinct 类型,您的数据库方言也必须支持该类型。下表显示了 Looker 最新版本中哪些方言支持 percentile_distinct 类型:
| 方言 | 是否支持? |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13+ | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |
period_over_period
对于支持不同时间段对比度量的方言,您可以创建 LookML 度量 type: period_over_period 来创建不同时间段对比 (PoP) 度量。PoP 指标是指对较早时间段的汇总。
以下是一个提供上个月订单数量的 PoP 指标示例:
measure: orders_last_month {
type: period_over_period
based_on: orders.count
based_on_time: orders.created_month
period: month
kind: previous
}
具有 type: period_over_period 的衡量指标还必须具有以下子参数:
如需了解详情和示例,请参阅 Looker 中的同比指标。
running_total
type: running_total 计算列中单元格的累计总和。它不能用于计算行中的总和,除非该行是透视的结果。
type: running_total 指标的 sql 参数必须引用另一个数值指标。
可以使用 value_format 或 value_format_name 参数设置 type: running_total 字段的格式。
以下 LookML 示例创建了一个基于 total_sale_price 指标的 cumulative_total_revenue 指标:
measure: cumulative_total_revenue {
type: running_total
sql: ${total_sale_price} ;;
value_format_name: usd
}
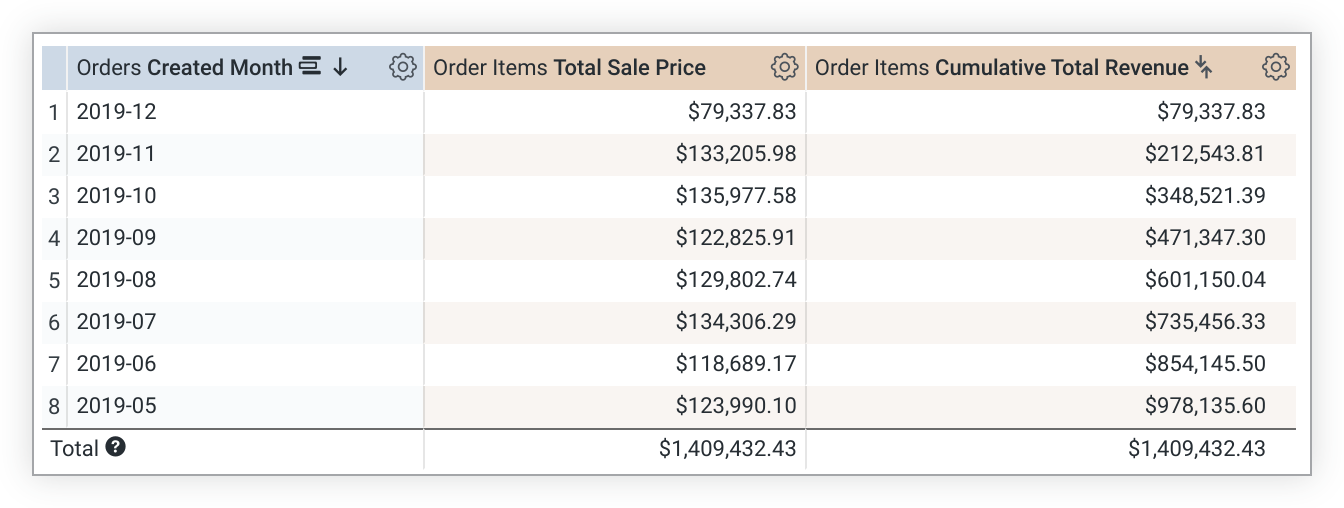
请注意,running_total 值取决于排序顺序。如果您更改了排序,则必须重新运行查询以重新计算 running_total 值。如果查询进行了透视,running_total 会在行中运行,而不是在列中运行。如果这不是您想要的结果,请将 direction: "column" 添加到指标定义中。
此外,running_total 指标是在从数据库返回数据后计算的。这意味着您不应在一个指标内引用另一个 running_total 指标;由于它们可能在不同时间计算,因此您可能无法获得准确的结果。这也意味着,无法根据 running_total 指标进行过滤。
string
type: string 用于包含字母或特殊字符的字段。
type: string 指标的 sql 参数可以采用任何有效的 SQL 表达式,只要该表达式的结果为字符串即可。实际上,这种类型很少使用,因为大多数 SQL 聚合函数不会返回字符串。一个常见的例外情况是 MySQL 的 GROUP_CONCAT 函数,不过 Looker 针对该用例提供了 type: list。
例如,以下 LookML 通过合并名为 category 的字段的唯一值来创建字段 category_list:
measure: category_list {
type: string
sql: GROUP_CONCAT(${category}) ;;
}
在此示例中,可以省略 type: string,因为 string 是 type 的默认值。
sum
type: sum 会将指定字段中的值相加。它类似于 SQL 的 SUM 函数。不过,与原始 SQL 不同的是,即使查询的联接包含扇出,Looker 也会正确计算总和。
type: sum 度量的 sql 参数可以采用任何有效的 SQL 表达式,该表达式会生成数值表列、LookML 维度或 LookML 维度的组合。
可以使用 value_format 或 value_format_name 参数设置 type: sum 字段的格式。
例如,以下 LookML 通过将 sales_price 维度相加来创建一个名为 total_revenue 的字段,然后以货币格式($1,234.56)显示该字段:
measure: total_revenue {
type: sum
sql: ${sales_price} ;;
value_format_name: usd
}
sum_distinct
type: sum_distinct 适用于非规范化数据集。它会根据 sql_distinct_key 参数定义的唯一值,对指定字段中的非重复值进行求和。
这是一个高级概念,通过示例可以更清楚地说明。假设有一个如下所示的反规范化表:
| 订单项 ID | 订单 ID | 订单配送 |
|---|---|---|
| 1 | 1 | 10.00 |
| 2 | 1 | 10.00 |
| 3 | 2 | 20.00 |
| 4 | 2 | 20.00 |
| 5 | 2 | 20.00 |
在这种情况下,您可以看到每个订单都有多行。因此,如果您为 order_shipping 列添加了 type: sum 度量,您会得到 80.00 的总和,即使实际收取的运费总额为 30.00。
# Will NOT calculate the correct shipping amount
measure: total_shipping {
type: sum
sql: ${order_shipping} ;;
}
为了获得准确的结果,您可以使用 sql_distinct_key 参数为 Looker 定义应如何识别每个唯一实体(在本例中为每个唯一订单)。此公式将计算出正确的 30.00 金额:
# Will calculate the correct shipping amount
measure: total_shipping {
type: sum_distinct
sql_distinct_key: ${order_id} ;;
sql: ${order_shipping} ;;
}
sql_distinct_key 的每个唯一值在 sql 中都必须只有一个对应的值。换句话说,上述示例之所以有效,是因为 order_id 为 1 的每行的 order_shipping 均为 10.00,而 order_id 为 2 的每行的 order_shipping 均为 20.00。
可以使用 value_format 或 value_format_name 参数设置 type: sum_distinct 字段的格式。
yesno
type: yesno 会创建一个字段,用于指明某个内容是 true 还是 false。这些值在探索界面中显示为 Yes 和 No。
type: yesno 指标的 sql 参数接受计算结果为 TRUE 或 FALSE 的有效 SQL 表达式。如果条件计算结果为 TRUE,则向用户显示是;否则,显示否。
type: yesno 度量的 SQL 表达式必须仅包含聚合,这意味着 SQL 聚合或对 LookML 度量的引用。如果您想创建包含对 LookML 维度或非聚合 SQL 表达式的引用的 yesno 字段,请使用带有 type: yesno 的维度,而不是度量。
与具有 type: number 的度量类似,具有 type: yesno 的度量不会进行任何汇总,只会引用其他汇总。
例如,以下 total_sale_price 度量示例是订单中订单商品的总销售价格之和。第二种衡量指标(称为 is_large_total)为 type: yesno。is_large_total 指标具有 sql 参数,用于评估 total_sale_price 值是否大于 1,000 美元。
measure: total_sale_price {
type: sum
value_format_name: usd
sql: ${sale_price} ;;
drill_fields: [detail*]
}
measure: is_large_total {
description: "Is order total over $1000?"
type: yesno
sql: ${total_sale_price} > 1000 ;;
}
如果您想在另一个字段中引用 type: yesno 字段,则应将 type: yesno 字段视为布尔值(换句话说,就好像它已包含 true 或 false 值)。例如:
measure: is_large_total {
description: "Is order total over $1000?"
type: yesno
sql: ${total_sale_price} > 1000 ;;
}
# This is correct:
measure: reward_points {
type: number
sql: CASE WHEN ${is_large_total} THEN 200 ELSE 100 END ;;
}
# This is NOT correct:
measure: reward_points {
type: number
sql: CASE WHEN ${is_large_total} = 'Yes' THEN 200 ELSE 100 END ;;
}