
このページでは、指標の一部である
typeパラメータについて説明します。
typeは、ディメンション、フィルタ、パラメータ タイプのドキュメント ページで説明されているように、ディメンションまたはフィルタの一部としても使用できます。
typeは、dimension_groupパラメータのドキュメント ページで説明されているように、ディメンション グループの一部としても使用できます。
用途
view: view_name {
measure: field_name {
type: measure_field_type
}
}
|
階層
type |
使用可能なフィールドタイプ
測定
許可
メジャータイプ
|
このページには、メジャーに割り当て可能なさまざまなタイプに関する詳細が含まれます。1 つのメジャーに使用できるタイプは 1 つのみであり、タイプが指定されない場合はデフォルトで string になります。
一部のメジャータイプには補助パラメーターがあります。補助パラメーターについては、該当するセクションで説明しています。
メジャータイプのカテゴリ
各メジャータイプは次のいずれかのカテゴリに分類されます。これらのカテゴリは、メジャータイプが集計を実行するかどうか、メジャータイプが参照できるフィールドのタイプ、filters パラメータを使用してメジャータイプをフィルタできるかどうかを決定します。
- 集計メジャー: 集計メジャータイプは、
sumやaverageなどの集計を実行します。集計メジャーは、ディメンションのみを参照でき、他のメジャーを参照することはできません。これは、filtersパラメータを使用できる唯一のメジャータイプです。 - 非集計メジャー: 非集計メジャーは、名前が示すとおり、
numberやyesnoなど、集計を実行しないメジャータイプです。これらのメジャータイプでは基本的な変換が実行されます。また、集計が実行されないことから、集計メジャーまたは以前に集計されたディメンションのみを参照できます。これらの測定タイプではfiltersパラメータを使用できません。 - Post-SQL メジャー: Post-SQL メジャーは、Looker によってクエリ SQL が生成された後に特定の計算を実行する特殊なメジャータイプです。数値メジャーまたは数値ディメンションのみを参照できます。これらの測定タイプでは
filtersパラメータを使用できません。
タイプ定義のリスト
| タイプ | カテゴリ | 説明 |
|---|---|---|
average |
集計 | 列内の値の平均を生成します。 |
average_distinct |
集計 | 非正規化データを使用する場合に値の平均を適切に生成します。詳細については、average_distinct セクションをご覧ください。 |
count |
集計 | 行のカウントを生成します。 |
count_distinct |
集計 | 列内の一意の値のカウントを生成します。 |
date |
非集計 | 日付を含むメジャーに使用します。 |
list |
集計 | 列内の一意の値のリストを生成します。 |
max |
集計 | 列内の最大値を生成します。 |
median |
集計 | 列内の値の中央値(中間値)を生成します。 |
median_distinct |
集計 | 結合によりファンアウトが生じる場合に値の中央値(中間値)を適切に生成します。詳細については、median_distinct セクションをご覧ください。 |
min |
集計 | 列内の最小値を生成します。 |
number |
非集計 | 数値を含むメジャーに使用します。 |
percent_of_previous |
Post-SQL | 表示された行間の差分割合(%)を生成します。 |
percent_of_total |
Post-SQL | 表示された各行の合計に対する割合(%)を生成します。 |
percentile |
集計 | 列内の指定パーセンタイルの値を生成します。 |
percentile_distinct |
集計 | 結合によりファンアウトが生じる場合に指定パーセンタイルの値を生成します。詳細については、percentile_distinct セクションをご覧ください。 |
running_total |
Post-SQL | 表示された各行の現在までの合計を生成します。 |
period_over_period |
集計 | 以前の期間の集計を参照する |
string |
非集計 | 文字や特殊文字を含むメジャーに使用します(MySQL の GROUP_CONCAT 関数と同様です)。 |
sum |
集計 | 列内の値の合計を生成します。 |
sum_distinct |
集計 | 非正規化データを使用する場合に値の合計を適切に生成します。詳細については、sum_distinct セクションをご覧ください。 |
yesno |
非集計 | 何かが真であるか偽であるかを示すフィールドに使用します。 |
int |
非集計 |
5.4 で削除
type: number に置き換え |
average
type: average は、指定されたフィールドの値を平均します。これは SQL の AVG 関数に似ています。ただし、生の SQL とは異なり、クエリの結合にファンアウトが含まれている場合でも、Looker は平均を適切に計算します。
type: average メジャーの sql パラメータには、数値テーブル列、LookML ディメンション、または LookML ディメンションの組み合わせをもたらす有効な SQL 式を指定できます。
type: average フィールドは、value_format パラメータまたは value_format_name パラメータを使用してフォーマットできます。
たとえば、次の LookML では、sales_price ディメンションを平均することで avg_order というフィールドが作成され、これが金額書式($1,234.56)で表示されます。
measure: avg_order {
type: average
sql: ${sales_price} ;;
value_format_name: usd
}
average_distinct
type: average_distinct は、非正規化されたデータセットで使用します。sql_distinct_key パラメータで定義された一意の値に基づいて、指定されたフィールドの重複しない値の平均を計算します。
これは高度な概念であるため、例を挙げてよりわかりやすく説明します。次のような非正規化テーブルについて考えます。
| Order Item ID | 注文 ID | 注文出荷 |
|---|---|---|
| 1 | 1 | 10.00 |
| 2 | 1 | 10.00 |
| 3 | 2 | 20.00 |
| 4 | 2 | 20.00 |
| 5 | 2 | 20.00 |
この状況では、各注文に複数の行が存在することがわかります。したがって、order_shipping 列に基本的な type: average メジャーを追加した場合、実際の平均は 15.00 であるにもかかわらず、値として 16.00 が返されます。
# Will NOT calculate the correct average
measure: avg_shipping {
type: average
sql: ${order_shipping} ;;
}
正確な結果を得るには、sql_distinct_key パラメータを使用して、一意の各エンティティ(この例では一意の各注文)の識別方法を Looker に定義します。これにより、正しい額である 15.00 が計算されるようになります。
# Will calculate the correct average
measure: avg_shipping {
type: average_distinct
sql_distinct_key: ${order_id} ;;
sql: ${order_shipping} ;;
}
sql_distinct_key の一意の値ごとに、sql に対応する値が 1 つだけ存在する必要があります。つまり、order_id が 1 のすべての行の order_shipping が 10.00 で、order_id が 2 のすべての行の order_shipping が 20.00 であるため、上記の例は機能します。
type: average_distinct フィールドは、value_format パラメータまたは value_format_name パラメータを使用してフォーマットできます。
count
type: count は、SQL の COUNT 関数と同様に、テーブルのカウントを実行します。ただし、生の SQL とは異なり、クエリの結合にファンアウトが含まれている場合でも、Looker はカウントを適切に計算します。
type: count メジャーはテーブルの主キーに基づいてテーブル カウントを行うため、type: count メジャーは sql パラメータをサポートしていません。
テーブルの主キー以外のフィールドに対してテーブルカウントを実行する場合は、type: count_distinct メジャーを使用します。count_distinct を使用したくない場合は、type: number の指標を使用できます(詳細については、コミュニティ投稿の主キー以外の方法をカウントする方法をご覧ください)。
たとえば、次の LookML は number_of_products フィールドを作成します。
view: products {
measure: number_of_products {
type: count
drill_fields: [product_details*] # optional
}
}
type: count 測定を定義する際に drill_fields(フィールド用)パラメータを指定することはよくあります。これにより、ユーザーがカウントをクリックしたときに、そのカウントを構成する個々のレコードを確認できます。
Explore で
type: countの measure を使用する場合、可視化された値には、「Count」という単語ではなく、ビュー名でラベルが付けられます。混乱を避けるために、ビュー名は複数形で設定することを推奨します。ビジュアリゼーション設定の [シリーズ] で [完全なフィールド名を表示] を選択するか、ビュー名を複数形にしたview_labelを使用します。
filters パラメータを使用すると、type: count の指標にフィルタを追加できます。
count_distinct
type: count_distinct は、特定のフィールド内にある、重複を含まない値の数を計算します。これには SQL の COUNT DISTINCT 関数が使用されます。
type: count_distinct メジャーの sql パラメータには、テーブル列、LookML ディメンション、または LookML ディメンションの組み合わせをもたらす有効な SQL 式を指定できます。
たとえば、次の LookML では、一意の顧客 ID の数をカウントする number_of_unique_customers というフィールドが作成されます。
measure: number_of_unique_customers {
type: count_distinct
sql: ${customer_id} ;;
}
filters パラメータを使用すると、type: count_distinct の指標にフィルタを追加できます。
date
<mq:rxt-req displaytext="`type: date`" val="`type: date`" />は、日付を含むフィールドとともに使用されます。type: date
type: date 測定の sql パラメータには、日付を返す有効な SQL 式を指定できます。日付を返す SQL 集計関数はごくわずかであることから、このタイプが実際に使用されることはほとんどありません。一般的な例外は、日付ディメンションの MIN または MAX です。
type: date を使用して最大または最小の日付指標を作成する
最大日付または最小日付の指標を作成する場合は、最初に type: max または type: min の指標を使用することを検討するかもしれません。ただし、これらの指標タイプは数値フィールドとのみ互換性があります。代わりに、type: date の指標を定義し、sql パラメータで参照される日付フィールドを MIN() 関数または MAX() 関数でラップすることで、最大日付または最小日付を取得できます。
updated という名前の type: time のディメンション グループがあるとします。
dimension_group: updated {
type: time
timeframes: [time, date, week, month, raw]
sql: ${TABLE}.updated_at ;;
}
次のように、type: date の測定を作成して、このディメンション グループの最大日付を取得できます。
measure: last_updated_date {
type: date
sql: MAX(${updated_raw}) ;;
convert_tz: no
}
この例では、type: max の指標を使用して last_updated_date 指標を作成する代わりに、MAX() 関数が sql パラメータに適用されています。また、last_updated_date 指標の convert_tz パラメータは no に設定されています。これは、ディメンショングループ updated の定義でタイムゾーン変換がすでに実行されているため、指標でタイムゾーン変換が二重に実行されるのを防ぐためです。詳細については、convert_tz パラメータに関するドキュメントをご覧ください。
last_updated_date 指標の LookML の例では、string が type のデフォルト値であるため、type: date を省略すると、値は文字列として扱われます。ただし、type: date を使用すると、ユーザーのフィルタリング機能が向上します。
また、last_updated_date 指標の定義が ${updated_date} 期間ではなく ${updated_raw} 期間を参照していることにも気づくかもしれません。${updated_date} から返される値は文字列であるため、代わりに ${updated_raw} を使用して実際の日付値を参照する必要があります。
また、type: date で datatype パラメータを使用して、データベース テーブルで使用される日付データの型を指定することで、クエリのパフォーマンスを向上させることもできます。
日時列の最大値または最小値のメジャーを作成する
type: datetime 列の最大値を計算する方法は少し異なります。この場合は、次のように型を宣言せずにメジャーを作成します。
measure: last_updated_datetime {
sql: MAX(${TABLE}.datetime_string_field) ;;
}
list
type: list は、特定のフィールド内の個別値のリストを作成します。これは、MySQL の GROUP_CONCAT 関数に似ています。
type: list 指標に sql パラメータを含める必要はありません。代わりに、list_field パラメータを使用して、作成するリストの基礎となるディメンションを指定します。
使用方法は次のとおりです。
view: view_name {
measure: field_name {
type: list
list_field: my_field_name
}
}
たとえば、次の LookML は name ディメンションに基づいて name_list メジャーを作成します。
measure: name_list {
type: list
list_field: name
}
list については、次の点に注意してください。
list測定タイプではフィルタリングはサポートされていません。type: list測定でfiltersパラメータを使用することはできません。list指標タイプは、置換演算子($)を使用して参照できません。${}構文を使用してtype: list指標を参照することはできません。
list でサポートされているデータベース言語
Looker プロジェクトで type: list をサポートするには、データベース言語でも type: list をサポートしている必要があります。次の表に、Looker の最新リリースで type: list をサポートする言語を示します。
| 方言 | サポート対象 |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13+ | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |
max
type: max は、指定されたフィールドの最大値を検索します。これには SQL の MAX 関数が使用されます。
type: max のメジャーの sql パラメータには、数値テーブル列、LookML ディメンション、または LookML ディメンションの組み合わせをもたらす有効な SQL 式を指定できます。
type: max のメジャーは数値フィールドとのみ互換性があるため、type: max のメジャーを使用して最大日付を見つけることはできません。代わりに、type: date の指標の sql パラメータで MAX() 関数を使用して、最大日付を取得できます。これは、前の date セクションの例で示されています。
type: max フィールドは、value_format パラメータまたは value_format_name パラメータを使用してフォーマットできます。
例えば、次の LookML では、sales_price ディメンションを確認することで largest_order というフィールドが作成され、これが金額書式($1,234.56)で表示されます。
measure: largest_order {
type: max
sql: ${sales_price} ;;
value_format_name: usd
}
文字列または日付に対して type: max メジャーを使用することはできませんが、次のように MAX 関数を手動で追加することで、これらのフィールドを作成することは可能です。
measure: latest_name_in_alphabet {
type: string
sql: MAX(${name}) ;;
}
median
type: median は、特定のフィールド内の値の中間値を返します。これは、データに大きすぎる外れ値または小さすぎる外れ値がいくつか含まれており、それに起因してデータの基本平均が歪む場合に特に役立ちます。
次のようなテーブルについて考えます。
| Order Item ID | 費用 | 中間? |
|---|---|---|
| 2 | 10.00 | |
| 4 | 10.00 | |
| 3 | 20.00 | 中間値 |
| 1 | 80.00 | |
| 5 | 90.00 |
テーブルは費用で並べ替えられますが、結果には影響しません。average タイプを使用した場合は 42 が返される(すべての値を合計して 5 で割る)のに対し、median タイプを使用した場合は中間値の 20.00 が返されます。
値の数が偶数である場合は、中間から最も近い 2 つの値の平均を求めることによって中央値が計算されます。偶数行からなる次のようなテーブルについて考えます。
| Order Item ID | 費用 | 中間? |
|---|---|---|
| 2 | 10 | |
| 3 | 20 | 中間の直前 |
| 1 | 80 | 中間の直後 |
| 4 | 90 |
中央値(中間値)は (20 + 80)/2 = 50 です。
中央値は 50 番目のパーセンタイルの値とも等しくなります。
type: median メジャーの sql パラメータには、数値テーブル列、LookML ディメンション、または LookML ディメンションの組み合わせをもたらす有効な SQL 式を指定できます。
type: median フィールドは、value_format パラメータまたは value_format_name パラメータを使用してフォーマットできます。
例
たとえば、次の LookML では、sales_price ディメンションを平均することで median_order というフィールドが作成され、これが金額書式($1,234.56)で表示されます。
measure: median_order {
type: median
sql: ${sales_price} ;;
value_format_name: usd
}
median で考慮すべき事項
ファンアウトに関与するフィールドに median を使用している場合、Looker は代わりに median_distinct を使用しようとします。ただし、medium_distinct は特定のダイアレクトでのみサポートされています。ダイアレクトで median_distinct が使用できない場合、Looker はエラーを返します。median は 50 パーセンタイルと見なすことができるため、エラーにはダイアレクトが個別のパーセンタイルをサポートしていないことが示されます。
median でサポートされているデータベース言語
Looker が Looker プロジェクトで median 型をサポートできるようにするには、データベース言語もそれをサポートしている必要があります。次の表に、Looker の最新リリースで median 型をサポートする言語を示します。
| 方言 | サポート対象 |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13+ | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |
クエリにファンアウトが伴う場合は、median から median_distinct への変換が試みられます。この変換は、median_distinct をサポートする言語でのみ成功します。
median_distinct
結合にファンアウトが含まれる場合は、type: median_distinct を使用します。sql_distinct_key パラメータで定義された一意の値に基づいて、指定されたフィールドの重複しない値の平均を計算します。メジャーに sql_distinct_key パラメータがない場合、Looker は primary_key フィールドを使用しようとします。
注文品目テーブルと注文テーブルを結合した次のようなクエリ結果について考えます。
| Order Item ID | 注文 ID | 注文出荷 |
|---|---|---|
| 1 | 1 | 10 |
| 2 | 1 | 10 |
| 3 | 2 | 20 |
| 4 | 3 | 50 |
| 5 | 3 | 50 |
| 6 | 3 | 50 |
この状況では、各注文に複数の行が存在することがわかります。各注文はそれぞれ複数の注文品目に対応付けられているため、このクエリにはファンアウトが伴っています。median_distinct では、この点を考慮して個別値 10、20、50 の中央値が検索され、結果として値 20 が返されます。
正確な結果を得るには、sql_distinct_key パラメータを使用して、一意の各エンティティ(この例では一意の各注文)の識別方法を Looker に定義します。これにより、正しい額が計算されるようになります。
measure: median_shipping {
type: median_distinct
sql_distinct_key: ${order_id} ;;
sql: ${order_shipping} ;;
}
sql_distinct_key の一意の値ごとに、メジャーの sql パラメータに対応する値が 1 つだけ存在する必要があります。つまり、前の例が機能するのは、order_id が 1 のすべての行の order_shipping が 10 であり、order_id が 2 のすべての行の order_shipping が 20 であるためです。
type: median_distinct フィールドは、value_format パラメータまたは value_format_name パラメータを使用してフォーマットできます。
median_distinct で考慮すべき事項
medium_distinct 測定タイプは、特定の言語でのみサポートされています。ダイアレクトで median_distinct が利用できない場合は、エラーが返されます。median は 50 パーセンタイルと見なすことができるため、このエラーは、この言語で個別のパーセンタイルがサポートされていないことを示しています。
median_distinct でサポートされているデータベース言語
Looker が Looker プロジェクトで median_distinct 型をサポートできるようにするには、データベース言語もそれをサポートしている必要があります。次の表に、Looker の最新リリースで median_distinct 型をサポートする言語を示します。
| 方言 | サポート対象 |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13+ | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |
min
type: min は、指定されたフィールドの最小値を検索します。これには SQL の MIN 関数が使用されます。
type: min のメジャーの sql パラメータには、数値テーブル列、LookML ディメンション、または LookML ディメンションの組み合わせをもたらす有効な SQL 式を指定できます。
type: min のメジャーは数値フィールドとのみ互換性があるため、type: min のメジャーを使用して最小日付を見つけることはできません。代わりに、type: date の指標の sql パラメータで MIN() 関数を使用して最小値をキャプチャできます。これは、type: date の指標で MAX() 関数を使用して最大日付をキャプチャできるのと同様です。これは、このページの前の date セクションで説明されています。このセクションには、sql パラメータで MAX() 関数を使用して最大日付を検索する例が含まれています。
type: min フィールドは、value_format パラメータまたは value_format_name パラメータを使用してフォーマットできます。
例えば、次の LookML では、sales_price ディメンションを確認することで smallest_order というフィールドが作成され、これが金額書式($1,234.56)で表示されます。
measure: smallest_order {
type: min
sql: ${sales_price} ;;
value_format_name: usd
}
文字列または日付に対して type: min メジャーを使用することはできませんが、次のように MIN 関数を手動で追加することで、これらのフィールドを作成することは可能です。
measure: earliest_name_in_alphabet {
type: string
sql: MIN(${name}) ;;
}
number
type: number は数値または整数とともに使用されます。type: number のメジャーは集計を行わず、他のメジャーに対して基本的な変換を行うことを目的としています。別のメジャーに基づくメジャーを定義する場合は、ネストされた集計エラーを回避するために、新しいメジャーを type: number にする必要があります。
type: number 測定の sql パラメータには、数値または整数をもたらす有効な SQL 式を指定できます。
type: number フィールドは、value_format パラメータまたは value_format_name パラメータを使用してフォーマットできます。
たとえば、次の LookML では、total_sale_price と total_gross_margin の集計メジャーに基づいて total_gross_margin_percentage というメジャーを作成し、小数点以下 2 桁のパーセント形式(12.34%)で表示します。
measure: total_sale_price {
type: sum
value_format_name: usd
sql: ${sale_price} ;;
}
measure: total_gross_margin {
type: sum
value_format_name: usd
sql: ${gross_margin} ;;
}
measure: total_gross_margin_percentage {
type: number
value_format_name: percent_2
sql: ${total_gross_margin}/ NULLIF(${total_sale_price},0) ;;
}
また、この例では、NULLIF() SQL 関数を使用して、ゼロ除算エラーの可能性を排除しています。
type: number で考慮すべき事項
type: number 指標を使用する際は、次の点に注意してください。
type: numberのメジャーは、他のメジャーに対してのみ演算を実行でき、他のディメンションに対しては実行できません。- Looker の対称集計は、結合全体で計算される場合、メジャー
type: numberの SQL の集計関数を保護しません。 filtersパラメータはtype: number指標では使用できませんが、filtersのドキュメントで回避策が説明されています。type: number指標では、ユーザーに提案は表示されません。
percent_of_previous
type: percent_of_previous は、列内のセルとその前のセルとの差(%)を計算します。
type: percent_of_previous メジャーの sql パラメータは、別の数値メジャーを参照する必要があります。
type: percent_of_previous フィールドは、value_format パラメータまたは value_format_name パラメータを使用してフォーマットできます。ただし、value_format_name パラメータのパーセント形式は type: percent_of_previous 指標では使用できません。これらのパーセンテージ書式は値に100を乗算するものであり、前の計算のパーセント結果を歪める原因となります。
この LookML の例では、count measure に基づく count_growth measure を作成します。
measure: count_growth {
type: percent_of_previous
sql: ${count} ;;
}
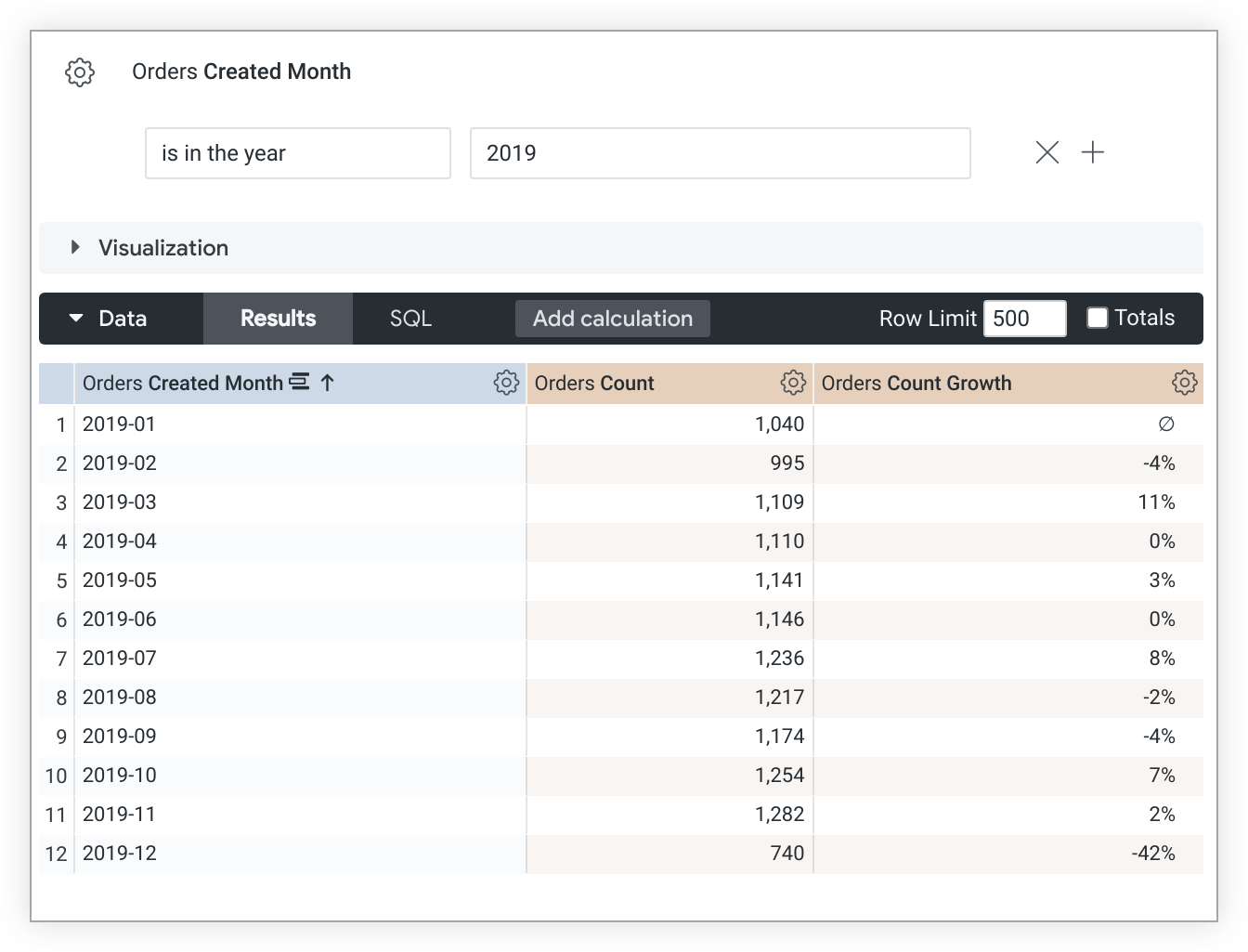
percent_of_previous の値は並べ替え順序によって異なります。ソートを変更した場合は、クエリを再実行して percent_of_previous の値を再計算する必要があります。クエリがピボットされている場合、percent_of_previous は列ではなく行全体で実行されます。この動作は変更できません。
また、percent_of_previous 指標は、データベースからデータが返された後に計算されます。つまり、percent_of_previous メジャーを別のメジャー内で参照しないでください。各メジャーの計算タイミングが異なり、正確な結果が得られない可能性があります。また、percent_of_previous メジャーはフィルタリングできません。
このタイプの指標の 1 つの用途は、期間比較(PoP)分析です。これは、現在の測定値を過去の同等の期間の同じ測定値と比較する分析パターンです。PoP の詳細については、Looker コミュニティの記事 期間比較分析を行う方法と Looker での期間比較(PoP)分析の方法をご覧ください。
percent_of_total
type: percent_of_total は、列の合計に対するセルの割合を計算します。計算される割合(%)は、クエリから返される行の合計に対するものであり、存在するすべての行の合計に対するものではありません。ただし、クエリから返されるデータが行数上限を超える場合、割合の合計を計算するために結果全体が必要になるため、フィールドの値は NULL で表示されます。
type: percent_of_total メジャーの sql パラメータは、別の数値メジャーを参照する必要があります。
type: percent_of_total フィールドは、value_format パラメータまたは value_format_name パラメータを使用して書式設定できます。ただし、value_format_name パラメータのパーセンテージ書式は type: percent_of_total 指標では機能しません。これらのパーセンテージ書式は値に 100 を乗算するものであり、percent_of_total 計算の結果を歪める原因となります。
この LookML の例では、total_gross_margin measure に基づく percent_of_total_gross_margin measure を作成します。
measure: percent_of_total_gross_margin {
type: percent_of_total
sql: ${total_gross_margin} ;;
}
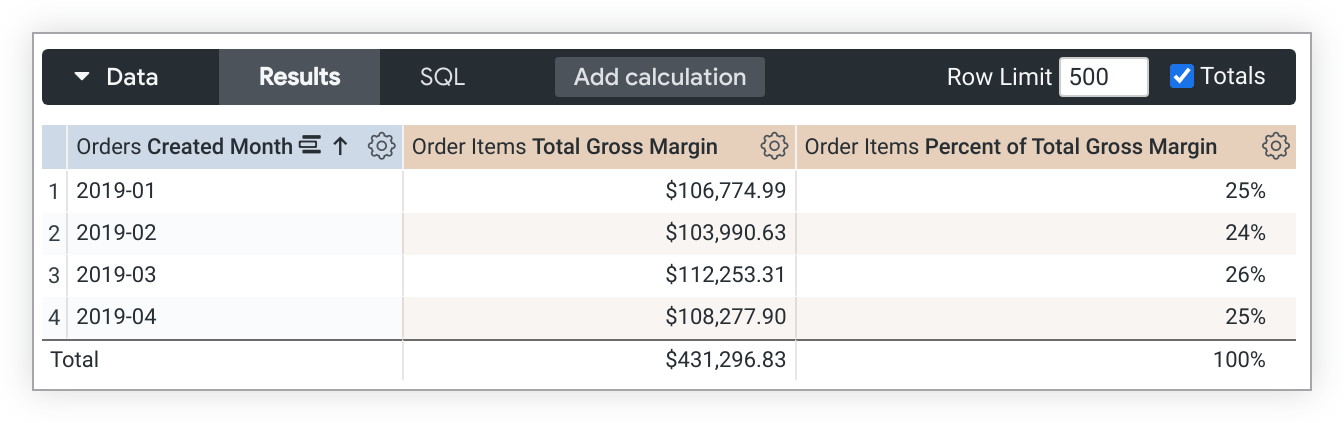
クエリがピボットされている場合、percent_of_total は列ではなく行全体で実行されます。この動作を望まない場合は、direction: "column" を指標の定義に追加します。
また、percent_of_total 指標は、データベースからデータが返された後に計算されます。つまり、percent_of_total メジャーを別のメジャー内で参照しないでください。各メジャーの計算タイミングが異なり、正確な結果が得られない可能性があります。また、percent_of_total メジャーはフィルタリングできません。
percentile
type: percentile は、指定されたフィールドの値の指定されたパーセンタイルの値を返します。例えば、75番目のパーセンタイルを指定した場合、データセット内の他の75%の値より大きい値が返されます。
返される値は、データ値の合計数を計算し、その数に指定パーセンタイルを乗算することによって識別されます。データの実際のソート方法に関係なく、データ値の昇順における相対順序が識別されます。返されるデータ値は、次の 2 つのセクションで説明するように、計算結果が整数になるかそうでないかに応じて変わります。
計算値が整数でない場合
返されるデータ値は、計算値の端数切り上げ後の値に基づいて特定されます。19 個のテストスコアのセットを扱うこの例では、75 番目のパーセンタイルは 19 * .75 = 14.25 によって識別されます。つまり、75% の値は、15 番目の位置より下位にある最初の 14 個のデータ値に含まれています。したがって、75%のデータ値より大きい15番目のデータ値(87)が返されます。

計算値が整数である場合
この場合はもう少し複雑で、当該位置のデータ値とその次のデータ値の平均が返されます。これを理解するために、20 個のテストスコアのセットを考えてみましょう。75 番目のパーセンタイルは 20 * 0.75 = 15 で識別されます。つまり、15 番目の位置にあるデータ値は 75 番目のパーセンタイルの一部であり、75% のデータ値よりも大きい値を返す必要があります。この 75% を保証するために、15 番目の位置の値(82)と 16 番目の位置の値(87)の平均が返されます。実際の平均(84.5)はデータ値のセットには存在しませんが、75%のデータ値より大きくなります。

必須パラメーターとオプションパラメーター
percentile: キーワードを使用して、戻り値より下にあるデータの割合を示す小数値を指定します。たとえば、percentile: 75 を使用してデータ順序で 75 番目のパーセンタイルの値を指定するか、percentile: 10 を使用して 10 番目のパーセンタイルの値を返します。50 番目のパーセンタイルの値を見つける場合は、percentile: 50 を指定するか、median 型を使用します。
type: percentile メジャーの sql パラメータには、数値テーブル列、LookML ディメンション、または LookML ディメンションの組み合わせをもたらす有効な SQL 式を指定できます。
type: percentile フィールドは、value_format パラメータまたは value_format_name パラメータを使用してフォーマットできます。
例
たとえば、次の LookML では、test_scores ディメンションの 75 番目のパーセンタイルの値を返す test_scores_75th_percentile というフィールドが作成されます。
measure: test_scores_75th_percentile {
type: percentile
percentile: 75
sql: ${TABLE}.test_scores ;;
}
percentile で考慮すべき事項
ファンアウトに関与するフィールドに percentile を使用している場合、Looker は代わりに percentile_distinct を使用しようとします。percentile_distinct が言語で使用できない場合、Looker はエラーを返します。詳細については、percentile_distinct でサポートされている言語をご覧ください。
percentile でサポートされているデータベース言語
Looker が Looker プロジェクトで percentile 型をサポートできるようにするには、データベース言語もそれをサポートしている必要があります。次の表に、Looker の最新リリースで percentile 型をサポートする言語を示します。
| 方言 | サポート対象 |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13+ | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |
percentile_distinct
type: percentile_distinct は percentile の特殊な形式であり、結合にファンアウトが伴う場合に使用する必要があります。sql_distinct_key パラメータで定義された一意の値に基づいて、指定されたフィールドの繰り返し以外の値を使用します。メジャーに sql_distinct_key パラメータがない場合、Looker は primary_key フィールドを使用しようとします。
注文品目テーブルと注文テーブルを結合した次のようなクエリ結果について考えます。
| Order Item ID | 注文 ID | 注文出荷 |
|---|---|---|
| 1 | 1 | 10 |
| 2 | 1 | 10 |
| 3 | 2 | 20 |
| 4 | 3 | 50 |
| 5 | 3 | 50 |
| 6 | 3 | 50 |
| 7 | 4 | 70 |
| 8 | 4 | 70 |
| 9 | 5 | 110 |
| 10 | 5 | 110 |
この状況では、各注文に複数の行が存在することがわかります。各注文はそれぞれ複数の注文品目に対応付けられているため、このクエリにはファンアウトが伴っています。percentile_distinct では、この点を考慮して個別値 10、20、50、70、110 を基にパーセンタイル値が検索されます。25番目のパーセンタイルを指定した場合は2番目の個別値(20)が返され、80番目のパーセンタイルを指定した場合は4番目と5番目の個別値の平均(90)が返されます。
必須パラメーターとオプションパラメーター
percentile: キーワードを使用して、小数値を指定します。たとえば、percentile: 75 を使用してデータの順序で 75 パーセンタイルの値を指定したり、percentile: 10 を使用して 10 パーセンタイルの値を返したりします。50 パーセンタイルの値を見つけようとしている場合は、代わりに median_distinct 型を使用できます。
正確な結果を得るには、sql_distinct_key パラメータを使用して、一意の各エンティティ(この例では一意の各注文)の識別方法を Looker に指定します。
次に、percentile_distinct を使用して 90 番目のパーセンタイルの値を返す例を示します。
measure: order_shipping_90th_percentile {
type: percentile_distinct
percentile: 90
sql_distinct_key: ${order_id} ;;
sql: ${order_shipping} ;;
}
sql_distinct_key の一意の値ごとに、メジャーの sql パラメータに対応する値が 1 つだけ存在する必要があります。つまり、前の例が機能するのは、order_id が 1 のすべての行の order_shipping が 10 であり、order_id が 2 のすべての行の order_shipping が 20 であるためです。
type: percentile_distinct フィールドは、value_format パラメータまたは value_format_name パラメータを使用してフォーマットできます。
percentile_distinct で考慮すべき事項
言語で percentile_distinct を使用できない場合、Looker はエラーを返します。詳細については、percentile_distinct でサポートされている言語をご覧ください。
percentile_distinct でサポートされているデータベース言語
Looker が Looker プロジェクトで percentile_distinct 型をサポートできるようにするには、データベース言語もそれをサポートしている必要があります。次の表に、Looker の最新リリースで percentile_distinct 型をサポートする言語を示します。
| 方言 | サポート対象 |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13+ | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |
period_over_period
期間比較の指標をサポートする言語では、type: period_over_period の LookML 指標を作成して、期間比較(PoP)の指標を作成できます。PoP 指標は、前の期間の集計を参照します。
前月の注文数を提供する PoP 指標の例を次に示します。
measure: orders_last_month {
type: period_over_period
based_on: orders.count
based_on_time: orders.created_month
period: month
kind: previous
}
type: period_over_period を含む指標には、次のサブパラメータも必要です。
詳細と例については、Looker の期間比較指標をご覧ください。
running_total
type: running_total は、列に沿ってセルの累積合計を計算します。ピボットの結果として行が処理される場合を除き、行方向で合計を計算することはできません。
type: running_total メジャーの sql パラメータは、別の数値メジャーを参照する必要があります。
type: running_total フィールドは、value_format パラメータまたは value_format_name パラメータを使用してフォーマットできます。
次の LookML の例では、total_sale_price 測定に基づいて cumulative_total_revenue 測定を作成します。
measure: cumulative_total_revenue {
type: running_total
sql: ${total_sale_price} ;;
value_format_name: usd
}
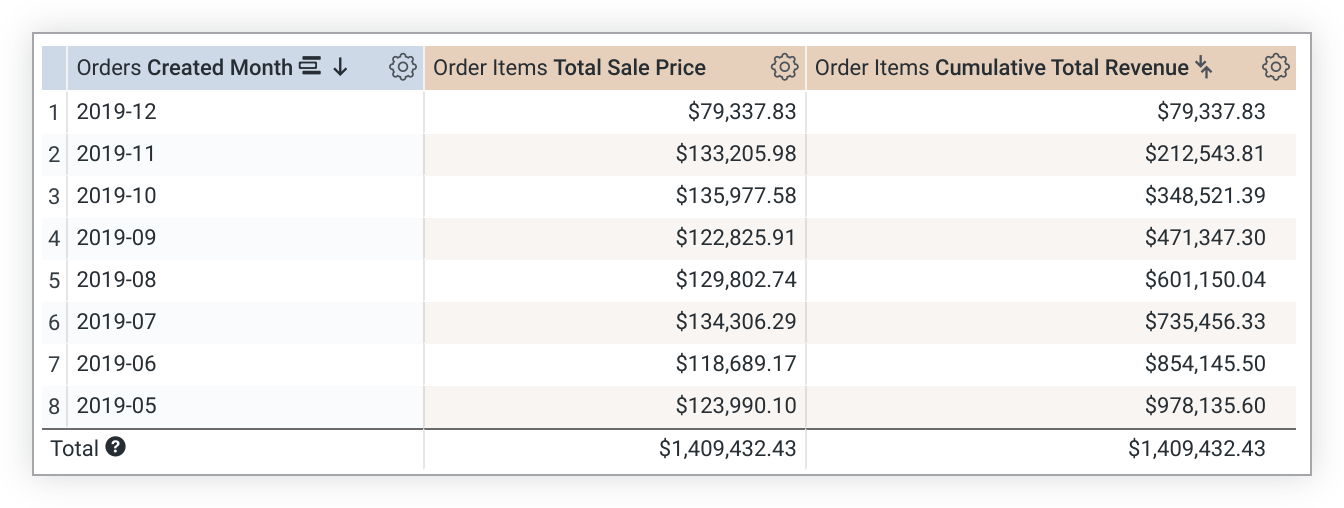
running_total の値は並べ替え順序によって異なります。並べ替えを変更した場合は、クエリを再実行して running_total の値を再計算する必要があります。クエリがピボットされている場合、running_total は列ではなく行に沿って実行されます。この動作を望まない場合は、測定値の定義に direction: "column" を追加します。
また、running_total 指標は、データベースからデータが返された後に計算されます。つまり、running_total メジャーを別のメジャー内で参照しないでください。各メジャーの計算タイミングが異なり、正確な結果が得られない可能性があります。また、running_total メジャーはフィルタリングできません。
string
type: string は、文字や特殊文字を含むフィールドとともに使用されます。
type: string 指標の sql パラメータには、文字列を返す任意の有効な SQL 式を指定できます。ストリングを返す SQL 集計関数はごくわずかであることから、このタイプを実際に使用することはほとんどありません。一般的な例外の 1 つは MySQL の GROUP_CONCAT 関数ですが、Looker には、このユースケースに対応する type: list が用意されています。
例えば、次の LookML では、category というフィールドの一意の値を組み合わせて category_list というフィールドが作成されます。
measure: category_list {
type: string
sql: GROUP_CONCAT(${category}) ;;
}
この例では、string が type のデフォルト値であるため、type: string を省略できます。
sum
type: sum は、指定されたフィールドの値を合計します。SQL の SUM 関数に似ています。ただし、生の SQL とは異なり、クエリの結合にファンアウトが含まれている場合でも、Looker は合計を適切に計算します。
type: sum メジャーの sql パラメータには、数値テーブル列、LookML ディメンション、または LookML ディメンションの組み合わせをもたらす有効な SQL 式を指定できます。
type: sum フィールドは、value_format パラメータまたは value_format_name パラメータを使用してフォーマットできます。
たとえば、次の LookML では、sales_price ディメンションを合計することで total_revenue というフィールドが作成され、これが金額書式($1,234.56)で表示されます。
measure: total_revenue {
type: sum
sql: ${sales_price} ;;
value_format_name: usd
}
sum_distinct
type: sum_distinct は、非正規化されたデータセットで使用します。sql_distinct_key パラメータで定義された一意の値に基づいて、指定されたフィールドの重複しない値を合計します。
これは高度な概念であるため、例を挙げてよりわかりやすく説明します。次のような非正規化テーブルについて考えます。
| Order Item ID | 注文 ID | 注文出荷 |
|---|---|---|
| 1 | 1 | 10.00 |
| 2 | 1 | 10.00 |
| 3 | 2 | 20.00 |
| 4 | 2 | 20.00 |
| 5 | 2 | 20.00 |
この状況では、各注文に複数の行が存在することがわかります。したがって、order_shipping 列に type: sum メジャーを追加すると、実際に徴収された送料の合計は 30.00 であるにもかかわらず、合計は 80.00 になります。
# Will NOT calculate the correct shipping amount
measure: total_shipping {
type: sum
sql: ${order_shipping} ;;
}
正確な結果を得るには、sql_distinct_key パラメータを使用して、一意の各エンティティ(この例では一意の各注文)の識別方法を Looker に定義します。これにより、正しい金額 30.00 が計算されます。
# Will calculate the correct shipping amount
measure: total_shipping {
type: sum_distinct
sql_distinct_key: ${order_id} ;;
sql: ${order_shipping} ;;
}
sql_distinct_key の一意の値ごとに、sql に対応する値が 1 つだけ存在する必要があります。つまり、order_id が 1 のすべての行の order_shipping が 10.00 で、order_id が 2 のすべての行の order_shipping が 20.00 であるため、上記の例は機能します。
type: sum_distinct フィールドは、value_format パラメータまたは value_format_name パラメータを使用してフォーマットできます。
yesno
type: yesno は、何かが真であるか偽であるかを示すフィールドを作成します。値は、Explore UI で [Yes] と [No] として表示されます。
type: yesno 指標の sql パラメータは、TRUE または FALSE に評価される有効な SQL 式を受け取ります。条件が TRUE に評価されると、ユーザーに [はい] が表示されます。それ以外の場合は、[いいえ] が表示されます。
type: yesno メジャーの SQL 式には、集計のみ(SQL 集計または LookML メジャーの参照)を含める必要があります。LookML ディメンションの参照または集計ではない SQL 式を含む yesno フィールドを作成する場合は、メジャーではなく type: yesno を使用してディメンションを使用します。
type: number を含むメジャーと同様に、type: yesno を含むメジャーは集計を行わず、他の集計を参照するだけです。
たとえば、次の total_sale_price メジャーの例は、注文内の注文アイテムの合計販売価格の合計です。is_large_total という 2 つ目のメジャーは type: yesno です。is_large_total メジャーには、total_sale_price の値が $1,000 より大きいかどうかを評価する sql パラメータがあります。
measure: total_sale_price {
type: sum
value_format_name: usd
sql: ${sale_price} ;;
drill_fields: [detail*]
}
measure: is_large_total {
description: "Is order total over $1000?"
type: yesno
sql: ${total_sale_price} > 1000 ;;
}
type: yesno フィールドを別のフィールドで参照する場合は、type: yesno フィールドをブール値として(つまり、true または false の値がすでに含まれているかのように)扱う必要があります。次に例を示します。
measure: is_large_total {
description: "Is order total over $1000?"
type: yesno
sql: ${total_sale_price} > 1000 ;;
}
# This is correct:
measure: reward_points {
type: number
sql: CASE WHEN ${is_large_total} THEN 200 ELSE 100 END ;;
}
# This is NOT correct:
measure: reward_points {
type: number
sql: CASE WHEN ${is_large_total} = 'Yes' THEN 200 ELSE 100 END ;;
}