
Auf dieser Seite wird auf den Parameter
typeverwiesen, der Teil eines Messwerts ist.
typekann auch als Teil einer Dimension oder eines Filters verwendet werden, wie auf der Dokumentationsseite Dimensionen, Filter und Parametertypen beschrieben.
typekann auch als Teil einer Dimensionsgruppe verwendet werden. Weitere Informationen finden Sie auf der Dokumentationsseite zum Parameterdimension_group.
Nutzung
view: view_name {
measure: field_name {
type: measure_field_type
}
}
|
Hierarchie
type |
Mögliche Feldtypen
Messen
Akzeptiert
Ein Ergebnistyp
|
Auf dieser Seite finden Sie Details zu den verschiedenen Typen, die einem Messwert zugewiesen werden können. Ein Messwert kann nur einen Typ haben. Wenn kein Typ angegeben ist, wird standardmäßig string verwendet.
Einige Messwerttypen haben unterstützende Parameter, die im entsprechenden Abschnitt beschrieben werden.
Kategorien von Measure-Typen
Jeder Messwerttyp fällt in eine der folgenden Kategorien. Diese Kategorien bestimmen, ob der Messwerttyp Aggregationen ausführt, auf welche Feldtypen er verweisen kann und ob Sie ihn mit dem Parameter filters filtern können:
- Aggregierte Messwerte: Bei aggregierten Messwerttypen werden Aggregationen wie
sumundaverageausgeführt. Aggregierte Messwerte können nur Dimensionen und keine anderen Messwerte referenzieren. Dies ist der einzige Messwerttyp, der mit dem Parameterfiltersfunktioniert. - Nicht aggregierte Messwerte: Wie der Name schon sagt, werden bei nicht aggregierten Messwerten keine Aggregationen ausgeführt, z. B. bei
numberundyesno. Bei diesen Messwerttypen werden grundlegende Transformationen ausgeführt. Da keine Aggregationen erfolgen, kann nur auf aggregierte Messwerte oder zuvor aggregierte Dimensionen verwiesen werden. Der Parameterfilterskann nicht mit diesen Messwerttypen verwendet werden. - Post-SQL-Messwerte: Post-SQL-Messwerte sind spezielle Messwerttypen, mit denen bestimmte Berechnungen ausgeführt werden, nachdem Looker die SQL-Abfrage generiert hat. Sie können nur numerische Messwerte oder numerische Dimensionen referenzieren. Der Parameter
filterskann nicht mit diesen Analysetypen verwendet werden.
Liste der Typdefinitionen
| Typ | Kategorie | Beschreibung |
|---|---|---|
average |
Aggregat | Berechnet den Durchschnitt (Mittelwert) der Werte in einer Spalte. |
average_distinct |
Aggregat | Generiert einen Durchschnitt (Mittelwert) von Werten, wenn denormalisierte Daten verwendet werden. Eine vollständige Beschreibung finden Sie im Abschnitt average_distinct. |
count |
Aggregat | Anzahl der Zeilen wird generiert |
count_distinct |
Aggregat | Gibt die Anzahl der eindeutigen Werte in einer Spalte zurück |
date |
Nicht aggregiert | Für Messungen mit Datumsangaben |
list |
Aggregat | Erstellt eine Liste der eindeutigen Werte in einer Spalte |
max |
Aggregat | Generiert den Maximalwert in einer Spalte. |
median |
Aggregat | Generiert den Median (Mittelwert) der Werte in einer Spalte. |
median_distinct |
Aggregat | Generiert einen korrekten Median (Mittelwert) der Werte, wenn durch einen Join ein Fanout verursacht wird. Eine vollständige Beschreibung finden Sie im Abschnitt median_distinct. |
min |
Aggregat | Gibt den Minimalwert in einer Spalte zurück. |
number |
Nicht aggregiert | Für Messungen, die Zahlen enthalten |
percent_of_previous |
Post-SQL | Berechnet den prozentualen Unterschied zwischen den angezeigten Zeilen. |
percent_of_total |
Post-SQL | Generiert den Prozentsatz des Gesamtwerts für jede angezeigte Zeile. |
percentile |
Aggregat | Gibt den Wert am angegebenen Perzentil innerhalb einer Spalte zurück |
percentile_distinct |
Aggregat | Generiert den Wert am angegebenen Perzentil korrekt, wenn ein Join einen Fanout verursacht. Eine vollständige Beschreibung finden Sie im Abschnitt percentile_distinct. |
running_total |
Post-SQL | Generiert die laufende Summe für jede angezeigte Zeile. |
period_over_period |
Aggregat | Bezieht sich auf eine Aggregation aus einem früheren Zeitraum |
string |
Nicht aggregiert | Für Messwerte, die Buchstaben oder Sonderzeichen enthalten (wie bei der GROUP_CONCAT-Funktion von MySQL) |
sum |
Aggregat | Summe der Werte in einer Spalte berechnen |
sum_distinct |
Aggregat | Summiert Werte bei Verwendung denormalisierter Daten korrekt.Eine vollständige Beschreibung finden Sie im Abschnitt sum_distinct. |
yesno |
Nicht aggregiert | Für Felder, in denen angezeigt wird, ob etwas wahr oder falsch ist |
int |
Nicht aggregiert |
Entfernt 5.4
Ersetzt durch type: number |
average
Mit type: average werden die Werte in einem bestimmten Feld gemittelt. Sie ähnelt der SQL-Funktion AVG. Anders als bei rohem SQL berechnet Looker jedoch Durchschnittswerte richtig, auch wenn die Joins Ihrer Abfrage Fanouts enthalten.
Der Parameter sql für type: average-Messwerte kann einen beliebigen gültigen SQL-Ausdruck enthalten, der zu einer numerischen Tabellenspalte, einer LookML-Dimension oder einer Kombination aus LookML-Dimensionen führt.
type: average-Felder können mit den Parametern value_format oder value_format_name formatiert werden.
Mit dem folgenden LookML-Code wird beispielsweise ein Feld namens avg_order erstellt, indem der Durchschnitt der Dimension sales_price berechnet wird. Anschließend wird es im Währungsformat ($1.234,56) angezeigt:
measure: avg_order {
type: average
sql: ${sales_price} ;;
value_format_name: usd
}
average_distinct
type: average_distinct wird für denormalisierte Datasets verwendet. Dabei werden die nicht wiederholten Werte in einem bestimmten Feld auf Grundlage der eindeutigen Werte gemittelt, die durch den Parameter sql_distinct_key definiert werden.
Dies ist ein komplexes Konzept, das sich anhand eines Beispiels besser veranschaulichen lässt. Betrachten Sie eine denormalisierte Tabelle wie diese:
| Artikel-ID der Bestellung | Bestell-ID | Versand von Bestellungen |
|---|---|---|
| 1 | 1 | 10,00 |
| 2 | 1 | 10,00 |
| 3 | 2 | 20,00 |
| 4 | 2 | 20,00 |
| 5 | 2 | 20,00 |
In diesem Fall sehen Sie, dass für jeden Auftrag mehrere Zeilen vorhanden sind. Wenn Sie also einen einfachen type: average-Messwert für die Spalte order_shipping hinzufügen, erhalten Sie den Wert 16,00, obwohl der tatsächliche Durchschnitt 15,00 ist.
# Will NOT calculate the correct average
measure: avg_shipping {
type: average
sql: ${order_shipping} ;;
}
Damit Sie ein genaues Ergebnis erhalten, können Sie in Looker mit dem Parameter sql_distinct_key definieren, wie jede eindeutige Einheit (in diesem Fall jede eindeutige Bestellung) identifiziert werden soll. Damit wird der richtige Betrag von 15,00 € berechnet:
# Will calculate the correct average
measure: avg_shipping {
type: average_distinct
sql_distinct_key: ${order_id} ;;
sql: ${order_shipping} ;;
}
Jeder eindeutige Wert von sql_distinct_key muss genau einen entsprechenden Wert in sql haben. Das obige Beispiel funktioniert, weil jede Zeile mit einem order_id von 1 denselben order_shipping von 10,00 hat und jede Zeile mit einem order_id von 2 denselben order_shipping von 20,00 hat.
type: average_distinct-Felder können mit den Parametern value_format oder value_format_name formatiert werden.
count
Mit type: count wird eine Tabellenzählung durchgeführt, ähnlich wie mit der SQL-Funktion COUNT. Im Gegensatz zu Raw-SQL berechnet Looker die Anzahl jedoch auch dann richtig, wenn die Joins Ihrer Abfrage Fanouts enthalten.
Bei type: count-Messungen werden Tabellenzählungen auf Grundlage des Primärschlüssels der Tabelle durchgeführt. Daher wird der Parameter sql bei type: count-Messungen nicht unterstützt.
Wenn Sie eine Tabellenzählung für ein anderes Feld als den Primärschlüssel der Tabelle durchführen möchten, verwenden Sie eine type: count_distinct-Messung. Wenn Sie count_distinct nicht verwenden möchten, können Sie auch type: number verwenden. Weitere Informationen finden Sie im Community-Beitrag How to count a non-primary key.
Mit dem folgenden LookML-Code wird beispielsweise das Feld number_of_products erstellt:
view: products {
measure: number_of_products {
type: count
drill_fields: [product_details*] # optional
}
}
Es ist sehr üblich, beim Definieren eines type: count-Messwerts einen drill_fields-Parameter (für Felder) anzugeben, damit Nutzer die einzelnen Datensätze sehen können, aus denen eine Anzahl besteht, wenn sie darauf klicken.
Wenn Sie in einem Explore den Messwert
type: countverwenden, werden die resultierenden Werte in der Visualisierung mit dem Namen der Ansicht anstelle des Worts „Anzahl“ gekennzeichnet. Um Verwirrung zu vermeiden, empfehlen wir, den Namen der Ansicht im Plural zu verwenden, in den Visualisierungseinstellungen unter Serien die Option Vollständigen Feldnamen anzeigen auszuwählen oder einenview_labelmit einer Pluralversion des Namens der Ansicht zu verwenden.
Mit dem Parameter filters können Sie einem Messwert von type: count einen Filter hinzufügen.
count_distinct
type: count_distinct berechnet die Anzahl der eindeutigen Werte in einem bestimmten Feld. Dabei wird die SQL-Funktion COUNT DISTINCT verwendet.
Der Parameter sql für type: count_distinct-Messwerte kann einen beliebigen gültigen SQL-Ausdruck enthalten, der zu einer Tabellenspalte, einer LookML-Dimension oder einer Kombination aus LookML-Dimensionen führt.
Mit dem folgenden LookML-Code wird beispielsweise das Feld number_of_unique_customers erstellt, in dem die Anzahl der eindeutigen Kunden-IDs gezählt wird:
measure: number_of_unique_customers {
type: count_distinct
sql: ${customer_id} ;;
}
Mit dem Parameter filters können Sie einem Messwert von type: count_distinct einen Filter hinzufügen.
date
type: date wird mit Feldern verwendet, die Datumsangaben enthalten.
Der Parameter sql für type: date-Messwerte kann einen beliebigen gültigen SQL-Ausdruck enthalten, der ein Datum zurückgibt. In der Praxis wird dieser Typ selten verwendet, da die meisten SQL-Aggregatfunktionen keine Datumsangaben zurückgeben. Eine häufige Ausnahme ist ein MIN oder MAX einer Datumsdimension.
Measure für das maximale oder minimale Datum mit type: date erstellen
Wenn Sie einen Messwert für ein maximales oder minimales Datum erstellen möchten, denken Sie vielleicht zuerst, dass ein Messwert vom Typ type: max oder type: min funktionieren würde. Diese Messwerttypen sind jedoch nur mit numerischen Feldern kompatibel. Stattdessen können Sie ein maximales oder minimales Datum erfassen, indem Sie einen Messwert vom Typ type: date definieren und das Datumsfeld, auf das im Parameter sql verwiesen wird, in eine MIN()- oder MAX()-Funktion einfügen.
Angenommen, Sie haben eine Dimensionsgruppe vom Typ type: time mit dem Namen updated:
dimension_group: updated {
type: time
timeframes: [time, date, week, month, raw]
sql: ${TABLE}.updated_at ;;
}
Sie können einen Messwert für type: date erstellen, um das maximale Datum dieser Dimensionsgruppe zu erfassen. Gehen Sie dazu so vor:
measure: last_updated_date {
type: date
sql: MAX(${updated_raw}) ;;
convert_tz: no
}
In diesem Beispiel wird anstelle einer type: max-Messung zum Erstellen der last_updated_date-Messung die MAX()-Funktion im sql-Parameter angewendet. Für den Messwert last_updated_date ist der Parameter convert_tz auf no festgelegt, um eine doppelte Zeitzonenkonvertierung im Messwert zu verhindern, da die Zeitzonenkonvertierung bereits in der Definition der Dimensionsgruppe updated erfolgt ist. Weitere Informationen finden Sie in der Dokumentation zum Parameter convert_tz.
Im Beispiel-LookML für die Messung last_updated_date könnte type: date weggelassen werden. Der Wert würde dann als String behandelt, da string der Standardwert für type ist. Wenn Sie type: date verwenden, erhalten Sie jedoch bessere Filterfunktionen für Nutzer.
Möglicherweise stellen Sie auch fest, dass in der Messwertdefinition für last_updated_date auf den Zeitraum ${updated_raw} anstelle des Zeitraums ${updated_date} verwiesen wird. Da der von ${updated_date} zurückgegebene Wert ein String ist, muss stattdessen ${updated_raw} verwendet werden, um auf den tatsächlichen Datumswert zu verweisen.
Sie können den Parameter datatype auch mit type: date verwenden, um die Abfrageleistung zu verbessern, indem Sie den Typ der Datumsdaten angeben, die in Ihrer Datenbanktabelle verwendet werden.
Maximal- oder Minimalmesswert für eine Spalte mit Datums-/Uhrzeitangaben erstellen
Die Berechnung des Maximums für eine type: datetime-Spalte ist etwas anders. In diesem Fall möchten Sie ein Maß ohne Typdeklaration erstellen, etwa so:
measure: last_updated_datetime {
sql: MAX(${TABLE}.datetime_string_field) ;;
}
list
Mit type: list wird eine Liste der eindeutigen Werte in einem bestimmten Feld erstellt. Sie ähnelt der MySQL-Funktion GROUP_CONCAT.
Sie müssen keinen sql-Parameter für type: list-Messungen angeben. Stattdessen können Sie mit dem Parameter list_field die Dimension angeben, aus der Sie Listen erstellen möchten.
Die Verwendung ist wie folgt:
view: view_name {
measure: field_name {
type: list
list_field: my_field_name
}
}
Mit dem folgenden LookML wird beispielsweise der Messwert name_list auf Grundlage der Dimension name erstellt:
measure: name_list {
type: list
list_field: name
}
Beachten Sie für list Folgendes:
- Der Messwerttyp
listunterstützt keine Filterung. Sie können den Parameterfiltersnicht für einen Messwert vom Typtype: listverwenden. - Auf den
listMeasure-Typ kann nicht mit dem Substitutionsoperator ($) verwiesen werden. Sie können die${}-Syntax nicht verwenden, um auf einentype: listMeasure zu verweisen.
Unterstützte Datenbankdialekte für list
Damit Looker type: list in Ihrem Looker-Projekt unterstützen kann, muss diese Funktion auch von Ihrem Datenbankdialekt unterstützt werden. In der folgenden Tabelle ist zu sehen, welche Dialekte type: list in der aktuellen Version von Looker unterstützen:
| Dialekt | Unterstützt? |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13+ | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |
max
type: max ermittelt den größten Wert in einem bestimmten Feld. Dazu wird die SQL-Funktion MAX verwendet.
Der Parameter sql für Messwerte vom Typ type: max kann einen beliebigen gültigen SQL-Ausdruck enthalten, der zu einer numerischen Tabellenspalte, einer LookML-Dimension oder einer Kombination aus LookML-Dimensionen führt.
Da Messwerte vom Typ type: max nur mit numerischen Feldern kompatibel sind, können Sie keinen Messwert vom Typ type: max verwenden, um ein maximales Datum zu ermitteln. Stattdessen können Sie die Funktion MAX() im Parameter sql einer Messung vom Typ type: date verwenden, um ein maximales Datum zu erfassen, wie bereits in den Beispielen im Abschnitt date gezeigt.
type: max-Felder können mit den Parametern value_format oder value_format_name formatiert werden.
Mit dem folgenden LookML wird beispielsweise ein Feld namens largest_order erstellt, indem die Dimension sales_price betrachtet und dann im Geldformat ($1.234,56) angezeigt wird:
measure: largest_order {
type: max
sql: ${sales_price} ;;
value_format_name: usd
}
type: max-Messwerte können nicht für Strings oder Datumsangaben verwendet werden. Sie können die MAX-Funktion aber manuell hinzufügen, um ein entsprechendes Feld zu erstellen, z. B. so:
measure: latest_name_in_alphabet {
type: string
sql: MAX(${name}) ;;
}
median
type: median gibt den Mittelwert für die Werte in einem bestimmten Feld zurück. Das ist besonders nützlich, wenn die Daten einige sehr große oder kleine Ausreißerwerte enthalten, die einen einfachen Durchschnitt (Mittelwert) der Daten verzerren würden.
Nehmen wir an, Sie haben eine Tabelle wie diese:
| Artikel-ID der Bestellung | Kosten | Mittelpunkt? |
|---|---|---|
| 2 | 10,00 | |
| 4 | 10,00 | |
| 3 | 20,00 | Mittelwert |
| 1 | 80,00 | |
| 5 | 90,00 |
Die Tabelle ist nach Kosten sortiert, was sich jedoch nicht auf das Ergebnis auswirkt. Während der Typ average den Wert 42 zurückgeben würde (alle Werte addieren und durch 5 dividieren), würde der Typ median den Mittelwert zurückgeben: 20,00.
Bei einer geraden Anzahl von Werten wird der Medianwert berechnet, indem der Mittelwert der beiden Werte ermittelt wird, die dem Mittelpunkt am nächsten sind. Nehmen wir eine Tabelle mit einer geraden Anzahl von Zeilen:
| Artikel-ID der Bestellung | Kosten | Mittelpunkt? |
|---|---|---|
| 2 | 10 | |
| 3 | 20 | Am nächsten vor der Routenhälfte |
| 1 | 80 | Am nächsten nach der Routenhälfte |
| 4 | 90 |
Der Medianwert, also der Wert, der in der Mitte der Datenverteilung liegt, beträgt (20 + 80)/2 = 50.
Der Median entspricht auch dem Wert im 50. Perzentil.
Der Parameter sql für type: median-Messwerte kann einen beliebigen gültigen SQL-Ausdruck enthalten, der zu einer numerischen Tabellenspalte, einer LookML-Dimension oder einer Kombination aus LookML-Dimensionen führt.
type: median-Felder können mit den Parametern value_format oder value_format_name formatiert werden.
Beispiel
Mit dem folgenden LookML-Code wird beispielsweise ein Feld namens median_order erstellt, indem der Durchschnitt der Dimension sales_price berechnet wird. Anschließend wird es im Währungsformat ($1.234,56) angezeigt:
measure: median_order {
type: median
sql: ${sales_price} ;;
value_format_name: usd
}
Wichtige Punkte für median
Wenn Sie median für ein Feld verwenden, das in einem Fanout enthalten ist, versucht Looker stattdessen, median_distinct zu verwenden. medium_distinct wird jedoch nur für bestimmte Dialekte unterstützt. Wenn median_distinct für Ihren Dialekt nicht verfügbar ist, gibt Looker einen Fehler zurück. Da median als 50. Perzentil betrachtet werden kann, besagt der Fehler, dass der Dialekt keine unterschiedlichen Perzentile unterstützt.
Unterstützte Datenbankdialekte für median
Damit Looker den Typ median in Ihrem Looker-Projekt unterstützen kann, muss er auch von Ihrem Datenbankdialekt unterstützt werden. In der folgenden Tabelle sehen Sie, welche Dialekte den Typ median in der aktuellen Version von Looker unterstützen:
| Dialekt | Unterstützt? |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13+ | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |
Wenn eine Fanout-Operation in einer Abfrage enthalten ist, versucht Looker, median in median_distinct zu konvertieren. Das funktioniert nur in Dialekten, die median_distinct unterstützen.
median_distinct
Verwenden Sie type: median_distinct, wenn Ihr Join einen Fanout umfasst. Es wird der Durchschnitt der nicht wiederholten Werte in einem bestimmten Feld berechnet, basierend auf den eindeutigen Werten, die durch den Parameter sql_distinct_key definiert werden. Wenn die Messung keinen sql_distinct_key-Parameter hat, versucht Looker, das Feld primary_key zu verwenden.
Sehen Sie sich das Ergebnis einer Abfrage an, bei der die Tabellen „Order Item“ und „Order“ zusammengeführt werden:
| Artikel-ID der Bestellung | Bestell-ID | Versand von Bestellungen |
|---|---|---|
| 1 | 1 | 10 |
| 2 | 1 | 10 |
| 3 | 2 | 20 |
| 4 | 3 | 50 |
| 5 | 3 | 50 |
| 6 | 3 | 50 |
In diesem Fall sehen Sie, dass für jeden Auftrag mehrere Zeilen vorhanden sind. Diese Abfrage umfasste einen Fanout, da jede Bestellung mehreren Bestellpositionen zugeordnet ist. Bei median_distinct wird dies berücksichtigt und der Median zwischen den eindeutigen Werten 10, 20 und 50 ermittelt. Das Ergebnis ist also 20.
Damit Sie ein genaues Ergebnis erhalten, können Sie in Looker mit dem Parameter sql_distinct_key definieren, wie jede eindeutige Einheit (in diesem Fall jede eindeutige Bestellung) identifiziert werden soll. So wird der richtige Betrag berechnet:
measure: median_shipping {
type: median_distinct
sql_distinct_key: ${order_id} ;;
sql: ${order_shipping} ;;
}
Jeder eindeutige Wert von sql_distinct_key muss genau einen entsprechenden Wert im Parameter sql des Messwerts haben. Das vorherige Beispiel funktioniert also, weil jede Zeile mit dem Wert 1 für order_id denselben Wert 10 für order_shipping hat und jede Zeile mit dem Wert 2 für order_id denselben Wert 20 für order_shipping hat.
type: median_distinct-Felder können mit den Parametern value_format oder value_format_name formatiert werden.
Wichtige Punkte für median_distinct
Der Messwerttyp medium_distinct wird nur für bestimmte Dialekte unterstützt. Wenn median_distinct für den Dialekt nicht verfügbar ist, gibt Looker einen Fehler zurück. Da median als 50. Perzentil betrachtet werden kann, wird im Fehler angegeben, dass der Dialekt keine eindeutigen Perzentile unterstützt.
Unterstützte Datenbankdialekte für median_distinct
Damit Looker den Typ median_distinct in Ihrem Looker-Projekt unterstützen kann, muss er auch von Ihrem Datenbankdialekt unterstützt werden. In der folgenden Tabelle sehen Sie, welche Dialekte den Typ median_distinct in der aktuellen Version von Looker unterstützen:
| Dialekt | Unterstützt? |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13+ | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |
min
Mit type: min wird der kleinste Wert in einem bestimmten Feld ermittelt. Dabei wird die SQL-Funktion MIN verwendet.
Der Parameter sql für Messwerte vom Typ type: min kann einen beliebigen gültigen SQL-Ausdruck enthalten, der zu einer numerischen Tabellenspalte, einer LookML-Dimension oder einer Kombination aus LookML-Dimensionen führt.
Da Messwerte vom Typ type: min nur mit numerischen Feldern kompatibel sind, können Sie keinen Messwert vom Typ type: min verwenden, um ein Mindestdatum zu ermitteln. Stattdessen können Sie die Funktion MIN() im Parameter sql einer Messung vom Typ type: date verwenden, um ein Minimum zu erfassen. Genauso können Sie die Funktion MAX() mit einer Messung vom Typ type: date verwenden, um ein maximales Datum zu erfassen. Das wurde bereits weiter oben auf dieser Seite im Abschnitt date gezeigt. Dort finden Sie Beispiele für die Verwendung der Funktion MAX() im Parameter sql, um ein maximales Datum zu ermitteln.
type: min-Felder können mit den Parametern value_format oder value_format_name formatiert werden.
Mit dem folgenden LookML wird beispielsweise ein Feld namens smallest_order erstellt, indem die Dimension sales_price betrachtet und dann im Geldformat ($1.234,56) angezeigt wird:
measure: smallest_order {
type: min
sql: ${sales_price} ;;
value_format_name: usd
}
type: min-Messwerte können nicht für Strings oder Datumsangaben verwendet werden. Sie können die MIN-Funktion aber manuell hinzufügen, um ein entsprechendes Feld zu erstellen, z. B. so:
measure: earliest_name_in_alphabet {
type: string
sql: MIN(${name}) ;;
}
number
type: number wird mit Zahlen oder Ganzzahlen verwendet. Bei einem Messwert vom Typ type: number erfolgt keine Aggregation. Er ist für die Durchführung einfacher Transformationen anderer Messwerte vorgesehen. Wenn Sie einen Messwert definieren, der auf einem anderen Messwert basiert, muss der neue Messwert vom Typ type: number sein, um Fehler bei der verschachtelten Aggregation zu vermeiden.
Für den Parameter sql für type: number-Messungen kann ein beliebiger gültiger SQL-Ausdruck verwendet werden, der zu einer Zahl oder einer Ganzzahl führt.
type: number-Felder können mit den Parametern value_format oder value_format_name formatiert werden.
Mit dem folgenden LookML-Code wird beispielsweise ein Messwert namens total_gross_margin_percentage auf Grundlage der aggregierten Messwerte total_sale_price und total_gross_margin erstellt und dann im Prozentformat mit zwei Dezimalstellen (12,34%) angezeigt:
measure: total_sale_price {
type: sum
value_format_name: usd
sql: ${sale_price} ;;
}
measure: total_gross_margin {
type: sum
value_format_name: usd
sql: ${gross_margin} ;;
}
measure: total_gross_margin_percentage {
type: number
value_format_name: percent_2
sql: ${total_gross_margin}/ NULLIF(${total_sale_price},0) ;;
}
In diesem Beispiel wird auch die SQL-Funktion NULLIF() verwendet, um die Möglichkeit von Division-durch-null-Fehlern zu vermeiden.
Wichtige Punkte für type: number
Bei der Verwendung von type: number-Messwerten sind einige wichtige Aspekte zu beachten:
- Bei einem Messwert vom Typ
type: numberkönnen nur arithmetische Operationen mit anderen Messwerten, nicht aber mit anderen Dimensionen ausgeführt werden. - Die symmetrischen Summen von Looker schützen Aggregatfunktionen im SQL einer Messung
type: numbernicht, wenn sie über einen Join hinweg berechnet werden. - Der Parameter
filterskann nicht mittype: number-Messungen verwendet werden. In der Dokumentation zufilterswird jedoch eine Problemumgehung beschrieben. - Bei
type: number-Messungen werden Nutzern keine Vorschläge angezeigt.
percent_of_previous
Mit type: percent_of_previous wird die prozentuale Differenz zwischen einer Zelle und der vorherigen Zelle in ihrer Spalte berechnet.
Der Parameter sql für type: percent_of_previous-Messungen muss auf einen anderen numerischen Messwert verweisen.
type: percent_of_previous-Felder können mit den Parametern value_format oder value_format_name formatiert werden. Die Prozentformate des Parameters value_format_name funktionieren jedoch nicht mit type: percent_of_previous-Messwerten. Bei diesen Prozentformaten werden Werte mit 100 multipliziert, was die Ergebnisse einer Berechnung des Prozentsatzes des vorherigen Werts verfälscht.
Mit diesem Beispiel-LookML wird ein count_growth-Messwert erstellt, der auf dem count-Messwert basiert:
measure: count_growth {
type: percent_of_previous
sql: ${count} ;;
}
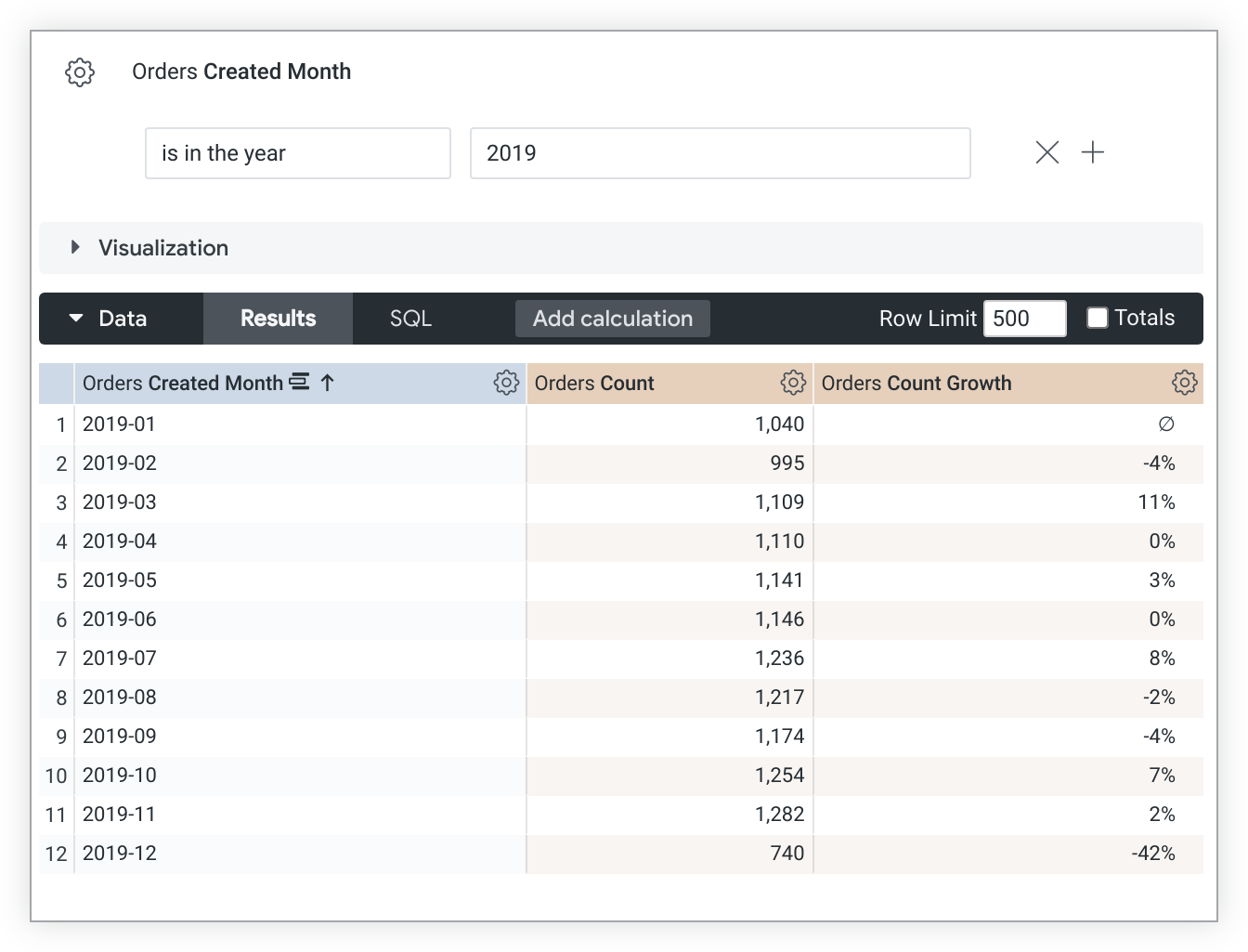
Die Werte für percent_of_previous hängen von der Sortierreihenfolge ab. Wenn Sie die Sortierung ändern, müssen Sie die Abfrage noch einmal ausführen, um die percent_of_previous-Werte neu zu berechnen. Wenn eine Abfrage pivotiert wird, wird percent_of_previous über die Zeile anstatt über die Spalte ausgeführt. Dieses Verhalten kann nicht geändert werden.
Außerdem werden percent_of_previous-Messwerte nach dem Abrufen von Daten aus Ihrer Datenbank berechnet. Das bedeutet, dass Sie nicht in einem anderen Messwert auf einen percent_of_previous-Messwert verweisen sollten, da die Messwerte möglicherweise zu unterschiedlichen Zeiten berechnet werden und Sie daher keine genauen Ergebnisse erhalten. Das bedeutet auch, dass percent_of_previous-Messwerte nicht gefiltert werden können.
Eine Anwendung für diese Art von Messung ist die Analyse von Zeitraum zu Zeitraum, bei der etwas in der Gegenwart gemessen und mit derselben Messung in einem vergleichbaren Zeitraum in der Vergangenheit verglichen wird. Weitere Informationen zu PoP finden Sie in den Looker Community-Artikeln How to do Period-over-Period Analysis und Methods for Period Over Period (PoP) Analysis in Looker.
percent_of_total
Mit type: percent_of_total wird der Anteil einer Zelle an der Spaltensumme berechnet. Der Prozentsatz wird anhand der Gesamtzahl der von Ihrer Abfrage zurückgegebenen Zeilen und nicht anhand der Gesamtzahl aller möglichen Zeilen berechnet. Wenn die von Ihrer Abfrage zurückgegebenen Daten jedoch ein Zeilenlimit überschreiten, werden die Werte des Felds als „null“ angezeigt, da für die Berechnung des Prozentsatzes des Gesamtwerts die vollständigen Ergebnisse erforderlich sind.
Der Parameter sql für type: percent_of_total-Messungen muss auf einen anderen numerischen Messwert verweisen.
type: percent_of_total-Felder können mit den Parametern value_format oder value_format_name formatiert werden. Die Prozentformate des Parameters value_format_name funktionieren jedoch nicht mit type: percent_of_total-Messwerten. Bei diesen Prozentformaten werden Werte mit 100 multipliziert, was die Ergebnisse einer percent_of_total-Berechnung verfälscht.
Mit diesem Beispiel-LookML wird ein percent_of_total_gross_margin-Messwert erstellt, der auf dem total_gross_margin-Messwert basiert:
measure: percent_of_total_gross_margin {
type: percent_of_total
sql: ${total_gross_margin} ;;
}
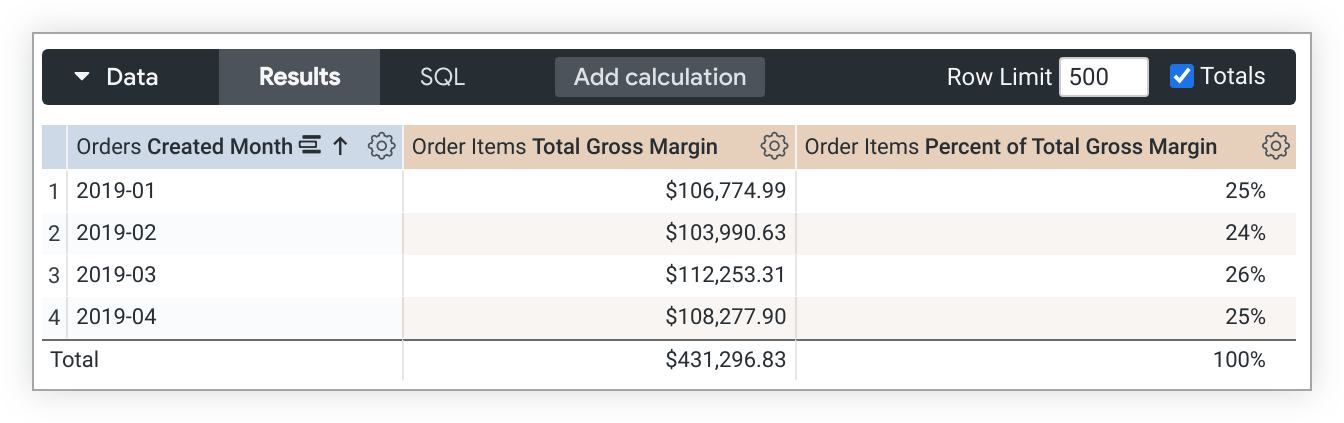
Wenn eine Abfrage pivotiert wird, wird percent_of_total über die Zeile statt über die Spalte ausgeführt. Wenn das nicht gewünscht ist, fügen Sie der Messwertdefinition direction: "column" hinzu.
Außerdem werden percent_of_total-Messwerte nach dem Abrufen von Daten aus Ihrer Datenbank berechnet. Das bedeutet, dass Sie nicht in einem anderen Messwert auf einen percent_of_total-Messwert verweisen sollten, da die Messwerte möglicherweise zu unterschiedlichen Zeiten berechnet werden und Sie daher keine genauen Ergebnisse erhalten. Das bedeutet auch, dass percent_of_total-Messwerte nicht gefiltert werden können.
percentile
type: percentile gibt den Wert beim angegebenen Perzentil der Werte in einem bestimmten Feld zurück. Wenn Sie beispielsweise das 75. Perzentil angeben, wird der Wert zurückgegeben, der größer als 75% der anderen Werte im Datensatz ist.
Um den zurückzugebenden Wert zu ermitteln, berechnet Looker die Gesamtzahl der Datenwerte und multipliziert das angegebene Perzentil mit der Gesamtzahl der Datenwerte. Unabhängig davon, wie die Daten tatsächlich sortiert werden, ermittelt Looker die relative Reihenfolge der Datenwerte in aufsteigender Reihenfolge. Der von Looker zurückgegebene Datenwert hängt davon ab, ob die Berechnung eine Ganzzahl ergibt oder nicht. Das wird in den folgenden beiden Abschnitten erläutert.
Wenn der berechnete Wert keine Ganzzahl ist
Looker rundet den berechneten Wert auf und verwendet ihn, um den zurückzugebenden Datenwert zu ermitteln. In diesem Beispiel mit 19 Testergebnissen wird das 75. Perzentil durch 19 * 0,75 = 14,25 ermittelt. Das bedeutet, dass 75% der Werte in den ersten 14 Datenwerten liegen – unter der 15. Position. Daher gibt Looker den 15. Datenwert (87) zurück, da er größer als 75% der Datenwerte ist.

Wenn der berechnete Wert eine Ganzzahl ist
In diesem etwas komplexeren Fall gibt Looker einen Durchschnitt des Datenwerts an dieser Position und des folgenden Datenwerts zurück. Sehen wir uns dazu eine Reihe von 20 Testergebnissen an: Das 75. Perzentil wird durch 20 * 0, 75 = 15 ermittelt. Das bedeutet, dass der Datenwert an der 15. Position zum 75. Perzentil gehört und wir einen Wert zurückgeben müssen, der höher als 75% der Datenwerte ist. Indem der Durchschnitt der Werte an der 15. Position (82) und der 16. Position (87) zurückgegeben wird, wird sichergestellt, dass 75%. Dieser Durchschnittswert (84,5) ist nicht in der Menge der Datenwerte enthalten, wäre aber größer als 75% der Datenwerte.

Erforderliche und optionale Parameter
Mit dem Keyword percentile: geben Sie den Bruchwert an, d. h. den Prozentsatz der Daten, der unter dem zurückgegebenen Wert liegen soll. Mit percentile: 75 geben Sie beispielsweise den Wert am 75. Perzentil in der Reihenfolge der Daten an und mit percentile: 10 den Wert am 10. Perzentil. Wenn Sie den Wert am 50. Perzentil ermitteln möchten, können Sie percentile: 50 angeben oder einfach den Typ median verwenden.
Der Parameter sql für type: percentile-Messwerte kann einen beliebigen gültigen SQL-Ausdruck enthalten, der zu einer numerischen Tabellenspalte, einer LookML-Dimension oder einer Kombination aus LookML-Dimensionen führt.
type: percentile-Felder können mit den Parametern value_format oder value_format_name formatiert werden.
Beispiel
Mit dem folgenden LookML-Code wird beispielsweise ein Feld namens test_scores_75th_percentile erstellt, das den Wert am 75. Perzentil in der Dimension test_scores zurückgibt:
measure: test_scores_75th_percentile {
type: percentile
percentile: 75
sql: ${TABLE}.test_scores ;;
}
Wichtige Punkte für percentile
Wenn Sie percentile für ein Feld verwenden, das in einem Fanout enthalten ist, versucht Looker, stattdessen percentile_distinct zu verwenden. Wenn percentile_distinct für den Dialekt nicht verfügbar ist, gibt Looker einen Fehler zurück. Weitere Informationen finden Sie unter Unterstützte Dialekte für percentile_distinct.
Unterstützte Datenbankdialekte für percentile
Damit Looker den Typ percentile in Ihrem Looker-Projekt unterstützen kann, muss er auch von Ihrem Datenbankdialekt unterstützt werden. In der folgenden Tabelle sehen Sie, welche Dialekte den Typ percentile in der aktuellen Version von Looker unterstützen:
| Dialekt | Unterstützt? |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13+ | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |
percentile_distinct
type: percentile_distinct ist eine spezielle Form von Prozentil und sollte verwendet werden, wenn Ihr Join einen Fanout umfasst. Dabei werden die nicht wiederholten Werte in einem bestimmten Feld verwendet, basierend auf den eindeutigen Werten, die durch den Parameter sql_distinct_key definiert werden. Wenn die Messung keinen sql_distinct_key-Parameter hat, versucht Looker, das Feld primary_key zu verwenden.
Sehen Sie sich das Ergebnis einer Abfrage an, bei der die Tabellen „Order Item“ und „Order“ zusammengeführt werden:
| Artikel-ID der Bestellung | Bestell-ID | Versand von Bestellungen |
|---|---|---|
| 1 | 1 | 10 |
| 2 | 1 | 10 |
| 3 | 2 | 20 |
| 4 | 3 | 50 |
| 5 | 3 | 50 |
| 6 | 3 | 50 |
| 7 | 4 | 70 |
| 8 | 4 | 70 |
| 9 | 5 | 110 |
| 10 | 5 | 110 |
In diesem Fall sehen Sie, dass für jeden Auftrag mehrere Zeilen vorhanden sind. Diese Abfrage umfasste einen Fanout, da jede Bestellung mehreren Bestellpositionen zugeordnet ist. Bei percentile_distinct wird dies berücksichtigt und der Prozentilwert wird anhand der eindeutigen Werte 10, 20, 50, 70 und 110 ermittelt. Das 25. Perzentil gibt den zweiten eindeutigen Wert (20) zurück, während das 80. Perzentil den Durchschnitt des vierten und fünften eindeutigen Werts (90) zurückgibt.
Erforderliche und optionale Parameter
Mit dem Schlüsselwort percentile: geben Sie den Bruchwert an. Mit percentile: 75 geben Sie beispielsweise den Wert am 75. Perzentil in der Reihenfolge der Daten an, mit percentile: 10 den Wert am 10. Perzentil. Wenn Sie den Wert für das 50. Perzentil suchen, können Sie stattdessen den Typ median_distinct verwenden.
Damit Sie ein genaues Ergebnis erhalten, müssen Sie mit dem Parameter sql_distinct_key angeben, wie Looker jede eindeutige Einheit (in diesem Fall jede eindeutige Bestellung) identifizieren soll.
Hier ein Beispiel für die Verwendung von percentile_distinct, um den Wert am 90. Perzentil zurückzugeben:
measure: order_shipping_90th_percentile {
type: percentile_distinct
percentile: 90
sql_distinct_key: ${order_id} ;;
sql: ${order_shipping} ;;
}
Jeder eindeutige Wert von sql_distinct_key muss genau einen entsprechenden Wert im Parameter sql des Messwerts haben. Das vorherige Beispiel funktioniert also, weil jede Zeile mit dem Wert 1 für order_id denselben Wert 10 für order_shipping hat und jede Zeile mit dem Wert 2 für order_id denselben Wert 20 für order_shipping hat.
type: percentile_distinct-Felder können mit den Parametern value_format oder value_format_name formatiert werden.
Wichtige Punkte für percentile_distinct
Wenn percentile_distinct für den Dialekt nicht verfügbar ist, gibt Looker einen Fehler zurück. Weitere Informationen finden Sie unter Unterstützte Dialekte für percentile_distinct.
Unterstützte Datenbankdialekte für percentile_distinct
Damit Looker den Typ percentile_distinct in Ihrem Looker-Projekt unterstützen kann, muss er auch von Ihrem Datenbankdialekt unterstützt werden. In der folgenden Tabelle sehen Sie, welche Dialekte den Typ percentile_distinct in der aktuellen Version von Looker unterstützen:
| Dialekt | Unterstützt? |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13+ | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |
period_over_period
Für Dialekte, die Zeitvergleichsmesswerte unterstützen, können Sie einen LookML-Messwert vom Typ type: period_over_period erstellen, um einen Zeitvergleichsmesswert zu erstellen. Ein Zeitvergleichsmesswert verweist auf eine Aggregation aus einem früheren Zeitraum.
Hier ist ein Beispiel für eine PoP-Messung, die die Anzahl der Bestellungen des Vormonats liefert:
measure: orders_last_month {
type: period_over_period
based_on: orders.count
based_on_time: orders.created_month
period: month
kind: previous
}
Messungen mit type: period_over_period müssen auch die folgenden Unterparameter haben:
Weitere Informationen und Beispiele finden Sie unter Periodenvergleich in Looker.
running_total
Mit type: running_total wird eine kumulative Summe der Zellen in einer Spalte berechnet. Sie kann nicht verwendet werden, um Summen entlang einer Zeile zu berechnen, es sei denn, die Zeile ist das Ergebnis eines Pivots.
Der Parameter sql für type: running_total-Messungen muss auf einen anderen numerischen Messwert verweisen.
type: running_total-Felder können mit den Parametern value_format oder value_format_name formatiert werden.
Im folgenden LookML-Beispiel wird das Measure cumulative_total_revenue erstellt, das auf dem Measure total_sale_price basiert:
measure: cumulative_total_revenue {
type: running_total
sql: ${total_sale_price} ;;
value_format_name: usd
}
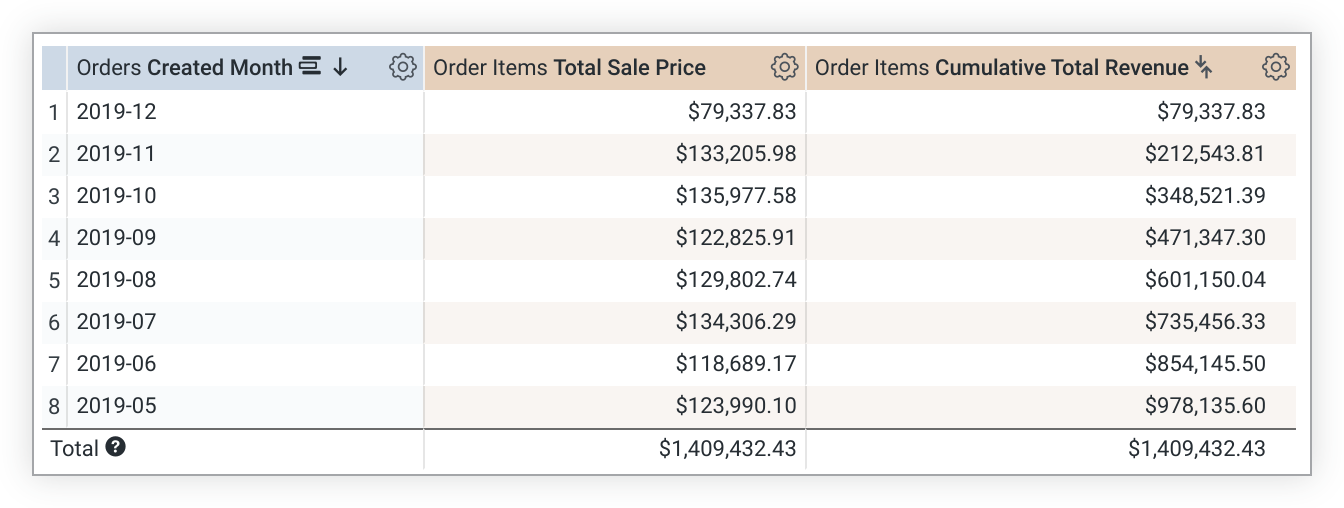
running_total-Werte hängen von der Sortierreihenfolge ab. Wenn Sie die Sortierung ändern, müssen Sie die Abfrage noch einmal ausführen, um die running_total-Werte neu zu berechnen. Wenn eine Abfrage pivotiert wird, wird running_total über die Zeile hinweg und nicht in der Spalte berechnet. Wenn das nicht Ihren Vorstellungen entspricht, fügen Sie der Messwertdefinition direction: "column" hinzu.
Außerdem werden running_total-Messwerte nach dem Abrufen von Daten aus Ihrer Datenbank berechnet. Das bedeutet, dass Sie nicht in einem anderen Messwert auf einen running_total-Messwert verweisen sollten, da die Messwerte möglicherweise zu unterschiedlichen Zeiten berechnet werden und Sie daher keine genauen Ergebnisse erhalten. Das bedeutet auch, dass running_total-Messwerte nicht gefiltert werden können.
string
type: string wird für Felder mit Buchstaben oder Sonderzeichen verwendet.
Der Parameter sql für type: string-Messwerte kann einen beliebigen gültigen SQL-Ausdruck enthalten, der zu einem String führt. In der Praxis wird dieser Typ selten verwendet, da die meisten SQL-Aggregatfunktionen keine Strings zurückgeben. Eine häufige Ausnahme ist die GROUP_CONCAT-Funktion von MySQL. Looker bietet jedoch type: list für diesen Anwendungsfall.
Mit dem folgenden LookML wird beispielsweise das Feld category_list erstellt, indem die eindeutigen Werte des Felds category kombiniert werden:
measure: category_list {
type: string
sql: GROUP_CONCAT(${category}) ;;
}
In diesem Beispiel könnte type: string weggelassen werden, da string der Standardwert für type ist.
sum
type: sum summiert die Werte in einem bestimmten Feld. Sie ähnelt der SQL-Funktion SUM. Anders als bei rohem SQL berechnet Looker Summen jedoch auch dann richtig, wenn die Joins Ihrer Abfrage Fanouts enthalten.
Der Parameter sql für type: sum-Messwerte kann einen beliebigen gültigen SQL-Ausdruck enthalten, der zu einer numerischen Tabellenspalte, einer LookML-Dimension oder einer Kombination aus LookML-Dimensionen führt.
type: sum-Felder können mit den Parametern value_format oder value_format_name formatiert werden.
Mit dem folgenden LookML wird beispielsweise ein Feld namens total_revenue erstellt, indem die Dimension sales_price addiert wird. Anschließend wird es im Währungsformat ($1.234,56) angezeigt:
measure: total_revenue {
type: sum
sql: ${sales_price} ;;
value_format_name: usd
}
sum_distinct
type: sum_distinct wird für denormalisierte Datasets verwendet. Damit werden die nicht wiederholten Werte in einem bestimmten Feld auf Grundlage der eindeutigen Werte addiert, die durch den Parameter sql_distinct_key definiert werden.
Dies ist ein komplexes Konzept, das sich anhand eines Beispiels besser veranschaulichen lässt. Betrachten Sie eine denormalisierte Tabelle wie diese:
| Artikel-ID der Bestellung | Bestell-ID | Versand von Bestellungen |
|---|---|---|
| 1 | 1 | 10,00 |
| 2 | 1 | 10,00 |
| 3 | 2 | 20,00 |
| 4 | 2 | 20,00 |
| 5 | 2 | 20,00 |
In diesem Fall sehen Sie, dass für jeden Auftrag mehrere Zeilen vorhanden sind. Wenn Sie also einen type: sum-Messwert für die Spalte order_shipping hinzugefügt haben, erhalten Sie insgesamt 80,00, obwohl die tatsächlich erhobenen Versandkosten 30,00 betragen.
# Will NOT calculate the correct shipping amount
measure: total_shipping {
type: sum
sql: ${order_shipping} ;;
}
Damit Sie ein genaues Ergebnis erhalten, können Sie in Looker mit dem Parameter sql_distinct_key definieren, wie jede eindeutige Einheit (in diesem Fall jede eindeutige Bestellung) identifiziert werden soll. Damit wird der richtige Betrag von 30,00 € berechnet:
# Will calculate the correct shipping amount
measure: total_shipping {
type: sum_distinct
sql_distinct_key: ${order_id} ;;
sql: ${order_shipping} ;;
}
Jeder eindeutige Wert von sql_distinct_key muss genau einen entsprechenden Wert in sql haben. Das obige Beispiel funktioniert, weil jede Zeile mit einem order_id von 1 denselben order_shipping von 10,00 hat und jede Zeile mit einem order_id von 2 denselben order_shipping von 20,00 hat.
type: sum_distinct-Felder können mit den Parametern value_format oder value_format_name formatiert werden.
yesno
Mit type: yesno wird ein Feld erstellt, das angibt, ob etwas wahr oder falsch ist. Die Werte werden in der Explore-Benutzeroberfläche als Ja und Nein angezeigt.
Der Parameter sql für einen type: yesno-Messwert akzeptiert einen gültigen SQL-Ausdruck, der als TRUE oder FALSE ausgewertet wird. Wenn die Bedingung als TRUE ausgewertet wird, wird dem Nutzer Ja angezeigt. Andernfalls wird Nein angezeigt.
Der SQL-Ausdruck für type: yesno-Messwerte darf nur Aggregationen enthalten, also SQL-Aggregationen oder Verweise auf LookML-Messwerte. Wenn Sie ein yesno-Feld erstellen möchten, das einen Verweis auf eine LookML-Dimension oder einen SQL-Ausdruck enthält, der keine Aggregation ist, verwenden Sie eine Dimension mit type: yesno und keinen Messwert.
Ähnlich wie bei Messwerten mit type: number werden bei einem Messwert mit type: yesno keine Aggregationen durchgeführt. Es wird nur auf andere Aggregationen verwiesen.
Das folgende Beispiel für den Messwert total_sale_price ist eine Summe des Gesamtverkaufspreises der Bestellartikel in einer Bestellung. Ein zweiter Messwert namens is_large_total ist type: yesno. Die Messung is_large_total hat einen sql-Parameter, der prüft, ob der total_sale_price-Wert größer als 1.000 $ ist.
measure: total_sale_price {
type: sum
value_format_name: usd
sql: ${sale_price} ;;
drill_fields: [detail*]
}
measure: is_large_total {
description: "Is order total over $1000?"
type: yesno
sql: ${total_sale_price} > 1000 ;;
}
Wenn Sie in einem anderen Feld auf ein type: yesno-Feld verweisen möchten, sollten Sie das type: yesno-Feld als booleschen Wert behandeln, d. h. so, als ob es bereits einen „true“- oder „false“-Wert enthält. Beispiel:
measure: is_large_total {
description: "Is order total over $1000?"
type: yesno
sql: ${total_sale_price} > 1000 ;;
}
# This is correct:
measure: reward_points {
type: number
sql: CASE WHEN ${is_large_total} THEN 200 ELSE 100 END ;;
}
# This is NOT correct:
measure: reward_points {
type: number
sql: CASE WHEN ${is_large_total} = 'Yes' THEN 200 ELSE 100 END ;;
}