
Usage
explore: explore_name {
join: view_name { ... }
}
|
היררכיה
join |
ערך ברירת המחדל
ללא
אישור
השם של תצוגה קיימת
כללים מיוחדים
|
הגדרה
join מאפשר להגדיר את קשר הצירוף בין ניתוח לבין תצוגה מפורטת, כדי שאפשר יהיה לשלב נתונים מכמה תצוגות מפורטות. אתם יכולים להצטרף לכמה תצוגות שתרצו בכל ניתוח נתונים.
כדאי לזכור שכל תצוגה משויכת לטבלה במסד הנתונים, או לטבלה נגזרת שהגדרתם ב-Looker. באופן דומה, מכיוון ש-Explore משויך לתצוגה, הוא גם מקושר לטבלה כלשהי.
הטבלה שמשויכת לניתוח ממוקמת בתנאי FROM של ה-SQL שנוצר על ידי Looker. טבלאות שמשויכות לתצוגות שצורפו ממוקמות בתנאי JOIN של ה-SQL ש-Looker יוצר.
פרמטרים חשובים של צירוף
כדי להגדיר את קשר הצירוף (הסעיף ON של SQL) בין ניתוח לבין תצוגה, צריך להשתמש ב-join בשילוב עם פרמטרים אחרים.
חובה להשתמש בפרמטר sql_on או בפרמטר foreign_key כדי להגדיר את פסוקית ה-SQL ON.
בנוסף, צריך לוודא שאתם משתמשים בסוגי הצטרפות ובקשרים מתאימים, למרות שהפרמטרים type ו-relationship לא תמיד נדרשים באופן מפורש. אם ערכי ברירת המחדל שלהם, type: left_outer ו-relationship: many_to_one, מתאימים לתרחיש השימוש שלכם, אפשר להחריג את הפרמטרים האלה.
אפשר לסכם את הפרמטרים העיקריים האלה ואת הקשר שלהם ל-SQL שנוצר ב-Looker באופן הבא:
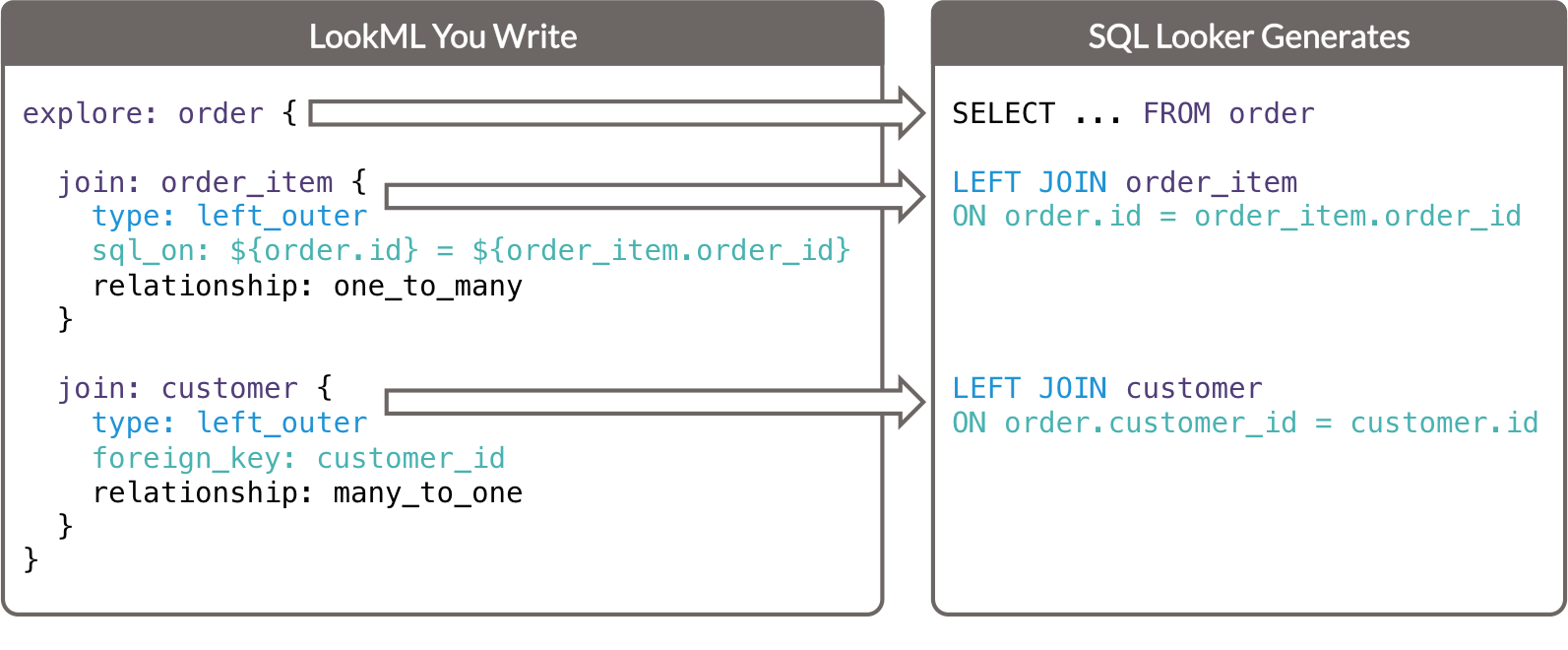
- הפרמטר
exploreקובע את הטבלה בסעיףFROMשל שאילתת ה-SQL שנוצרת. - כל פרמטר
joinקובע פסקהJOINשל שאילתת ה-SQL שנוצרת.- הפרמטר
typeקובע את סוג ה-SQL join. - הפרמטר
sql_onוהפרמטרforeign_keyקובעים את סעיףONשל שאילתת ה-SQL שנוצרת.
- הפרמטר
sql_on
sql_on מאפשרת לכם ליצור קשר בין טבלאות על ידי כתיבת פסקה של ON SQL ישירות. הוא יכול לבצע את אותם צירופים ש-foreign_key יכול לבצע, אבל קל יותר לקרוא ולהבין אותו.
מידע נוסף מופיע בדף התיעוד של הפרמטר sql_on.
foreign_key
foreign_key מאפשר ליצור קשר הצטרפות באמצעות המפתח הראשי של התצוגה המצורפת, ולחבר אותו למאפיין ב'ניתוח נתונים'. התבנית הזו נפוצה מאוד בתכנון מסדי נתונים, ו-foreign_key היא דרך אלגנטית לבטא את הצירוף במקרים האלה.
למידע נוסף, אפשר לעיין בדף מאמרי העזרה בנושא הפרמטר foreign_key.
type
רוב הצירופים ב-Looker הם LEFT JOIN מהסיבות שמפורטות בקטע עדיף לא להחיל לוגיקה עסקית בצירופים בדף הזה. לכן, אם לא מוסיפים באופן מפורש type, Looker יניח שרוצים LEFT JOIN. עם זאת, אם מסיבה כלשהי אתם צריכים סוג אחר של הצטרפות, אתם יכולים לעשות זאת באמצעות type.
הסבר מלא זמין בדף התיעוד של הפרמטר type.
relationship
ל-relationship אין השפעה ישירה על ה-SQL שנוצר ב-Looker, אבל הוא קריטי לתפקוד התקין של Looker. אם לא מוסיפים באופן מפורש relationship, Looker יפרש את הקשר כ-many-to-one, כלומר להרבה שורות בניתוח יכולה להיות שורה אחת בתצוגה המצורפת. לא כל הצטרפות היא מסוג הקשר הזה, וצריך להצהיר בצורה נכונה על הצטרפויות עם קשרים אחרים.
למידע נוסף, אפשר לעיין בדף מאמרי העזרה בנושא הפרמטר relationship.
דוגמאות
צירוף התצוגה שנקראת customer לניתוח שנקרא order, כאשר יחס הצירוף הוא
FROM order LEFT JOIN customer ON order.customer_id = customer.id:
explore: order {
join: customer {
foreign_key: customer_id
relationship: many_to_one # Could be excluded since many_to_one is the default
type: left_outer # Could be excluded since left_outer is the default
}
}
צירוף התצוגה שנקראת address לניתוח שנקרא person, כאשר יחס הצירוף הוא
FROM person LEFT JOIN address ON person.id = address.person_id
AND address.type = 'permanent':
explore: person {
join: address {
sql_on: ${person.id} = ${address.person_id} AND ${address.type} = 'permanent' ;;
relationship: one_to_many
type: left_outer # Could be excluded since left_outer is the default
}
}
צירוף התצוגה שנקראת member לניתוח שנקרא event, כאשר יחס הצירוף הוא
FROM event INNER JOIN member ON member.id = event.member_id:
explore: event {
join: member {
sql_on: ${event.member_id} = ${member.id} ;;
relationship: many_to_one # Could be excluded since many_to_one is the default
type: inner
}
}
אתגרים נפוצים
בשדה join צריך להשתמש בשמות של תצוגות ולא בשמות של טבלאות בסיסיות
הפרמטר join מקבל רק שם של תצוגה, ולא את שם הטבלה שמשויך לתצוגה הזו. לרוב, שם התצוגה ושם הטבלה זהים, ולכן אפשר להסיק בטעות שאפשר להשתמש בשמות של טבלאות.
חלק מסוגי המדדים דורשים צבירות סימטריות
אם לא משתמשים בצבירות סימטריות, רוב סוגי המדדים מוחרגים מתצוגות משולבות. כדי ש-Looker יתמוך בצבירות סימטריות בפרויקט Looker, הניב של מסד הנתונים צריך לתמוך בהן גם כן. בטבלה הבאה מפורטים הניבים שתומכים בצבירות סימטריות בגרסה האחרונה של Looker:
| דיאלקט | האם יש תמיכה? |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13+ | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |
בלי צבירות סימטריות, יחסי צירוף שהם לא אחד לאחד יכולים ליצור תוצאות לא מדויקות בפונקציות צבירה. מכיוון שמדדים ב-Looker הם פונקציות צבירה, רק מדדים של type: count (כמו COUNT DISTINCT) מועברים מתצוגות מצורפות אל Explore. אם יש לכם קשר של צירוף אחד לאחד, אתם יכולים להשתמש בפרמטר relationship כדי לכפות את הכללת סוגי המדדים האחרים, כך:
explore: person {
join: dna {
sql_on: ${person.dna_id} = ${dna.id} ;;
relationship: one_to_one
}
}
הסיבות לכך ש-Looker פועל בצורה הזו (בניבים שלא תומכים בצבירות סימטריות) מפורטות יותר בפוסט בקהילה בנושא הבעיה של פיצול שאילתות SQL.
חשוב לדעת
אפשר להצטרף לאותה טבלה יותר מפעם אחת באמצעות from
במקרים שבהם טבלה אחת מכילה סוגים שונים של ישויות, אפשר לצרף תצוגה לעולם תוכן מורחב יותר מפעם אחת. כדי לעשות את זה, צריך להשתמש בפרמטר from. נניח שיש לכם דוח order Explore ואתם צריכים לצרף אליו תצוגת person פעמיים: פעם אחת בשביל הלקוח ופעם אחת בשביל נציג שירות הלקוחות. לדוגמה, אפשר לכתוב משהו כזה:
explore: order {
join: customer {
from: person
sql_on: ${order.customer_id} = ${customer.id} ;;
}
join: representative {
from: person
sql_on: ${order.representative_id} = ${representative.id} ;;
}
}
אם אפשר, לא להחיל לוגיקה עסקית בצירופים
הגישה הרגילה ב-Looker לצירוף היא שימוש ב-LEFT JOIN כשאפשר. כדאי לשקול גישה אחרת אם אתם מוצאים את עצמכם עושים משהו מהסוגים הבאים:
explore: member_event {
from: event
always_join: [member]
join: member {
sql_on: ${member_event.member_id} = ${member.id} ;;
type: inner
}
}
בדוגמה הזו יצרנו ניתוח ב-Explore שבודק רק אירועים שמשויכים לחברים מוכרים. עם זאת, הדרך המומלצת לבצע את הפעולה הזו ב-Looker היא להשתמש ב-LEFT JOIN כדי לקבל נתוני אירועים ונתוני חברים שמשולבים יחד, כמו בדוגמה הבאה:
explore: event {
join: member {
sql_on: ${event.member_id} = ${member.id} ;;
}
}
אחר כך יוצרים מאפיין שאפשר להגדיר לו את הערכים yes או no, אם רוצים לראות רק אירועים של חברי מועדון, כמו בדוגמה הבאה:
dimension: is_member_event {
type: yesno
sql: ${member.id} IS NOT NULL ;;
}
הגישה הזו עדיפה כי היא מאפשרת למשתמשים לבחור אם להציג את כל האירועים או רק את האירועים של חברי הקהל. לא הגדרתם שהם יוכלו לראות רק אירועים לחברי מועדון באמצעות ההצטרפות.
אם לא משתמשים באגרגטים סימטריים, כדאי להימנע מצירופים שגורמים להתרחבות
הקטע הזה רלוונטי רק לדיאלקטים של מסדי נתונים שלא תומכים במצטברים סימטריים. כדי לבדוק אם הדיאלקט שלכם תומך בצבירה סימטרית, אפשר לעיין בדיון על צבירה סימטרית בקטע אתגרים נפוצים בדף הזה.
אם הדיאלקט של מסד הנתונים לא תומך בצבירה סימטרית, כדאי להימנע מאיחודים שמובילים ל-fanout. במילים אחרות, בדרך כלל כדאי להימנע מצירופים שיש בהם קשר של אחד לרבים בין ה-Explore לבין התצוגה. במקום זאת, צריך לצבור את הנתונים מהתצוגה בטבלה נגזרת כדי ליצור קשר של אחד לאחד עם הניתוח, ואז לצרף את הטבלה הנגזרת הזו לניתוח.
המושג החשוב הזה מוסבר בהרחבה בפוסט בקהילה The problem of SQL fanouts (הבעיה של פיצול SQL).