
Uso
explore: explore_name {
aggregate_table: table_name {
query: {
dimensions: [dimension1, dimension2, ... ]
measures: [measure1, measure2, ... ]
sorts: [field1: asc, field2: desc, ... ]
filters: [field1: "value1", field2: "value2", ... ]
timezone: timezone
}
materialization: {
...
}
}
...
}
|
Jerarquía
aggregate_table |
Valor predeterminado
Ninguno
Acepta Un nombre para la tabla de datos agregados, el subparámetro query para definir la tabla y el subparámetro materialization para definir la estrategia de persistencia de la tabla
Reglas especiales
|
Definición
El parámetro aggregate_table se usa para crear tablas agregadas que minimicen la cantidad de consultas necesarias para las tablas grandes de tu base de datos.
Looker utiliza la lógica de reconocimiento de agregaciones para encontrar la tabla de datos agregados más pequeña y eficiente disponible en tu base de datos para ejecutar una consulta y, al mismo tiempo, mantener la exactitud. (Consulta la página de documentación Aggregate awareness para obtener una descripción general y estrategias para crear tablas de agregación).
Para tablas muy grandes en tu base de datos, puedes crear tablas de datos agregados más pequeñas, agrupadas según varias combinaciones de atributos. Las tablas de datos agregados actúan como tablas de resumen o de integración que Looker puede usar para las consultas siempre que sea posible, en lugar de la tabla grande original.
Una vez que crees tus tablas de datos agregados, puedes ejecutar consultas en la exploración para ver cuáles de esas tablas son las que usa Looker. Para obtener más información, consulta la sección Cómo determinar qué tabla de datos agregados se usa para una consulta en la página de documentación Aggregate awareness.
Consulta la sección Solución de problemas en la página de documentación de Aggregate awareness para conocer los motivos comunes por los que no se usan las tablas agregadas.
Cómo definir una tabla de datos agregados en LookML
Cada parámetro aggregate_table debe tener un nombre único dentro de un explore determinado.
El parámetro aggregate_table tiene los subparámetros query y materialization.
query
El parámetro query define la consulta para la tabla de datos agregados, incluidas las dimensiones y las métricas que se usarán. El parámetro query incluye los siguientes subparámetros:
| Nombre del parámetro | Descripción | Ejemplo |
|---|---|---|
dimensions |
Es una lista separada por comas de las dimensiones de la función Explorar que se incluirán en tu tabla de datos agregados. El campo dimensions usa este formato: dimensions: [dimension1, dimension2, ...]
Cada dimensión de esta lista debe definirse como dimension en el archivo de vista de la Exploración de la consulta. Si deseas incluir un campo que se define como un campo filter en la consulta de Explorar, puedes agregarlo a la lista filters en la consulta de la tabla de agregación.
|
dimensions: [orders.created_month, orders.country] |
measures |
Es una lista separada por comas de las medidas de la exploración que se incluirán en tu tabla de datos agregados. El campo measures usa este formato: measures: [measure1, measure2, ...]
Para obtener información sobre los tipos de medidas admitidos para el conocimiento agregado, consulta la sección Factores del tipo de medida en la página de documentación Conocimiento agregado.
|
measures: [orders.count] |
filters |
De manera opcional, agrega un filtro a una query tabla de datos agregados. Los filtros se agregan a la cláusula WHERE del SQL que genera la tabla de datos agregados.
El campo filters usa este formato: filters: [field1: "value1", field2: "value2", ...]
Para obtener información sobre cómo los filtros pueden impedir que se use tu tabla de datos agregados, consulta la sección Factores de filtro en la página de documentación de Conocimiento de la agregación. |
filters: [orders.country: "United States", orders.state: "California"]
|
sorts |
De forma opcional, especifica los campos de ordenamiento y la dirección de ordenamiento (ascendente o descendente) para query.
El campo sorts usa este formato: sorts: [field1: asc|desc, field2: asc|desc, ...]
|
[orders.country: asc, orders.state: desc] |
timezone |
Establece la zona horaria para query. Si no se especifica una zona horaria, la tabla agregada no realizará ninguna conversión de zona horaria y, en su lugar, usará la zona horaria de la base de datos.
Para obtener información sobre cómo configurar la zona horaria de modo que tu tabla de datos agregados se use como fuente de consultas, consulta la sección Factores de zona horaria en la página de documentación Conocimiento de agregaciones.
El IDE sugiere automáticamente el valor de la zona horaria cuando escribes el parámetro timezone en el IDE. El IDE también muestra la lista de valores de zona horaria admitidos en el panel de ayuda rápida. |
timezone: America/Los_Angeles |
materialization
El parámetro materialization especifica la estrategia de persistencia para tu tabla de datos agregados, así como otras opciones de distribución, partición, indexación y agrupamiento que tu dialecto de SQL puede admitir.
Para que tu tabla de datos agregados sea accesible para el reconocimiento de agregaciones, debe conservarse en tu base de datos. El parámetro materialization de tu tabla de datos agregados debe tener uno de los siguientes subparámetros para especificar la estrategia de persistencia:
datagroup_triggersql_trigger_valuepersist_for(no recomendado)
Además, es posible que se admitan los siguientes subparámetros de materialization para tu tabla de datos agregados, según tu dialecto de SQL:
Para crear una tabla de datos agregados incremental, usa los siguientes subparámetros de materialization:
datagroup_trigger
Usa el parámetro datagroup_trigger para activar la regeneración de la tabla de datos agregados en función de un datagroup existente definido en el archivo del modelo:
explore: event {
aggregate_table: monthly_orders {
materialization: {
datagroup_trigger: order_datagroup
}
query: {
...
}
}
...
}
sql_trigger_value
Usa el parámetro sql_trigger_value para activar la regeneración de la tabla de datos agregados en función de una instrucción de SQL que proporciones. Si el resultado de la instrucción de SQL es diferente del valor anterior, se vuelve a generar la tabla. Esta instrucción sql_trigger_value activará la regeneración cuando cambie la fecha:
explore: event {
aggregate_table: monthly_orders {
materialization: {
sql_trigger_value: SELECT CURDATE() ;;
}
query: {
...
}
}
...
}
persist_for
El parámetro persist_for también se admite para las tablas de datos agregados. Sin embargo, es posible que la estrategia persist_for no te brinde el mejor rendimiento para el reconocimiento de agregaciones. Esto se debe a que, cuando un usuario ejecuta una consulta que depende de una tabla persist_for, Looker verifica la antigüedad de la tabla en función del parámetro de configuración persist_for. Si la tabla es más antigua que el parámetro de configuración persist_for, se vuelve a generar antes de que se ejecute la consulta. Si la antigüedad es menor que el parámetro de configuración persist_for, se usa la tabla existente. Por lo tanto, a menos que un usuario ejecute una consulta dentro del período persist_for, la tabla de datos agregados debe volver a compilarse antes de que se pueda usar para el reconocimiento de agregaciones.
explore: event {
aggregate_table: monthly_orders {
materialization: {
persist_for: "90 minutes"
}
query: {
...
}
}
...
}
A menos que comprendas las limitaciones y tengas un caso de uso específico para la implementación de persist_for, es mejor usar datagroup_trigger o sql_trigger_value como estrategia de persistencia para las tablas de agregación.
cluster_keys
El parámetro cluster_keys te permite agregar una columna agrupada en clústeres a las tablas particionadas en BigQuery o Snowflake. El agrupamiento ordena los datos en una partición según los valores de las columnas agrupadas y organiza las columnas agrupadas en bloques de almacenamiento de tamaño óptimo.
Consulta la página de documentación del parámetro cluster_keys para obtener más información.
distribution
El parámetro distribution te permite especificar la columna de una tabla de datos agregados en la que se aplicará una clave de distribución. distribution solo funciona con bases de datos de Redshift y Aster. Para otros dialectos de SQL (como MySQL y Postgres), usa indexes en su lugar.
Consulta la página de documentación del parámetro distribution para obtener más información.
distribution_style
El parámetro distribution_style te permite especificar cómo se distribuye la consulta de una tabla de datos agregados entre los nodos de una base de datos de Redshift:
distribution_style: allindica que todas las filas se copiaron por completo en cada nodo.distribution_style: evenespecifica una distribución uniforme, de modo que las filas se distribuyan a diferentes nodos de forma rotativa.
Consulta la página de documentación del parámetro distribution_style para obtener más información.
indexes
El parámetro indexes te permite aplicar índices a las columnas de una tabla de datos agregados.
Consulta la página de documentación del parámetro indexes para obtener más información.
partition_keys
El parámetro partition_keys define un array de columnas según las cuales se particionará la tabla de datos agregados. partition_keys admite dialectos de bases de datos que tienen la capacidad de particionar columnas. Cuando se ejecuta una consulta que se filtra en una columna particionada, la base de datos solo analizará las particiones que incluyen los datos filtrados, en lugar de analizar toda la tabla. partition_keys solo se admite con los dialectos de Presto y BigQuery.
Consulta la página de documentación del parámetro partition_keys para obtener más información.
publish_as_db_view
El parámetro publish_as_db_view te permite marcar una tabla de datos agregados para realizar consultas fuera de Looker. En el caso de las tablas de datos agregados con publish_as_db_view configurado como yes, Looker crea una vista estable de la base de datos en la base de datos para la tabla de datos agregados. La vista estable de la base de datos se crea en la propia base de datos, de modo que se pueda consultar fuera de Looker.
Consulta la página de documentación del parámetro publish_as_db_view para obtener más información.
sortkeys
El parámetro sortkeys te permite especificar una o más columnas de una tabla de datos agregados en las que se aplicará una clave de ordenamiento regular.
Consulta la página de documentación del parámetro sortkeys para obtener más información.
increment_key
Puedes crear PDT incrementales en tu proyecto si tu dialecto las admite. Una PDT incremental es una tabla derivada persistente (PDT) que Looker crea agregando datos recientes a la tabla, en lugar de volver a compilar la tabla en su totalidad. Consulta la página de documentación PDT incrementales para obtener más información.
Las tablas de datos agregados son un tipo de PDT y se pueden crear de forma incremental agregando el parámetro increment_key. Este parámetro especifica el incremento de tiempo para el que se deben consultar los datos recientes y agregarlos a la tabla de datos agregados.increment_key
Consulta la página de documentación del parámetro increment_key para obtener más información.
increment_offset
El parámetro increment_offset define la cantidad de períodos anteriores (en la granularidad de la clave de incremento) que se volverán a generar cuando se agreguen datos a la tabla de datos agregados. El parámetro increment_offset es opcional para las PDT incrementales y las tablas de agregación.
Consulta la página de documentación del parámetro increment_offset para obtener más información.
Cómo obtener LookML de tablas de datos agregados desde una Exploración
Como atajo, los desarrolladores de Looker pueden usar una consulta de Explorar para crear una tabla de datos agregados y, luego, copiar el código LookML en el proyecto de LookML:
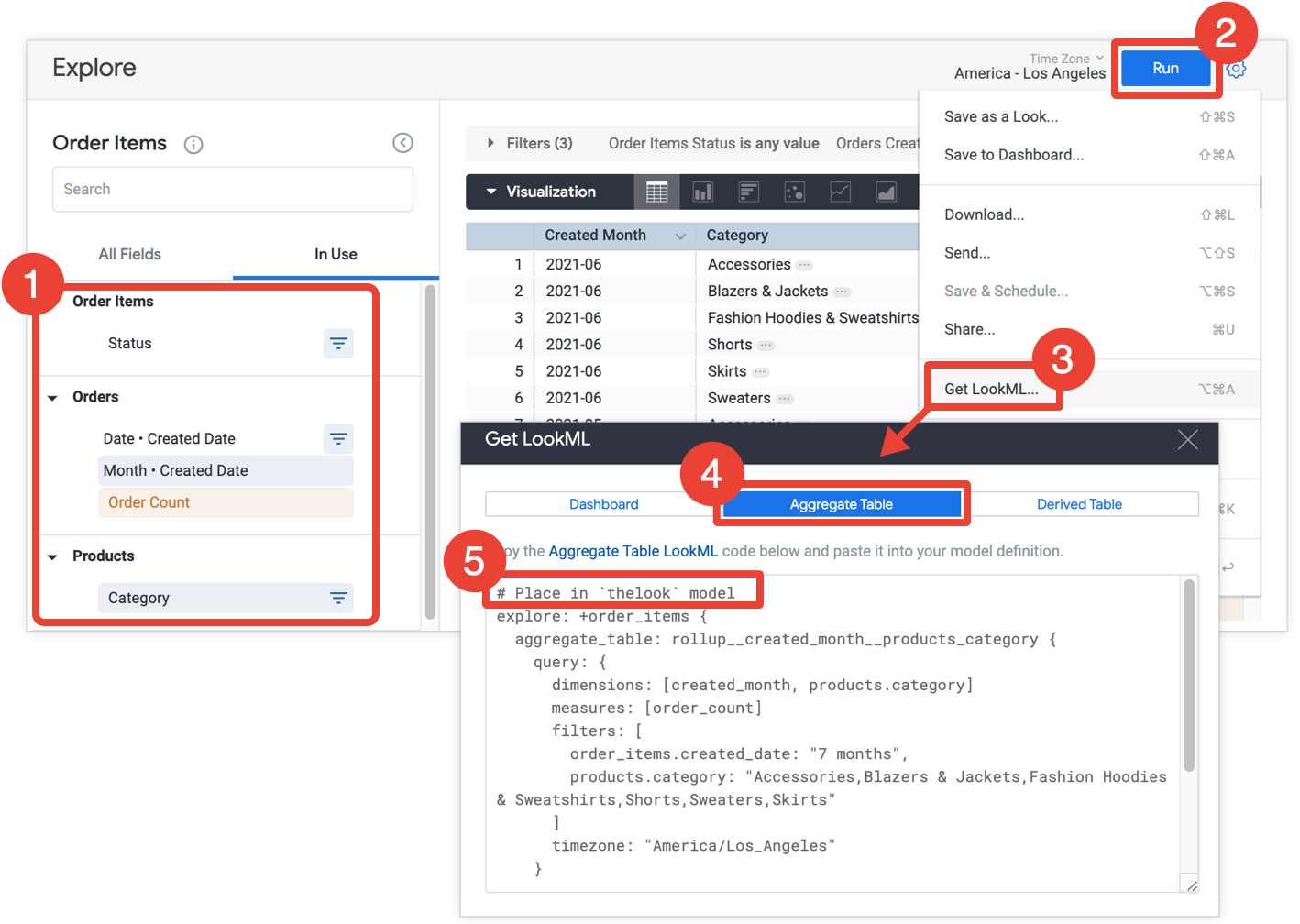
- En tu Explorar, selecciona todos los campos y filtros que quieras incluir en tu tabla de datos agregados.
- Haz clic en Ejecutar para obtener los resultados.
- Selecciona Obtener LookML en el menú de ajustes de la Exploración. Esta opción solo está disponible para los desarrolladores de Looker.
- Haz clic en la pestaña Tabla de agregación.
- Looker proporciona el LookML para un refinamiento de Explorar que agregará la tabla de datos agregados a la exploración. Copia el LookML y pégalo en el archivo del modelo asociado, que se indica en el comentario que precede al refinamiento de Explorar. Si la exploración se define en un archivo de exploración independiente y no en un archivo de modelo, puedes agregar el refinamiento al archivo de la exploración en lugar del archivo de modelo. Cualquiera de las dos ubicaciones funcionará.
Si necesitas modificar el LookML de la tabla de datos agregados, puedes hacerlo con los parámetros que se describen en la sección Cómo definir una tabla de datos agregados en LookML de esta página. Puedes cambiar el nombre de la tabla de datos agregados sin modificar su aplicabilidad a la consulta original de Explorar. Sin embargo, cualquier otro cambio en la tabla de datos agregados puede afectar la capacidad de Looker para usarla en la consulta de Explorar. Consulta la sección Diseña tablas agregadas de la página de documentación Reconocimiento de agregaciones para obtener sugerencias sobre cómo optimizar tus tablas agregadas y asegurarte de que se usen para el reconocimiento de agregaciones.
Cómo obtener el LookML de una tabla de datos agregados desde un panel
Otra opción para los desarrolladores de Looker es obtener el LookML de la tabla de datos agregados para todos los mosaicos de un panel y, luego, copiar el LookML en el proyecto de LookML.
Crear tablas de agregación puede mejorar drásticamente el rendimiento de un panel, en especial para las tarjetas que consultan conjuntos de datos enormes.
Si tienes permiso de develop, puedes obtener el LookML para crear tablas agregadas para un panel abriéndolo, seleccionando Obtener LookML en el menú de tres puntos del panel y eligiendo la pestaña Tablas agregadas:
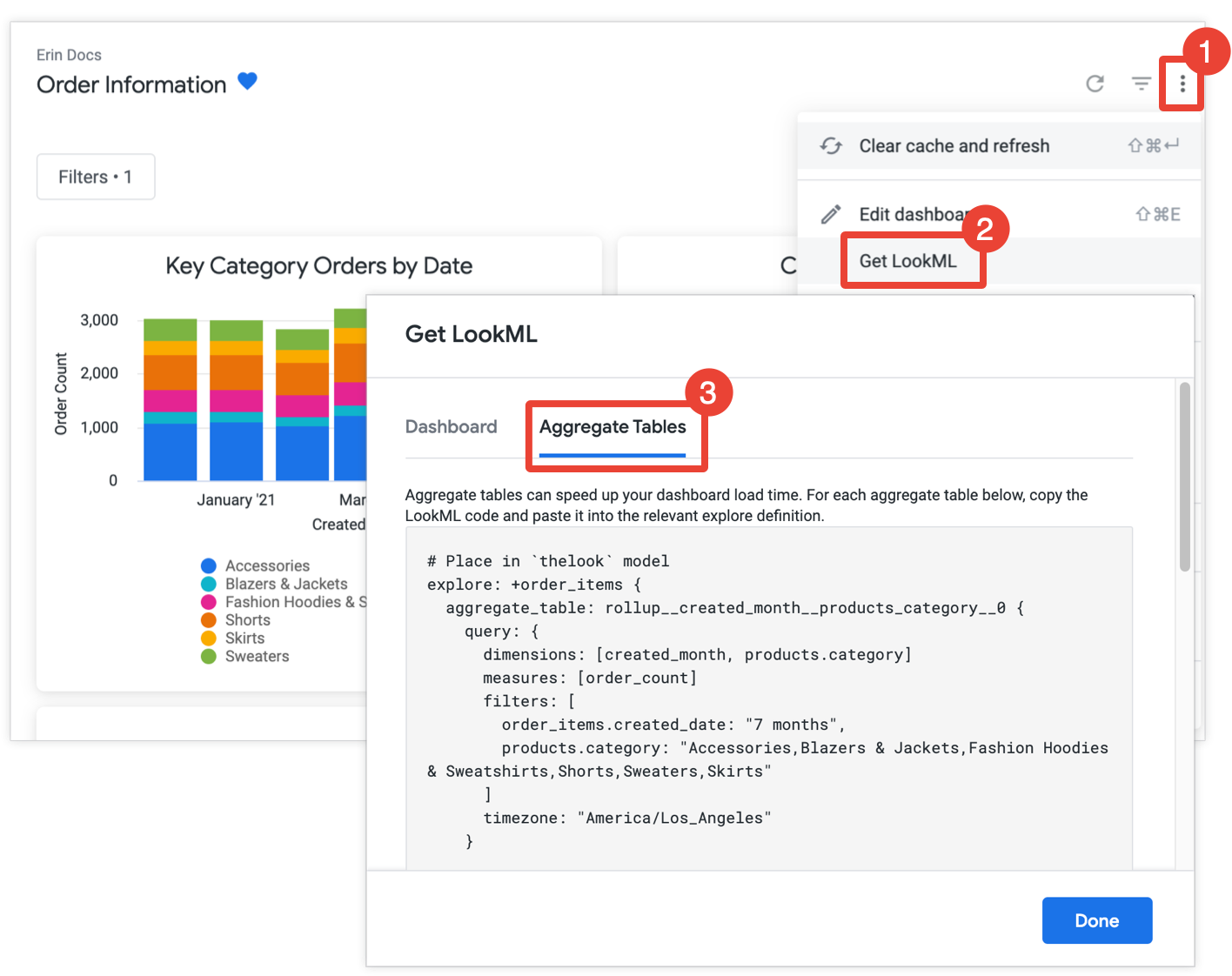
Para cada tarjeta que aún no esté optimizada con la función de reconocimiento de datos agregados, Looker proporciona el LookML para una mejora de la exploración que agregará la tabla de datos agregados a la exploración. Si el panel incluye varios mosaicos de la misma exploración, Looker coloca todas las tablas de datos agregados en una sola versión mejorada de la exploración. Para reducir la cantidad de tablas de datos agregados generadas, Looker determina si una tabla de datos agregados generada se podría usar para más de una tarjeta y, si es así, descarta las tablas de datos agregados redundantes que se puedan usar para menos tarjetas.
Copia y pega cada refinamiento de Explore en el archivo del modelo asociado, que se indica en el comentario que precede al refinamiento de Explore. Si la exploración se define en un archivo de exploración independiente y no en un archivo de modelo, puedes agregar el perfeccionamiento al archivo de exploración en lugar de al archivo de modelo. Cualquiera de las dos ubicaciones funcionará.
Si se aplica un filtro del panel a un mosaico, Looker agregará la dimensión del filtro a la tabla de datos agregados del mosaico para que se pueda usar la tabla de datos agregados en el mosaico. Esto se debe a que las tablas de datos agregados solo se pueden usar para una consulta si los filtros de la consulta hacen referencia a campos que están disponibles como dimensiones en la tabla de datos agregados. Consulta la página de documentación Aggregate awareness para obtener más información.
Si necesitas modificar el LookML de la tabla de datos agregados, puedes hacerlo con los parámetros que se describen en la sección Cómo definir una tabla de datos agregados en LookML de esta página. Puedes cambiar el nombre de la tabla de datos agregados sin cambiar su aplicabilidad al panel original, pero cualquier otro cambio en la tabla de datos agregados puede afectar la capacidad de Looker para usarla en el panel. Consulta la sección Diseña tablas agregadas de la página de documentación Reconocimiento de agregaciones para obtener sugerencias sobre cómo optimizar tus tablas agregadas y asegurarte de que se usen para el reconocimiento de agregaciones.
Ejemplo
En el siguiente ejemplo, se crea una tabla de datos agregados monthly_orders para la exploración event. La tabla de datos agregados crea un recuento mensual de pedidos. Looker usará la tabla de datos agregados para las consultas de recuento de pedidos que puedan aprovechar la granularidad mensual, como las consultas de recuentos de pedidos anuales, trimestrales y mensuales.
La tabla de datos agregados se configura con persistencia usando datagroup orders_datagroup. Además, la tabla de datos agregados se define con publish_as_db_view: yes, lo que significa que Looker creará una vista estable de la base de datos para la tabla de datos agregados.
La definición de la tabla de datos agregados se ve de la siguiente manera:
explore: event {
aggregate_table: monthly_orders {
materialization: {
datagroup_trigger: orders_datagroup
publish_as_db_view: yes
}
query: {
dimensions: [orders.created_month]
measures: [orders.count]
filters: [orders.created_date: "1 year", orders.status: "fulfilled"]
timezone: America/Los_Angeles
}
}
}
Aspectos para tener en cuenta
Consulta la sección Diseño de tablas agregadas de la página de documentación Conocimiento de los agregados para obtener sugerencias sobre cómo crear estratégicamente tus tablas agregadas:
- Factores de período
- Factores de zona horaria
- Factores de filtro
- Factores de campo
- Factores del tipo de medida
Compatibilidad con dialectos para el reconocimiento agregado
La capacidad de usar la agregación depende del dialecto de la base de datos que usa tu conexión de Looker. En la versión más reciente de Looker, los siguientes dialectos admiten el reconocimiento de agregados:
| Dialecto | ¿Es compatible? |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13+ | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |