
用法
explore: explore_name {
aggregate_table: table_name {
query: {
dimensions: [dimension1, dimension2, ... ]
measures: [measure1, measure2, ... ]
sorts: [field1: asc, field2: desc, ... ]
filters: [field1: "value1", field2: "value2", ... ]
timezone: timezone
}
materialization: {
...
}
}
...
}
|
层次结构
aggregate_table |
默认值
无
接受
汇总表格的名称、用于定义表的 query 子参数,以及用于定义表的 materialization 子参数,用于定义表的 持久性策略
特殊规则
|
定义
aggregate_table 参数用于创建汇总表,以最大限度地减少数据库中大型表所需的查询数量。
Looker 使用 汇总感知 逻辑在数据库中查找最小、最有效的可用汇总表格,从而运行查询,同时仍保持正确性。(如需了解汇总表及其创建策略的概览,请参阅汇总感知文档页面。)
对于数据库中非常大的表,您可以创建较小的汇总表,其中包含按各种属性组合分组的数据。这些汇总表充当汇总表或摘要表,Looker 可以在查询时尽可能使用它们来替代原始大型表。
创建汇总表后,您可以在探索中运行查询,以便查看 Looker 使用了哪些汇总表。如需了解详情,请参阅确定查询使用哪个汇总表格部分,该部分位于汇总感知文档页面上。
如需了解汇总表未被使用的常见原因,请参阅汇总感知文档页面上的问题排查部分。
在 LookML 中定义汇总表格
每个 aggregate_table 参数都必须有一个在给定的 explore 中唯一的名称。
aggregate_table 参数具有 query 和 materialization 子参数。
query
query 参数用于定义汇总表格的查询,包括要使用的维度和度量。query 参数包含以下子参数:
| 参数名称 | 说明 | 示例 |
|---|---|---|
dimensions |
探索中要包含在汇总表格中的维度的英文逗号分隔列表。dimensions 字段使用以下格式:dimensions: [dimension1, dimension2, ...]
此列表中的每个维度都必须在查询的探索的视图文件中定义为 dimension。如果您想在探索查询中包含定义为 filter 字段的字段,可以将其添加到汇总表的查询中的 filters 列表。
|
dimensions: [orders.created_month, orders.country] |
measures |
探索中要包含在汇总表格中的度量的逗号分隔列表。measures 字段使用以下格式:measures: [measure1, measure2, ...]
如需了解汇总感知支持的度量类型,请参阅度量类型因素部分,该部分位于汇总感知文档页面上。
|
measures: [orders.count] |
filters |
(可选)向 query 添加过滤条件。过滤条件会添加到生成汇总表格的 SQL 的 WHERE 子句中。
filters 字段使用以下格式:filters: [field1: "value1", field2: "value2", ...]
如需了解过滤条件如何阻止汇总表格被使用,请参阅过滤条件因素部分,具体请参阅汇总感知文档页面。 |
filters: [orders.country: "United States", orders.state: "California"]
|
sorts |
(可选)为 query 指定排序字段和排序方向(升序或降序)。
sorts 字段使用以下格式:sorts: [field1: asc|desc, field2: asc|desc, ...]
|
[orders.country: asc, orders.state: desc] |
timezone |
为 query 设置时区。如果未指定时区,汇总表格将不会执行任何时区转换,而是使用数据库时区。
如需了解如何设置时区,以便将汇总表格用作查询来源,请参阅时区因素部分,该部分位于汇总感知文档页面上。
当您在 IDE 中输入 timezone 参数时,IDE 会自动建议时区值。IDE 还会“快速帮助”面板中显示支持的时区值列表。 |
timezone: America/Los_Angeles |
materialization
materialization 参数用于指定汇总表格的持久性策略,以及 SQL 方言可能支持的其他选项,例如分发、分区、索引和聚簇。
汇总表格必须在数据库中持久化,才能实现汇总感知。汇总表格的 materialization 参数必须具有以下子参数之一,以指定持久性策略:
此外,根据 SQL 方言的不同,汇总表格可能支持以下 materialization 子参数:
如需创建 增量 汇总表格,请使用以下 materialization 子参数:
datagroup_trigger
使用 datagroup_trigger 参数 根据模型文件中定义的现有 数据组 触发 汇总表格 的重新生成:
explore: event {
aggregate_table: monthly_orders {
materialization: {
datagroup_trigger: order_datagroup
}
query: {
...
}
}
...
}
sql_trigger_value
使用 sql_trigger_value 参数根据您提供的 SQL 语句触发汇总表格的重新生成。如果 SQL 语句的结果与之前的值不同,则会重新生成表。以下 sql_trigger_value 语句会在日期更改时触发重新生成:
explore: event {
aggregate_table: monthly_orders {
materialization: {
sql_trigger_value: SELECT CURDATE() ;;
}
query: {
...
}
}
...
}
persist_for
汇总表也支持 persist_for 参数。不过,persist_for 策略可能无法为汇总感知提供最佳性能。这是因为,当用户运行依赖于 persist_for 表的查询时,Looker 会根据 persist_for 设置检查表的时长。如果表时长超过 persist_for 设置,则会在运行查询之前重新生成表。如果时长小于 persist_for 设置,则会使用现有表。因此,除非用户在 persist_for 时间内运行查询,否则必须先重建汇总表格,然后才能将其用于汇总感知。
explore: event {
aggregate_table: monthly_orders {
materialization: {
persist_for: "90 minutes"
}
query: {
...
}
}
...
}
除非您了解限制并具有 persist_for 实现的特定用例,否则最好使用 datagroup_trigger 或 sql_trigger_value 作为汇总表的持久性策略。
cluster_keys
借助 cluster_keys 参数,您可以向 BigQuery 或 Snowflake 上的 分区表添加聚簇列。聚簇会根据聚簇列中的值对分区中的数据进行排序,并以最佳大小的存储块组织聚簇列。
如需了解详情,请参阅 cluster_keys 参数文档页面。
distribution
借助 distribution 参数,您可以指定要向其应用分发键的汇总表格中的列。distribution 仅适用于 Redshift 和 Aster 数据库。对于其他 SQL 方言(例如 MySQL 和 Postgres),请改用 indexes。
如需了解详情,请参阅 distribution 参数文档页面。
distribution_style
借助 distribution_style 参数,您可以指定如何将汇总表格的查询分发到 Redshift 数据库中的节点:
distribution_style: all表示所有行都完全复制到每个节点。distribution_style: even指定均匀分发,以便以轮循方式将行分发到不同的节点。
如需了解详情,请参阅 distribution_style 参数文档页面。
indexes
借助 indexes 参数,您可以将索引应用于汇总表格的列。
如需了解详情,请参阅 indexes 参数文档页面。
partition_keys
partition_keys 参数用于定义汇总表格将按其分区的列数组。partition_keys 支持能够对列进行分区的数据库方言。当运行按分区列过滤的查询时,数据库将仅扫描包含过滤数据的分区,而不是扫描整个表。partition_keys 仅受 Presto 和 BigQuery 方言支持。
如需了解详情,请参阅 partition_keys 参数文档页面。
publish_as_db_view
借助 publish_as_db_view 参数,您可以标记汇总表格以在 Looker 外部进行查询。对于 publish_as_db_view 设置为 yes 的汇总表格,Looker 会在数据库中为汇总表格创建稳定的数据库视图。稳定的数据库视图是在数据库本身上创建的,因此可以在 Looker 外部进行查询。
如需了解详情,请参阅 publish_as_db_view 参数文档页面。
sortkeys
借助 sortkeys 参数,您可以指定要向其应用常规排序键的汇总表格的一列或多列。
如需了解详情,请参阅 sortkeys 参数文档页面。
increment_key
如果您的 方言支持增量 PDT,您可以在项目中创建 增量 PDT。增量 PDT 是一种 永久性派生表 (PDT),Looker 通过向表中添加最新数据来构建它,而不是完全重建表。如需了解详情,请参阅增量 PDT文档页面。
汇总表是一种 PDT,可以通过添加 increment_key 参数以增量方式构建。increment_key 参数用于指定应查询最新数据并将其附加到汇总表格的时间增量。
如需了解详情,请参阅 increment_key 参数文档页面。
increment_offset
increment_offset 参数用于定义在向汇总表格附加数据时将重建的先前时间段数(以增量键的粒度为单位)。对于增量 PDT 和汇总表,increment_offset 参数是可选的。
如需了解详情,请参阅 increment_offset 参数文档页面。
从探索获取汇总表格 LookML
作为快捷方式,Looker 开发者可以使用探索查询来创建汇总表格,然后将 LookML 复制到 LookML 项目中:
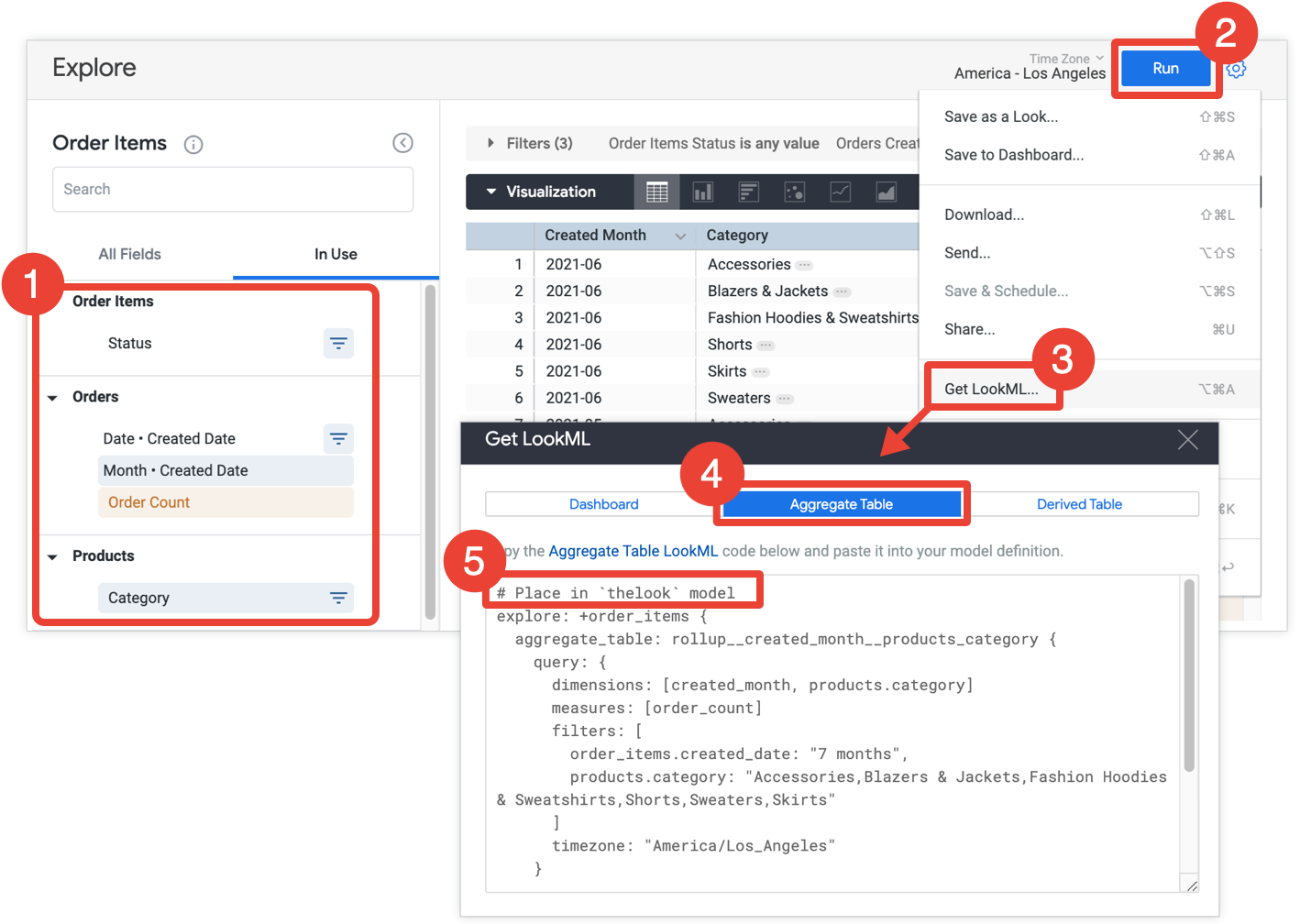
- 在探索中,选择要包含在汇总表格中的所有字段和过滤条件。
- 点击运行 以获取结果。
- 从探索的齿轮菜单中选择 Get LookML 。此选项仅适用于 Looker 开发者。
- 点击汇总表 标签页。
- Looker 会提供探索 优化 的 LookML,该优化会将汇总表格添加到探索中。复制 LookML 并将其粘贴到关联的模型文件中,该文件在探索优化之前的注释中指明。如果探索是在单独的探索文件中定义的,而不是在模型文件中定义的,您可以将优化添加到探索的文件中,而不是模型文件中。这两个位置都可以。
如果您需要修改汇总表格 LookML,可以使用本页面上的在 LookML 中定义汇总表格部分中所述的参数进行修改。您可以重命名汇总表格,而不会更改其对原始探索查询的适用性。不过,对汇总表的任何其他更改都可能会影响 Looker 将汇总表用于探索查询的能力。如需了解有关优化汇总表的提示,以确保它们用于汇总感知,请参阅汇总感知文档页面的设计汇总表部分。
从信息中心获取汇总表格 LookML
Looker 开发者还可以选择获取信息中心上所有模块的汇总表格 LookML,然后将 LookML 复制到 LookML 项目中。
创建汇总表可以大幅提高信息中心的性能,尤其是对于查询大型数据集的图块。
如果您具有 develop 权限,则可以获取 LookML 以便为信息中心创建汇总表,方法是打开信息中心,从信息中心的三点状菜单中选择 Get LookML ,然后选择汇总表 标签页:
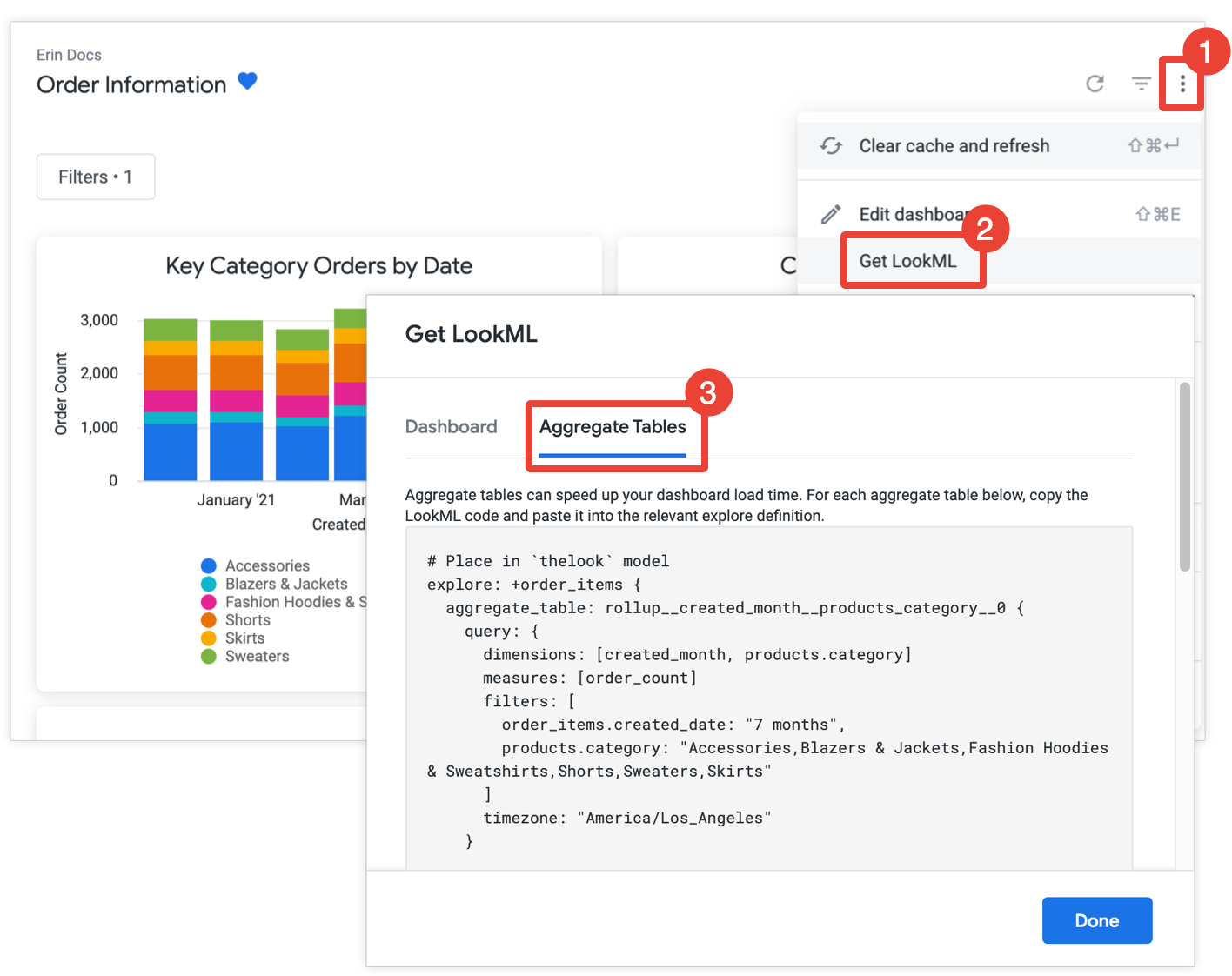
对于尚未通过汇总感知优化的每个模块,Looker 会提供探索 优化 的 LookML,该优化会将汇总表格添加到探索中。如果信息中心包含来自同一探索的多个图块,Looker 会将所有汇总表放在单个探索优化中。为了减少生成的汇总表格的数量,Looker 会确定生成的汇总表格是否可用于多个模块,如果可以,则会删除可用于较少模块的任何冗余汇总表格。
将每个探索优化复制并粘贴到关联的模型文件中,该文件在探索优化之前的注释中指明。如果探索是在单独的探索文件中定义的,而不是在模型文件中定义的,您可以将优化添加到探索文件中,而不是模型文件中。这两个位置都可以。
如果信息中心过滤条件应用于图块,Looker 会将过滤条件的维度添加到图块的汇总表格中,以便汇总表格可用于图块。这是因为,只有当查询的过滤条件引用在汇总表格中可用作维度的字段时,汇总表格才能用于查询。如需了解详情,请参阅汇总感知文档页面。
如果您需要修改汇总表格 LookML,可以使用本页面上的在 LookML 中定义汇总表格部分中所述的参数进行修改。您可以重命名汇总表格,而不会更改其对原始信息中心模块的适用性,但对汇总表格的任何其他更改都可能会影响 Looker 将汇总表格用于信息中心的能力。如需了解有关优化汇总表的提示,以确保它们用于汇总感知,请参阅汇总感知文档页面的设计汇总表部分。
示例
以下示例为 event 探索创建 monthly_orders 汇总表格。汇总表格会创建每月订单数。Looker 会将汇总表格用于可采用每月粒度的订单数查询,例如年度、季度和每月订单数查询。
汇总表格使用 数据组 orders_datagroup 设置了持久性。此外,汇总表还使用 publish_as_db_view: yes 定义,这意味着 Looker 会在数据库中为汇总表创建稳定的数据库视图。
汇总表格定义如下所示:
explore: event {
aggregate_table: monthly_orders {
materialization: {
datagroup_trigger: orders_datagroup
publish_as_db_view: yes
}
query: {
dimensions: [orders.created_month]
measures: [orders.count]
filters: [orders.created_date: "1 year", orders.status: "fulfilled"]
timezone: America/Los_Angeles
}
}
}
注意事项
如需了解有关策略性创建汇总表的提示,请参阅汇总感知 文档页面的设计汇总表部分:
汇总感知的方言支持
使用汇总感知的能力取决于 Looker 连接使用的数据库方言。在最新版本的 Looker 中,以下方言支持汇总感知:
| 方言 | 是否支持? |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13+ | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |