
Questa pagina fornisce informazioni più approfondite su come i parchi risorse ti aiutano a gestire i deployment multi-cluster, inclusi alcuni concetti e terminologia chiave dei parchi risorse. I parchi risorse sono un Google Cloud concetto per l'organizzazione logica dei cluster e di altre risorse; ti consentono di utilizzare e gestire le funzionalità multi-cluster e di applicare criteri coerenti in tutti i tuoi sistemi. I parchi risorse sono una parte fondamentale del funzionamento della funzionalità multi-cluster in Google Cloud.
Questa guida è pensata per i lettori tecnici, inclusi architetti di sistema, operatori di piattaforma e operatori di servizi, che vogliono sfruttare più cluster e l'infrastruttura correlata. Questi concetti sono utili ovunque la tua organizzazione esegua più cluster, sia in Google Cloud, sia su più provider di servizi cloud, sia on-premise.
Prima di leggere questa pagina, assicurati di conoscere i concetti di base di Kubernetes, come cluster e spazi dei nomi. In caso contrario, consulta Nozioni di base su Kubernetes, la documentazione di GKE, e Preparare un'applicazione per Cloud Service Mesh.
Terminologia
Di seguito sono riportati alcuni termini importanti che utilizziamo quando parliamo di parchi risorse.
Risorse compatibili con i parchi risorse
Le risorse compatibili con i parchi risorse sono Google Cloud risorse di progetto che possono essere raggruppate e gestite logicamente come parchi risorse. Al momento, solo i cluster Kubernetes possono essere membri di un parco risorse.
Progetto host del parco risorse
L'implementazione dei parchi risorse, come molte altre Google Cloud risorse, è radicata in un Google Cloud progetto, che chiamiamo progetto host del parco risorse. Un determinato Google Cloud progetto può avere associato un solo parco risorse (o nessun parco risorse) . Questa limitazione rafforza l'utilizzo dei Google Cloud progetti per fornire un isolamento più efficace tra le risorse che non sono gestite o utilizzate insieme.
Raggruppamento dell'infrastruttura
Il primo concetto importante dei parchi risorse è il concetto di raggruppamento, ovvero la scelta di quali risorse compatibili con i parchi risorse correlate devono far parte di un parco risorse. La decisione su cosa raggruppare richiede di rispondere alle seguenti domande:
- Le risorse sono correlate tra loro?
- Le risorse che hanno grandi quantità di comunicazione tra servizi traggono il massimo vantaggio dalla gestione congiunta in un parco risorse.
- Le risorse nello stesso ambiente di deployment (ad esempio, l'ambiente di produzione) devono essere gestite insieme in un parco risorse.
- Chi amministra le risorse?
- Avere un controllo unificato (o almeno reciprocamente attendibile) sulle risorse è fondamentale per garantire l'integrità del parco risorse.
Per illustrare questo punto, prendi in considerazione un'organizzazione che ha più linee di business (LOB). In questo caso, i servizi raramente comunicano tra i confini delle LOB, i servizi in LOB diverse vengono gestiti in modo diverso (ad esempio, i cicli di upgrade variano tra le LOB) e potrebbero persino avere un insieme diverso di amministratori per ogni LOB. In questo caso, potrebbe essere opportuno avere parchi risorse per LOB. È probabile che ogni LOB adotti anche più parchi risorse per separare i servizi di produzione e non di produzione.
Man mano che esplori altri concetti relativi ai parchi risorse nelle sezioni seguenti, potresti trovare altri motivi per creare più parchi risorse in base alle esigenze specifiche della tua organizzazione.
Identicità
Un concetto importante nei parchi risorse è il concetto di identicità. Ciò significa che quando utilizzi determinate funzionalità abilitate per i parchi risorse, alcuni oggetti Kubernetes, come gli spazi dei nomi che hanno lo stesso nome in cluster diversi, vengono trattati come se fossero la stessa cosa. Questa normalizzazione viene eseguita per semplificare l'amministrazione delle risorse del parco risorse. Se utilizzi funzionalità che sfruttano l'identicità, questo presupposto di identicità fornisce alcune indicazioni importanti su come configurare spazi dei nomi, servizi e identità. Tuttavia, segue anche ciò che la maggior parte delle organizzazioni implementa già.
I diversi tipi di identicità offrono vantaggi diversi, come mostrato nella tabella seguente:
| Proprietà di identicità | Ti consente di... |
|---|---|
| Uno spazio dei nomi è considerato lo stesso in più cluster. |
|
| Una combinazione di nome dello spazio dei nomi e del servizio è considerata la stessa in più cluster. I servizi con lo stesso nome nello stesso spazio dei nomi utilizzano lo stesso selettore di etichette. |
|
| Una combinazione di spazio dei nomi e account di servizio (identità) è considerata la stessa in più cluster. |
|
Come suggerisce, diverse funzionalità del parco risorse si basano su diversi tipi di identicità. Un numero inferiore di funzionalità non utilizza affatto l'identicità. Puoi scoprire di più in Quali funzionalità utilizzano l'identicità?, inclusi quali funzionalità puoi utilizzare senza dover considerare l'identicità a livello di parco risorse e quali funzionalità potrebbero richiedere una pianificazione più attenta.
Identicità dello spazio dei nomi
L'esempio fondamentale di identicità in un parco risorse è l'identicità dello spazio dei nomi. Gli spazi dei nomi con lo stesso nome in cluster diversi sono considerati uguali da molte funzionalità del parco risorse. Un altro modo per pensare a questa proprietà è che uno spazio dei nomi è definito logicamente in un intero parco risorse, anche se l'istanza dello spazio dei nomi esiste solo in un sottoinsieme delle risorse del parco risorse.
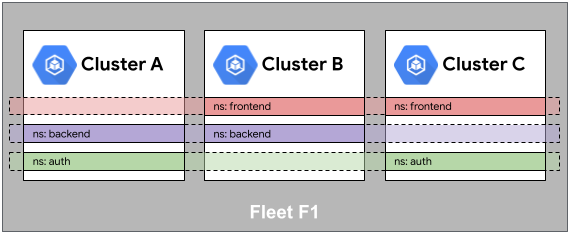
Prendi in considerazione il seguente esempio di spazio dei nomi backend. Sebbene lo spazio dei nomi sia istanziato solo nei cluster A e B, è implicitamente riservato nel cluster C (consente di pianificare anche un servizio nello spazio dei nomi backend nel cluster C, se necessario).
Ciò significa che gli spazi dei nomi vengono allocati per l'intero parco risorse e non per cluster. Pertanto, l'identicità dello spazio dei nomi richiede una proprietà dello spazio dei nomi coerente in tutto il parco risorse.
Identicità del servizio
Cloud Service Mesh e Ingress multi-cluster utilizzano il concetto di identicità dei servizi all'interno di uno spazio dei nomi. Come l'identicità dello spazio dei nomi, ciò implica che i servizi con lo stesso spazio dei nomi e lo stesso nome del servizio sono considerati lo stesso servizio.
Gli endpoint di servizio possono essere uniti nel mesh nel caso di Cloud Service Mesh. Con Ingress multi-cluster, una risorsa MultiClusterService (MCS) rende più esplicita l'unione degli endpoint; tuttavia, consigliamo pratiche simili per quanto riguarda la denominazione. Per questo motivo, è importante assicurarsi che i servizi con lo stesso nome nello stesso spazio dei nomi siano effettivamente la stessa cosa.
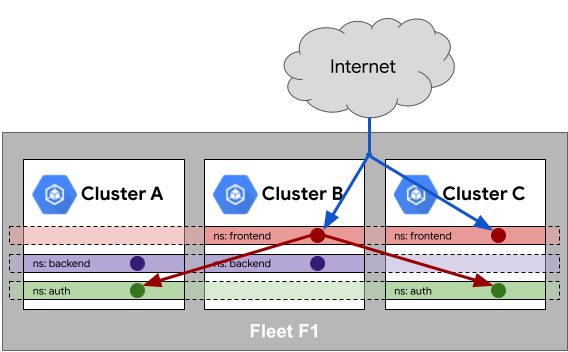
Nell'esempio seguente, il traffico internet viene bilanciato del carico su un servizio con lo stesso nome nello spazio dei nomi frontend presente sia nel cluster B sia nel cluster C. Allo stesso modo, utilizzando le proprietà del mesh di servizi all'interno del parco risorse, il servizio nello spazio dei nomi frontend può raggiungere un servizio con lo stesso nome nello spazio dei nomi auth presente nei cluster A e C.
Identicità dell'identità quando si accede a risorse esterne
Con la federazione delle identità per i workload del parco risorse, i servizi all'interno di un parco risorse possono sfruttare un'identità comune quando accedono a risorse esterne come Google Cloud servizi, object store, e così via. Questa identità comune consente di concedere l'accesso a una risorsa esterna ai servizi all'interno di un parco risorse una sola volta anziché cluster per cluster.
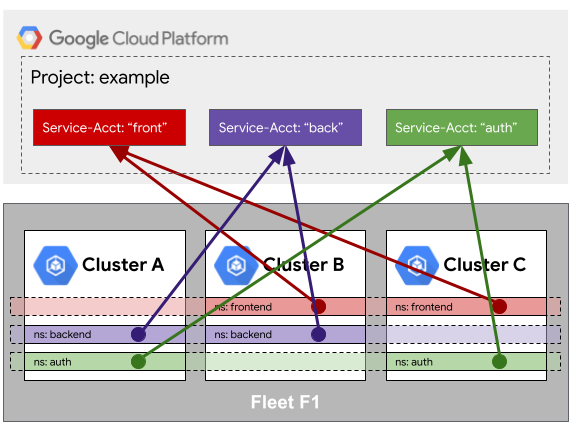
Per illustrare ulteriormente questo punto, prendi in considerazione il seguente esempio. I cluster A, B e C sono registrati con un'identità comune all'interno del loro parco risorse. Quando i servizi nello spazio dei nomi
backend accedono alle risorse Google Cloud , le loro identità vengono
mappate a un account di servizio comune denominato Google Cloud back. L'
Google Cloud account di servizio back può essere autorizzato su un numero qualsiasi di
servizi gestiti, da Cloud Storage a Cloud SQL. Quando vengono aggiunte nuove risorse del parco risorse, come i cluster, nello spazio dei nomi backend, queste ereditano automaticamente le proprietà di identicità dei workload.
A causa dell'identicità dell'identità, è importante che tutte le risorse di un parco risorse siano attendibili e ben gestite. Tornando all'esempio precedente, se il cluster C è di proprietà di un team separato e non attendibile, anche questo può creare uno spazio dei nomi backend e accedere ai servizi gestiti come se fosse il backend nel cluster A o B.
Identicità dell'identità all'interno di un parco risorse
All'interno del parco risorse, l'identicità dell'identità viene utilizzata in modo simile all'identicità dell'identità esterna di cui abbiamo parlato in precedenza. Proprio come i servizi del parco risorse vengono autorizzati una sola volta per un servizio esterno, possono essere autorizzati anche internamente.
Nell'esempio seguente, utilizziamo Cloud Service Mesh
per creare un mesh di servizi multi-cluster in cui frontend ha accesso a backend.
Con Cloud Service Mesh e i parchi risorse, non è necessario specificare che frontend nei cluster B e C può accedere a backend nei cluster A e B. Invece, specifichiamo solo che frontend nel parco risorse può accedere a backend nel parco risorse. Questa proprietà non solo semplifica l'autorizzazione, ma rende anche più flessibili i limiti delle risorse; ora i carichi di lavoro possono essere spostati facilmente da un cluster all'altro senza influire sulla loro autorizzazione. Come per l'identicità dei workload, la governance sulle risorse del parco risorse è fondamentale per garantire l'integrità della comunicazione tra servizi.

Quali funzionalità utilizzano l'identicità?
Diverse funzionalità del parco risorse non si basano affatto sull'identicità e possono essere abilitate e utilizzate senza dover considerare se vuoi presupporre una forma di identicità nel tuo parco risorse. Altre funzionalità (tra cui Config Sync e Policy Controller) possono utilizzare l'identicità, ad esempio se vuoi selezionare uno spazio dei nomi in più cluster membri del parco risorse per la configurazione da un'unica fonte attendibile, ma non è obbligatoria per tutti i casi d'uso. Infine, esistono funzionalità come Ingress multi-cluster e la federazione delle identità per i workload a livello di parco risorse che presuppongono sempre una forma di identicità tra i cluster e potrebbero dover essere adottate con attenzione a seconda delle tue esigenze e dei carichi di lavoro esistenti.
Alcune funzionalità del parco risorse (come la federazione delle identità per i workload del parco risorse) richiedono che l'intero parco risorse sia pronto per i presupposti di identicità che utilizzano. Altre funzionalità, come la gestione dei team, ti consentono di attivare gradualmente l'identicità a livello di spazio dei nomi o di ambito del team.
La tabella seguente mostra quali funzionalità richiedono uno o più dei concetti di identicità descritti in questa sezione.
| Funzionalità | Supporta l'adozione graduale dell'identicità | Dipende dall'identicità dello spazio dei nomi | Dipende dall'identicità del servizio | Dipende dall'identicità dell'identità |
|---|---|---|---|---|
| Parchi risorse | N/D | No | No | No |
| Autorizzazione binaria | N/D | No | No | No |
| Crittografia trasparente tra nodi | N/D | No | No | No |
| Policy di rete basata sul nome di dominio completo | N/D | No | No | No |
| Connect Gateway | N/D | No | No | No |
| Config Sync | N/D | No | No | No |
| Policy Controller | N/D | No | No | No |
| Strategia di sicurezza di GKE | N/D | No | No | No |
| Advanced Vulnerability Insights | N/D | No | No | No |
| Postura di conformità | N/D | No | No | No |
| Sequenza di implementazione | N/D | No | No | No |
| Gestione dei team | Sì | Sì | Sì | No |
| Ingress multi-cluster | Sì | Sì | Sì | Sì |
| Servizi multi-cluster | Sì | Sì | Sì | Sì |
| Federazione delle identità per i workload del parco risorse | No | Sì | Sì | Sì |
| Cloud Service Mesh | No | Sì | Sì | Sì |
Esclusività
Le risorse compatibili con i parchi risorse possono essere membri di un solo parco risorse alla volta, una limitazione applicata da Google Cloud strumenti e componenti. Questa limitazione garantisce che esista una sola fonte attendibile che governa un cluster. Senza esclusività, anche i componenti più semplici diventerebbero complessi da utilizzare, richiedendo alla tua organizzazione di ragionare e configurare il modo in cui interagirebbero più componenti di più parchi risorse.
Elevata attendibilità
L'identicità del servizio, l'identicità dei workload e l'identicità del mesh si basano su un principio di elevata attendibilità tra i membri di un parco risorse. Questa attendibilità consente di aumentare il livello di gestione di queste risorse al parco risorse, anziché gestire risorsa per risorsa (ovvero cluster per cluster per le risorse Kubernetes), e in definitiva rende meno importante il limite del cluster.
In altre parole, all'interno di un parco risorse, i cluster forniscono protezione dai problemi relativi al raggio di esplosione, alla disponibilità (sia del piano di controllo sia dell'infrastruttura sottostante), ai vicini rumorosi e così via. Tuttavia, non sono un limite di isolamento efficace per criteri e governance, perché gli amministratori di qualsiasi membro di un parco risorse possono potenzialmente influire sulle operazioni dei servizi in altri membri del parco risorse.
Per questo motivo, consigliamo di inserire i cluster non attendibili dall'amministratore del parco risorse nei propri parchi risorse per mantenerli isolati. Quindi, se necessario, i singoli servizi possono essere autorizzati oltre il limite del parco risorse.
Ambiti dei team
Un ambito del team è un meccanismo per suddividere ulteriormente il parco risorse in gruppi di cluster, consentendoti di definire le risorse compatibili con i parchi risorse assegnate a un team di applicazioni specifico. A seconda del caso d'uso, un singolo cluster membro del parco risorse può essere associato a nessun team, a un team o a più team, consentendo a più team di condividere i cluster. Puoi anche utilizzare gli ambiti dei team per sequenziare le implementazioni degli upgrade dei cluster nel parco risorse, anche se ciò richiede che ogni cluster sia associato a un solo team.
Un ambito del team può avere spazi dei nomi del parco risorse definiti in modo esplicito associati, in cui lo spazio dei nomi è considerato lo stesso nell'ambito. In questo modo hai un controllo più granulare sugli spazi dei nomi rispetto all'identicità dello spazio dei nomi predefinita fornita solo dai parchi risorse.
Componenti abilitati per il parco risorse
I seguenti componenti sfruttano i concetti relativi ai parchi risorse, come l'identicità dello spazio dei nomi e delle identità, per offrire un modo semplificato per lavorare con i tuoi cluster e servizi. Per eventuali requisiti o limitazioni attuali per l'utilizzo dei parchi risorse con ogni componente, consulta i requisiti del componente.
Pool di identità del workload
Un parco risorse offre un pool di identità del workload comune che può essere utilizzato per autenticare e autorizzare i workload in modo uniforme all'interno di un mesh di servizi e per i servizi esterni.Cloud Service Mesh
Cloud Service Mesh è una suite di strumenti che ti aiuta a monitorare e gestire un mesh di servizi affidabile su Google Cloud, on-premise e altri ambienti supportati. Puoi formare un mesh di servizi tra i cluster che fanno parte dello stesso parco risorse.Config Sync
Config Sync consente di eseguire il deployment e il monitoraggio dei pacchetti di configurazione dichiarativi di configurazione per il sistema archiviati in un'unica fonte attendibile, ad esempio un repository Git, sfruttando i concetti di base di Kubernetes come spazi dei nomi, etichette e annotazioni. Con Config Sync, le configurazioni vengono definite nel parco risorse, ma applicate e applicate localmente in ciascuna delle risorse membro.Policy Controller
Policy Controller consente di applicare e applicare policy dichiarative per i cluster Kubernetes. Questi criteri fungono da sistema di protezione e possono aiutarti con le best practice, la sicurezza e la gestione della conformità dei tuoi cluster e del tuo parco risorse.Ingress multi-cluster
Ingress multi-cluster utilizza il parco risorse per definire l'insieme di cluster ed endpoint di servizio su cui è possibile bilanciare il carico del traffico, consentendo servizi a bassa latenza e ad alta disponibilità.
Passaggi successivi
- Scopri di più su quando utilizzare più cluster per soddisfare le tue esigenze tecniche e aziendali in Casi d'uso multi-cluster.
- Sei pronto a pensare di applicare questi concetti ai tuoi sistemi? Consulta Pianificare le risorse del parco risorse.