
本页面介绍了可用于监控 Config Sync 资源的 OpenTelemetry 指标。
价格
Config Sync 指标使用 Google Cloud Managed Service for Prometheus 将指标加载到 Cloud Monitoring 中。Cloud Monitoring 会根据注入的样本数量收取这些指标的注入费用。
如需了解详情,请参阅 Cloud Monitoring 价格。
Config Sync 如何收集指标
Config Sync 使用 OpenCensus 创建和记录指标,并使用 OpenTelemetry 将其指标导出到 Prometheus 和 Cloud Monitoring。以下指南介绍了如何导出指标:
如需配置 OpenTelemetry Collector,Config Sync 默认会创建一个名为 otel-collector 的 ConfigMap。otel-collector Deployment 在 config-management-monitoring 命名空间中运行。
创建 otel-collector ConfigMap 会配置 prometheus 导出器,该导出器会公开一个供 Prometheus 扫描的指标端点。
当您在 GKE 上或在配置了 Google Cloud 凭据的其他 Kubernetes 环境中运行 Config Sync 时,Config Sync 会创建一个名为 otel-collector-google-cloud 的 ConfigMap。otel-collector-google-cloud 会替换 otel-collector ConfigMap 中的配置。Config Sync 会还原对 otel-collector 或 otel-collector-google-cloud ConfigMap 的任何更改。
创建 otel-collector-google-cloud ConfigMap 还会添加 cloudmonitoring 指标导出器(用于导出到 Cloud Monitoring)和 kubernetes 指标导出器(用于导出到 Google 的内部指标服务)。kubernetes 导出器会将所选的匿名化指标发送给 Google,以帮助改进 Config Sync。
Cloud Monitoring 会将您发送给它的指标存储在您的Google Cloud 项目中。cloudmonitoring 和 kubernetes 指标导出器使用相同的Google Cloud 服务账号,该账号需要具有向 Cloud Monitoring 写入数据的 IAM 权限。如需配置这些权限,请参阅为 Cloud Monitoring 授予指标写入权限。
OpenTelemetry 指标
Config Sync 和 Resource Group Controller 使用 OpenCensus 收集以下指标,并通过 OpenTelemetry 收集器提供这些指标。标记列列出了适用于每个指标的 Config Sync 特定标记。带有标记的指标代表多个测量结果,每个标记值组合对应一个。
Config Sync 指标
| 名称 | 类型 | 标签 | 说明 |
|---|---|---|---|
| api_duration_seconds | 分布 | operation、status | API 服务器调用的延迟时间分布。 |
| apply_duration_seconds | 分布 | status | 将从可靠来源声明的资源应用于集群的延迟时间分布。 |
| apply_operations_total | 计数 | operation、status、controller | 为将资源从可靠来源同步到集群而执行的操作总数。 |
| declared_resources | 最后一个值 | 从 Git 解析的已声明资源数量。 | |
| internal_errors_total | 计数 | 来源 | Config Sync 遇到的内部错误总数。如果没有发生内部错误,指标可能不会显示在查询结果中。 |
| last_sync_timestamp | 最后一个值 | status | 从 Git 最近一次同步的时间戳。 |
| parser_duration_seconds | 分布 | status、trigger、source | 从可靠来源同步到集群所涉及的不同阶段的延迟时间分布。 |
| pipeline_error_observed | 最后一个值 | name、reconciler、component | RootSync 和 RepoSync 自定义资源的状态。值 1 表示失败。 |
| reconcile_duration_seconds | 分布 | status | 由协调器管理器处理的协调事件的延迟时间分布。 |
| reconciler_errors | 最后一个值 | component、errorclass | 将资源从可靠来源同步到集群时遇到的错误数量。 |
| remediate_duration_seconds | 分布 | status | 补救器协调事件的延迟时间分布。 |
| resource_conflicts_total | 计数 | 因缓存资源和集群资源之间存在不匹配而导致的资源冲突总数。如果没有发生资源冲突,指标可能不会显示在查询结果中。 | |
| resource_fights_total | 计数 | 过于频繁同步的资源总数。任何高于零的结果都表示有问题。如需了解详情,请参阅 KNV2005:ResourceFightWarning。 如果没有发生资源争夺,指标可能不会显示在查询结果中。 |
资源组控制器指标
资源组控制器是 Config Sync 中的一个组件,它可跟踪代管式资源并检查每个资源是否准备就绪或已协调。您可以查看以下指标。
| 名称 | 类型 | 标签 | 说明 |
|---|---|---|---|
| rg_reconcile_duration_seconds | 分布 | stallreason | 协调 ResourceGroup CR 所需的时间分布 |
| resource_group_total | 最后一个值 | 当前的 ResourceGroup CR 数量 | |
| resource_count | 最后一个值 | resourcegroup | 一个 ResourceGroup 跟踪的资源总数 |
| ready_resource_count | 最后一个值 | resourcegroup | ResourceGroup 中准备就绪的资源总数 |
| resource_ns_count | 最后一个值 | resourcegroup | ResourceGroup 中的资源使用的命名空间数量 |
| cluster_scoped_resource_count | 最后一个值 | resourcegroup | ResourceGroup 中集群范围的资源的数量 |
| crd_count | 最后一个值 | resourcegroup | ResourceGroup 中的 CRD 数量 |
| kcc_resource_count | 最后一个值 | resourcegroup | ResourceGroup 中的 KCC 资源总数 |
| pipeline_error_observed | 最后一个值 | name、reconciler、component | RootSync 和 RepoSync 自定义资源的状态。值 1 表示失败。 |
Config Sync 指标标签
指标标签可用于聚合 Cloud Monitoring 和 Prometheus 中的指标数据。可从 Monitoring 控制台中的“分组依据”下拉列表选择这些指标。
如需详细了解 Cloud Monitoring 标签和 Prometheus 指标标签,请参阅指标模型的组成部分和 Prometheus 数据模型。
指标标签
Config Sync 和 Resource Group Controller 指标会使用以下标签,这些标签在使用 Cloud Monitoring 和 Prometheus 进行监控时可用。
| 名称 | 值 | 说明 |
|---|---|---|
operation |
create、patch、update、delete | 执行的操作类型 |
status |
success、error | 操作的执行状态 |
reconciler |
rootsync、reposync | 协调器的类型 |
source |
parser、differ、remediator | 内部错误的来源 |
trigger |
retry、watchUpdate、managementConflict、resync、reimport | 协调事件的触发因素 |
name |
协调器的名称 | 协调器的名称 |
component |
parsing、source、sync、rendering、readiness | 协调所在组件/当前阶段的名称 |
container |
reconciler、git-sync | 容器的名称 |
resource |
cpu、memory | 资源的类型 |
controller |
applier、remediator | 根协调器或命名空间协调器中的控制器名称 |
type |
任何 Kubernetes 资源,例如 ClusterRole、Namespace、NetworkPolicy、Role 等。 | Kubernetes API 的类型 |
commit |
---- | 最近同步的提交的哈希值 |
资源标签
发送到 Prometheus 和 Cloud Monitoring 的 Config Sync 指标设置了以下指标标签来标识来源 Pod:
| 名称 | 说明 |
|---|---|
k8s.node.name |
托管 Kubernetes Pod 的节点的名称 |
k8s.pod.namespace |
Pod 的命名空间 |
k8s.pod.uid |
Pod 的 UID |
k8s.pod.ip |
Pod 的 IP |
k8s.deployment.name |
拥有 Pod 的 Deployment 的名称 |
从 reconciler Pod 发送到 Prometheus 和 Cloud Monitoring 的 Config Sync 指标还设置了以下指标标签来标识用于配置协调器的 RootSync 或 RepoSync:
| 名称 | 说明 |
|---|---|
configsync.sync.kind |
配置此协调器的资源种类:RootSync 或 RepoSync |
configsync.sync.name |
配置此协调器的 RootSync 或 RepoSync 的名称 |
configsync.sync.namespace |
配置此协调器的 RootSync 或 RepoSync 的命名空间 |
Cloud Monitoring 资源标签
Cloud Monitoring 资源标签用于将存储空间中的指标编入索引,这意味着它们对基数的影响可以忽略不计,与指标标签不同,基数是重要的性能问题。如需了解详情,请参阅受监控的资源类型。
k8s_container 资源类型设置了以下资源标签来标识来源容器:
| 名称 | 说明 |
|---|---|
container_name |
容器的名称 |
pod_name |
Pod 的名称 |
namespace_name |
Pod 的命名空间 |
location |
托管节点的集群的区域或地区 |
cluster_name |
托管节点的集群的名称 |
project |
托管集群的项目的 ID |
配置自定义指标过滤
您可以调整 Config Sync 导出到 Prometheus、Cloud Monitoring 和 Google 内部监控服务的自定义指标。调整自定义指标,以微调纳入的指标或配置不同的后端。
如需修改自定义指标,请创建并修改名为 otel-collector-custom 的 ConfigMap。使用此 ConfigMap 可确保 Config Sync 不会还原您所做的任何修改。如果您修改 otel-collector 或 otel-collector-google-cloud ConfigMap,Config Sync 会还原所有更改。
如需查看有关如何调整此 ConfigMap 的示例,请参阅开源 Config Sync 文档中的自定义指标过滤。
了解 pipeline_error_observed 指标
pipeline_error_observed 指标可帮助您快速识别未同步或包含未协调为所需状态的资源的 RepoSync 或 RootSync CR。
对于 RootSync 或 RepoSync 的成功同步,具有所有组件(
rendering、source、sync、readiness)的指标的值显示为 0。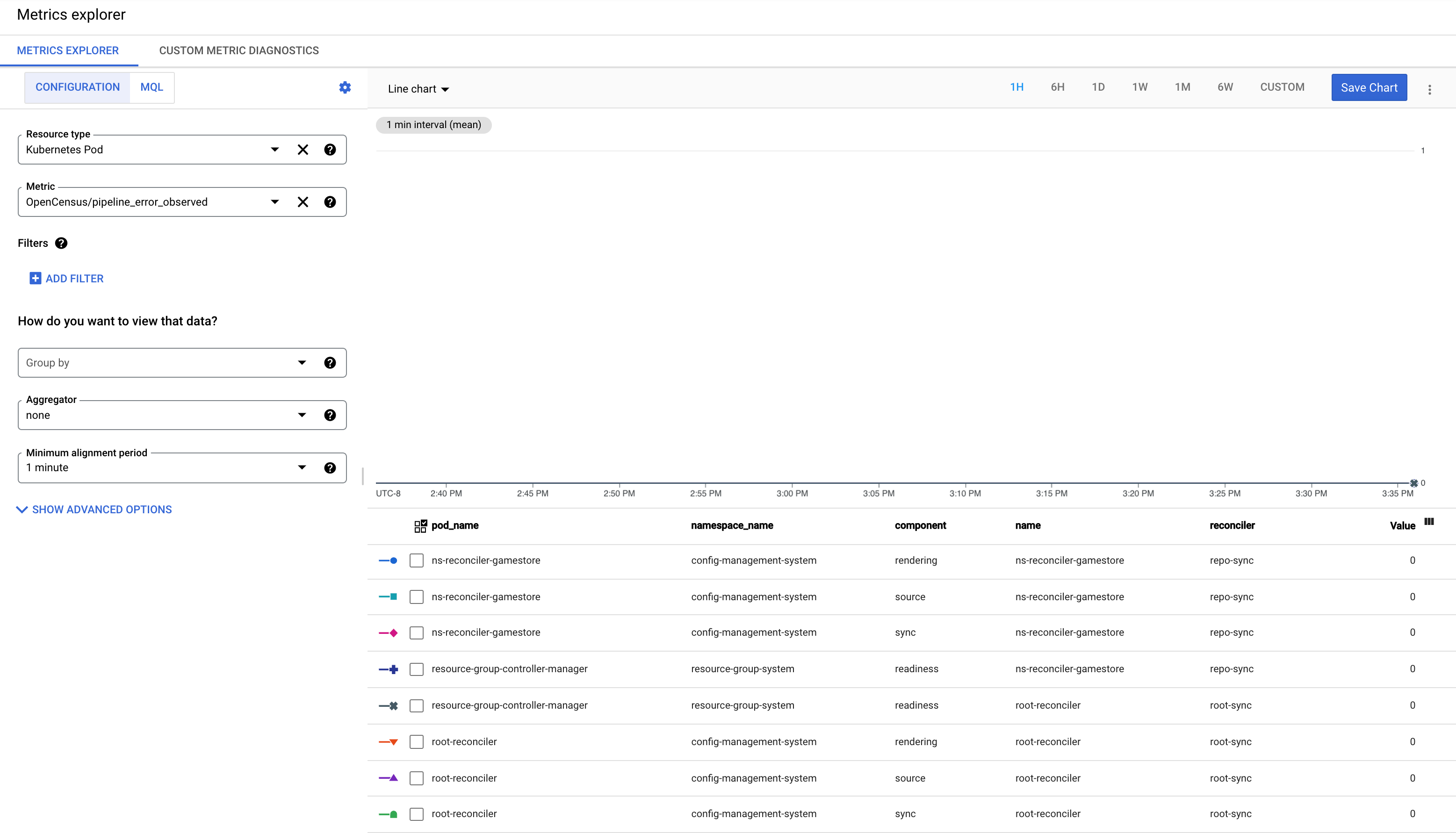
当最新提交使自动呈现失败时,包含组件
rendering的指标的值为 1。在签出最新提交遇到错误或最新提交包含无效配置时,具有组件
source的指标的值显示为 1。当某个资源无法应用于集群时,具有组件
sync的指标的值显示为 1。如果应用资源,但资源无法达到其所需状态,则具有组件
readiness的指标的值显示为 1。例如,Deployment 已应用于集群,但相应的 pod 却未成功创建。
后续步骤
- 详细了解如何监控 RootSync 和 RepoSync 对象。
- 了解如何使用 Config Sync SLI。