
Este tutorial mostra como publicar grandes modelos de linguagem (LLMs) usando unidades de processamento tensor (TPUs) no Google Kubernetes Engine (GKE) com a framework de publicação vLLM. Neste tutorial, vai publicar o Llama 3.1 70b, usar a TPU Trillium e configurar o dimensionamento automático de pods horizontal usando métricas do servidor vLLM.
Este documento é um bom ponto de partida se precisar do controlo detalhado, da escalabilidade, da resiliência, da portabilidade e da rentabilidade do Kubernetes gerido quando implementa e publica as suas cargas de trabalho de IA/ML.
Contexto
Ao usar a TPU Trillium no GKE, pode implementar uma solução de publicação robusta e pronta para produção com todas as vantagens do Kubernetes gerido, incluindo escalabilidade eficiente e maior disponibilidade. Esta secção descreve as principais tecnologias usadas neste guia.
TPU Trillium
As TPUs são circuitos integrados específicos da aplicação (ASICs) desenvolvidos pela Google. As TPUs são usadas para acelerar a aprendizagem automática e os modelos de IA criados com frameworks como o TensorFlow, o PyTorch e o JAX. Este tutorial usa a TPU Trillium, que é a TPU de sexta geração da Google.
Antes de usar as TPUs no GKE, recomendamos que conclua o seguinte percurso de aprendizagem:
- Saiba mais sobre a arquitetura do sistema da TPU Trillium.
- Saiba mais sobre as TPUs no GKE.
vLLM
O vLLM é uma framework de código aberto altamente otimizada para publicar GMLs. O vLLM pode aumentar a taxa de transferência de publicação em TPUs, com funcionalidades como as seguintes:
- Implementação do transformador otimizada com PagedAttention.
- Processamento em lote contínuo para melhorar o débito geral da publicação.
- Paralelismo de tensores e publicação distribuída em várias UTPs.
Para saber mais, consulte a documentação do vLLM.
Cloud Storage FUSE
O Cloud Storage FUSE fornece acesso do seu cluster do GKE ao Cloud Storage para pesos do modelo que residem em contentores de armazenamento de objetos. Neste tutorial, o contentor do Cloud Storage criado vai estar inicialmente vazio. Quando o vLLM é iniciado, o GKE transfere o modelo do Hugging Face e coloca em cache os pesos no contentor do Cloud Storage. No reinício do pod ou no aumento da escala da implementação, os carregamentos de modelos subsequentes transferem dados em cache do contentor do Cloud Storage, tirando partido das transferências paralelas para um desempenho ideal.
Para saber mais, consulte a documentação do controlador CSI FUSE do Cloud Storage.
Objetivos
Este tutorial destina-se a engenheiros de MLOps ou DevOps, ou administradores de plataformas que queiram usar as capacidades de orquestração do GKE para publicar LLMs.
Este tutorial abrange os seguintes passos:
- Crie um cluster do GKE com a topologia de TPU Trillium recomendada com base nas caraterísticas do modelo.
- Implemente a framework vLLM num node pool no seu cluster.
- Use a framework vLLM para publicar o Llama 3.1 70b através de um equilibrador de carga.
- Configure a escala automática horizontal de pods através das métricas do servidor vLLM.
- Publique o modelo.
Antes de começar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the required API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the required API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Make sure that you have the following role or roles on the project:
roles/container.admin,roles/iam.serviceAccountAdmin,roles/iam.securityAdmin,roles/artifactregistry.writer,roles/container.clusterAdminCheck for the roles
-
In the Google Cloud console, go to the IAM page.
Go to IAM - Select the project.
-
In the Principal column, find all rows that identify you or a group that you're included in. To learn which groups you're included in, contact your administrator.
- For all rows that specify or include you, check the Role column to see whether the list of roles includes the required roles.
Grant the roles
-
In the Google Cloud console, go to the IAM page.
Aceder ao IAM - Selecione o projeto.
- Clique em Conceder acesso.
-
No campo Novos responsáveis, introduza o identificador do utilizador. Normalmente, este é o endereço de email de uma Conta Google.
- Clique em Selecionar uma função e, de seguida, pesquise a função.
- Para conceder funções adicionais, clique em Adicionar outra função e adicione cada função adicional.
- Clique em Guardar.
- Crie uma conta Hugging Face, se ainda não tiver uma.
- Certifique-se de que o seu projeto tem quota suficiente para o Cloud TPU no GKE.
- Clique em O seu perfil > Definições > Tokens de acesso.
- Selecione Novo token.
- Especifique um nome à sua escolha e uma função de, pelo menos,
Read. - Selecione Gerar um token.
Na Google Cloud consola, inicie uma sessão do Cloud Shell clicando em
 Ativar Cloud Shell na Google Cloud consola. Esta ação inicia uma sessão no painel inferior da consola. Google Cloud
Ativar Cloud Shell na Google Cloud consola. Esta ação inicia uma sessão no painel inferior da consola. Google Cloud Defina as variáveis de ambiente predefinidas:
gcloud config set project PROJECT_ID && \ gcloud config set billing/quota_project PROJECT_ID && \ export PROJECT_ID=$(gcloud config get project) && \ export PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)") && \ export CLUSTER_NAME=CLUSTER_NAME && \ export CONTROL_PLANE_LOCATION=CONTROL_PLANE_LOCATION && \ export ZONE=ZONE && \ export HF_TOKEN=HUGGING_FACE_TOKEN && \ export CLUSTER_VERSION=CLUSTER_VERSION && \ export GSBUCKET=GSBUCKET && \ export KSA_NAME=KSA_NAME && \ export NAMESPACE=NAMESPACESubstitua os seguintes valores:
- PROJECT_ID : o seu Google Cloud ID do projeto.
- CLUSTER_NAME : o nome do seu cluster do GKE.
- CONTROL_PLANE_LOCATION: a região do Compute Engine do plano de controlo do seu cluster. Indique uma região que suporte a TPU Trillium (v6e).
- ZONE : uma zona que suporta a TPU Trillium (v6e).
- CLUSTER_VERSION : a versão do GKE, que tem de suportar o tipo de máquina que quer usar. Tenha em atenção que a versão predefinida do GKE pode não ter disponibilidade para a TPU de destino. A TPU Trillium (v6e) é suportada nas versões do GKE 1.31.2-gke.1115000 ou posteriores.
- GSBUCKET : o nome do contentor do Cloud Storage a usar para o Cloud Storage FUSE.
- KSA_NAME : o nome da ServiceAccount do Kubernetes que é usada para aceder aos contentores do Cloud Storage. O acesso ao contentor é necessário para o Cloud Storage FUSE funcionar.
- NAMESPACE : o namespace do Kubernetes onde quer implementar os recursos do vLLM.
Crie um cluster do GKE Autopilot:
gcloud container clusters create-auto ${CLUSTER_NAME} \ --cluster-version=${CLUSTER_VERSION} \ --location=${CONTROL_PLANE_LOCATION}Crie um cluster padrão do GKE:
gcloud container clusters create ${CLUSTER_NAME} \ --project=${PROJECT_ID} \ --location=${CONTROL_PLANE_LOCATION} \ --node-locations=${ZONE} \ --cluster-version=${CLUSTER_VERSION} \ --workload-pool=${PROJECT_ID}.svc.id.goog \ --addons GcsFuseCsiDriverCrie um node pool de fatia de TPU:
gcloud container node-pools create tpunodepool \ --location=${CONTROL_PLANE_LOCATION} \ --node-locations=${ZONE} \ --num-nodes=1 \ --machine-type=ct6e-standard-8t \ --cluster=${CLUSTER_NAME} \ --enable-autoscaling --total-min-nodes=1 --total-max-nodes=2O GKE cria os seguintes recursos para o GML:
- Um cluster padrão do GKE que usa a federação do Workload Identity para o GKE e tem o controlador CSI do FUSE do Cloud Storage ativado.
- Um conjunto de nós da TPU Trillium com um tipo de máquina
ct6e-standard-8t. Este conjunto de nós tem um nó, oito chips de TPU e o escalonamento automático ativado.
Crie um espaço de nomes. Pode ignorar este passo se estiver a usar o espaço de nomes
default:kubectl create namespace ${NAMESPACE}Crie um segredo do Kubernetes que contenha o token do Hugging Face, execute o seguinte comando:
kubectl create secret generic hf-secret \ --from-literal=hf_api_token=${HF_TOKEN} \ --namespace ${NAMESPACE}Crie a conta de serviço do Kubernetes:
kubectl create serviceaccount ${KSA_NAME} --namespace ${NAMESPACE}Conceda acesso de leitura/escrita à conta de serviço do Kubernetes para aceder ao contentor do Cloud Storage:
gcloud storage buckets add-iam-policy-binding gs://${GSBUCKET} \ --member "principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/${NAMESPACE}/sa/${KSA_NAME}" \ --role "roles/storage.objectUser"Em alternativa, pode conceder acesso de leitura/escrita a todos os contentores do Cloud Storage no projeto:
gcloud projects add-iam-policy-binding ${PROJECT_ID} \ --member "principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/${NAMESPACE}/sa/${KSA_NAME}" \ --role "roles/storage.objectUser"O GKE cria os seguintes recursos para o GML:
- Um contentor do Cloud Storage para armazenar o modelo transferido e a cache de compilação. Um controlador CSI FUSE do Cloud Storage lê o conteúdo do contentor.
- Volumes com a colocação em cache de ficheiros ativada e a funcionalidade de transferência paralela do Cloud Storage FUSE.
Prática recomendada: Use uma cache de ficheiros suportada por
tmpfsouHyperdisk / Persistent Diskconsoante o tamanho esperado dos conteúdos do modelo, por exemplo, ficheiros de ponderação. Neste tutorial, usa a cache de ficheiros do FUSE do Cloud Storage suportada por RAM.Inspecione o seguinte manifesto de implementação guardado como
vllm-llama3-70b.yaml, que usa uma única réplica:Se aumentar a implementação para várias réplicas, as escritas simultâneas no
VLLM_XLA_CACHE_PATHcausam o erro:RuntimeError: filesystem error: cannot create directories. Para evitar este erro, tem duas opções:Remova a localização da cache XLA removendo o seguinte bloco do YAML de implementação. Isto significa que todas as réplicas vão recompilar a cache.
- name: VLLM_XLA_CACHE_PATH value: "/data"Dimensione a implementação para
1e aguarde que a primeira réplica fique pronta e escreva na cache XLA. Em seguida, expanda para réplicas adicionais. Isto permite que as restantes réplicas leiam a cache, sem tentar escrevê-la.
Aplique o manifesto executando o seguinte comando:
kubectl apply -f vllm-llama3-70b.yaml -n ${NAMESPACE}Veja os registos do servidor de modelos em execução:
kubectl logs -f -l app=vllm-tpu -n ${NAMESPACE}O resultado deve ser semelhante ao seguinte:
INFO: Started server process [1] INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)Para obter o endereço IP externo do serviço VLLM, execute o seguinte comando:
export vllm_service=$(kubectl get service vllm-service -o jsonpath='{.status.loadBalancer.ingress[0].ip}' -n ${NAMESPACE})Interagir com o modelo através de
curl:curl http://$vllm_service:8000/v1/completions \ -H "Content-Type: application/json" \ -d '{ "model": "meta-llama/Llama-3.1-70B", "prompt": "San Francisco is a", "max_tokens": 7, "temperature": 0 }'O resultado deve ser semelhante ao seguinte:
{"id":"cmpl-6b4bb29482494ab88408d537da1e608f","object":"text_completion","created":1727822657,"model":"meta-llama/Llama-3-8B","choices":[{"index":0,"text":" top holiday destination featuring scenic beauty and","logprobs":null,"finish_reason":"length","stop_reason":null,"prompt_logprobs":null}],"usage":{"prompt_tokens":5,"total_tokens":12,"completion_tokens":7}}Configure o adaptador do Stackdriver de métricas personalizadas no seu cluster:
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/k8s-stackdriver/master/custom-metrics-stackdriver-adapter/deploy/production/adapter_new_resource_model.yamlAdicione a função Leitor do Monitoring à conta de serviço que o adaptador do Stackdriver de métricas personalizadas usa:
gcloud projects add-iam-policy-binding projects/${PROJECT_ID} \ --role roles/monitoring.viewer \ --member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/custom-metrics/sa/custom-metrics-stackdriver-adapterGuarde o seguinte manifesto como
vllm_pod_monitor.yaml:Aplique-o ao cluster:
kubectl apply -f vllm_pod_monitor.yaml -n ${NAMESPACE}Execute um script bash (
load.sh) para enviarNpedidos paralelos ao ponto final vLLM:#!/bin/bash N=PARALLEL_PROCESSES export vllm_service=$(kubectl get service vllm-service -o jsonpath='{.status.loadBalancer.ingress[0].ip}' -n ${NAMESPACE}) for i in $(seq 1 $N); do while true; do curl http://$vllm_service:8000/v1/completions -H "Content-Type: application/json" -d '{"model": "meta-llama/Llama-3.1-70B", "prompt": "Write a story about san francisco", "max_tokens": 1000, "temperature": 0}' done & # Run in the background done waitSubstitua PARALLEL_PROCESSES pelo número de processos paralelos que quer executar.
Execute o script bash:
chmod +x load.sh nohup ./load.sh &Na Google Cloud consola, aceda à página Explorador de métricas.
Clique em < > PromQL.
Introduza a seguinte consulta para observar as métricas de tráfego:
vllm:num_requests_waiting{cluster='CLUSTER_NAME'}num_requests_waiting: esta métrica está relacionada com o número de pedidos à espera na fila do servidor do modelo. Este número começa a aumentar visivelmente quando a cache de KV está cheia.gpu_cache_usage_perc: esta métrica está relacionada com a utilização da cache KV, que está diretamente correlacionada com o número de pedidos que estão a ser processados para um determinado ciclo de inferência no servidor do modelo. Tenha em atenção que esta métrica funciona da mesma forma em GPUs e TPUs, embora esteja associada ao esquema de nomenclatura de GPUs.Guarde o seguinte manifesto como
vllm-hpa.yaml:As métricas vLLM no serviço gerido da Google Cloud para Prometheus seguem o formato
vllm:metric_name.Prática recomendada: Use
num_requests_waitingpara dimensionar o débito. Usegpu_cache_usage_percpara exemplos de utilização de TPU sensíveis à latência.Implemente a configuração do redimensionador automático horizontal de pods:
kubectl apply -f vllm-hpa.yaml -n ${NAMESPACE}O GKE agenda outro pod para implementação, o que aciona o escalador automático do conjunto de nós para adicionar um segundo nó antes de implementar a segunda réplica do vLLM.
Acompanhe o progresso do ajuste de escala automático de pods:
kubectl get hpa --watch -n ${NAMESPACE}O resultado é semelhante ao seguinte:
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE vllm-hpa Deployment/vllm-tpu <unknown>/10 1 2 0 6s vllm-hpa Deployment/vllm-tpu 34972m/10 1 2 1 16s vllm-hpa Deployment/vllm-tpu 25112m/10 1 2 2 31s vllm-hpa Deployment/vllm-tpu 35301m/10 1 2 2 46s vllm-hpa Deployment/vllm-tpu 25098m/10 1 2 2 62s vllm-hpa Deployment/vllm-tpu 35348m/10 1 2 2 77sAguarde 10 minutos e repita os passos na secção Verifique se o serviço gerido do Google Cloud para Prometheus introduz as métricas. O serviço gerido do Google Cloud para Prometheus ingere agora as métricas de ambos os pontos finais do vLLM.
- Saiba mais sobre as TPUs no GKE.
- Saiba mais sobre as métricas disponíveis para configurar o Horizontal Pod Autoscaler.
- Explore o repositório do GitHub do vLLM e a documentação.
Prepare o ambiente
Nesta secção, aprovisiona os recursos de que precisa para implementar o vLLM e o modelo.
Aceda ao modelo
Tem de assinar o contrato de consentimento para usar o Llama 3.1 70b no repositório do Hugging Face.
Gere um token de acesso
Se ainda não tiver um, gere um novo token do Hugging Face:
Inicie o Cloud Shell
Neste tutorial, vai usar o Cloud Shell para gerir recursos alojados no Google Cloud. O Cloud Shell é pré-instalado com o software de que precisa para este tutorial, incluindo o
kubectle a CLI gcloud.Para configurar o seu ambiente com o Cloud Shell, siga estes passos:
Crie um cluster do GKE
Pode publicar MDIs em TPUs num cluster do GKE Autopilot ou Standard. Recomendamos que use um cluster do Autopilot para uma experiência do Kubernetes totalmente gerida. Para escolher o modo de funcionamento do GKE mais adequado às suas cargas de trabalho, consulte o artigo Escolha um modo de funcionamento do GKE.
Piloto automático
Standard
Configure o kubectl para comunicar com o seu cluster
Para configurar o kubectl para comunicar com o cluster, execute o seguinte comando:
gcloud container clusters get-credentials ${CLUSTER_NAME} --location=${CONTROL_PLANE_LOCATION}Crie um segredo do Kubernetes para as credenciais do Hugging Face
Crie um contentor do Cloud Storage
No Cloud Shell, execute o seguinte comando:
gcloud storage buckets create gs://${GSBUCKET} \ --uniform-bucket-level-accessIsto cria um contentor do Cloud Storage para armazenar os ficheiros do modelo que transfere do Hugging Face.
Configure uma conta de serviço do Kubernetes para aceder ao contentor
Implemente o servidor de modelos vLLM
Para implementar o servidor do modelo vLLM, este tutorial usa uma implementação do Kubernetes. Uma implementação é um objeto da API Kubernetes que lhe permite executar várias réplicas de pods distribuídos entre os nós num cluster.
Publique o modelo
Configure o escalador automático personalizado
Nesta secção, configura o escalamento automático de pods horizontal com métricas Prometheus personalizadas. Usa o serviço gerido do Google Cloud para métricas do Prometheus a partir do servidor vLLM.
Para saber mais, consulte o Google Cloud Managed Service for Prometheus. Esta opção deve estar ativada por predefinição no cluster do GKE.
Crie carga no ponto final do vLLM
Crie carga para o servidor vLLM para testar como o GKE é dimensionado automaticamente com uma métrica vLLM personalizada.
Verifique se o Google Cloud Managed Service for Prometheus ingere as métricas
Depois de o serviço gerido do Google Cloud para Prometheus extrair as métricas e de adicionar carga ao ponto final da vLLM, pode ver as métricas no Cloud Monitoring.
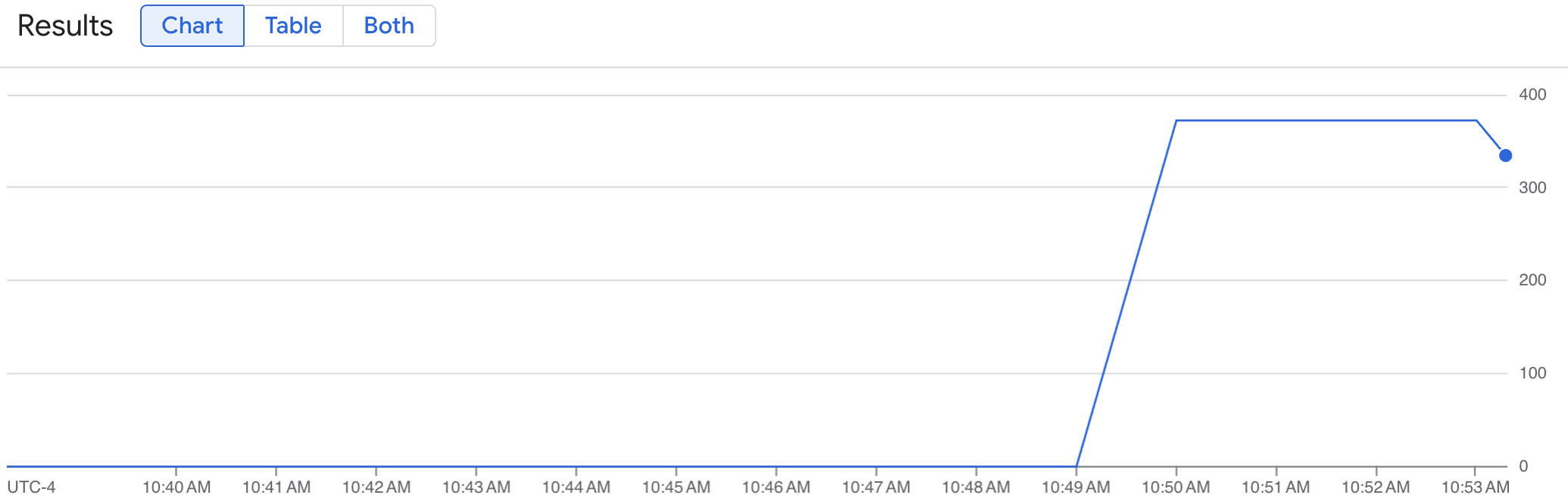
Um gráfico de linhas mostra a sua métrica de vLLM (num_requests_waiting) medida ao longo do tempo. A métrica vLLM aumenta de 0 (pré-carregamento) para um valor (pós-carregamento). Este gráfico confirma que as suas métricas de vLLM estão a ser carregadas no Google Cloud Managed Service for Prometheus. O gráfico de exemplo seguinte mostra um valor de pré-carregamento inicial de 0, que atinge um valor de pós-carregamento máximo de quase 400 no prazo de um minuto.
Implemente a configuração do redimensionador automático horizontal de pods
Ao decidir em função de que métrica fazer o dimensionamento automático, recomendamos as seguintes métricas para a TPU vLLM:
Recomendamos que use
num_requests_waitingquando otimizar em função do débito e do custo, e quando os seus alvos de latência forem alcançáveis com o débito máximo do servidor do modelo.Recomendamos que use
gpu_cache_usage_percquando tiver cargas de trabalho sensíveis à latência em que o escalamento baseado em filas não é suficientemente rápido para satisfazer os seus requisitos.Para uma explicação mais detalhada, consulte o artigo Práticas recomendadas para o dimensionamento automático de cargas de trabalho de inferência de modelos de linguagem (conteúdo extenso) (MDI/CE) com as TPUs.
Quando selecionar um
averageValuealvo para a configuração de HPA, tem de o determinar experimentalmente. Consulte a publicação no blogue Save on GPUs: Smarter autoscaling for your GKE inferencing workloads para ver ideias adicionais sobre como otimizar esta parte. O profile-generator usado nesta publicação no blogue também funciona para a TPU vLLM.Nas instruções seguintes, implementa a configuração do HPA através da métrica num_requests_waiting. Para fins de demonstração, define a métrica para um valor baixo, para que a configuração do HPA dimensione as réplicas do vLLM para duas. Para implementar a configuração do redimensionador automático horizontal de pods através de num_requests_waiting, siga estes passos:
Limpar
Para evitar incorrer em custos na sua conta do Google Cloud pelos recursos usados neste tutorial, elimine o projeto que contém os recursos ou mantenha o projeto e elimine os recursos individuais.
Elimine os recursos implementados
Para evitar incorrer em custos na sua Google Cloud conta pelos recursos que criou neste guia, execute os seguintes comandos:
ps -ef | grep load.sh | awk '{print $2}' | xargs -n1 kill -9gcloud container clusters delete ${CLUSTER_NAME} \ --location=${CONTROL_PLANE_LOCATION}O que se segue?
-