
En este tutorial se muestra cómo servir modelos de lenguaje extensos (LLMs) mediante unidades de procesamiento de tensor (TPUs) en Google Kubernetes Engine (GKE) con el framework de servicio vLLM. En este tutorial, se sirve Llama 3.1 70b, se usa TPU Trillium y se configura el autoescalado de pods horizontal mediante métricas del servidor vLLM.
Este documento es un buen punto de partida si necesitas el control granular, la escalabilidad, la resiliencia, la portabilidad y la rentabilidad de Kubernetes gestionado al desplegar y servir tus cargas de trabajo de IA o aprendizaje automático.
Fondo
Si usas TPU Trillium en GKE, puedes implementar una solución de servicio estable y lista para producción con todas las ventajas de Kubernetes gestionado, como una escalabilidad eficiente y una mayor disponibilidad. En esta sección se describen las tecnologías clave que se usan en esta guía.
TPU Trillium
Las TPUs son circuitos integrados para aplicaciones específicas (ASIC) desarrollados a medida por Google. Las TPUs se usan para acelerar los modelos de aprendizaje automático y de IA creados con frameworks como TensorFlow, PyTorch y JAX. En este tutorial se usa la TPU Trillium, que es la TPU de sexta generación de Google.
Antes de usar las TPUs en GKE, te recomendamos que completes el siguiente plan de formación:
- Consulta información sobre la arquitectura del sistema de TPU Trillium.
- Consulta información sobre las TPUs en GKE.
vLLM
vLLM es un framework de código abierto muy optimizado para servir LLMs. vLLM puede aumentar el rendimiento del servicio en las TPUs con funciones como las siguientes:
- Implementación optimizada de Transformer con PagedAttention.
- Agrupación continua para mejorar el rendimiento general del servicio.
- Paralelismo de tensores y servicio distribuido en varias TPUs.
Para obtener más información, consulta la documentación de vLLM.
FUSE de Cloud Storage
Cloud Storage FUSE proporciona acceso desde tu clúster de GKE a Cloud Storage para los pesos del modelo que residen en segmentos de almacenamiento de objetos. En este tutorial, el segmento de Cloud Storage creado estará vacío al principio. Cuando se inicia vLLM, GKE descarga el modelo de Hugging Face y almacena en caché los pesos en el segmento de Cloud Storage. Cuando se reinicie un pod o se aumente la escala de una implementación, las cargas de modelos posteriores descargarán los datos almacenados en caché del segmento de Cloud Storage, lo que aprovechará las descargas paralelas para optimizar el rendimiento.
Para obtener más información, consulta la documentación del controlador CSI de FUSE de Cloud Storage.
Objetivos
Este tutorial está dirigido a ingenieros de MLOps o DevOps, o bien a administradores de plataformas que quieran usar las funciones de orquestación de GKE para ofrecer LLMs.
Este tutorial abarca los siguientes pasos:
- Crea un clúster de GKE con la topología de TPU Trillium recomendada en función de las características del modelo.
- Despliega el framework vLLM en un grupo de nodos de tu clúster.
- Usa el framework vLLM para servir Llama 3.1 70b mediante un balanceador de carga.
- Configura el autoescalado horizontal de pods con métricas del servidor vLLM.
- Sirve el modelo.
Antes de empezar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the required API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the required API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Make sure that you have the following role or roles on the project:
roles/container.admin,roles/iam.serviceAccountAdmin,roles/iam.securityAdmin,roles/artifactregistry.writer,roles/container.clusterAdminCheck for the roles
-
In the Google Cloud console, go to the IAM page.
Go to IAM - Select the project.
-
In the Principal column, find all rows that identify you or a group that you're included in. To learn which groups you're included in, contact your administrator.
- For all rows that specify or include you, check the Role column to see whether the list of roles includes the required roles.
Grant the roles
-
In the Google Cloud console, go to the IAM page.
Ir a IAM - Selecciona el proyecto.
- Haz clic en Conceder acceso.
-
En el campo Nuevos principales, introduce tu identificador de usuario. Normalmente, se trata de la dirección de correo de una cuenta de Google.
- Haz clic en Selecciona un rol y busca el rol.
- Para conceder más roles, haz clic en Añadir otro rol y añade cada rol adicional.
- Haz clic en Guardar.
- Crea una cuenta de Hugging Face si aún no tienes una.
- Asegúrate de que tu proyecto tiene suficiente cuota para usar Cloud TPU en GKE.
- Haz clic en Tu perfil > Configuración > Tokens de acceso.
- Selecciona New Token (Nuevo token).
- Especifica el nombre que quieras y un rol de al menos
Read. - Selecciona Generar un token.
En la Google Cloud consola, inicia una sesión de Cloud Shell haciendo clic en
 Activar Cloud Shell en la Google Cloud consola. Se iniciará una sesión en el panel inferior de la Google Cloud consola.
Activar Cloud Shell en la Google Cloud consola. Se iniciará una sesión en el panel inferior de la Google Cloud consola.Define las variables de entorno predeterminadas:
gcloud config set project PROJECT_ID && \ gcloud config set billing/quota_project PROJECT_ID && \ export PROJECT_ID=$(gcloud config get project) && \ export PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)") && \ export CLUSTER_NAME=CLUSTER_NAME && \ export CONTROL_PLANE_LOCATION=CONTROL_PLANE_LOCATION && \ export ZONE=ZONE && \ export HF_TOKEN=HUGGING_FACE_TOKEN && \ export CLUSTER_VERSION=CLUSTER_VERSION && \ export GSBUCKET=GSBUCKET && \ export KSA_NAME=KSA_NAME && \ export NAMESPACE=NAMESPACESustituye los siguientes valores:
- PROJECT_ID : tu Google Cloud ID de proyecto.
- CLUSTER_NAME : el nombre de tu clúster de GKE.
- CONTROL_PLANE_LOCATION: la región de Compute Engine del plano de control de tu clúster. Proporciona una región que admita TPU Trillium (v6e).
- ZONE : una zona que admite TPU Trillium (v6e).
- CLUSTER_VERSION : la versión de GKE, que debe ser compatible con el tipo de máquina que quieras usar. Ten en cuenta que es posible que la versión predeterminada de GKE no esté disponible para tu TPU de destino. TPU Trillium (v6e) es compatible con las versiones de GKE 1.31.2-gke.1115000 o posteriores.
- GSBUCKET : el nombre del segmento de Cloud Storage que se va a usar en Cloud Storage FUSE.
- KSA_NAME : el nombre de la cuenta de servicio de Kubernetes que se usa para acceder a los segmentos de Cloud Storage. Para que Cloud Storage FUSE funcione, es necesario tener acceso al segmento.
- NAMESPACE : el espacio de nombres de Kubernetes en el que quieres desplegar los recursos de vLLM.
Crea un clúster de Autopilot de GKE:
gcloud container clusters create-auto ${CLUSTER_NAME} \ --cluster-version=${CLUSTER_VERSION} \ --location=${CONTROL_PLANE_LOCATION}Crea un clúster Estándar de GKE:
gcloud container clusters create ${CLUSTER_NAME} \ --project=${PROJECT_ID} \ --location=${CONTROL_PLANE_LOCATION} \ --node-locations=${ZONE} \ --cluster-version=${CLUSTER_VERSION} \ --workload-pool=${PROJECT_ID}.svc.id.goog \ --addons GcsFuseCsiDriverCrea un grupo de nodos de segmento de TPU:
gcloud container node-pools create tpunodepool \ --location=${CONTROL_PLANE_LOCATION} \ --node-locations=${ZONE} \ --num-nodes=1 \ --machine-type=ct6e-standard-8t \ --cluster=${CLUSTER_NAME} \ --enable-autoscaling --total-min-nodes=1 --total-max-nodes=2GKE crea los siguientes recursos para el LLM:
- Un clúster Estándar de GKE que use Workload Identity Federation for GKE y tenga habilitado el controlador CSI de Cloud Storage FUSE.
- Un grupo de nodos de TPU Trillium con un tipo de máquina
ct6e-standard-8t. Este grupo de nodos tiene un nodo, ocho chips de TPU y el autoescalado habilitado.
Crea un espacio de nombres. Puedes saltarte este paso si usas el espacio de nombres
default:kubectl create namespace ${NAMESPACE}Crea un secreto de Kubernetes que contenga el token de Hugging Face. Para ello, ejecuta el siguiente comando:
kubectl create secret generic hf-secret \ --from-literal=hf_api_token=${HF_TOKEN} \ --namespace ${NAMESPACE}Crea la cuenta de servicio de Kubernetes:
kubectl create serviceaccount ${KSA_NAME} --namespace ${NAMESPACE}Concede acceso de lectura y escritura a la cuenta de servicio de Kubernetes para acceder al segmento de Cloud Storage:
gcloud storage buckets add-iam-policy-binding gs://${GSBUCKET} \ --member "principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/${NAMESPACE}/sa/${KSA_NAME}" \ --role "roles/storage.objectUser"También puedes conceder acceso de lectura y escritura a todos los segmentos de Cloud Storage del proyecto:
gcloud projects add-iam-policy-binding ${PROJECT_ID} \ --member "principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/${NAMESPACE}/sa/${KSA_NAME}" \ --role "roles/storage.objectUser"GKE crea los siguientes recursos para el LLM:
- Un segmento de Cloud Storage para almacenar el modelo descargado y la caché de compilación. Un controlador CSI de FUSE de Cloud Storage lee el contenido del segmento.
- Volúmenes con el almacenamiento en caché de archivos habilitado y la función de descarga paralela de Cloud Storage FUSE.
Práctica recomendada: Usa una caché de archivos respaldada por
tmpfsoHyperdisk / Persistent Disk, según el tamaño previsto del contenido del modelo (por ejemplo, los archivos de pesos). En este tutorial, se usa la caché de archivos de Cloud Storage FUSE respaldada por RAM.Inspecciona el siguiente manifiesto de Deployment guardado como
vllm-llama3-70b.yaml, que usa una sola réplica:Si aumentas el número de réplicas de la implementación, las escrituras simultáneas en
VLLM_XLA_CACHE_PATHprovocarán el errorRuntimeError: filesystem error: cannot create directories. Para evitar este error, tienes dos opciones:Elimina la ubicación de la caché de XLA quitando el siguiente bloque del archivo YAML de implementación. Esto significa que todas las réplicas volverán a compilar la caché.
- name: VLLM_XLA_CACHE_PATH value: "/data"Escala el Deployment a
1y espera a que la primera réplica esté lista y escriba en la caché de XLA. A continuación, escala a réplicas adicionales. De esta forma, el resto de las réplicas pueden leer la caché sin intentar escribir en ella.
Aplica el manifiesto ejecutando el siguiente comando:
kubectl apply -f vllm-llama3-70b.yaml -n ${NAMESPACE}Consulta los registros del servidor de modelos en ejecución:
kubectl logs -f -l app=vllm-tpu -n ${NAMESPACE}La salida debería ser similar a la siguiente:
INFO: Started server process [1] INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)Para obtener la dirección IP externa del servicio VLLM, ejecuta el siguiente comando:
export vllm_service=$(kubectl get service vllm-service -o jsonpath='{.status.loadBalancer.ingress[0].ip}' -n ${NAMESPACE})Interactúa con el modelo mediante
curl:curl http://$vllm_service:8000/v1/completions \ -H "Content-Type: application/json" \ -d '{ "model": "meta-llama/Llama-3.1-70B", "prompt": "San Francisco is a", "max_tokens": 7, "temperature": 0 }'La salida debería ser similar a la siguiente:
{"id":"cmpl-6b4bb29482494ab88408d537da1e608f","object":"text_completion","created":1727822657,"model":"meta-llama/Llama-3-8B","choices":[{"index":0,"text":" top holiday destination featuring scenic beauty and","logprobs":null,"finish_reason":"length","stop_reason":null,"prompt_logprobs":null}],"usage":{"prompt_tokens":5,"total_tokens":12,"completion_tokens":7}}Configura el adaptador de Stackdriver de métricas personalizadas en tu clúster:
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/k8s-stackdriver/master/custom-metrics-stackdriver-adapter/deploy/production/adapter_new_resource_model.yamlAñade el rol Lector de Monitoring a la cuenta de servicio que usa el adaptador de Stackdriver de métricas personalizadas:
gcloud projects add-iam-policy-binding projects/${PROJECT_ID} \ --role roles/monitoring.viewer \ --member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/custom-metrics/sa/custom-metrics-stackdriver-adapterGuarda el siguiente archivo de manifiesto como
vllm_pod_monitor.yaml:Aplícalo al clúster:
kubectl apply -f vllm_pod_monitor.yaml -n ${NAMESPACE}Ejecuta una secuencia de comandos bash (
load.sh) para enviarNsolicitudes paralelas al endpoint de vLLM:#!/bin/bash N=PARALLEL_PROCESSES export vllm_service=$(kubectl get service vllm-service -o jsonpath='{.status.loadBalancer.ingress[0].ip}' -n ${NAMESPACE}) for i in $(seq 1 $N); do while true; do curl http://$vllm_service:8000/v1/completions -H "Content-Type: application/json" -d '{"model": "meta-llama/Llama-3.1-70B", "prompt": "Write a story about san francisco", "max_tokens": 1000, "temperature": 0}' done & # Run in the background done waitSustituye PARALLEL_PROCESSES por el número de procesos paralelos que quieras ejecutar.
Ejecuta la secuencia de comandos bash:
chmod +x load.sh nohup ./load.sh &En la Google Cloud consola, ve a la página Explorador de métricas.
Haz clic en < > PromQL.
Introduce la siguiente consulta para observar las métricas de tráfico:
vllm:num_requests_waiting{cluster='CLUSTER_NAME'}num_requests_waiting: esta métrica se refiere al número de solicitudes que esperan en la cola del servidor del modelo. Este número empieza a crecer de forma notable cuando la caché de pares clave-valor está llena.gpu_cache_usage_perc: esta métrica está relacionada con la utilización de la caché de clave-valor, que se corresponde directamente con el número de solicitudes que se procesan en un ciclo de inferencia determinado en el servidor del modelo. Ten en cuenta que esta métrica funciona igual en las GPUs y las TPUs, aunque está vinculada al esquema de nomenclatura de las GPUs.Guarda el siguiente archivo de manifiesto como
vllm-hpa.yaml:Las métricas de vLLM de Google Cloud Managed Service para Prometheus siguen el formato
vllm:metric_name.Práctica recomendada: Usa
num_requests_waitingpara escalar el rendimiento. Usagpu_cache_usage_percpara los casos prácticos de TPU sensibles a la latencia.Despliega la configuración de Horizontal Pod Autoscaler:
kubectl apply -f vllm-hpa.yaml -n ${NAMESPACE}GKE programa otro pod para desplegarlo, lo que activa el escalador automático del grupo de nodos para añadir un segundo nodo antes de desplegar la segunda réplica de vLLM.
Supervisa el progreso del autoescalado de pods:
kubectl get hpa --watch -n ${NAMESPACE}El resultado debería ser similar al siguiente:
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE vllm-hpa Deployment/vllm-tpu <unknown>/10 1 2 0 6s vllm-hpa Deployment/vllm-tpu 34972m/10 1 2 1 16s vllm-hpa Deployment/vllm-tpu 25112m/10 1 2 2 31s vllm-hpa Deployment/vllm-tpu 35301m/10 1 2 2 46s vllm-hpa Deployment/vllm-tpu 25098m/10 1 2 2 62s vllm-hpa Deployment/vllm-tpu 35348m/10 1 2 2 77sEspera 10 minutos y repite los pasos de la sección Verificar que Google Cloud Managed Service para Prometheus ingiere las métricas. Google Cloud Managed Service para Prometheus ahora ingiere las métricas de ambos endpoints de vLLM.
- Consulta más información sobre las TPUs en GKE.
- Consulta más información sobre las métricas disponibles para configurar la herramienta de adaptación dinámica de pods horizontal.
- Consulta el repositorio de GitHub y la documentación de vLLM.
Preparar el entorno
En esta sección, aprovisiona los recursos que necesitas para desplegar vLLM y el modelo.
Acceder al modelo
Debes firmar el acuerdo de consentimiento para usar Llama 3.1 70b en el repositorio de Hugging Face.
Generar un token de acceso
Si aún no tienes uno, genera un token de Hugging Face:
Iniciar Cloud Shell
En este tutorial, usarás Cloud Shell para gestionar los recursos alojados enGoogle Cloud. Cloud Shell tiene preinstalado el software que necesitas para este tutorial, incluido
kubectly la CLI de gcloud.Para configurar tu entorno con Cloud Shell, sigue estos pasos:
Crear un clúster de GKE
Puedes servir LLMs en TPUs en un clúster Autopilot o Estándar de GKE. Te recomendamos que uses un clúster de Autopilot para disfrutar de una experiencia de Kubernetes totalmente gestionada. Para elegir el modo de funcionamiento de GKE que mejor se adapte a tus cargas de trabajo, consulta Elegir un modo de funcionamiento de GKE.
Autopilot
Estándar
Configurar kubectl para que se comunique con el clúster
Para configurar kubectl de forma que se comunique con tu clúster, ejecuta el siguiente comando:
gcloud container clusters get-credentials ${CLUSTER_NAME} --location=${CONTROL_PLANE_LOCATION}Crear un secreto de Kubernetes para las credenciales de Hugging Face
Crea un segmento de Cloud Storage
En Cloud Shell, ejecuta el siguiente comando:
gcloud storage buckets create gs://${GSBUCKET} \ --uniform-bucket-level-accessDe esta forma, se crea un segmento de Cloud Storage para almacenar los archivos del modelo que descargues de Hugging Face.
Configurar una cuenta de servicio de Kubernetes para acceder al segmento
Desplegar el servidor de modelos vLLM
Para desplegar el servidor de modelos vLLM, en este tutorial se usa un despliegue de Kubernetes. Un Deployment es un objeto de la API de Kubernetes que te permite ejecutar varias réplicas de pods distribuidas entre los nodos de un clúster.
Aplicar el modelo
Configurar el escalador automático personalizado
En esta sección, configurará el autoescalado horizontal de pods mediante métricas de Prometheus personalizadas. Usas las métricas de Google Cloud Managed Service para Prometheus del servidor vLLM.
Para obtener más información, consulta Google Cloud Managed Service para Prometheus. Esta opción debería estar habilitada de forma predeterminada en el clúster de GKE.
Crear carga en el endpoint de vLLM
Crea carga en el servidor vLLM para probar cómo se adapta dinámicamente GKE con una métrica vLLM personalizada.
Verificar que Google Cloud Managed Service para Prometheus ingiere las métricas
Una vez que Managed Service para Prometheus de Google Cloud haya recogido las métricas y añadas carga al endpoint de vLLM, podrás ver las métricas en Cloud Monitoring.
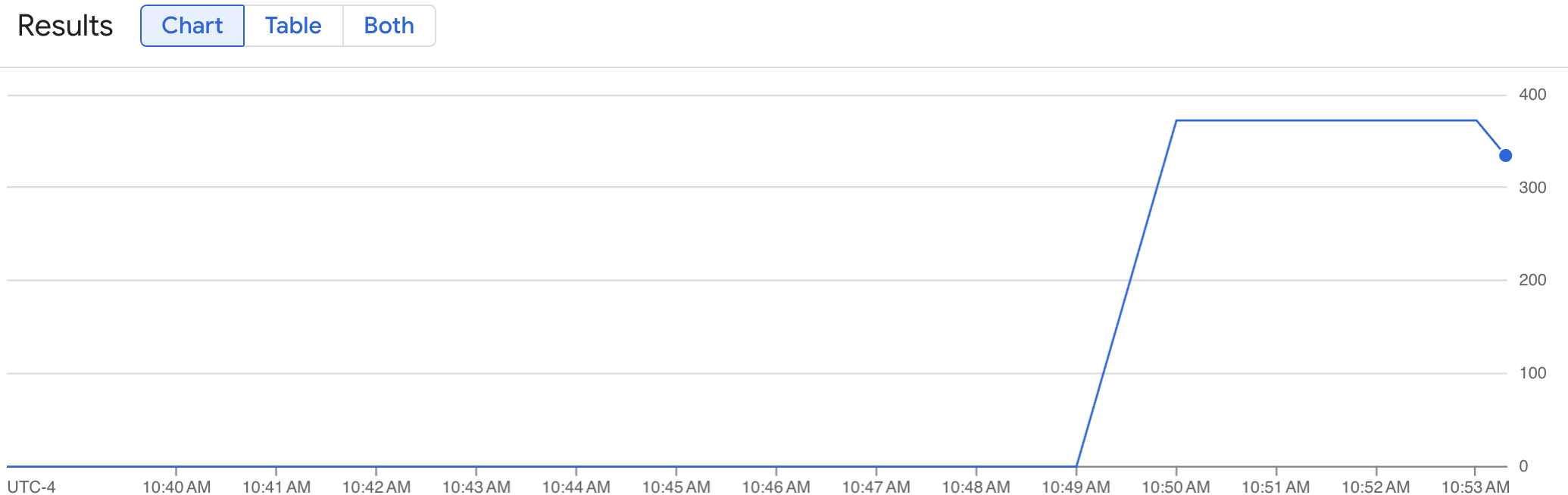
Un gráfico de líneas muestra tu métrica de vLLM (num_requests_waiting) medida a lo largo del tiempo. La métrica vLLM aumenta de 0 (precarga) a un valor (después de la carga). Este gráfico confirma que tus métricas de vLLM se están ingiriendo en Google Cloud Managed Service para Prometheus. En el siguiente gráfico de ejemplo se muestra un valor de precarga inicial de 0, que alcanza un valor máximo posterior a la carga de casi 400 en un minuto.
Desplegar la configuración de la herramienta de adaptación dinámica horizontal de pods
A la hora de decidir qué métrica usar para el autoescalado, te recomendamos las siguientes métricas para la TPU de vLLM:
Te recomendamos que uses
num_requests_waitingcuando optimices el rendimiento y el coste, y cuando puedas alcanzar tus objetivos de latencia con el rendimiento máximo del servidor de tu modelo.Te recomendamos que uses
gpu_cache_usage_perccuando tengas cargas de trabajo sensibles a la latencia en las que el escalado basado en colas no sea lo suficientemente rápido para cumplir tus requisitos.Para obtener más información, consulta las prácticas recomendadas para escalar automáticamente las cargas de trabajo de inferencia de modelos de lenguaje extensos (LLMs) con TPUs.
Al seleccionar un
averageValueobjetivo para tu configuración de HPA, tendrás que determinarlo de forma experimental. Consulta la entrada de blog Ahorra en GPUs: autoescalado más inteligente para tus cargas de trabajo de inferencia de GKE para obtener más ideas sobre cómo optimizar esta parte. El generador de perfiles que se usa en esta entrada de blog también funciona con vLLM TPU.En las siguientes instrucciones, desplegarás tu configuración de HPA mediante la métrica num_requests_waiting. Para hacer una demostración, asigna a la métrica un valor bajo para que la configuración de HPA escale tus réplicas de vLLM a dos. Para implementar la configuración de Horizontal Pod Autoscaler mediante num_requests_waiting, sigue estos pasos:
Limpieza
Para evitar que los recursos utilizados en este tutorial se cobren en tu cuenta de Google Cloud, elimina el proyecto que contiene los recursos o conserva el proyecto y elimina los recursos.
Eliminar los recursos desplegados
Para evitar que se apliquen cargos en tu cuenta de Google Cloud por los recursos que has creado en esta guía, ejecuta los siguientes comandos:
ps -ef | grep load.sh | awk '{print $2}' | xargs -n1 kill -9gcloud container clusters delete ${CLUSTER_NAME} \ --location=${CONTROL_PLANE_LOCATION}Siguientes pasos
-