
このページでは、GKE Inference Quickstart(GIQ)を使用して、Google Kubernetes Engine(GKE)での AI/ML 推論ワークロードのデプロイを簡素化する方法について説明します。Inference Quickstart は、推論に関するビジネス要件を指定すると、モデル、モデルサーバー、アクセラレータ(GPU、TPU)、スケーリング、ストレージに関するベスト プラクティスや Google のベンチマークに基づいた最適化済みの Kubernetes 構成を取得できるユーティリティです。これにより、構成を手動で調整してテストする必要がなくなり、時間を節約することができます。
このページは、AI / ML 推論用に GKE を効率的に管理して最適化する方法を探している機械学習(ML)エンジニア、プラットフォーム管理者、オペレーター、データおよび AI スペシャリストを対象としています。 Google Cloud のコンテンツで使用されている一般的なロールとタスクの例の詳細については、一般的な GKE ユーザーのロールとタスクをご覧ください。
モデル サービングのコンセプトと用語、GKE の生成 AI 機能を使用してモデル サービングのパフォーマンスを強化する方法については、GKE でのモデル推論についてをご覧ください。
このページを読む前に、Kubernetes、GKE、モデル サービングについて理解しておいてください。
Inference Quickstart の使用
Inference Quickstart を使用すると、推論ワークロードのパフォーマンスや費用対効果を分析し、そのデータに基づいてリソースの割り当てやモデルのデプロイ戦略を決定することができます。
Inference Quickstart の使用手順の概要は次のとおりです。
パフォーマンスと費用を分析する:
gcloud container ai profiles listコマンドを使用すると、利用可能な構成を確認し、パフォーマンスや費用の要件に基づいてフィルタすることができます。特定の構成のベンチマーク データの完全なセットを表示するには、gcloud container ai profiles benchmarks listコマンドを使用します。このコマンドを使用することで、自身のパフォーマンス要件に対して最も費用対効果の高いハードウェアを特定できます。また、ユースケースや入出力サイズなどのワークロードの特性や、サービング スタックに基づいて、推論クイックスタートの推奨事項をフィルタリングすることもできます。サービング スタックは、モデルのホスティング、推論の処理、予測の提供のためのユーザー リクエストのルーティングに使用されるテクノロジーの完全なセットです。たとえば、
llm-dサービング スタックは、基盤となるモデルサーバーとして vLLM を使用し、コア推論エンジンの上にオーケストレーションとルーティングのレイヤを追加します。マニフェストをデプロイする: 分析した結果をもとに、最適化された Kubernetes マニフェストを生成してデプロイできます。必要に応じて、ストレージと自動スケーリングの最適化を有効にできます。デプロイは、 Google Cloud コンソールから行うことも、
kubectl applyコマンドを使用して行うこともできます。デプロイする前に、 Google Cloud プロジェクトで選択した GPU または TPU に十分なアクセラレータ割り当てがあることを確認する必要があります。(省略可)独自のベンチマークを実行する: Inference Quickstart によって提供される構成とパフォーマンス データは、
inference-perfツールによって生成されたベンチマークに基づいています。ワークロードのパフォーマンスはこのベースラインと異なる可能性があるため、ユースケースを最もよく表すデータセットを使用して、inference-perfツールでモデルのパフォーマンスを測定することをおすすめします。
利点
Inference Quickstart から最適化された構成が提供されるため、時間とリソースを節約できます。この最適化により、次のようにパフォーマンスを向上させ、インフラストラクチャの費用を抑えることができます。
- アクセラレータ(GPU と TPU)、モデルサーバー、スケーリング構成を設定する際の詳細なベスト プラクティスが提示されます。GKE は、最新の修正、イメージ、パフォーマンス ベンチマークを使用して Inference Quickstart を定期的に更新します。
- Google Cloud コンソール UI またはコマンドライン インターフェースを使用して、ワークロードのレイテンシとスループットの要件を指定し、Kubernetes デプロイ マニフェストとして詳細なベスト プラクティスを取得できます。
仕組み
Inference Quickstart は、モデル、モデルサーバー、アクセラレータ トポロジの組み合わせに対する単一レプリカのパフォーマンスについて、Google の包括的な内部ベンチマークを使用して、カスタマイズされたベスト プラクティスを提供します。これらのベンチマークでは、キューサイズや KV キャッシュ指標など、レイテンシとスループットをグラフで表示し、それぞれの組み合わせのパフォーマンス曲線を示します。
カスタマイズされたベスト プラクティスの生成方法
レイテンシは出力トークンあたりの正規化された時間(NTPOT)とファースト トークンまでの時間(TTFT)でミリ秒単位で測定し、スループットはアクセラレータをフル稼働させた状態で 1 秒あたりの出力トークン数で測定します。これらのパフォーマンス指標の詳細については、GKE でのモデル推論についてをご覧ください。
次のレイテンシ プロファイルの例は、スループットが横ばいになる変曲点(緑色)、レイテンシが悪化する変曲点(赤色)、レイテンシ ターゲットで最適なスループットを得るための理想的なゾーン(青色)を示しています。Inference Quickstart には、この理想的なゾーンのパフォーマンス データと構成が用意されています。
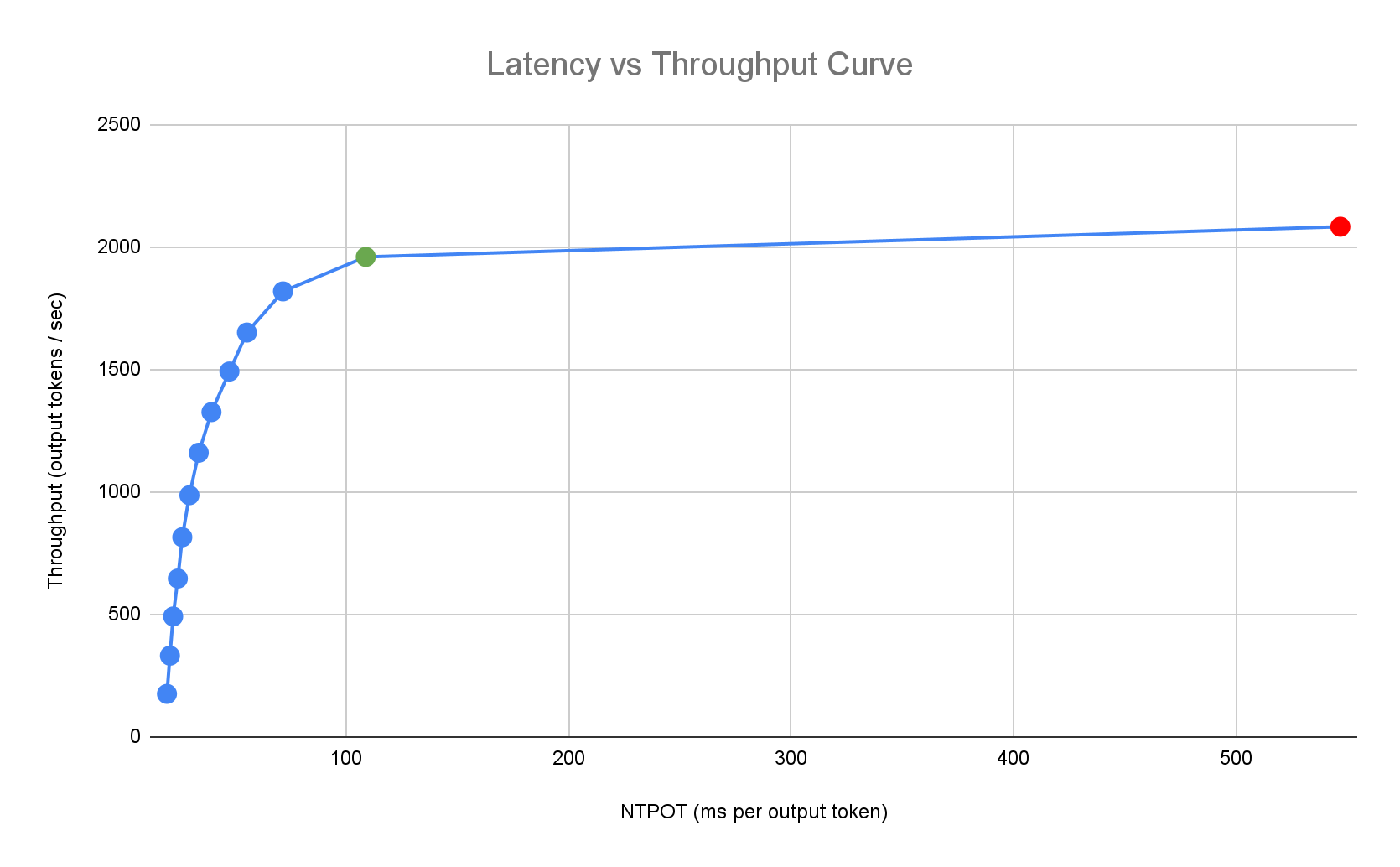
Inference Quickstart は、推論アプリケーションのレイテンシ要件に基づいて適切な組み合わせを特定し、レイテンシとスループットの曲線上の最適な動作ポイントを決定します。このポイントで、HorizontalPodAutoscaler(HPA)のしきい値が設定され、スケールアップ レイテンシを考慮したバッファが設定されます。全体的なしきい値では、必要なレプリカの初期数も示しますが、HPA はワークロードに基づいてこの数を動的に調整します。
費用の見積もり
アクセラレータ VM のトークンあたりの費用を見積もるために、Inference Quickstart では出力トークンと入力トークンの費用比率を設定できます。たとえば、この比率を 4 に設定すると、各出力トークンのコストは入力トークンの 4 倍であると想定されます。次の式を使用して、トークンあたりの費用指標を計算します。
\[ \$/\text{output token} = \frac{\text{GPU \$/s}}{(\frac{1}{\text{output-to-input-cost-ratio}} \cdot \text{input tokens/s} + \text{output tokens/s})} \]
ここで
\[ \$/\text{input token} = \frac{\text{\$/output token}}{\text{output-to-input-cost-ratio}} \]
ベンチマーク
提供されている構成とパフォーマンス データは、inference-perf ツールによって生成されたベンチマークに基づいており、次の入出力分布でトラフィックを送信します。
| 入力トークン | 出力トークン | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 最小 | 中央値 | 平均 | P90 | P99 | 最大 | 最小 | 中央値 | 平均 | P90 | P99 | 最大 |
| 4 | 108 | 226 | 635 | 887 | 1024 | 1 | 132 | 195 | 488 | 778 | 1024 |
始める前に
作業を始める前に、次のタスクが完了していることを確認してください。
- Google Kubernetes Engine API を有効にする。 Google Kubernetes Engine API を有効化
- このタスクに Google Cloud CLI を使用する場合は、gcloud CLI をインストールして初期化します。gcloud CLI をインストール済みの場合は、
gcloud components updateコマンドを実行して最新のバージョンを取得します。以前のバージョンの gcloud CLI では、このドキュメントのコマンドを実行できない場合があります。
Google Cloud コンソールのプロジェクト セレクタページで、 Google Cloud プロジェクトを選択または作成します。
プロジェクトに十分なアクセラレータ容量があることを確認します。
- GPU を使用している場合: [割り当て] ページを確認します。
- TPU を使用している場合: TPU と他の GKE リソースの割り当てを確保するをご覧ください。
GKE AI / ML ユーザー インターフェースを使用する準備をする
Google Cloud コンソールを使用する場合、プロジェクトに Autopilot クラスタがまだ作成されていなければ、Autopilot クラスタの作成も必要になります。Autopilot クラスタを作成するの手順に沿って操作します。
コマンドライン インターフェースを使用する準備をする
gcloud CLI を使用して Inference Quickstart を実行する場合は、次の追加コマンドも実行する必要があります。
gkerecommender.googleapis.comAPI を有効にします。gcloud services enable gkerecommender.googleapis.comAPI 呼び出しに使用する課金割り当てプロジェクトを設定します。
gcloud config set billing/quota_project PROJECT_IDgcloud CLI のバージョンが 536.0.1 以降であることを確認します。そうでない場合は、次のコマンドを実行します。
gcloud components update
制限事項
Inference Quickstart の使用を開始する前に、次の制限事項に注意してください。
- Google Cloud コンソールでモデルをデプロイする場合、Autopilot クラスタへのデプロイのみがサポートされています。
- Inference Quickstart では、特定のモデルサーバーでサポートされているすべてのモデルのプロファイルが提供されるわけではありません。
- Hugging Face の大規模モデル(90 GiB 以上)用に生成されたマニフェストを使用するときに
HF_HOME環境変数を設定しない場合は、デフォルトよりも大きいブートディスクを使用するクラスタを使用するか、マニフェストを変更してHF_HOMEを/dev/shm/hf_cacheに設定する必要があります。これにより、ノードのブートディスクではなく、RAM がキャッシュに使用されます。詳細については、トラブルシューティングセクションをご覧ください。 - Cloud Storage からモデルを読み込むには、Workload Identity Federation for GKE が必要です。Cloud Storage FUSE CSI ドライバは、すべての TPU ワークロードにも必要であり、
v0.11.1より前の特定のモデルサーバー バージョンのフォールバックとしても必要です。Workload Identity Federation for GKE と Cloud Storage FUSE CSI ドライバは、Autopilot クラスタではデフォルトで有効になっています。詳細については、GKE 用に Cloud Storage FUSE CSI ドライバを設定するをご覧ください。
モデル推論用に最適化された構成を分析して表示する
このセクションでは、Google Cloud CLI を使用して構成の推奨事項を調査して分析する方法について説明します。
gcloud container ai profiles コマンドを使用して、最適化されたプロファイル(モデル、モデルサーバー、モデルサーバー バージョン、アクセラレータの組み合わせ)を探索したり分析したりできます。
モデル
モデルを探索して選択するには、models オプションを使用します。
gcloud container ai profiles models list
プロファイル
list コマンドを使用して、生成されたプロファイルを確認し、パフォーマンスや費用の要件に基づいてフィルタすることができます。次に例を示します。
gcloud container ai profiles list \
--model=openai/gpt-oss-20b \
--pricing-model=on-demand \
--target-ttft-milliseconds=300
コマンドの出力には以下のように、サポートされているプロファイルと、そのパフォーマンス指標(スループット、レイテンシ、100 万トークンあたりの費用など)が示されます。たとえば、次のように表示されます。
Instance Type Accelerator Cost/M Input Tokens Cost/M Output Tokens Output Tokens/s NTPOT(ms) TTFT(ms) Model Server Model Server Version Model
a3-highgpu-1g nvidia-h100-80gb 0.009 0.035 13335 67 297 vllm gptoss openai/gpt-oss-20b
この値は、このアクセラレータ タイプで特定のプロファイルの処理量の増加が停止し、レイテンシが急増し始めるポイント(つまり、変曲点または飽和点)で観測されたパフォーマンスを表します。これらのパフォーマンス指標の詳細については、GKE でのモデル推論についてをご覧ください。
設定できるフラグの完全なリストについては、list コマンドのドキュメントをご覧ください。
すべての料金情報は米ドルでのみ提供され、デフォルトでは us-east5 リージョンの料金が表示されます。ただし、A3 マシンを使用する構成の場合は、デフォルトで us-central1 リージョンに設定されます。
ベンチマーク
特定のプロファイルのすべてのベンチマーク データを取得するには、benchmarks list コマンドを使用します。
例:
gcloud container ai profiles benchmarks list \
--model=deepseek-ai/DeepSeek-R1-Distill-Qwen-7B \
--model-server=vllm
出力には、さまざまなリクエスト レートで実行されたベンチマークのパフォーマンス指標のリストが含まれます。
コマンドの出力は CSV 形式で表示されます。出力をファイルとして保存するには、出力のリダイレクトを使用します。例: gcloud container ai profiles benchmarks list > profiles.csv。
設定できるフラグの完全なリストについては、benchmarks list コマンドのドキュメントをご覧ください。
モデル、モデルサーバー、モデルサーバーのバージョン、アクセラレータを選択したら、デプロイ マニフェストの作成に進みます。
ユースケース別に最適化案を表示する
Inference Quickstart では、一般的な AI/ML ワークロードを表すさまざまなユースケースの推奨事項が提供されます。これらのユースケースは、実際の顧客ワークロードに基づくさまざまな入力トークンと出力トークンの長さが特徴であり、基盤となる推論サービング スタックのパフォーマンスに影響を与える可能性があります。
次の表に、利用可能なユースケースとその特性の概要を示します。
| ユースケース | 入力トークン | 出力トークン | 比率 | 説明 |
|---|---|---|---|---|
| 高度なカスタマー サポート | 8,192 | 256 | 32:1 | 包括的で合成された回答で複雑な顧客の問題を解決し、サポート業務を拡大してユーザー満足度を高めます。 |
| コード補完 | 512 | 32 | 16:1 | コードを自動的に提案して補完することで、ソフトウェア開発を加速します。 |
| テキスト要約 | 1,024 | 128 | 8:1 | 長いドキュメント、記事、会話を簡潔な要約にまとめます。 |
| チャットボット(ShareGPT) | 128 | 128 | 1:1 | 質問への回答、タスクの実行、ガイダンスの提供を即座に会話形式で行います。 |
| テキスト生成 | 512 | 2,048 | 1:4 | メールやレポートの作成からクリエイティブなストーリーの生成まで、新しい文章コンテンツの作成を自動化します。 |
| Deep Research | 256 | 4,096 | 1:16 | 大量のデータを分析して統合し、特定の情報を検索したり、パターンを特定したり、分析情報を明らかにしたりすることで、詳細な調査と研究を可能にします。 |
推論クイックスタートでサポートされているユースケースの完全なリストを確認するには、gcloud container ai profiles use-cases list コマンドを使用します。
ユースケースでレコメンデーションをフィルタリングするには、--use-case フラグを使用します。マニフェストを作成するときにこのフラグを指定しないと、デフォルトで Chatbot になります。
次に例を示します。
gcloud container ai profiles list \
--use-case="Text Summarization"
推奨構成をデプロイする
このセクションでは、 Google Cloud コンソールまたはコマンドラインを使用して構成の推奨事項を生成し、デプロイする方法について説明します。
コンソール
- Google Cloud コンソールで、[GKE AI/ML] ページに移動します。
- [モデルをデプロイ] をクリックします。
デプロイするモデルを選択します。Inference Quickstart でサポートされているモデルには、「Optimized」(最適化済み)のタグが表示されます。
- 基盤モデルを選択すると、モデルページが開きます。[デプロイ] をクリックします。実際のデプロイ前に構成を変更できます。
- プロジェクトに Autopilot クラスタがない場合、Autopilot クラスタを作成するよう求められます。Autopilot クラスタを作成するの手順に沿って操作します。クラスタを作成したら、 Google Cloud コンソールの [GKE AI / ML] ページに戻り、モデルを選択します。
- Gemma や Llama などのゲート付きモデルをデプロイするには、まず Hugging Face トークンを作成して、Kubernetes Secret として追加する必要があります。これを行わないと、Deployment の作成を妨げる
"Does not have minimum availability"エラーが発生する可能性があります。詳細な手順については、このドキュメント ページの [gcloud] タブを開いてください。
モデルのデプロイページに、選択したモデルと、推奨されるモデルサーバー / アクセラレータが自動的に入力されています。最大レイテンシやモデルソースなどの設定も構成できます。
(省略可)推奨構成のマニフェストを表示するには、[YAML を表示] をクリックします。
推奨構成でマニフェストをデプロイするには、[デプロイ] をクリックします。デプロイ オペレーションが完了するまでに数分かかることがあります。
デプロイを表示するには、[Kubernetes Engine] > [ワークロード] ページに移動します。
gcloud
モデル レジストリからモデルを読み込む準備をする: Inference Quickstart では、Hugging Face または Cloud Storage からモデルを読み込むことができます。
Hugging Face
Hugging Face アクセス トークンと、対応する Kubernetes Secret を生成します(まだ生成していない場合)。
Hugging Face トークンを含む Kubernetes Secret を作成するには、次のコマンドを実行します。
kubectl create secret generic hf-secret \ --from-literal=hf_api_token=HUGGING_FACE_TOKEN \ --namespace=NAMESPACE次の値を置き換えます。
- HUGGING_FACE_TOKEN: 先ほど生成した Hugging Face トークン。
- NAMESPACE: モデルサーバーをデプロイする Kubernetes Namespace。
モデルによっては、ライセンス契約に同意して署名することが求められることもあります。
Cloud Storage
調整された Cloud Storage FUSE 設定を使用して、Cloud Storage からサポートされているモデルを読み込むことができます。これを行うには、まず Hugging Face から Cloud Storage バケットにモデルを読み込む必要があります。
この Kubernetes Job をデプロイしてモデルを転送できます。その際、
MODEL_IDを Inference Quickstart でサポートされているモデルに置き換えてください。マニフェストを生成する: マニフェストの生成には次のオプションがあります。
- 基本構成: 単一レプリカの推論サーバーをデプロイするための標準の Kubernetes Deployment、Service、PodMonitoring マニフェストを生成します。
- (省略可)ストレージ最適化構成: Cloud Storage の読み込み用に最適化されたマニフェストを生成します。この構成では、サポートされている vLLM バージョンのパフォーマンスを向上させるために Run:ai Model Streamer が優先され、以前のバージョンでは調整された Cloud Storage FUSE 設定が使用されます。この構成は、
--model-bucket-uriフラグを使用して有効にします。これらの最適化により、LLM Pod の起動時間を 7 倍以上短縮できます。 (省略可)自動スケーリング用に最適化された構成: HorizontalPodAutoscaler(HPA)を含むマニフェストを生成し、トラフィックに基づいてモデルサーバー レプリカの数を自動的に調整します。この構成を有効にするには、
--target-ntpot-millisecondsなどのフラグを使用してレイテンシ ターゲットを指定します。
基本構成
ターミナルで
manifestsオプションを使用して、Deployment、Service、PodMonitoring のマニフェストを生成します。gcloud container ai profiles manifests create必要な
--model、--model-server、--accelerator-typeパラメータを使用して、マニフェストをカスタマイズします。必要に応じて、次のパラメータを設定できます。
--target-ntpot-milliseconds: このパラメータを設定して HPA しきい値を指定します。このパラメータを設定することで、出力トークンあたりの正規化された時間(NTPOT)の P50 レイテンシ(50パーセンタイルで測定される中央値のレイテンシ)を、指定した値未満に保つためのスケーリングしきい値を定義できます。アクセラレータの最小レイテンシより大きい値を選択します。アクセラレータの最大レイテンシを超える NTPOT 値を指定すると、HPA は最大スループット用に構成されます。次に例を示します。gcloud container ai profiles manifests create \ --model=google/gemma-2-27b-it \ --model-server=vllm \ --model-server-version=v0.7.2 \ --accelerator-type=nvidia-l4 \ --target-ntpot-milliseconds=200--target-ttft-milliseconds: 最初のトークンまでの目標時間(TTFT)(ミリ秒単位)。この値を設定すると、マニフェストに Horizontal Pod Autoscaler(HPA)リソースが含まれ、p50 TTFT が指定されたしきい値を下回るように維持されます。--output-path: 指定すると、出力はターミナルではなく、指定されたパスに保存されるため、デプロイする前に出力を編集できます。たとえば、マニフェストを YAML ファイルに保存する場合は、--output=manifestオプションを使用します。次に例を示します。gcloud container ai profiles manifests create \ --model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B \ --model-server vllm \ --accelerator-type=nvidia-tesla-a100 \ --output=manifest \ --output-path /tmp/manifests.yaml--target-itl-milliseconds: 目標トークン間レイテンシ(ITL)(ミリ秒単位)。この値を設定すると、マニフェストに HorizontalPodAutoscaler(HPA)リソースが含まれ、p50 ITL が指定されたしきい値未満に保たれます。--use-case: マニフェストはこのユースケースに合わせて最適化されます。指定しない場合、このフラグはデフォルトでChatbotになります。詳細については、ユースケース別に推奨事項を表示するをご覧ください。
設定できるフラグの完全なリストについては、
manifests createコマンドのドキュメントをご覧ください。ストレージ最適化
Cloud Storage からモデルを読み込むことで、Pod の起動時間を短縮できます。Inference Quickstart は、構成に最適なパフォーマンスのストレージ バックエンドを自動的に選択します。
- Run:ai Model Streamer: GPU の vLLM バージョン 0.11.1 以降と TPU の 0.14.0 以降で自動的に使用されるストリーミング ソリューション。
- Cloud Storage FUSE CSI ドライバ: vLLM バージョン 0.11.1 より前と他のモデルサーバーで使用される標準のストレージ最適化。
Cloud Storage からの読み込みには、GKE バージョン 1.29.6-gke.1254000、1.30.2-gke.1394000 以降が必要です。
手順は次のとおりです。
- Hugging Face リポジトリから Cloud Storage バケットにモデルを読み込みます。
マニフェストを生成するときに
--model-bucket-uriフラグを設定します。これにより、Cloud Storage バケットから読み込むようにモデルが構成されます。モデルは、サポートされている vLLM バージョンに対して高パフォーマンスの Run:ai Model Streamer を自動的に使用し、それ以外のバージョンに対しては Cloud Storage FUSE CSI ドライバにフォールバックします。URI は、モデルのconfig.jsonファイルと重みを含むパスを指している必要があります。バケット URI にパスを追加することで、バケット内のディレクトリへのパスを指定できます。例:
gcloud container ai profiles manifests create \ --model=openai/gpt-oss-120b \ --model-server=vllm \ --model-server-version=v0.11.2 \ --accelerator-type=nvidia-h100-80gb \ --model-bucket-uri=gs://BUCKET_NAME \ --output-path=manifests.yamlBUCKET_NAMEは、Cloud Storage バケットの名前に置き換えます。マニフェストを適用する前に、マニフェストのコメントにある
gcloud storage buckets add-iam-policy-bindingコマンドを実行する必要があります。このコマンドは、Workload Identity Federation for GKE を使用して Cloud Storage バケットにアクセスする権限を GKE サービス アカウントに付与するために必要です。TPU で Deployment を複数のレプリカにスケーリングする場合は、次のいずれかのオプションを選択して、XLA キャッシュ パス(
VLLM_XLA_CACHE_PATH)への同時書き込みエラーを防ぐ必要があります。- オプション 1(推奨): まず、Deployment のレプリカ数を 1 にスケーリングします。Pod の準備ができるまで待ちます。この段階で Pod は XLA キャッシュに書き込みを行います。次に、必要なレプリカ数までスケールアップします。追加されたレプリカは既存のキャッシュから読み取るため、書き込みの競合は発生しません。
- オプション 2: マニフェストから
VLLM_XLA_CACHE_PATH環境変数を完全に削除します。このアプローチは簡単ですが、すべてのレプリカのキャッシュ保存が無効になります。
TPU アクセラレータ タイプでは、このキャッシュパスは XLA コンパイル キャッシュの保存に使用されます。これにより、繰り返しデプロイするためのモデルの準備が高速化されます。
パフォーマンスを高めるためのその他のヒントについては、GKE のパフォーマンスを向上させるために Cloud Storage FUSE CSI ドライバを最適化するをご覧ください。
自動スケーリング向けに最適化
HorizontalPodAutoscaler(HPA)を構成して、負荷に基づいてモデルサーバー レプリカの数を自動的に調整できます。これにより、モデルサーバーは必要に応じてスケールアップまたはスケールダウンすることで、さまざまな負荷を効率的に処理できます。HPA 構成は、GPU と TPU のガイドの自動スケーリングのベスト プラクティスに準拠しています。
マニフェストの生成時に HPA 構成を含めるには、
--target-ntpot-millisecondsフラグと--target-ttft-millisecondsフラグのどちらかまたは両方を使用します。これらのパラメータは、NTPOT または TTFT の P50 レイテンシを指定値未満に保つように HPA のスケーリングしきい値を定義します。これらのフラグのいずれか 1 つのみを設定すると、その指標のみがスケーリングの対象となります。アクセラレータの最小レイテンシより大きい値を選択します。アクセラレータの最大レイテンシを超える値を指定すると、HPA は最大スループット用に構成されます。
例:
gcloud container ai profiles manifests create \ --model=google/gemma-2-27b-it \ --accelerator-type=nvidia-l4 \ --target-ntpot-milliseconds=250クラスタを作成する: GKE Autopilot クラスタまたは GKE Standard クラスタでモデルを提供できます。フルマネージドの Kubernetes エクスペリエンスを実現するには、Autopilot クラスタを使用することをおすすめします。ワークロードに最適な GKE の運用モードを選択するには、GKE の運用モードを選択するをご覧ください。
既存のクラスタがない場合は、次の操作を行います。
Autopilot
次の手順で Autopilot クラスタを作成します。プロジェクトに必要な割り当てがある場合、GKE はデプロイ マニフェストに基づいて GPU または TPU 容量を持つノードのプロビジョニングを処理します。
Standard
- ゾーンまたはリージョン クラスタを作成します。
適切なアクセラレータを使用してノードプールを作成します。選択したアクセラレータ タイプに応じて、次の操作を行います。
- GPU: まず、 Google Cloud コンソールの [割り当て] ページで、十分な GPU 容量があることを確認します。次に、GPU ノードプールを作成するの手順に沿って操作します。
- TPU: まず、TPU と他の GKE リソースの割り当てを確保するの手順に沿って、十分な TPU があることを確認します。次に、TPU ノードプールを作成するに進みます。
(省略可、ただし推奨)オブザーバビリティ機能を有効にする: 生成されたマニフェストのコメント セクションには、推奨されるオブザーバビリティ機能を有効にするための追加コマンドがあります。これらの機能を有効にすると、ワークロードと基盤となるインフラストラクチャのパフォーマンスやステータスをモニタリングする際に役立つ詳細な分析情報を得ることができます。
オブザーバビリティ機能を有効にするコマンドの例を次に示します。
gcloud container clusters update $CLUSTER_NAME \ --project=$PROJECT_ID \ --location=$LOCATION \ --enable-managed-prometheus \ --logging=SYSTEM,WORKLOAD \ --monitoring=SYSTEM,DEPLOYMENT,HPA,POD,DCGM \ --auto-monitoring-scope=ALL詳細については、推論ワークロードをモニタリングするをご覧ください。
(HPA のみ)指標アダプタをデプロイする: デプロイ マニフェストで HPA リソースが生成された場合は、Custom Metrics Stackdriver Adapter などの指標アダプタが必要です。指標アダプタを使用すると、HPA は kube external metrics API を使用するモデルサーバー指標にアクセスできます。アダプタをデプロイするには、GitHub のアダプタ ドキュメントをご覧ください。
マニフェストをデプロイする:
kubectl applyコマンドを実行し、マニフェストの YAML ファイルを渡します。次に例を示します。kubectl apply -f ./manifests.yaml
llm-d サービス スタックの推奨構成をデプロイする
llm-d は、Kubernetes ネイティブの分散推論サービング スタックです。テストとベンチマークが行われた「明確なパス」を提供し、大規模な生成 AI モデルを高いパフォーマンスで大規模に提供できるようにします。詳細については、llm-d のドキュメントをご覧ください。
Inference Quickstart を使用して llm-d サービング スタックの推奨構成を生成してデプロイするには、--serving-stack フラグを使用し、値を llm-d に設定します。次に例を示します。
gcloud container ai profiles manifests create \
--accelerator-type=nvidia-h100-80gb \
--model=openai/gpt-oss-120b \
--model-server=vllm \
--serving-stack=llm-d \
--use-case 'Multi Agent Large Document Summarization'
manifests create の出力を確認して、クラスタの作成と依存関係のインストールに関する追加の手順を確認し、llm-d の環境を正しく設定します。
デプロイ エンドポイントをテストする
マニフェストをデプロイすると、サービスは http://SERVICE_NAME:8000 で公開されます。ここで、SERVICE_NAME はデプロイの名前です。
サービス名を確認するには、名前空間(default など)のサービスを一覧表示します。
kubectl get services --namespace NAMESPACE
デプロイをテストするには、kubectl port-forward コマンドを使用してローカルポートをサービスポートに転送します。別のターミナルで、次のコマンドを実行します。
kubectl port-forward service/SERVICE_NAME 8000:8000
その後、http://localhost:8000 にリクエストを送信できます。エンドポイントにリクエストを作成して送信する方法の例については、vLLM のドキュメントをご覧ください。
マニフェストのバージョニング
Inference Quickstart は、最新の GKE クラスタ バージョンで検証された最新のマニフェストを提供します。プロファイルに対して返されるマニフェストは、デプロイ時に最適化された構成を受け取れるように、時間の経過とともに変更される可能性があります。安定したマニフェストが必要な場合は、それを別途保存しておいてください。
マニフェストには、次の形式のコメントと recommender.ai.gke.io/version アノテーションが含まれています。
# Generated on DATE using:
# GKE cluster CLUSTER_VERSION
# GPU_DRIVER_VERSION GPU driver for node version NODE_VERSION
# Model server MODEL_SERVER MODEL_SERVER_VERSION
上記のアノテーションには次の値があります。
- DATE: マニフェストが生成された日付。
- CLUSTER_VERSION: 検証に使用される GKE クラスタのバージョン。
- NODE_VERSION: 検証に使用される GKE ノードのバージョン。
- GPU_DRIVER_VERSION:(GPU のみ)検証に使用される GPU ドライバのバージョン。
- MODEL_SERVER: マニフェストで使用されるモデルサーバー。
- MODEL_SERVER_VERSION: マニフェストで使用されるモデルサーバーのバージョン。
推論ワークロードをモニタリングする
デプロイされた推論ワークロードをモニタリングするには、 Google Cloud コンソールの Metrics Explorer に移動します。
自動モニタリングを有効にする
GKE には、より広範なオブザーバビリティ機能の一部として自動モニタリング機能があります。この機能は、サポートされているモデルサーバーで実行されているワークロードをクラスタでスキャンし、これらのワークロード指標を Cloud Monitoring に表示できるようにする PodMonitoring リソースをデプロイします。自動モニタリングの有効化と構成の詳細については、ワークロードの自動アプリケーション モニタリングを構成するをご覧ください。
この機能を有効にすると、GKE はサポートされているワークロードのアプリケーションをモニタリングするための事前構築済みダッシュボードをインストールします。
Google Cloud コンソールの GKE AI / ML ページからデプロイすると、targetNtpot 構成を使用して PodMonitoring リソースと HPA リソースが自動的に作成されます。
トラブルシューティング
- レイテンシを低く設定しすぎると、推奨事項が生成されないことがあります。この問題を解決するには、選択したアクセラレータで観測された最小レイテンシと最大レイテンシの間のレイテンシ目標を選択します。
- Inference Quickstart は GKE コンポーネントとは独立して存在するため、クラスタのバージョンはサービスの使用に直接関係しません。ただし、パフォーマンスの差異を回避するため、新しいクラスタまたは最新のクラスタを使用することをおすすめします。
gkerecommender.googleapis.comコマンドで割り当てプロジェクトが見つからないというPERMISSION_DENIEDエラーが発生した場合は、手動で設定する必要があります。gcloud config set billing/quota_project PROJECT_IDを実行して修正します。
エフェメラル ストレージが不足しているため、Pod が強制排除されました
Hugging Face から 90 GiB 以上の大きなモデルをデプロイすると、次のようなエラー メッセージが表示されて Pod が強制終了されることがあります。
Fails because inference server consumes too much ephemeral storage, and gets evicted low resources: Warning Evicted 3m24s kubelet The node was low on resource: ephemeral-storage. Threshold quantity: 10120387530, available: 303108Ki. Container inference-server was using 92343412Ki, request is 0, has larger consumption of ephemeral-storage..,
このエラーは、モデルがノードのブートディスク(エフェメラル ストレージの一種)にキャッシュ保存されているために発生します。デプロイ マニフェストで HF_HOME 環境変数がノードの RAM 内のディレクトリに設定されていない場合、ブートディスクはエフェメラル ストレージに使用されます。
- デフォルトでは、GKE ノードには 100 GiB のブートディスクがあります。
- GKE はブートディスクの 10% をシステム用として確保するため、ユーザーのワークロードが使えるのは残りの 90 GiB になります。
- モデルのサイズが 90 GiB 以上で、デフォルト サイズのブートディスク上で実行すると、エフェメラル ストレージを解放するために kubelet が Pod を強制停止します。
この問題は、次のいずれかの方法で解決できます。
- モデルのキャッシュ保存に RAM を使用する: Deployment マニフェストで、
HF_HOME環境変数を/dev/shm/hf_cacheに設定します。これにより、ブートディスクではなくノードの RAM を使用してモデルをキャッシュに保存します。 -
ブートディスクのサイズを増やす:
- GKE Standard: クラスタの作成、ノードプールの作成、またはノードプールの更新時に、ブートディスクのサイズを増やします。
- Autopilot: より大きなブートディスクをリクエストするには、カスタム コンピューティング クラスを作成し、
machineTypeルールでbootDiskSizeフィールドを設定します。
Cloud Storage からモデルを読み込むときに Pod がクラッシュ ループに入る
--model-bucket-uri フラグで生成されたマニフェストをデプロイすると、Deployment が停止し、Pod が CrashLoopBackOff 状態になることがあります。inference-server コンテナのログを確認すると、huggingface_hub.errors.HFValidationError などの誤解を招くエラーが表示されることがあります。次に例を示します。
huggingface_hub.errors.HFValidationError: Repo id must use alphanumeric chars or '-', '_', '.', '--' and '..' are forbidden, '-' and '.' cannot start or end the name, max length is 96: '/data'.
このエラーは通常、--model-bucket-uri フラグで指定された Cloud Storage パスが正しくない場合に発生します。vLLM などの推論サーバーが、マウントされたパスで必要なモデルファイル(config.json など)を見つけられません。ローカル ファイルが見つからない場合、サーバーはパスが Hugging Face Hub リポジトリ ID であると想定します。パスが有効なリポジトリ ID ではないため、サーバーは検証エラーで失敗し、クラッシュ ループに入ります。
この問題を解決するには、--model-bucket-uri フラグに指定したパスが、モデルの config.json ファイルと関連するすべてのモデルの重みを含む Cloud Storage バケット内の正確なディレクトリを指していることを確認します。
次のステップ
- GKE での AI / ML のオーケストレーション ポータルにアクセスして、GKE で AI / ML ワークロードを実行するための公式ガイド、チュートリアル、ユースケースを確認する。
- モデル サービング最適化の詳細を確認する。GPU を使用して大規模言語モデルの推論を最適化する際のベスト プラクティスをご覧ください。量子化、テンソル並列処理、メモリ管理など、GKE の GPU で LLM を提供する際のベスト プラクティスについて説明します。
- 自動スケーリングのベスト プラクティスの詳細については、次のガイドをご覧ください。
- ストレージのベスト プラクティスについては、GKE のパフォーマンスを向上させるために Cloud Storage FUSE CSI ドライバを最適化するをご覧ください。
- GKE を活用して AI / ML イニシアチブを加速するための試験運用版のサンプルを GKE AI Labs で確認する。