
このページでは、Google Kubernetes Engine(GKE)Inference Gateway の主なコンセプトと機能について説明します。これは、生成 AI アプリケーションの提供を最適化するために GKE Gateway を拡張したものです。
このページでは、次の内容を理解していることを前提としています。
- GKE での AI / ML オーケストレーション
- 生成 AI の用語。
- GKE ネットワーキングのコンセプト(Service、GKE Gateway API など)。
- Google Cloudでのロード バランシング、特にロードバランサが GKE とやり取りする方法。
このページは、次のような方を対象としています。
- AI / ML ワークロードの提供に Kubernetes コンテナ オーケストレーション機能を使用することに関心をお持ちの ML エンジニア、プラットフォーム管理者 / オペレーター、データ / AI スペシャリスト。
- Kubernetes ネットワーキングを操作するクラウド アーキテクトとネットワーク スペシャリスト。
概要
GKE Inference Gateway は GKE Gateway を拡張したもので、生成 AI ワークロードの提供に最適化されたルーティングとロード バランシングを提供します。これにより、AI 推論ワークロードのデプロイ、管理、オブザーバビリティが簡素化されます。
AI/ML ワークロードに最適なロード バランシング戦略を選択するには、GKE での AI/ML モデル推論のロード バランシング戦略を選択するをご覧ください。
機能とメリット
GKE Inference Gateway は、GKE 上の生成 AI アプリケーションに生成 AI モデルを効率的に提供するために次の主要な機能を提供します。
- サポートされている指標:
KV cache hits: Key-Value(KV)キャッシュでのルックアップの成功回数。- GPU または TPU の使用率: GPU または TPU がアクティブに処理している時間の割合。
- リクエスト キューの長さ: 処理を待機しているリクエストの数 。
- 推論用に最適化されたロード バランシング: リクエストを分散して、AI モデル提供のパフォーマンスを最適化します。
KV cache hitsやqueue length of pending requestsなどのモデルサーバーからの指標を消費して、生成 AI ワークロードでアクセラレータ(GPU や TPU など)をより効率的に消費します。これにより、プレフィックス キャッシュ対応ルーティング が有効になります。これは、リクエスト本文の分析によって特定された共有コンテキストを含むリクエストを、キャッシュ ヒットを最大化することで同じモデルレプリカに送信する重要な機能です。このアプローチにより、冗長な計算が大幅に削減され、最初のトークンまでの時間が改善されます。そのため、会話型 AI、検索拡張生成(RAG)、その他のテンプレート ベースの生成 AI ワークロードに非常に効果的です。 - 動的 LoRA ファインチューニング モデル提供: 共通のアクセラレータで動的 LoRA ファインチューニング モデルを提供できます。これにより、共通のベースモデルとアクセラレータで複数の LoRA ファインチューニング モデルを多重化して、モデルの提供に必要な GPU と TPU の数を削減できます。
- 推論用に最適化された自動スケーリング: GKE Horizontal Pod Autoscaler(HPA)は、モデルサーバーの指標を使用して 自動スケーリングを行います。 これにより、コンピューティング リソースの効率的な使用と推論 パフォーマンスの最適化が実現します。
- モデル対応ルーティング: 仕様
で定義されたモデル名
に基づいて推論リクエストを GKE クラスタ内でルーティングします。
OpenAI APIトラフィック分割やリクエスト ミラーリングなどの Gateway ルーティング ポリシーを定義して、さまざまなモデル バージョンを管理し、モデルのロールアウトを簡素化できます。たとえば、特定のモデル名のリクエストを、それぞれ異なるバージョンのモデルを提供する異なる InferencePool オブジェクトにルーティングできます。この構成方法の詳細については、本文ベースの ルーティングを構成するをご覧ください。 - 統合された AI の安全性とコンテンツ フィルタリング: GKE Inference Gateway は Google Cloud Model Armor と統合されており、ゲートウェイでプロンプトとレスポンスに AI 安全性チェックとコンテンツ フィルタリングを適用します。NVIDIA NeMo Guardrails を使用することもできます。Model Armor は、事後分析と最適化のために、リクエスト、回答、処理のログを提供します。 GKE Inference Gateway のオープン インターフェースを使用すると、サードパーティのプロバイダとデベロッパーがカスタム サービスを推論リクエスト プロセスに統合できます。
- モデル固有の提供の
Priority: AI モデルの提供のPriorityを指定できます。レイテンシに敏感なリクエストを、レイテンシに寛容なバッチ推論ジョブよりも優先します。たとえばリソースが制限されている場合は、レイテンシに敏感なアプリケーションからのリクエストを優先し、時間的制約の少ないタスクを破棄できます。 - 予測レイテンシに基づくルーティング: リアルタイム交通情報で継続的にトレーニングされた XGBoost モデルを使用して推論リクエストをルーティングし、リクエストごとの最初のトークンまでの時間(TTFT)と出力トークンあたりの時間(TPOT)の目標を最適化します。分散の大きいワークロードでは、静的ヒューリスティックよりも正確です。GKE Inference Gateway で予測レイテンシに基づくルーティングを使用するをご覧ください。
- 推論のオブザーバビリティ: リクエスト率、レイテンシ、エラー、飽和度などの推論 リクエストのオブザーバビリティ指標を提供します。Cloud Monitoring と Cloud Logging を使用して、推論サービスのパフォーマンスと動作をモニタリングします。詳細な分析情報については、専用の事前構築済みダッシュボードを活用します。詳細については、GKE Inference Gateway ダッシュボードを表示するをご覧ください。
- Apigee を使用した高度な API 管理: Apigee と統合して、API セキュリティ、レート制限、割り当てなどの機能で推論ゲートウェイを強化します。詳細な手順については、 認証と API 管理用に Apigee を構成するをご覧ください。
- 拡張性: 拡張可能なオープンソースの Kubernetes Gateway API Inference Extension 上に構築されており、ユーザー管理の llm-d Endpoint Picker(EPP)アルゴリズムをサポートしています。llm-d によって提供されます。 llm-d によって提供されるllm-d Endpoint Picker(EPP) アルゴリズムは、この拡張機能のコア ルーティング インテリジェンスを提供します。
- マルチポートのサポート: 複数のポートを公開するモデルサーバーをサポートします。これは、データ並列アテンションなどの高度なサービング シナリオに不可欠です。
- ネットワーク エンドポイント グループ(NEG)の制限:Google Cloud バックエンド サービスごとに 50 個の NEG の制限があります。マルチポート InferencePool を使用する場合、各ゾーンの各ポートに専用の NEG が作成されます。たとえば、一般的なリージョン クラスタ(3 つのゾーン)に 8 つのポートを持つ InferencePool は、24 個の NEG を生成します。したがって、マルチクラスタ Gateway は、50 個の NEG の上限に達する前に、最大 2 つのクラスタ(2 つのクラスタ × 24 個の NEG = 48 個の NEG)からこのような InferencePool を集約できます。
主要なコンセプトを理解する
GKE Inference Gateway は、GatewayClass オブジェクトを使用する既存の GKE Gateway を拡張します。GKE Inference Gateway には、推論用の OSS Kubernetes
Gateway API 拡張機能に合わせて、次の新しい
Gateway API カスタム リソース定義(CRD)が導入されています。
- InferencePool オブジェクト: 同じコンピューティング構成、アクセラレータ タイプ、ベース言語モデル、
モデルサーバーを共有する Pod(コンテナ)のグループを表します。これにより、AI モデル提供リソースが論理的にグループ化されて管理されます。1 つの InferencePool オブジェクトは、異なる GKE ノードの複数の Pod にまたがって拡張性と高可用性を提供できます。複数のポートを必要とするモデルサーバーをサポートするために、InferencePool リソースで最大 8 つの
targetPortsを指定できます。 - InferenceObjective オブジェクト: InferencePool のサービング モデルの名前を
OpenAI API仕様に従って指定します。InferenceObjective オブジェクトは、AI モデルのPriorityなど、モデルのサービング プロパティも指定します。GKE Inference Gateway は、優先度の値が高いワークロードを優先します。これにより、レイテンシが重要な AI ワークロードとレイテンシに寛容な AI ワークロードを GKE クラスタで多重化できます。LoRA ファインチューニング モデルを提供する InferenceObjective オブジェクトを構成することもできます。
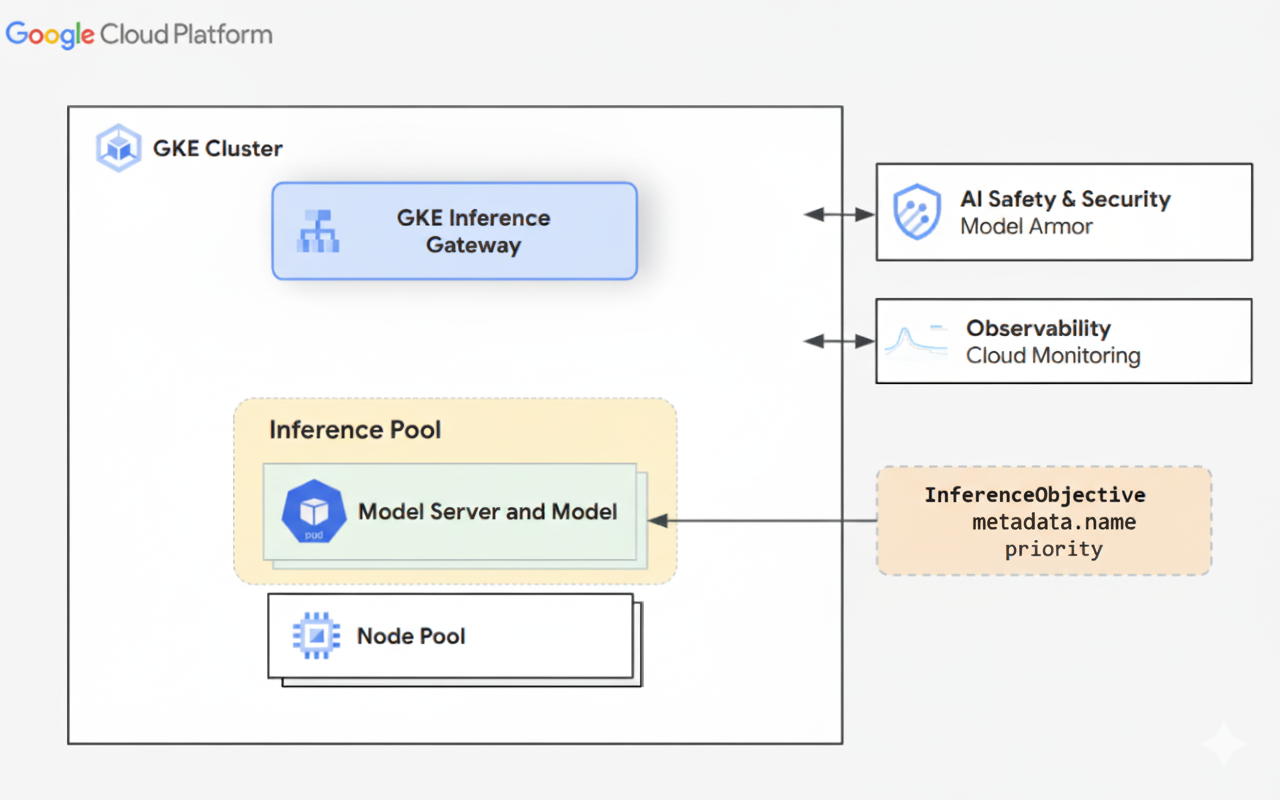
次の図は、GKE クラスタ内の GKE Inference Gateway と、その AI の安全性、オブザーバビリティ、モデル提供との統合を示しています。
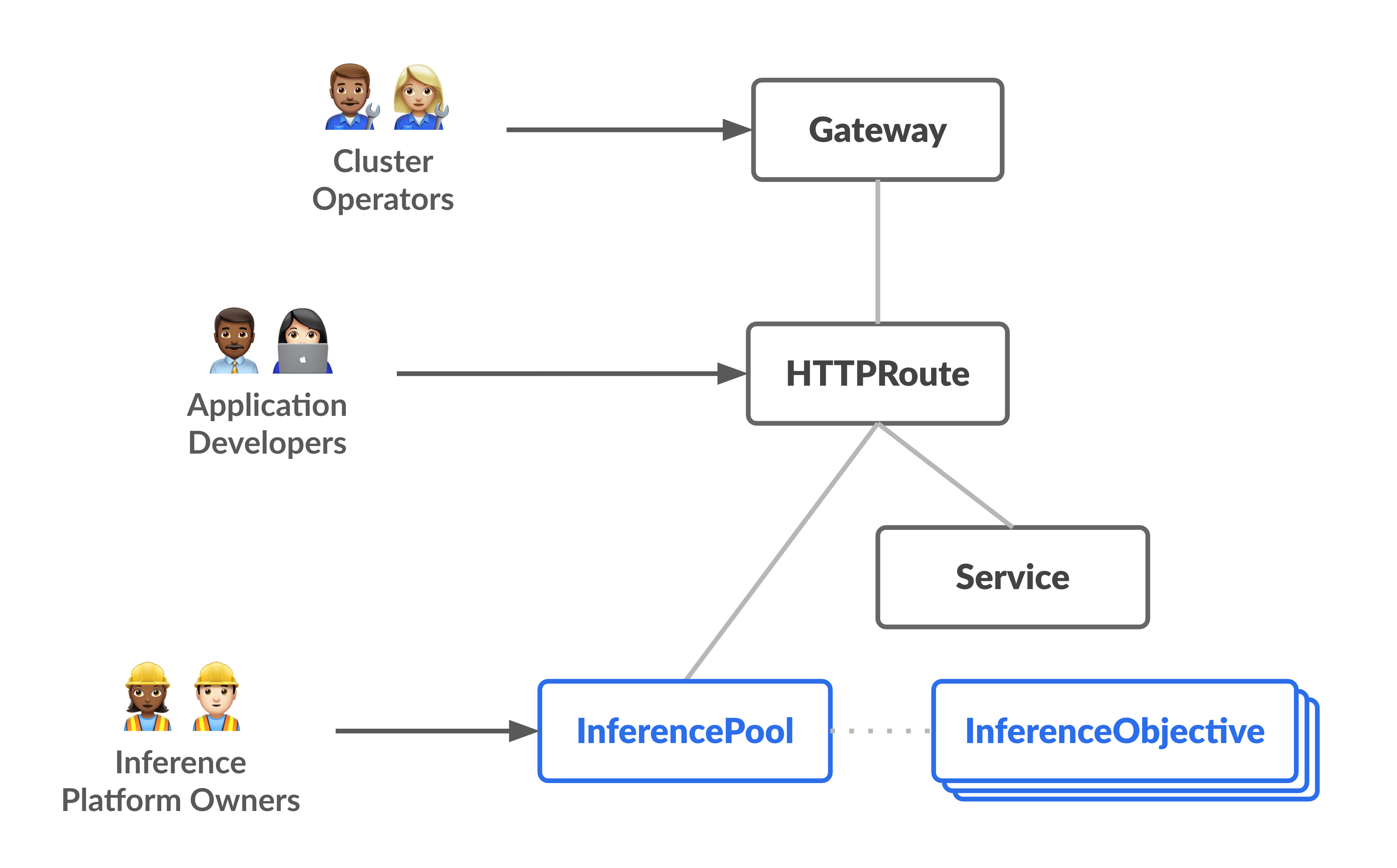
次の図は、2 つの新しい推論重視のペルソナと、それらが管理するリソースに焦点を当てたリソースモデルを示しています。
llm-d ルーター
llm-d ルーターは、Inference Gateway がリクエストごとのエンドポイントを決定するために使用するインテリジェントなリクエスト ルーティング コンポーネントです。これは、次の 2 つのサブコンポーネントで構成されています。
| サブコンポーネント | 説明 |
|---|---|
| L7 Proxy | データプレーン(接続管理、TLS 終端、リクエスト転送)を処理する、準拠した業界グレードの L7 プロキシ(通常は Envoy) GKE Inference Gateway(Gateway モード)では、 Proxy は GKE Gateway です。 |
| llm-d Endpoint Picker (EPP) | Proxy が ext-proc プロトコルを使用してリクエストごとに参照する専用サービス。EPP にはルーティング
インテリジェンスが含まれています。モデルサーバーからのリアルタイム シグナル
(KV キャッシュ使用率、キューの長さ、プレフィックス キャッシュの状態、LoRA
アダプタ アフィニティ)を使用して、リクエストごとに最適なモデルサーバー Pod を選択します。 |
Gateway モード
GKE Inference Gateway は、Gateway モードで動作する llm-d Router です。Gateway モードでは、Proxy は EPP サービスとは別にプロビジョニングおよび管理される正式な Kubernetes Gateway です。Gateway は ext-proc を介して EPP を呼び出してルーティングを決定し、選択したモデルサーバー Pod にリクエストを直接転送します。
Gateway(データプレーン)と EPP(ルーティング インテリジェンス)を分離することで、次のことが可能になります。
- 共有インフラストラクチャ: 単一の GKE Gateway が、標準の Kubernetes Service とともに 複数の InferencePool を提供します。
- 高度なトラフィック管理:
HTTPRouteポリシーは、重み付け分割、段階的なロールアウト、リクエスト ミラーリングをサポートしています。 - 独立したスケーリング: EPP サービスは Gateway とは独立してスケーリングされます。
- クラウドネイティブな統合: GKE のマネージド Gateway コントローラ、Cloud Load Balancing、既存のオブザーバビリティ ツールと連携します。
GKE Inference Gateway の仕組み
GKE Inference Gateway は、Gateway API 拡張機能とモデル固有のルーティング ロジックを使用して、AI モデルへのクライアント リクエストを処理します。リクエスト フローは次のとおりです。
リクエスト フローの仕組み
GKE Inference Gateway は、最初のリクエストからモデル インスタンスまでクライアント リクエストをルーティングします。このセクションでは、GKE Inference Gateway がリクエストを処理する方法について説明します。このリクエスト フローはすべてのクライアントに共通です。
- クライアントが、OpenAI API 仕様で説明されている形式のリクエストを、 GKE で実行されているモデルに送信します。
GKE Inference Gateway が、次の推論拡張機能を使用してリクエストを処理します。
- 本文ベースのルーティング拡張機能: クライアント リクエストの本文からモデル ID を抽出して、GKE Inference Gateway に送信します。
GKE Inference Gateway は、この ID を使用して、Gateway API
HTTPRouteオブジェクトで定義されたルールに基づいてリクエストをルーティングします。リクエスト本文のルーティングは、URL パスに基づくルーティングに似ています。違いは、リクエスト本文のルーティングではリクエスト本文のデータが使用されることです。 - セキュリティ拡張機能: Model Armor、NVIDIA NeMo Guardrails、またはサポートされているサードパーティ ソリューションを使用して、コンテンツ フィルタリング、脅威検出、サニタイゼーション、ロギングなどのモデル固有のセキュリティ ポリシーを適用します。セキュリティ拡張機能は、これらのポリシーをリクエストと回答の両方の処理パスに適用します。
- llm-d Endpoint Picker(EPP): InferencePool 内のモデルサーバーからの主要な 指標をモニタリングし、リクエストを最適なモデルレプリカに ルーティングします。詳細については、 llm-d ルーターをご覧ください。
- 本文ベースのルーティング拡張機能: クライアント リクエストの本文からモデル ID を抽出して、GKE Inference Gateway に送信します。
GKE Inference Gateway は、この ID を使用して、Gateway API
GKE Inference Gateway が、エンドポイント選択拡張機能によって返されたモデルレプリカにリクエストをルーティングします。
次の図は、GKE Inference Gateway によるクライアントからモデル インスタンスへのリクエスト フローを示しています。

トラフィック分配の仕組み
GKE Inference Gateway は、InferencePool オブジェクト内のモデルサーバーに推論リクエストを動的に分散します。これにより、リソース使用率を最適化し、さまざまな負荷条件下でパフォーマンスを維持できます。 GKE Inference Gateway は、次の 2 つのメカニズムを使用してトラフィック分散を管理します。
エンドポイントの選択: 推論リクエストを処理するのに最適なモデルサーバーを動的に選択します。サーバーの負荷と可用性をモニタリングし、複数の最適化ヒューリスティックを組み合わせて各サーバーの
scoreを計算することで、最適なルーティングの決定を行います。- プレフィックス キャッシュ対応ルーティング: GKE Inference Gateway は、各モデルサーバーで使用可能なプレフィックス キャッシュ インデックスを追跡し、プレフィックス キャッシュの一致が長いサーバーに高いスコアを付けます。
- 負荷認識ルーティング: GKE Inference Gateway はサーバーの負荷(KV キャッシュ使用率と保留中のキューの深さ)をモニタリングし、負荷の低いサーバーに高いスコアを付けます。
- LoRA 認識ルーティング: 動的 LoRA サービングが有効になっている場合、GKE Inference Gateway はサーバーごとにアクティブな LoRA アダプタをモニタリングし、リクエストされた LoRA アダプタがアクティブになっているサーバー、またはリクエストされた LoRA アダプタを動的に読み込むための空き容量があるサーバーに高いスコアを付けます。上記の合計スコアが最も高いサーバーが選択されます。
キューイングと負荷制限: リクエスト フローを管理し、トラフィックの過負荷を防ぎます。GKE Inference Gateway は、受信リクエストをキューに保存し、定義された優先度に基づいてリクエストの優先度を設定します。
GKE Inference Gateway は、数値 Priority システム(Criticality とも呼ばれます)を使用して、リクエスト フローを管理し、過負荷を防止します。この Priority は、ユーザーが各 InferenceObjective に対して定義する省略可能な整数フィールドです。値が大きいほど、リクエストの重要度が高くなります。システムに負荷がかかると、Priority が 0 より小さいリクエストは優先度が低いと見なされ、最初に破棄されて 429 エラーが返され、より重要なワークロードが保護されます。デフォルトでは、Priority は 0 です。リクエストが優先度によって破棄されるのは、Priority が 0 より小さい値に明示的に設定されている場合のみです。このシステムを使用すると、レイテンシの影響を受けやすいオンライン推論トラフィックを、時間的制約の少ないバッチジョブよりも優先できます。
GKE Inference Gateway は、継続的または準リアルタイムの更新が必要な chatbot やリアルタイム翻訳などのアプリケーションのためにストリーミング推論をサポートしています。ストリーミング推論では、回答を単一の完全な出力ではなく増分チャンクまたはセグメントで提供します。ストリーミング レスポンス中にエラーが発生すると、ストリーミングが終了し、クライアントにエラー メッセージが送信されます。GKE Inference Gateway はストリーミング レスポンスを再試行しません。
アプリケーションの例を確認する
このセクションでは、GKE Inference Gateway を使用してさまざまな生成 AI アプリケーション シナリオに対処する例を示します。
例 1: GKE クラスタで複数の生成 AI モデルを提供する
ある企業が、複数の大規模言語モデル(LLM)をデプロイして、さまざまなワークロードに対応したいと考えています。たとえば、chatbot インターフェース用に Gemma3 モデルをデプロイし、レコメンデーション アプリケーション用に DeepSeek モデルをデプロイする、などです。これらの LLM のサービング パフォーマンスを最適化する必要もあります。
GKE Inference Gateway を使用すると、InferencePool で選択したアクセラレータ構成を使用してこれらの LLM を GKE クラスタにデプロイし、 モデルの名前(chatbot や recommender など)と Priority プロパティに基づいてリクエストをルーティングできます。
次の図は、GKE Inference Gateway がモデルの名前と Priority に基づいてリクエストを異なるモデルにルーティングする方法を示しています。
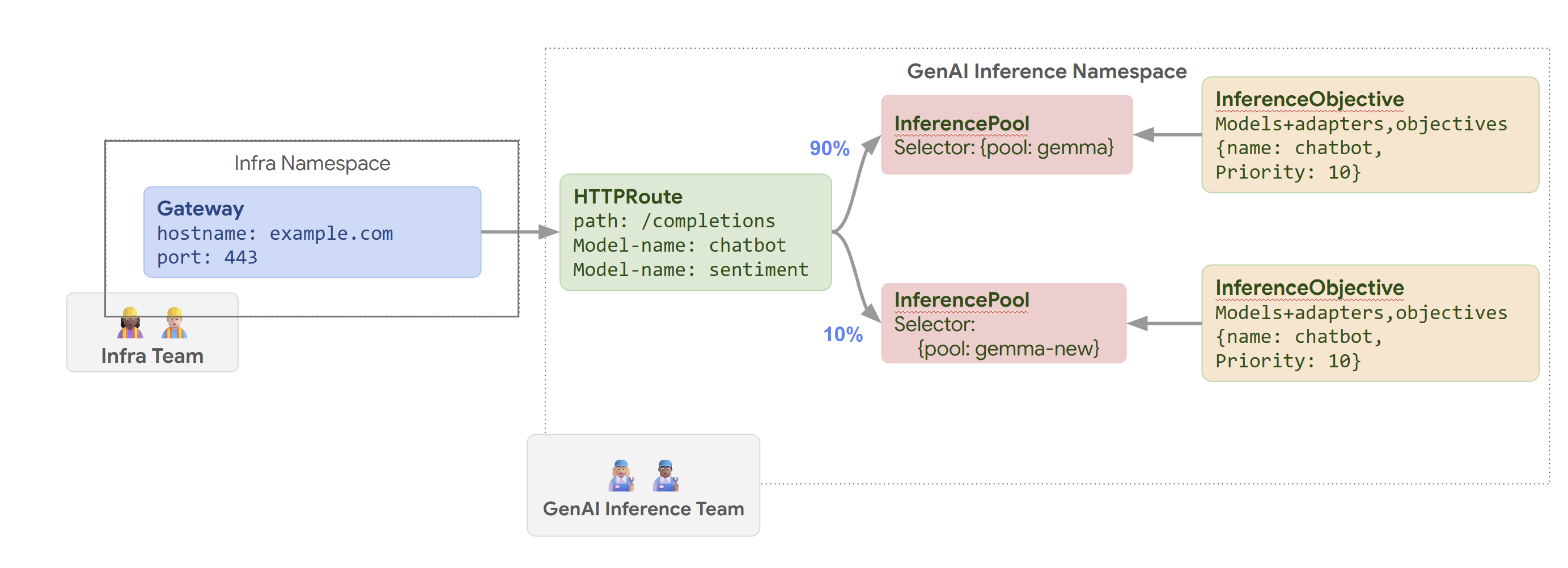
この図は、example.com/completions の GenAI サービスに対するリクエストが GKE Inference Gateway によって処理される仕組みを示しています。リクエストは、まず Infra 名前空間の Gateway に到達します。この Gateway は、リクエストを GenAI Inference 名前空間の HTTPRoute に転送します。これは、chatbot モデルと感情分析モデルのリクエストを処理するように構成されています。chatbot モデルの場合、HTTPRoute はトラフィックを分割します。90% は現在のモデル バージョン({pool: gemma} で選択される)を実行している InferencePool に転送され、10% は新しいバージョン({pool: gemma-new})を含むプールに転送されます(通常はカナリアテスト用)。両方のプールは InferenceObjective にリンクされており、chatbot モデルのリクエストに 10 の Priority を割り当て、これらのリクエストが優先度の高いリクエストとして扱われるようにします。
例 2: 共有アクセラレータで LoRA アダプタをサービングする
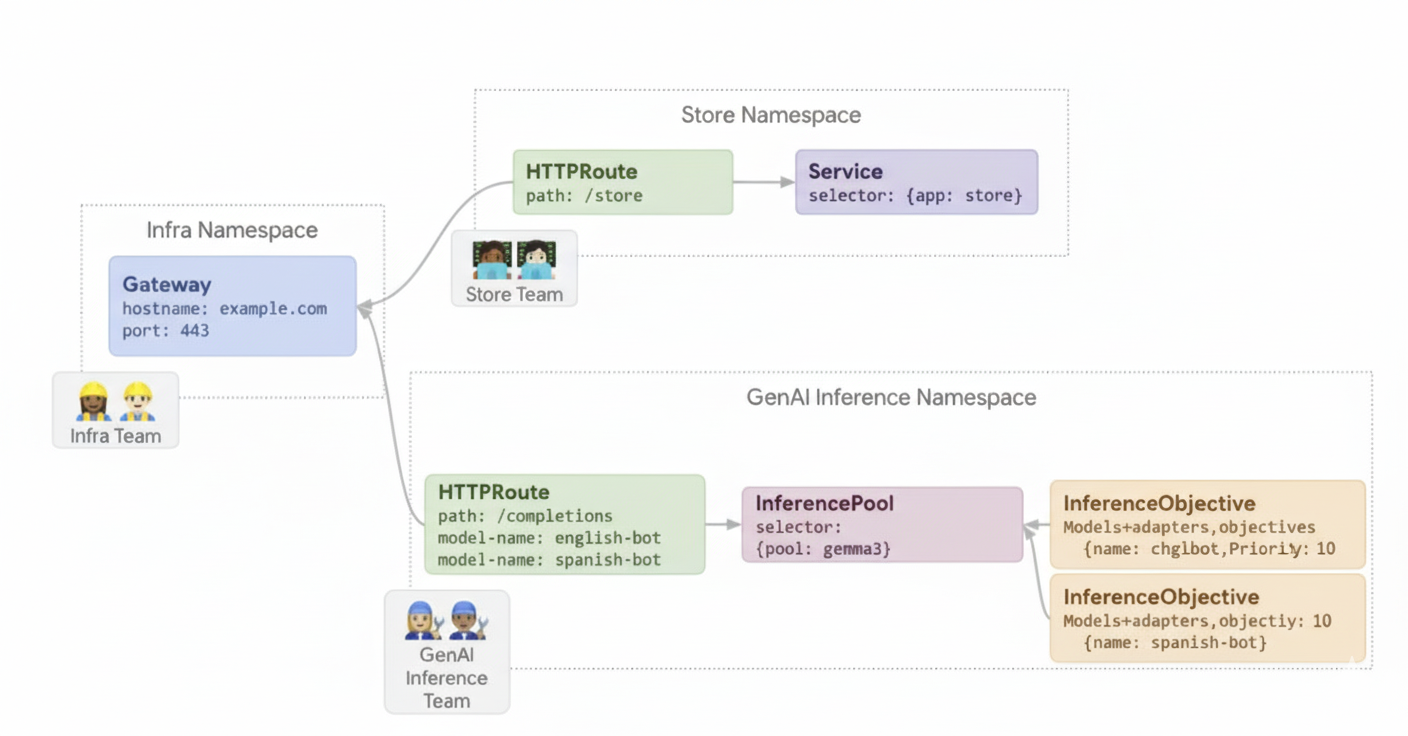
ある企業が、英語やスペイン語など複数の言語のオーディエンスに焦点を当てて、ドキュメント分析用の LLM を提供したいと考えています。言語ごとにファイン チューニングされたモデルがありますが、GPU と TPU の容量を効率的に使用する必要があります。GKE Inference Gateway を使用すると、各言語の動的 LoRA ファインチューニング アダプタ(english-bot や spanish-bot など)を、共通のベースモデル(llm-base など)とアクセラレータにデプロイできます。これにより、複数のモデルを共通のアクセラレータに密集させて配置することで、必要なアクセラレータの数を減らすことができます。
次の図は、GKE Inference Gateway が共有アクセラレータで複数の LoRA アダプタを提供する方法を示しています。
次のステップ
- GKE Inference Gateway をデプロイする
- GKE Inference Gateway の構成をカスタマイズする
- GKE Inference Gateway を使用して LLM をサービングする
- GKE Inference Gateway(プレビュー)で予測レイテンシに基づくルーティングを使用する