
このドキュメントでは、Conversational Analytics API(geminidataanalytics.googleapis.com またはリージョン エンドポイントを介してアクセス)を使用するための重要なコンセプトについて説明します。この API を使用すると、自然言語を使用して構造化データに関する質問に回答するデータ エージェントを作成してやり取りできます。このドキュメントでは、エージェントのアーキテクチャ、一般的なワークフロー、会話モード、Identity and Access Management(IAM)ロール、マルチエージェント システムの設計について説明します。
Conversational Analytics API で利用可能なアーキテクチャ アプローチと、API が会話コンテキストを管理する方法については、統合パターンと状態管理をご覧ください。
データ エージェントの仕組み
Conversational Analytics API のデータ エージェントは、提供されたコンテキスト(ビジネス情報やビジネスデータ)とツール(SQL や Python など)を使用して、自然言語の質問を解釈し、構造化データからレスポンスを生成します。
次の図は、ユーザーが質問したときのエージェントのワークフローの各ステージを示しています。
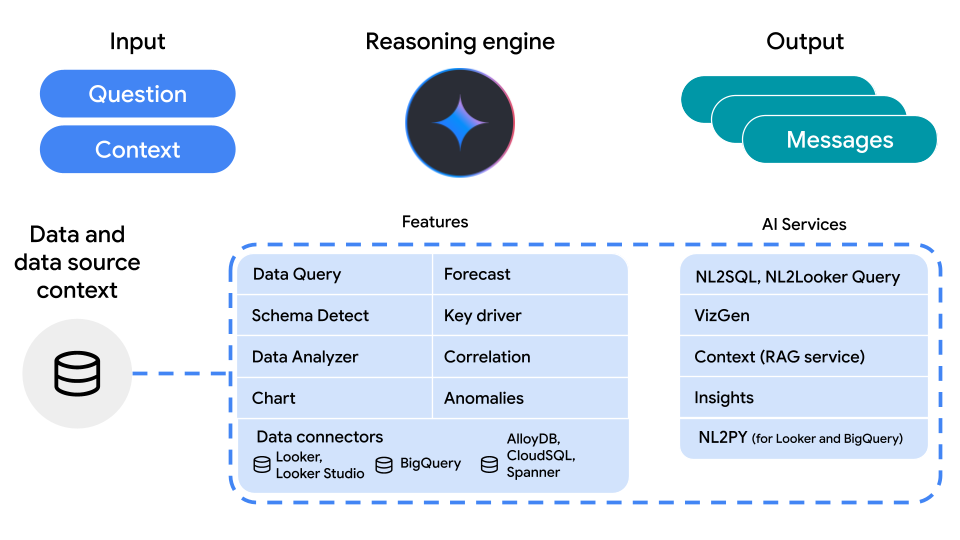
図に示すように、ユーザーが質問すると、エージェントは次のステージでリクエストを処理します。
- 入力: ユーザーが質問を自然言語で送信します。このとき、以前に提供した追加のコンテキストも送信できます。
- データソース: エージェントは、Looker、BigQuery(テーブルまたはグラフのいずれかを含む)、データポータルのデータに接続してチャット機能を実現します。また、
QueryDataメソッドを使用して、AlloyDB、GoogleSQL for Spanner、Cloud SQL for MySQL、Cloud SQL for PostgreSQL データベースからデータをクエリすることもできます。 - 推論エンジン: エージェントの中核となる部分で、利用可能なツールを使用してユーザーの質問を処理し、回答を生成します。
- 出力: エージェントがメッセージのストリームを返します。メッセージには、テキスト、データ、グラフを含めることができます。これらのメッセージには、回答テキストの特定の部分を、用語集の用語やクエリの例など、提供されたコンテキスト ソースにリンクする引用が含まれる場合があります。一部のデータソースでは、テキスト メッセージでエージェントの推論に関するステップバイステップの分析情報が提供されたり、アクションの進行状況が報告されたり、クエリに対する最終的な回答が提供されたりします。
エージェントの設計と使用のワークフロー
Conversational Analytics API は、(エージェントを構築して構成する)エージェント作成者と(既存のエージェントとやり取りする)エージェント利用者のワークフローをサポートしています。
次の図は、エージェント作成者による初期設定からエージェント利用者との最終的なやり取りまでのエンドツーエンドのプロセスを示しています。
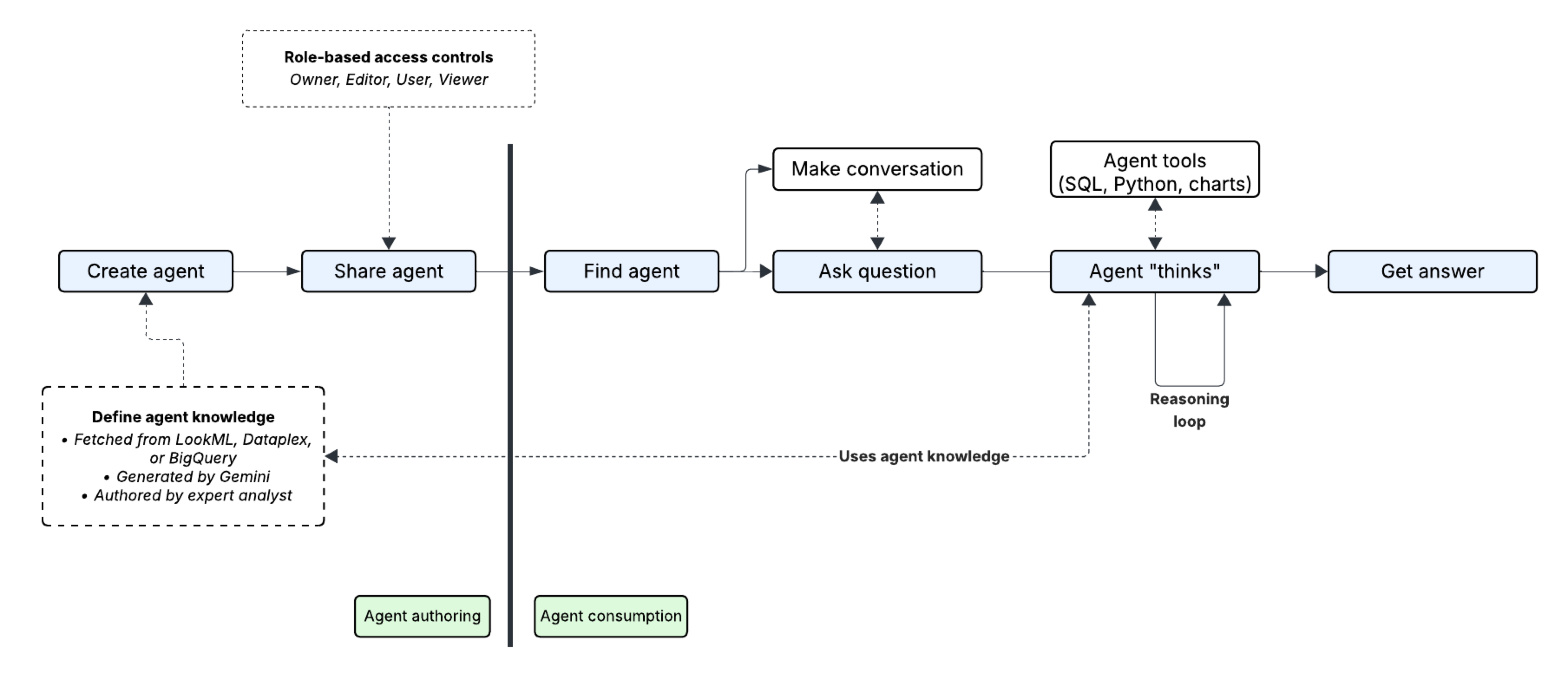
以降のセクションでは、エージェント作成者とエージェント利用者のワークフローについて詳しく説明します。
エージェント作成者のワークフロー
エージェント作成者は、エージェントの設定と構成を担当します。このワークフローには次のステップが含まれます。
- エージェントを作成する: 作成者はまず、新しいエージェントを作成し、システム指示やデータソースへの接続など、必要なコンテキストを指定します。このステップは、エージェントがユーザーの質問を効果的に理解して回答できるようにするために不可欠です。
- エージェントを共有する: エージェントを構成したら、作成者は他のユーザーと共有し、権限を管理するための適切なロールベース アクセス制御を設定します。
エージェント利用者のワークフロー
エージェント利用者は通常、構成済みのエージェントから回答を取得する必要があるビジネス ユーザーです。このワークフローには次のステップが含まれます。
- エージェントを見つける: ユーザーはまず、自分と共有されているエージェントを見つけます。
- 質問する: ユーザーが自然言語で質問します。この質問は、単一のクエリである場合も、複数ターンの会話の一部である場合もあります。
- エージェントが「思考」する: エージェントの推論エンジンが質問を処理します。推論エンジンは、エージェントの事前定義されたナレッジと利用可能なエージェント ツール(SQL、Python、グラフなど)を「推論ループ」で使用して、質問に回答する最適な方法を判断します。
- エージェントが回答する: エージェントがメッセージのストリームを返します。メッセージには、テキスト、データ、グラフを含めることができます。一部のデータソースでは、テキスト メッセージでエージェントの推論に関するステップバイステップの分析情報が提供されたり、アクションの進行状況が報告されたり、クエリに対する最終的な回答が提供されたりします。
会話モード
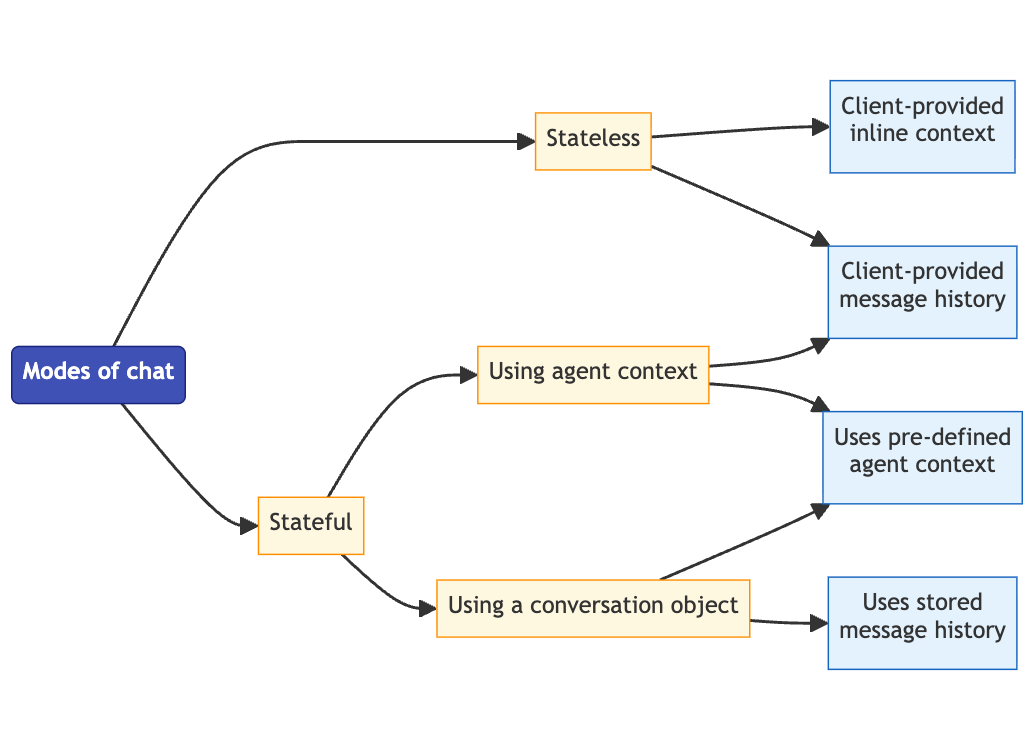
Conversational Analytics API エージェントは、エージェントが会話履歴を処理する方法とインタラクション間でのコンテキストの永続性を決定するさまざまな会話モードをサポートしています。次の会話モードを使用できます。
- ステートレス モード: エージェントは会話履歴を保存しません。各インタラクションは個別に処理されます。このモードは、複数のターンにわたってコンテキストを維持する必要がないアプリケーションで役立ちます。
- ステートフル モード: エージェントはコンテキストと会話履歴を保持し、よりコンテキストを考慮したインタラクションを可能にします。このモードは、複数のターンにわたってコンテキストを維持する必要があるアプリケーションで役立ちます。より正確でパーソナライズされたレスポンスを得るには、ステートフル モードを使用することをおすすめします。
会話履歴とコンテキストの永続性に関するアプリケーションの要件に基づいて、会話モードを選択してください。
IAM ロール
IAM ロールは、Conversational Analytics API エージェントの作成、管理、共有、やり取りを行うことができるユーザーを制御します。次の表に、Conversational Analytics API の主な IAM ロールを示します。
| ロール | 一般的なスコープ | このロールで実行できること | このロールを使用するユーザーの例 |
|---|---|---|---|
Gemini データ分析データ エージェント作成者(roles/geminidataanalytics.dataAgentCreator) |
プロジェクト | エージェントを作成し、エージェントのオーナー権限を継承します。 | データ アナリスト |
Gemini データ分析データ エージェント オーナー(roles/geminidataanalytics.dataAgentOwner) |
プロジェクト、エージェント | エージェントを編集、削除、他のユーザーと共有します。 | シニア データ アナリスト |
Gemini データ分析データ エージェント編集者(roles/geminidataanalytics.dataAgentEditor) |
エージェント、プロジェクト | エージェントの構成またはコンテキストを更新します。 | ジュニア データ アナリスト |
Gemini データ分析データ エージェント ユーザー(roles/geminidataanalytics.dataAgentUser) |
エージェント、プロジェクト | エージェントとチャットします。 | マーケター、店舗オーナー |
Gemini データ分析データ エージェント閲覧者(roles/geminidataanalytics.dataAgentViewer) |
プロジェクト、エージェント | エージェントを一覧表示して詳細を取得します。エージェントを編集することはできません。 | すべてのユーザー |
Gemini データ分析データクエリ ユーザー(roles/geminidataanalytics.queryDataUser) |
プロジェクト | QueryData メソッドを使用して、サポートされているデータベース ソースからデータをクエリします。 |
アプリケーション デベロッパー、データ アナリスト |
Gemini データ分析ステートレス チャット ユーザー(roles/geminidataanalytics.dataAgentStatelessUser) |
プロジェクト | コンテキストや会話履歴を保存せずにエージェントとチャットします。 | すべてのユーザー |
複数のエージェントを含むシステム
複数の Conversational Analytics API エージェントを統合することで、複雑なシステムを設計できます。よくあるパターンとしては、プライマリ「オーケストレーター」エージェントを使用して、特定のドメイン(販売データやマーケティング データなど)を処理する 1 つ以上の専門エージェントにタスクを委任します。このアプローチでは、複数のエージェントの強みを組み合わせて、幅広い質問に対応できるシステムを構築できます。
次の図は、このマルチエージェント パターンを示したもので、プライマリ エージェントがデータに関する質問を専門の Conversational Analytics エージェントに委任する仕組みを示しています。
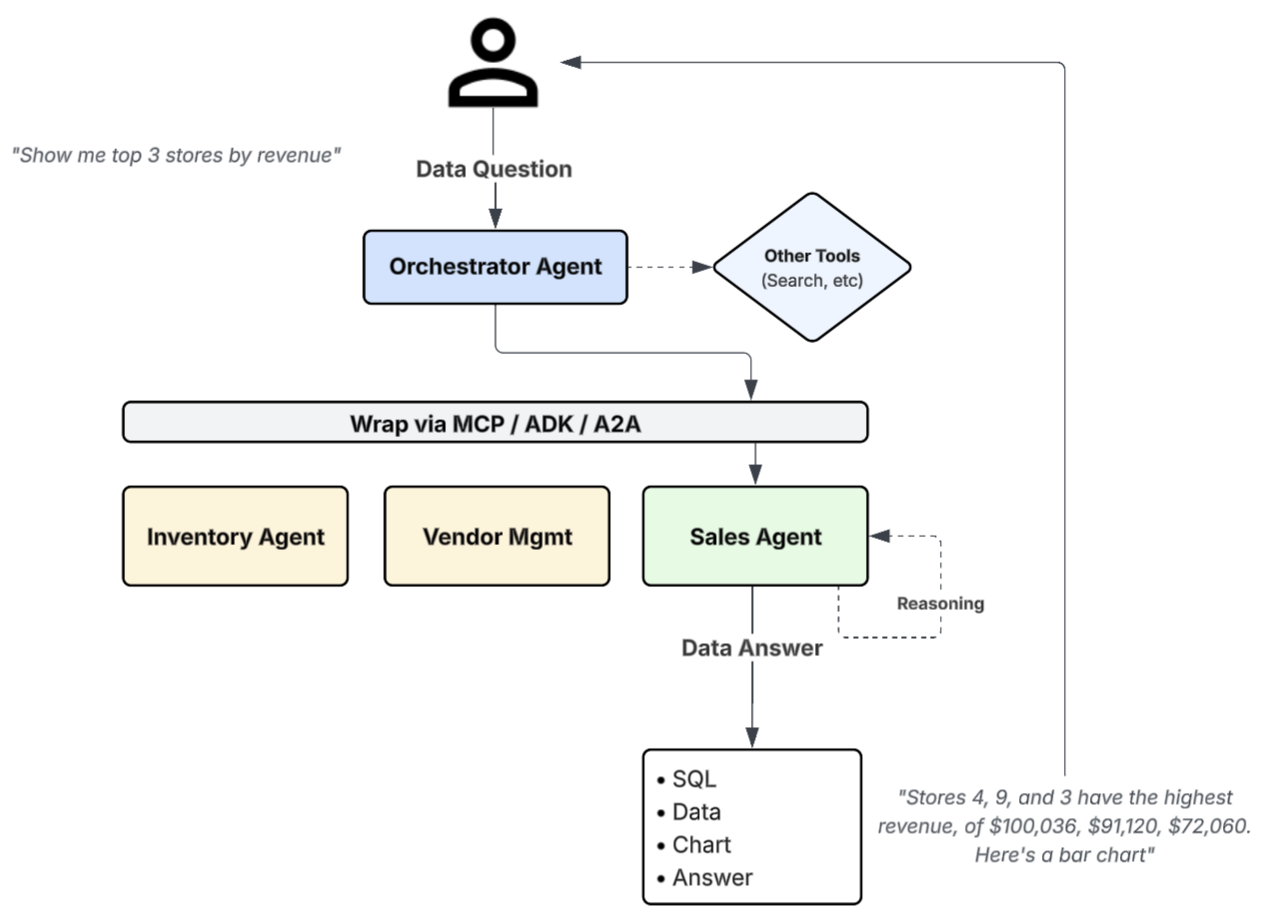
マルチエージェント システムの一般的なワークフローには、次のステップが含まれます。
- ビジネス ユーザーまたはデータ アナリストが自然言語で質問します(「収益上位 3 店舗を示して」など)。
- プライマリ「オーケストレーター」エージェントが、リクエストを適切な専門エージェントに委任します。
- 専門エージェントが委任されたリクエストを受け取り、関連するデータソースに接続し、ツールを使用して必要な SQL クエリとグラフを生成して、レスポンスを生成します。
- 専門エージェントのレスポンスがユーザーに返されます(「収益上位の店舗は 4、9、3 です。グラフをご確認ください」)。
次のステップ
Conversational Analytics API の基本的なコンセプトを理解したら、次の機能の実装方法を確認してください。
- アーキテクチャの統合パターンを比較して、アプリケーションに最適なアプローチを決定します。
- データ エージェントの状態管理と、API による会話コンテキストの管理方法を理解する。
- データソースの認証と接続を行う方法を確認する。
- HTTP を使用してエージェントを作成して構成する方法を学習する。
- Python を使用してエージェントを作成して構成する方法を学習する。
- 作成されたコンテキストでエージェントの動作をガイドする方法を学習する。
- IAM による Conversational Analytics API のアクセス制御について理解する。
- CMEK を使用してデータ エージェントと会話を保護する方法を確認する。
- Looker データソースのエージェント レスポンスをレンダリングする方法を確認する。