

Il servizio di distillazione Gemini (distillazione) consente agli utenti di addestrare un modello "studente" più piccolo ed efficiente che utilizza gli output e i pattern di ragionamento di un modello "insegnante" più grande e potente. Sebbene i modelli all'avanguardia definiscano la frontiera dell'AI, possono essere sovrautilizzati per casi d'uso aziendali specifici. La distillazione colma questo divario, consentendo un'efficienza di livello di produzione (latenza e costi inferiori) e permettendo ai modelli più piccoli di raggiungere un livello di ragionamento più profondo.
A differenza del fine-tuning supervisionato (SFT) standard, che utilizza solo l'output di testo finale, la distillazione sfrutta:
- Risposte dell'insegnante: l'output di testo finale.
- Pensieri grezzi: i percorsi di ragionamento interni generati dal modello insegnante.
Modelli supportati
I seguenti modelli sono supportati per la Distillazione durante l'accesso in anteprima:
- Modello per insegnanti:
gemini-3.1-pro - Modello dello studente:
gemini-2.5-flash
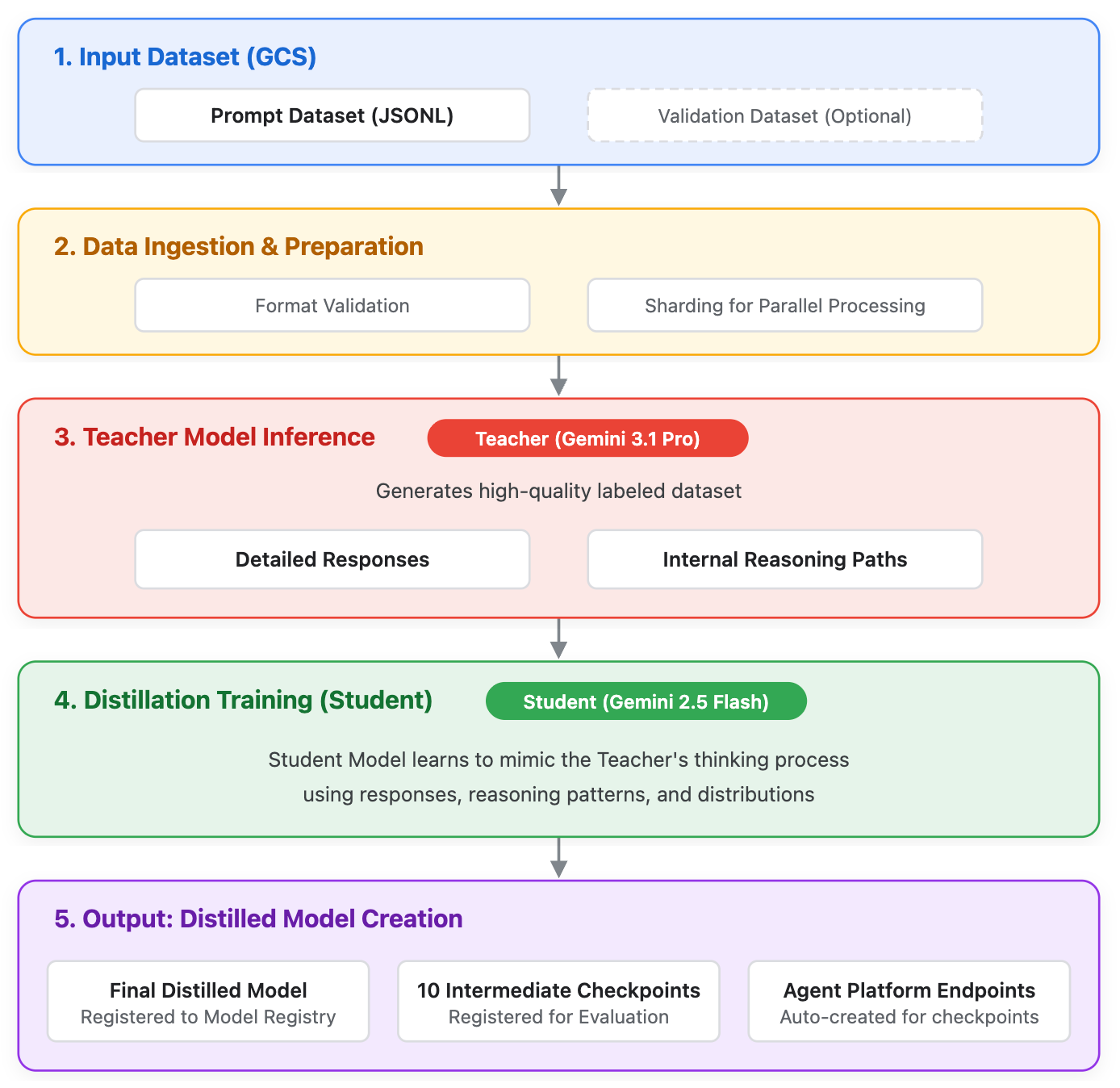
Fig. 1 Illustrazione del sistema che mostra come funziona Gemini Distillation Service.
Casi d'uso adatti
La distillazione è consigliata rispetto al prompting standard o al fine-tuning supervisionato (SFT) nei seguenti scenari:
- Applicazioni ad alto volume e sensibili alla latenza: quando la tua applicazione richiede le funzionalità di ragionamento di un modello di livello Pro, ma deve rispettare SLA di latenza rigorosi o vincoli di budget che richiedono un modello di livello Flash.
- Mancanza di dati di riferimento (SFT non fattibile): quando hai un set di dati di prompt o query degli utenti di grandi dimensioni, ma non disponi delle risorse per etichettare o generare manualmente risposte di riferimento di alta qualità necessarie per la SFT standard.
- Attività di ragionamento complesse: attività che prevedono una logica in più fasi, il riepilogo di documenti altamente tecnici o attività di programmazione complesse in cui il modello Flash di base ha difficoltà, ma il modello Pro riesce.
- Significativi divari di prestazioni: quando il modello dell'insegnante supera in modo sostanziale il modello di base dello studente in un'attività specifica, fornendo un chiaro margine di conoscenza da trasferire durante la distillazione.
Prerequisiti e configurazione del progetto
Prima di avviare un job di distillazione, assicurati che l'ambiente Google Cloud sia configurato correttamente:
- Richiedi l'accesso alla lista consentita: assicurati che l'ID progetto Google Cloud sia stato aggiunto alla lista consentita per l'accesso in anteprima al servizio di distillazione di Gemini. Contatta il tuo rappresentante di vendita Google per aggiungere il tuo progetto alla lista consentita.
- Abilita l'API: abilita l'API Agent Platform nel tuo progetto Google Cloud .
- Imposta le autorizzazioni del ruolo IAM: devi disporre del ruolo IAM
Amministratore Agent Platform (
roles/aiplatform.admin). - Imposta la regione: i job di distillazione devono essere eseguiti nella regione
us-central1.
Preparazione del set di dati
Una funzionalità chiave di questo servizio è l'utilizzo di set di dati solo con prompt. Poiché il modello insegnante genera gli output di destinazione durante il processo di distillazione, non è necessario fornire le risposte previste.
Requisiti del set di dati
I set di dati devono essere in formato JSON Lines (JSONL) e archiviati in un bucket Cloud Storage. Ogni voce deve rispettare il formato del set di dati di ottimizzazione di Gemini, oltre a quanto segue:
- Istruzioni di sistema: puoi includere un campo
systemInstructionfacoltativo (con un ruolo "system") per definire i prompt di sistema. - Input: il campo dei contenuti (con il ruolo "utente") è obbligatorio per l'input principale.
Prompt multi-turn: puoi alternare i ruoli "utente" e "modello", a condizione che l'ultima voce della sequenza sia "utente".
Di seguito sono riportati due esempi di file dataset.jsonl:
{
"contents": [
{
"role": "user",
"parts": [
{
"text": "You're the artist here. Choose as many strands of thread as you like, as long as you're using three or more. Go for color combinations that you think would make a pretty pattern. Get creative! If you only use one color of thread, you won't be able to create a pattern.\n\nProvide a summary of the article in two or three sentences:\n\n"
}
]
}
]
},
{
"contents": [
{
"role": "user",
"parts": [
{
"text": "You're the artist here. Choose as many strands of thread as you like, as long as you're using three or more. Go for color combinations that you think would make a pretty pattern. Get creative! If you only use one color of thread, you won't be able to create a pattern.\n\nProvide a summary of the article in two or three sentences:\n\n"
}
]
},
{
"role": "model",
"parts": [
{
"text": "Choose several strands of embroidery thread in a variety of colors."
}
]
},
{
"role": "user",
"parts": [
{
"text": "You will need one egg (raw or hard boiled but hard boiled is best) and one spoon for each person participating in the race. You might even like to use dyed Easter eggs as something special for Easter. It's best to have this race on grass or some other soft surface, to give dropped eggs a chance!"
}
]
}
]
}
Best practice
Segui queste linee guida quando crei il set di dati:
- Dimensioni: per un miglioramento notevole della qualità,si consiglia un minimo di 1000 esempi.
- Diversità: assicurati che i prompt coprano i casi limite e le varie lunghezze previste nel traffico di produzione.
Configura la richiesta di distillazione
Un job di distillazione richiede la configurazione sia del comportamento di generazione dell'insegnante sia degli iperparametri di addestramento dello studente.
Configurare il comportamento di generazione del modello insegnante
Devi definire il modo in cui il modello insegnante risponde al tuo set di dati. La qualità del modello studente è direttamente legata alla qualità dell'output dell'insegnante. Per
configurare il comportamento di generazione del modello di insegnante, imposta candidateCount:
candidateCount: il numero di varianti di risposta da generare. (Esempio:4. Intervallo[1, 5]). Se non è specificato nella richiesta, verrà utilizzato un valore predefinito di4.
Imposta gli iperparametri di distillazione
Gli iperparametri di distillazione controllano il processo di addestramento del modello studente. Per saperne di più sugli iperparametri in Gemini Enterprise Agent Platform, consulta la sezione"Crea un job di ottimizzazione" della guida al fine-tuning supervisionato.
Quando crei un job di distillazione, devi impostare i seguenti iperparametri:
epochCount: il numero di volte in cui il modello studente itererà sul set di dati. (Esempio:20. Intervallo[1, 100]). Se non specificato, viene utilizzato un valore predefinito di4.learningRateMultiplier: modifica il tasso di apprendimento di base del modello studente. (Esempio:2.0. Intervallo[0.25, 4]). Se non specificato, viene utilizzato un valore predefinito di1.
Avvia il job di distillazione
Durante il periodo di accesso in anteprima, puoi inviare e monitorare i job di distillazione utilizzando la versione REST dell'API Agent Platform. Puoi avviare un nuovo job di distillazione o eseguire l'ottimizzazione continua su un checkpoint del modello già distillato.
Crea un nuovo job di distillazione
Crea un file JSON denominato request.json contenente la configurazione del job. Nell'esempio seguente, la configurazione di generazione dell'insegnante è nidificata all'interno del campo hyperParameters:
{
"description": "Distillation testing job.",
"baseModel": "gemini-2.5-flash",
"tunedModelDisplayName": "flash-distillation-run-1",
"distillationSpec": {
"promptDatasetUri": "gs://your-bucket/path/to/prompt_dataset.jsonl",
"validationDatasetUri": "",
"base_teacher_model": "gemini-3.1-pro-preview",
"hyperParameters": {
"epochCount": "20",
"learningRateMultiplier": 2.0,
"generation_config": {
"candidateCount": 5
}
}
}
}
Invia il job utilizzando curl:
curl -X POST \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
https://us-central1-aiplatform.googleapis.com/v1beta1/projects/PROJECT_ID/locations/us-central1/tuningJobs \
-d @request.json
Esegui l'ottimizzazione continua
Se vuoi riprendere l'ottimizzazione da un checkpoint del modello distillato in precedenza,
includi il blocco preTunedModel nel file request.json. L'ottimizzazione continua
è supportata solo per i checkpoint del modello distillato in precedenza, con lo stesso modello
studente di base. I checkpoint del modello ottimizzato con supervisione precedente (anche con lo stesso modello studente di base) non sono supportati.
Di seguito è riportato un esempio di configurazione dell'ottimizzazione continua per un checkpoint del modello distillato in precedenza:
{
"description": "Continuous distillation testing job.",
"preTunedModel": {
"tunedModelName": "projects/YOUR_PROJECT_ID/locations/us-central1/models/PRETUNED_MODEL_ID@1",
"checkpointId": "1",
"baseModel": "gemini-2.5-flash"
},
"tunedModelDisplayName": "flash-distillation-continuous",
"distillationSpec": {
"promptDatasetUri": "gs://your-bucket/path/to/prompt_dataset.jsonl",
"validationDatasetUri": "",
"base_teacher_model": "gemini-3.1-pro-preview",
"hyperParameters": {
"epochCount": "20",
"learningRateMultiplier": 2.0,
"generation_config": {
"candidateCount": 5,
}
}
}
}
Invia il payload utilizzando curl:
curl -X POST \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
https://us-central1-aiplatform.googleapis.com/v1beta1/projects/PROJECT_ID/locations/us-central1/tuningJobs \
-d @request.json
Monitorare il job di distillazione
La risposta all'invio restituirà un nome job contenente il tuo
JOB_ID. Puoi controllare lo stato del job
(state, errori e iperparametri finali) inviando una richiesta GET:
curl -X GET \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
https://us-central1-aiplatform.googleapis.com/v1beta1/projects/PROJECT_ID/locations/us-central1/tuningJobs/JOB_ID
Puoi anche monitorare visivamente l'avanzamento nella console Google Cloud
andando a Agent Platform > Tuning e scegliendo la regione
us-central1.
Per questa release di accesso in anteprima, l'interfaccia utente della console Agent Platform presenta le seguenti limitazioni note:
- Avanzamento del campionamento dell'insegnante: non è presente alcun widget di avanzamento per il processo di campionamento del modello dell'insegnante. Anche se lo stato potrebbe visualizzare "Esecuzione di Preparazione per l'ottimizzazione", il job procede normalmente in background.
- Grafici di ottimizzazione del modello studente: durante la fase di ottimizzazione del modello studente, l'interfaccia utente fornisce grafici per la curva di perdita e i token di testo di addestramento totali.
- Tabella dei checkpoint: l'interfaccia utente mostra una tabella dei checkpoint intermedi e link all'endpoint di previsione di Agent Platform generato per la valutazione. La colonna "Epoca" di questa tabella mostra "0" a causa di un problema noto.
Annulla il job di distillazione
Per annullare un job di distillazione in corso, procedi in uno dei seguenti modi:
Utilizza la console Google Cloud , modificando il seguente URL:
https://console.cloud.google.com/agent-platform/tuning/managed?project=YOUR_PROJECT_ID&vertex_ai_region=us-central1Sostituisci YOUR_PROJECT_ID con l'ID progetto.
Utilizza
curlper inviare una richiesta POST per annullare il job:curl -X POST \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json; charset=utf-8" \ https://us-central1-aiplatform.googleapis.com/v1beta1/projects/YOUR_PROJECT_ID/locations/us-central1/tuningJobs/YOUR_JOB_ID:cancelSostituisci quanto segue:
YOUR_PROJECT_IDcon l'ID progetto.YOUR_JOB_IDcon l'ID job.
Valutazione del risultato
Al termine del job di distillazione, il nuovo modello studente viene registrato automaticamente in Gemini Enterprise Agent Platform Model Registry e vengono creati uno o più endpoint dedicati per erogare previsioni. Per valutare il risultato, individua l'endpoint, invia una richiesta di previsione e infine valuta.
Per valutare il risultato:
Invia la seguente richiesta GET per visualizzare lo stato del job di ottimizzazione.
curl -X GET \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json; charset=utf-8" \ https://us-central1-aiplatform.googleapis.com/v1beta1/projects/YOUR_PROJECT_ID/locations/us-central1/tuningJobs/YOUR_JOB_IDSostituisci quanto segue:
YOUR_PROJECT_IDcon l'ID progetto.YOUR_JOB_IDcon l'ID job.
I job completati mostrano un campo
endpointnidificato all'interno dell'oggettotunedModel. EstraiENDPOINT_IDdalla fine della stringa del percorso restituita (ad esempio,projects/.../endpoints/YOUR_ENDPOINT_ID). Prendi nota dell'ID endpoint.Assicurati che il job di ottimizzazione sia stato completato correttamente, perché l'endpoint non è disponibile mentre il job di ottimizzazione è ancora in esecuzione o non è riuscito. Se il campo
endpointnon è presente, esegui il debug del job di ottimizzazione visualizzando le chiavistateoerrordel job.Crea una richiesta di payload JSON denominata
generate_content_request.jsonche contenga il prompt:{ "contents": { "role": "user", "parts": [ { "text": "hi, say something" } ] } }Utilizza il seguente esempio di POST per inviare una richiesta di previsione:
curl -X POST \ -H "Content-Type: application/json" \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ https://us-central1-aiplatform.googleapis.com/v1beta1/projects/YOUR_PROJECT_ID/locations/us-central1/endpoints/YOUR_ENDPOINT_ID:generateContent \ -d @generate_content_request.jsonSostituisci quanto segue:
YOUR_PROJECT_ID: il tuo ID progetto.YOUR_JOB_ID: il tuo ID job.ENDPOINT_ID: il tuo ID endpoint.
Per valutare i risultati:
Esegui un test set holdout, utilizzando prompt non inclusi nei dati di addestramento, sul modello appena distillato.
Confronta gli output con il modello
gemini-2.5-flashdi base per misurare i miglioramenti della qualità.Confronta gli output con il modello
gemini-3.1-proper determinare quanto lo studente si avvicina al ragionamento dell'insegnante.
Limitazioni
La tabella seguente descrive le limitazioni per la distillazione:
La distillazione è soggetta alle seguenti limitazioni:
- Limitazioni del modello:
- Vedi i modelli supportati
- Limitazioni del set di dati:
- Limiti di volume:
- La capacità massima del set di addestramento è di 50.000 esempi.
- Le dimensioni del file JSONL di origine non devono superare 1 GB.
- Specifiche della finestra contestuale:
- Il servizio può ospitare un massimo di 8000 token di input per voce. I job di distillazione vengono terminati se più del 10% delle voci fornite supera questa soglia stabilita.
- Il campionamento del modello insegnante è limitato a un output massimo di 24.000 token. Nei casi in cui il modello dell'insegnante genera più di 24.000 token, i contenuti vengono troncati a questo limite, il che potrebbe influire sul rendimento del modello dello studente.
- Modalità: limitata ai dati basati su testo. Non è previsto il supporto per input multimodali, tra cui video, immagini o chiamate di funzioni.
- Limiti di volume:
- Limitazioni di configurazione e iperparametri
- Rispetta i seguenti limiti quando definisci distillationSpec
e i relativi parametri:
- Crittografia: CMEK non è disponibile per le attività di distillazione che coinvolgono i modelli proprietari di Google.
epochCount: limitato a un valore intero compreso tra 1 e 100.learningRateMultiplier: i valori devono rientrare nell'intervallo in virgola mobile di0.25-4.0.
- Rispetta i seguenti limiti quando definisci distillationSpec
e i relativi parametri:
- Distillazione in un solo passaggio: il campionamento del modello insegnante e l'ottimizzazione del modello studente vengono eseguiti in una singola chiamata API. Se hai una grande quantità di dati da campionare, gli stessi dati devono essere campionati di nuovo nella seguente ottimizzazione.
Ottenere l'accesso
Se ti interessa sperimentare Gemini Distillation Service, contatta il nostro team del servizio di ottimizzazione all'indirizzo cloud-ai-tuning-service-support@google.com per richiedere l'accesso e l'inserimento del progetto nella lista consentita.
Per garantire prestazioni e gestione delle risorse ottimali, ti consigliamo di creare un progetto Google Cloud dedicato per le attività di distillazione. Quando contatti il nostro team, fornisci l'ID progetto o il numero di progetto per accelerare la procedura di inserimento nella lista consentita.
Quote e policy di accesso
Sono in vigore le seguenti quote e norme di accesso:
Capacità: i progetti aggiunti di recente alla nostra lista consentita vengono sottoposti al provisioning con una quota simultanea predefinita di 4. Per evitare la contesa delle risorse, consigliamo di utilizzare un progetto separato anziché uno in cui sono già in esecuzione altri job di ottimizzazione di Gemini.
Periodo di accesso: l'accesso viene concesso per un periodo iniziale di 30 giorni.