

プロビジョンド スループット(PT)は、Gemini Enterprise Agent Platform のスループットを予約する、固定料金の定期サブスクリプションです。このサブスクリプションは、複数の契約期間で利用できます。 スループットを予約するには、モデルと、モデルが実行される利用可能な ロケーションを指定する必要があります。
このページでは、プロビジョンド スループットの仕組み、超過料金を管理する方法、プロビジョンド スループットをバイパスする方法、使用状況をモニタリングする方法について説明します。
プロビジョンド スループットの使用が適切なケース
ユースケースで次のいずれかの事項が該当する場合は、プロビジョニングされたスループットの使用を検討してください。
- 重要なワークロードで常に高いスループットが求められる。スループットの測定はモデルによって異なります。
- アプリのユーザーに、一貫性があり予測可能なエクスペリエンスを提供したい。
- 月額または週単位の固定料金で生成 AI の費用を管理し、超過料金を制御したい。
プロビジョンド スループットは、Gemini Enterprise Agent Platform の複数の使用オプションの 1 つです。すべての使用オプションについては、使用 オプションをご覧ください。
プロビジョンド スループットの仕組み
このセクションでは、割り当ての適用期間中の割り当てチェックを使用して、プロビジョンド スループットの仕組みについて説明します。
プロビジョンド スループットの割り当ての確認
プロビジョンド スループットの最大割り当ては、購入した生成 AI スケール ユニット(GSU)の数と GSU あたりのスループットの倍数です。これは、 割り当て適用期間内にリクエストを送信するたびに確認されます。割り当て適用期間は、最大プロビジョンドスループット 割り当てが適用される頻度です。
リクエストを受信した時点では、実際のレスポンス サイズは不明です。リアルタイム アプリケーションではレスポンスの速度が優先されるため、プロビジョンド スループットは出力トークンサイズを推定します。初期見積もりが、利用可能なプロビジョンド スループットの最大割り当てを超えると、リクエストは従量課金制として処理されます。それ以外の場合は、プロビジョンド スループットとして処理されます。これは、初期見積もりとプロビジョンド スループットの最大割り当てを比較することで行われます。
レスポンスが生成され、実際の出力トークンサイズがわかると、推定値と実際の使用量の差が、使用可能なプロビジョンド スループットの割り当て量に追加され、実際の使用量と割り当てが調整されます。
プロビジョンド スループットの割り当て適用期間
Gemini Enterprise Agent Platform は、Gemini モデルのプロビジョンド スループットの割り当てを適用する際に、動的ウィンドウを適用します。これにより、スパイクが発生しやすいトラフィックの安定性が最適化されます。Agent Platform は、固定ウィンドウではなく、モデルタイプとプロビジョニングした GSU の数に応じて自動的に調整される柔軟なウィンドウで割り当てを適用します。そのため、場合によっては、1 秒あたりの割り当て量を超える優先トラフィックが一時的に発生する可能性があります。ただし、ウィンドウ期間を超えて割り当てを超えることはできません。これらの期間は Agent Platform の内部クロック時間に基づいており、リクエストが行われた時間とは関係ありません。
割り当て適用期間の仕組み
適用期間は、スロットリングされる前に、1 秒あたりの上限を超えることができる量(バースト)を決定します。このウィンドウは自動的に適用されます。これらのウィンドウは、パフォーマンスと信頼性を最適化するために変更される場合があります。
小規模な GSU 割り当て (3 GSU 以下): ウィンドウの範囲は 40 ~ 120 秒で、個々のリクエストを中断することなく処理できます。
たとえば、1 GSU の
gemini-2.5-flashを購入すると、1 秒あたり平均 2,690 トークンの継続的なスループットが得られます。120 秒間のウィンドウでの合計使用量は、322,800 トークン(1 秒あたり 2,690 トークン * 120 秒)を超えることはできません。したがって、1 秒あたり 70,000 トークンを使用するリクエストを送信しても、120 秒間の合計使用量が 322,800 トークン未満であれば、1 秒あたり 70,000 トークンのバーストはプロビジョンド スループットとしてカウントされます。これは、平均使用量が 1 秒あたり 2,690 トークンを超えないためです。標準(中規模)の GSU 割り当て (3 GSU 超): 中規模の GSU デプロイ(50 GSU 未満など)の場合、ウィンドウの範囲は 5 秒~ 30 秒です。GSU のしきい値とコンテキスト ウィンドウはモデルによって異なります。
たとえば、25 GSU の
gemini-2.5-flashを購入すると、1 秒あたり平均 67,250 トークン(1 秒あたり 2,690 トークン * 25)の継続的なスループットが得られます。30 秒間のウィンドウでの合計使用量は、2,017,500 トークン(1 秒あたり 67,250 トークン * 30 秒)を超えることはできません。したがって、1 秒あたり 1,000,000 トークンを使用するリクエストを送信しても、30 秒間の合計使用量が 2,017,500 トークン以内であれば、1 秒あたり 1,000,000 トークンのバーストはプロビジョンド スループットとしてカウントされます。これは、平均使用量が 1 秒あたり 67,250 トークンを超えないためです。高精度(大規模)の GSU 割り当て: 大規模な GSU デプロイ(50 GSU 以上など)の場合、ウィンドウの範囲は 1 ~ 5 秒で、インフラストラクチャ全体で高頻度のリクエストが最大限の 精度で処理されるようにします。
たとえば、250 GSU の
gemini-2.5-flashを購入すると、1 秒あたり平均 672,500 トークン(1 秒あたり 2,690 トークン * 250)の継続的なスループットが得られます。5 秒間のウィンドウでの合計使用量は、3,362,500 トークン(1 秒あたり 672,500 トークン * 5 秒)を超えることはできません。したがって、1 秒あたり 5,000,000 トークンを使用するリクエストを送信しても、プロビジョンド スループットとして処理されません。これは、5 秒間のウィンドウで 5,000,000 トークンの合計使用量が 3,362,500 トークンの上限を超えるためです。一方、1 秒あたり 1,000,000 トークンを使用するリクエストは、5 秒間のウィンドウでの平均使用量が 1 秒あたり 672,500 トークンを超えない場合、プロビジョンド スループットとして処理できます。
過剰な使用を制御するか、プロビジョンド スループットをバイパスする
購入したスループットを超過した場合の超過料金を管理するか、リクエストごとにプロビジョンド スループットをバイパスするには、API を使用します。
各オプションを確認して、ユースケースに何が必要かを判断してください。
デフォルトの動作
リクエストが残りのプロビジョンド スループットの割り当てを超えると、デフォルトではリクエスト全体が オンデマンド リクエストとして処理され、従量課金制 のレートで請求されます。この場合、トラフィックはモニタリング ダッシュボードにスピルオーバー として表示されます。プロビジョンド スループットの使用量のモニタリングの詳細については、プロビジョンド スループットをモニタリングするをご覧ください。
プロビジョンド スループットの注文が有効になると、デフォルトの動作が自動的に適用されます。プロビジョニングされたリージョンで注文を使用している限り、コードを変更する必要はありません。
プロビジョンド スループットのみを使用する
オンデマンド料金を回避して費用を管理する場合は、プロビジョンド スループットのみを使用します。
プロビジョンドスループットの注文量を超えるリクエストは、429 エラーを返します。
API にリクエストを送信するときは、X-Vertex-AI-LLM-Request-Type HTTP ヘッダーを dedicated
に設定します。
従量課金制のみを使用する
これは、オンデマンドを使用する場合にも該当します。リクエストは、プロビジョンド スループットの注文をバイパスして、従量課金制に直接送信されます。これは、テストや開発中のアプリケーションに役立ちます。
API にリクエストを送信するときは、X-Vertex-AI-LLM-Request-Type HTTP ヘッダーを shared
に設定します。
例
Python
インストール
pip install --upgrade google-genai
詳しくは、SDK リファレンス ドキュメントをご覧ください。
Vertex AI で Gen AI SDK を使用するための環境変数を設定します。
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
Go
Go をインストールまたは更新する方法について学びます。
詳しくは、SDK リファレンス ドキュメントをご覧ください。
Vertex AI で Gen AI SDK を使用するための環境変数を設定します。
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
Node.js
インストール
npm install @google/genai
詳しくは、SDK リファレンス ドキュメントをご覧ください。
Vertex AI で Gen AI SDK を使用するための環境変数を設定します。
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
Java
Java をインストールまたは更新します。
詳しくは、SDK リファレンス ドキュメントをご覧ください。
Vertex AI で Gen AI SDK を使用するための環境変数を設定します。
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
REST
環境をセットアップしたら、REST を使用してテキスト プロンプトをテストできます。次のサンプルは、パブリッシャー モデルのエンドポイントにリクエストを送信します。
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
-H "X-Vertex-AI-LLM-Request-Type: dedicated" \ # Options: dedicated, shared
$URL \
-d '{"contents": [{"role": "user", "parts": [{"text": "Hello."}]}]}'
API キーでプロビジョンド スループットを使用する
特定のプロジェクト、Google モデル、リージョンに対してプロビジョンド スループットを購入し、それを使用して API キーでリクエストを送信する場合は、リクエストのパラメータとしてプロジェクト ID、モデル、ロケーション、API キーを含める必要があります。
サービス アカウントにバインドされた Google Cloud API キーの作成方法については、API キーを取得するをご覧ください。 Google Cloud API キーを使用して Gemini API にリクエストを送信する方法については、 Gemini Enterprise Agent Platform の Gemini API API クイックスタートをご覧ください。
たとえば、次のサンプルは、プロビジョンド スループットを使用しながら API キーを使用してリクエストを送信する方法を示しています。
REST
環境をセットアップしたら、REST を使用してテキスト プロンプトをテストできます。次のサンプルは、パブリッシャー モデルのエンドポイントにリクエストを送信します。
curl \
-X POST \
-H "Content-Type: application/json" \
"https://aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/MODEL_ID:generateContent?key=YOUR_API_KEY" \
-d $'{
"contents": [
{
"role": "user",
"parts": [
{
"text": "Explain how AI works in a few words"
}
]
}
]
}'
プロビジョンド スループットをモニタリングする
プロビジョンド スループットの使用状況は、aiplatform.googleapis.com/PublisherModel
リソースタイプで測定される指標のセットを使用して自己モニタリングできます。
プロビジョンド スループットのトラフィック モニタリングは、パブリック プレビュー機能です。
ディメンション
次のディメンションを使用して指標をフィルタリングできます。
| ディメンション | 値 |
|---|---|
type |
inputoutput |
request_type |
|
パスの接頭辞
指標のパスの接頭辞は aiplatform.googleapis.com/publisher/online_serving です。
たとえば、/consumed_throughput 指標のフルパスは aiplatform.googleapis.com/publisher/online_serving/consumed_throughput です。
指標
Gemini モデルの aiplatform.googleapis.com/PublisherModel リソースでは、次の Cloud
Monitoring 指標を使用できます。dedicated リクエスト タイプを使用して、プロビジョンド
スループットの使用状況をフィルタリングします。
| 指標 | 表示名 | 説明 |
|---|---|---|
/dedicated_gsu_limit |
上限(GSU) | 専用の上限(GSU)。この指標を使用して、プロビジョンド スループットの最大割り当て(GSU)を把握します。 |
/tokens |
トークン | 入出力トークン数の分布。 |
/token_count |
トークン数 | 入力トークンと出力トークンの累積数。 |
/consumed_token_throughput |
トークンのスループット | バーンダウン率を考慮したスループット使用量(トークン単位)。割り当ての調整も含まれます。プロビジョンド スループットの割り当ての確認をご覧ください。 この指標を使用して、プロビジョンド スループットの割り当てがどのように使用されたかを把握します。 |
/dedicated_token_limit |
上限(1 秒あたりのトークン数) | 1 秒あたりのトークン数で表される専用の上限。この指標を使用して、トークンベースのモデルのプロビジョンド スループットの最大割り当てを把握します。 |
/characters |
文字数 | 入力と出力の文字数分布。 |
/character_count |
文字数 | 入力と出力の累積文字数。 |
/consumed_throughput |
文字スループット | バーンダウン率を考慮したスループット使用量。割り当ての調整とプロビジョンド スループットの割り当ての確認が組み込まれています。 この指標を使用して、プロビジョンド スループットの割り当てがどのように使用されたかを把握します。 トークンベースのモデルの場合、この指標はトークンで消費されるスループットに 4 を掛けた値に相当します。 |
/dedicated_character_limit |
上限(1 秒あたりの文字数) | 1 秒あたりの文字数で表される専用の上限。この指標を使用して、文字ベースのモデルのプロビジョンド スループットの最大割り当てを確認します。 |
/model_invocation_count |
モデルの呼び出し回数 | モデル呼び出しの数(予測リクエスト)。 |
/model_invocation_latencies |
モデル呼び出しのレイテンシ | モデル呼び出しのレイテンシ(予測レイテンシ)。 |
/first_token_latencies |
最初のトークンのレイテンシ | リクエストを受信してから最初のトークンが返されるまでの時間。 |
Anthropic モデルには、プロビジョンド スループットのフィルタもありますが、tokens と token_count にのみ適用されます。
ダッシュボード
プロビジョンド スループットのデフォルトのモニタリング ダッシュボードには、使用状況とプロビジョンド スループットの使用率をより詳細に把握できる指標が 用意されています。ダッシュボードにアクセスする手順は次のとおりです。
コンソールで、[**プロビジョンド スループット**] ページに移動します。 Google Cloud
注文全体における各モデルのプロビジョンド スループットの使用率を表示するには、[使用率の概要] タブを選択します。
[モデル別のプロビジョンド スループットの使用率] テーブルには、選択した期間の次の情報が表示されます。
お持ちの GSU の合計数。
GSU で表したピーク時のスループット使用量。
GSU の平均使用率。
プロビジョンド スループットの上限に達した回数。
[モデル別のプロビジョンド スループット使用率] テーブルからモデルを選択すると、選択したモデルに固有の指標が表示されます。
モニタリング ダッシュボードの見方
プロビジョンド スループットは、リクエストの作成時にミリ秒単位で利用可能な割り当てをリアルタイムでチェックしますが、このデータは Agent Platform の内部クロック時間に基づいてローリング割り当て適用期間と比較されます。この比較は、リクエストが行われた時間とは関係ありません。モニタリング ダッシュボードには、割り当ての調整後に使用状況指標が報告されます。ただし、これらの指標は、選択した期間に基づいて、ダッシュボードのアライメント期間の平均値を提供するように集計されます。モニタリング ダッシュボードでサポートされている最小粒度は分単位です。また、モニタリング ダッシュボードのクロック時間は Agent Platform のクロック時間とは異なります。
タイミングの違いにより、モニタリング ダッシュボードのデータとリアルタイムのパフォーマンスに差異が生じることがあります。これには、次のいずれかの理由が考えられます。
割り当てはリアルタイムで適用されますが、モニタリング チャートでは、モニタリング ダッシュボードで指定された期間に応じて、データを 1 分以上の平均ダッシュボード アライメント期間に集計します。
Agent Platform とモニタリング ダッシュボードは、異なるシステム クロックで実行されます。
1 秒間に、トラフィックのバーストがプロビジョンド スループット の割り当てを 適用 期間に基づいて超えると、リクエスト全体がスピルオーバー トラフィックとして 処理されます。ただし、その秒のモニタリング データが 1 分のアライメント期間内で平均化されると、アライメント期間全体の平均使用率が 100% を超えないため、プロビジョンド スループットの使用率が低く見えることがあります。スピルオーバー トラフィックが表示された場合は、特定のリクエストが行われた割り当て適用期間中にプロビジョンド スループットの割り当てが完全に使用されたことを確認します。これは、モニタリング ダッシュボードに表示される平均使用率に関係なく行われます。
モニタリング データに差異が生じる可能性の例
この例では、ウィンドウのアライメントのずれによって生じる差異を示します。図 1 は、特定の期間のスループット使用量を表しています。 この図では、次のようになります。
青いバーは、プロビジョンド スループットとして許可されたトラフィックを表します。
オレンジ色のバーは、使用量を GSU の上限を超えてプッシュし、スピルオーバーとして処理されるトラフィックを表します。
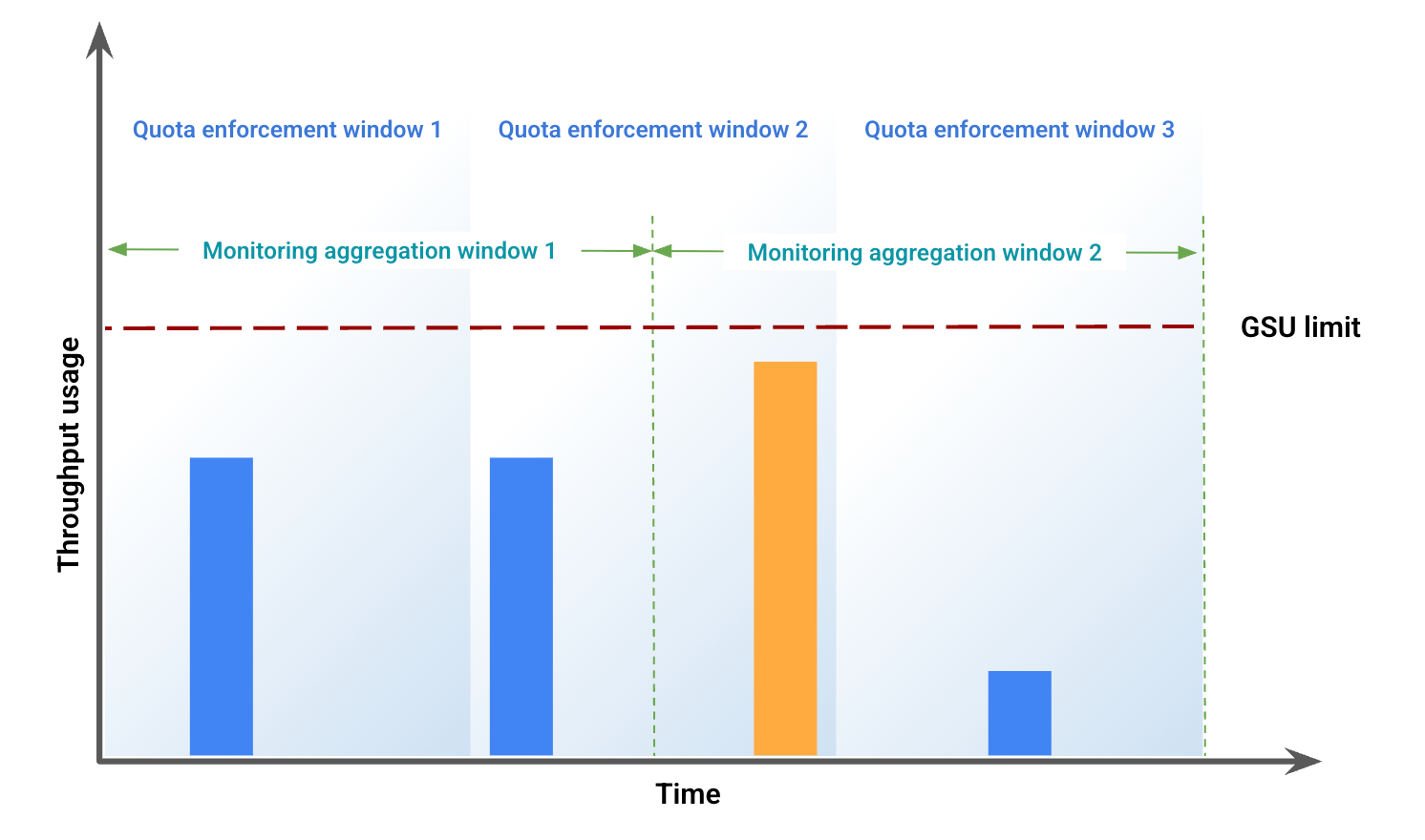
スループットの使用量に基づいて、図 2 は、ウィンドウのアライメントのずれによる視覚的な差異を示しています。この図では、次のようになります。
青い線はプロビジョンド スループット トラフィックを表します。
オレンジ色の線はスピルオーバー トラフィックを表します。
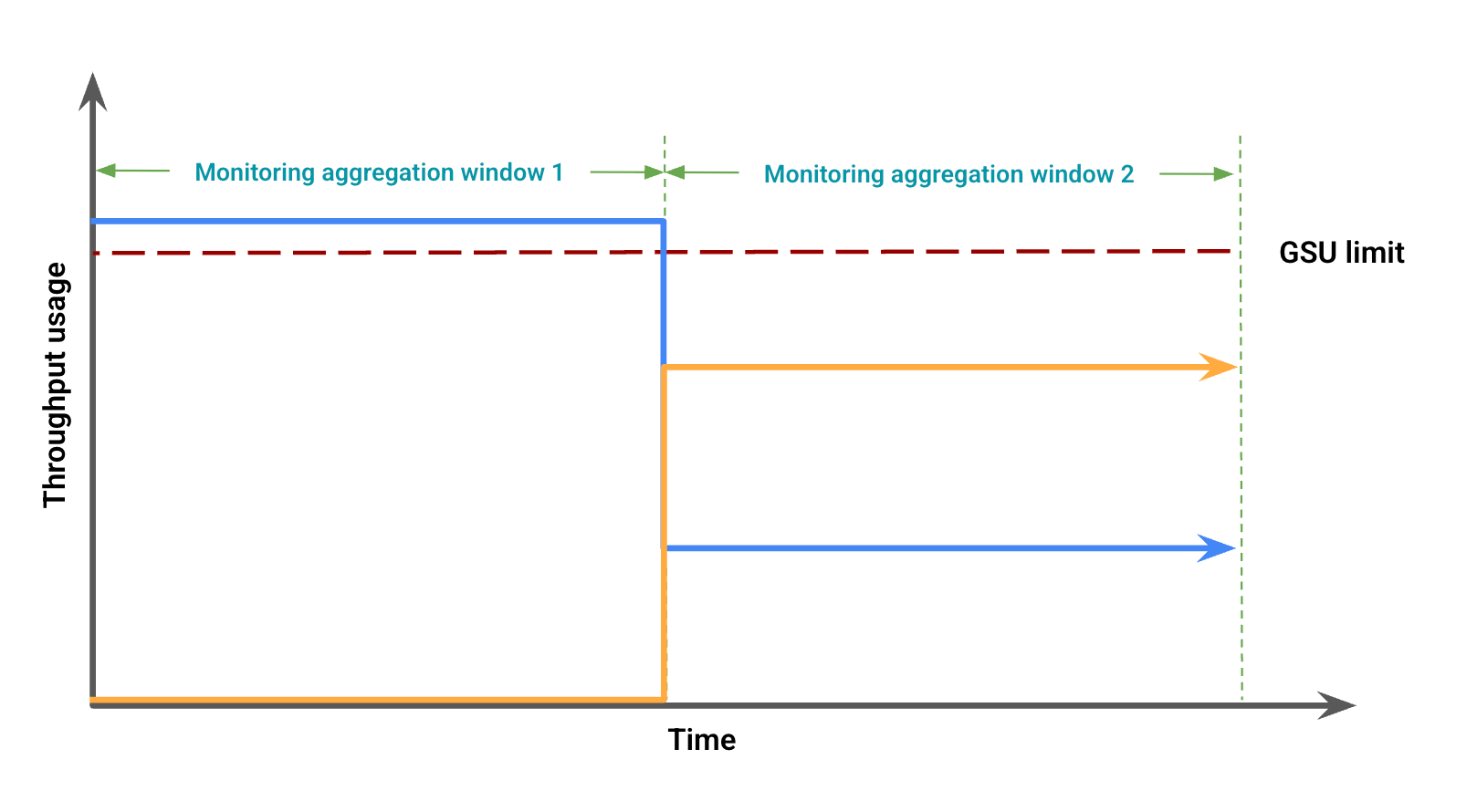
この場合、モニタリング集計期間のプロビジョンド スループットの使用量にスピルオーバーが表示されない一方で、別のモニタリング集計期間のスピルオーバーと一致する GSU の上限を下回るプロビジョンド スループットの使用量が表示されることがあります。
モニタリング ダッシュボードのトラブルシューティング
ダッシュボードで予期しないスピルオーバーや 429 エラーが発生した場合は、次の手順でトラブルシューティングできます。
ズームイン: ダッシュボードの期間を 12 時間以下に設定して、 最も細かいアライメント期間である 1 分にします。期間が長いと、スロットリングの原因となるスパイクが平滑化され、アライメント期間の平均値が増加します。
合計トラフィックを確認する: モデル固有のダッシュボードには、専用トラフィックとスピルオーバー トラフィックが 2 つの別々の線として表示されます。これにより、プロビジョンド スループットの割り当てが完全に使用されておらず、早期にスピルオーバーしているという誤った結論に至る可能性があります。トラフィックが利用可能な割り当てを超えると、リクエスト全体がスピルオーバーとして処理されます。別の便利な可視化方法として、Metrics Explorer を使用してダッシュボードにクエリを追加し、特定のモデルとリージョンのトークン スループットを含めます。追加の集計やフィルタを含めずに、すべてのトラフィック タイプ(専用、スピルオーバー、共有)の合計トラフィックを表示します。
Genmedia モデルをモニタリングする
プロビジョンド スループットのモニタリングは、Veo 3 モデルでは使用できません。
アラート
アラートを有効にしたら、トラフィック使用量の管理に役立つデフォルトのアラートを設定します。
アラートを有効にする
ダッシュボードでアラートを有効にする手順は次のとおりです。
コンソールで、[**プロビジョンド スループット**] ページに移動します。 Google Cloud
注文全体における各モデルのプロビジョンド スループットの使用率を表示するには、[使用率の概要] タブを選択します。
[推奨アラート] を選択すると、次のアラートが表示されます。
Provisioned Throughput Usage Reached LimitProvisioned Throughput Utilization Exceeded 80%Provisioned Throughput Utilization Exceeded 90%
トラフィックの管理に役立つアラートを確認します。
アラートの詳細を表示する
アラートの詳細を表示する手順は次のとおりです。
[インテグレーション] ページに移動します。
[フィルタ] フィールドに「vertex 」と入力し、Enter キーを押します。[Google Gemini Enterprise Agent Platform] が表示されます。
詳細を表示するには、[詳細を表示] をクリックします。[Google Gemini Enterprise Agent Platform の詳細] ペインが表示されます。
[アラート] タブを選択し、[アラート ポリシー] テンプレートを選択します。