
Entender o resultado
O Enterprise Knowledge Graph grava resultados em uma nova tabela do BigQuery para cada job. Esse é um snapshot dos dados no momento em que o job é executado. Por padrão, cada job gera um cluster_id aleatório para cada cluster de entidades. No entanto, se você quiser manter o ID estável entre diferentes execuções de jobs, use a opção avançada previous BigQuery result table.
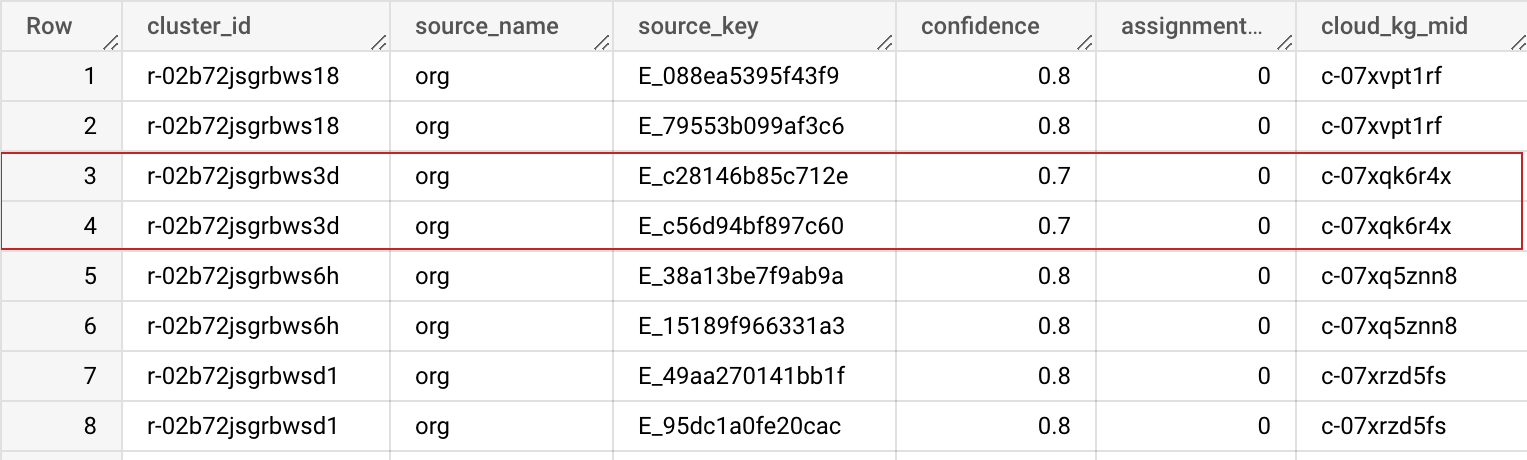
Esquema de saída
| Nome do campo | Tipo | Descrição |
|---|---|---|
| cluster_id | STRING | Esse ID de cluster é um ID de máquina do Mapa de informações (MID, na sigla em inglês) particular atribuído a esse cluster de registros. Ele pode ser usado para identificar o registro de maneira exclusiva no conjunto de dados. Você pode usar a tabela do BigQuery anterior nas opções avançadas para manter esse cluster_id estável e consistente em várias execuções. |
| source_name | STRING | O nome da origem especificado na configuração de entrada para ajudar a unir o conjunto de dados. |
| source_key | STRING | A chave exclusiva na tabela de origem para ajudar a unir o conjunto de dados. |
| confidence | FLOAT | Pontuação de confiança que determina a força com que esses registros pertencem a esse cluster. |
| assignment_age | INTEGER | Usado internamente para estabilização de cluster_id (MID) em diferentes jobs. |
| cloud_kg_mid | STRING | O MID da entidade vinculada do Mapa de informações do Google Cloud. Você pode usar esse MID como seu ID permanente ou pesquisar mais detalhes na API Cloud Knowledge Graph. |
Usar SQL para unir o conjunto de dados
O Enterprise Knowledge Graph gera entidades agrupadas por ID de cluster. A maneira mais simples de visualizar o resultado é usando o ID do cluster para "agrupar por" o resultado. O exemplo a seguir realiza uma verificação rápida de integridade unindo a tabela de saída à tabela original.
# get all entity clusters
SELECT distinct (cluster_id) FROM `ekg-test.<dataset>.clusters_9425187210682344597` order by cluster_id LIMIT 1000;
# join data with original table
SELECT confidence, RS., SRC. FROM `ekg-test.<dataset>.clusters_9425187210682344597` as RS join `ekg-api-test.demo.organization` as SRC
on RS.source_key = SRC.source_key where cluster_id = "r-02b72jsgrbws18";
Esse cluster de entidades representa dois registros diferentes que pertencem ao mesmo cluster. Esse mesmo cluster_id indica que esses dois registros precisam ser unidos e mesclados.

Avalie o sucesso
Par a par
Precisão: proporção de entidades distintas identificadas incorretamente como falsos positivos semelhantes (mais fáceis de detectar por inspeção manual).
Recall: proporção de entidades semelhantes que não são identificadas como falsos negativos ou mais difíceis de detectar.
Medida V do cluster
Medida V do cluster: (1 + beta) * homogeneidade * integridade / (beta * homogeneidade + integridade), em que beta=1.
Homogeneidade do cluster: proporção de clusters que têm entidades pertencentes à mesma entidade.
Integridade do cluster: proporção de clusters em que todas as entidades pertencentes à mesma entidade são colocadas no mesmo cluster.