
Comprendere il risultato
Enterprise Knowledge Graph scrive i risultati in una nuova tabella BigQuery per ogni job. Si tratta di un'istantanea dei dati al momento dell'esecuzione del job. Per impostazione predefinita, ogni job genera un cluster_id casuale per ogni cluster di entità. Tuttavia, se vuoi mantenere stabile l'ID tra diverse esecuzioni del job, utilizza l'opzione avanzata previous BigQuery result table.
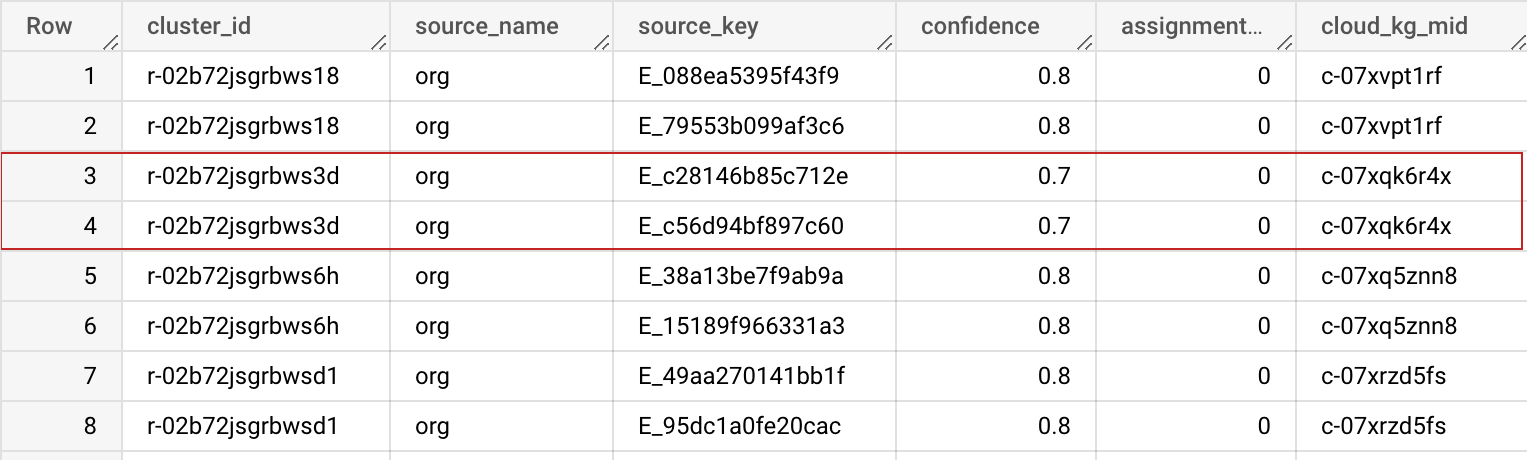
Schema di output
| Nome campo | Tipo | Descrizione |
|---|---|---|
| cluster_id | STRING | Questo ID cluster è un ID macchina (MID) di Knowledge Graph privato assegnato a questo cluster di record. Può essere utilizzato per identificare in modo univoco il record nel set di dati. Puoi utilizzare l'opzione Tabella BigQuery precedente nelle opzioni avanzate per mantenere questo cluster_id stabile e coerente in più esecuzioni. |
| source_name | STRING | Il nome dell'origine specificato nella configurazione di input, per aiutarti a unire i set di dati. |
| source_key | STRING | La chiave univoca nella tabella di origine, per aiutarti a unire i set di dati. |
| confidenza | FLOAT | Punteggio di confidenza che determina la probabilità che questi record appartengano a questo cluster. |
| assignment_age | INTEGER | Utilizzato internamente per la stabilizzazione di cluster_id (MID) in diversi job. |
| cloud_kg_mid | STRING | L'ID macchina dell'entità collegata di Google Cloud Knowledge Graph. Puoi utilizzare questo ID macchina come ID permanente o cercare ulteriori dettagli nell'API Cloud Knowledge Graph. |
Utilizzare SQL per unire il set di dati
Enterprise Knowledge Graph raggruppa le entità in base all'ID cluster. Il modo più semplice per visualizzare il risultato è utilizzare l'ID cluster per raggruppare il risultato. L'esempio seguente esegue un rapido controllo di integrità unendo la tabella di output con la tabella originale.
# get all entity clusters
SELECT distinct (cluster_id) FROM `ekg-test.<dataset>.clusters_9425187210682344597` order by cluster_id LIMIT 1000;
# join data with original table
SELECT confidence, RS., SRC. FROM `ekg-test.<dataset>.clusters_9425187210682344597` as RS join `ekg-api-test.demo.organization` as SRC
on RS.source_key = SRC.source_key where cluster_id = "r-02b72jsgrbws18";
Questo cluster di entità rappresenta due record diversi che appartengono allo stesso cluster. Questo stesso cluster_id indica che questi due record devono essere uniti e combinati.

Misura i risultati
Pair-wise
Precisione: rapporto tra entità distinte identificate erroneamente come falsi positivi simili (più facili da rilevare tramite ispezione manuale).
Identificazione: rapporto tra entità simili che non sono identificate come falsi negativi o più difficili da rilevare.
V-measure del cluster
Misura V del cluster: (1 + beta) * omogeneità * completezza / (beta * omogeneità + completezza), dove beta=1.
Omogeneità del cluster: il rapporto tra i cluster che hanno entità appartenenti alla stessa entità.
Completezza del cluster: il rapporto tra i cluster in cui tutte le entità appartenenti alla stessa entità vengono inserite nello stesso cluster.