
Memahami hasil
Enterprise Knowledge Graph menulis hasil ke dalam tabel BigQuery baru untuk setiap tugas. Ini adalah snapshot data pada saat tugas dijalankan. Secara default, setiap tugas menghasilkan cluster_id acak untuk setiap cluster entity. Namun, jika Anda ingin mempertahankan ID yang stabil di antara berbagai proses tugas, gunakan opsi lanjutan previous BigQuery result table.
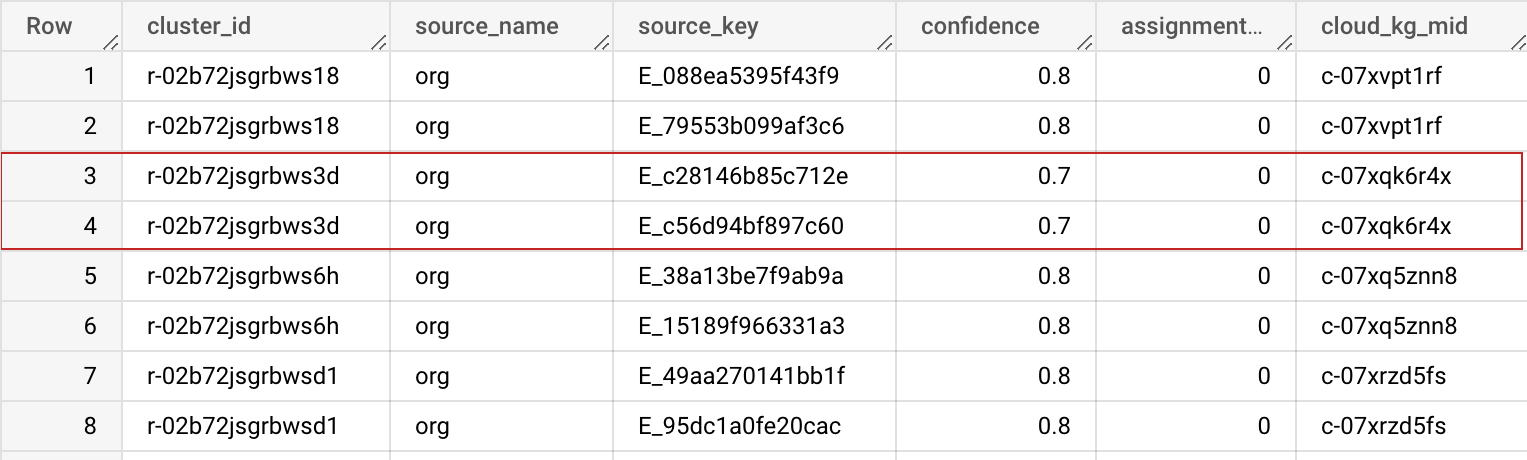
Skema Output
| Nama kolom | Jenis | Deskripsi |
|---|---|---|
| cluster_id | STRING | ID cluster ini adalah ID mesin (MID) pustaka pengetahuan pribadi yang ditetapkan ke cluster data ini. ID ini dapat digunakan untuk mengidentifikasi data secara unik dalam set data Anda. Anda dapat menggunakan Previous BigQuery table di Opsi Lanjutan untuk menjaga cluster_id ini tetap stabil dan konsisten di beberapa proses. |
| source_name | STRING | Nama sumber yang ditentukan dalam konfigurasi input, untuk membantu Anda menggabungkan set data. |
| source_key | STRING | Kunci unik dalam tabel sumber Anda, untuk membantu Anda menggabungkan set data. |
| confidence | FLOAT | Skor keyakinan yang menentukan seberapa kuat data ini termasuk dalam cluster ini. |
| assignment_age | INTEGER | Digunakan secara internal untuk stabilisasi cluster_id (MID) di berbagai tugas. |
| cloud_kg_mid | STRING | MID entity tertaut Google Cloud Knowledge Graph. Anda dapat menggunakan MID ini sebagai ID permanen atau mencari detail tambahan dari Cloud Knowledge Graph API. |
Menggunakan SQL untuk menggabungkan set data
Enterprise Knowledge Graph menampilkan entity yang dikelompokkan berdasarkan ID cluster. Cara paling sederhana untuk melihat hasilnya adalah dengan menggunakan ID cluster untuk "mengelompokkan menurut" hasil Anda. Contoh berikut melakukan pemeriksaan kewarasan cepat dengan menggabungkan tabel output dengan tabel asli.
# get all entity clusters
SELECT distinct (cluster_id) FROM `ekg-test.<dataset>.clusters_9425187210682344597` order by cluster_id LIMIT 1000;
# join data with original table
SELECT confidence, RS., SRC. FROM `ekg-test.<dataset>.clusters_9425187210682344597` as RS join `ekg-api-test.demo.organization` as SRC
on RS.source_key = SRC.source_key where cluster_id = "r-02b72jsgrbws18";
Cluster entity ini mewakili dua data berbeda yang termasuk dalam cluster yang sama. cluster_id yang sama ini menandakan bahwa kedua data ini harus digabungkan.

Mengukur keberhasilan
Berpasangan
Presisi: Rasio entity berbeda yang salah diidentifikasi sebagai positif palsu yang serupa (lebih mudah dideteksi dengan pemeriksaan manual).
Recall: Rasio entity serupa yang tidak diidentifikasi sebagai negatif palsu atau lebih sulit dideteksi.
Cluster V-measure
Cluster V-measure: (1 + beta) * homogeneity * completeness / (beta * homogeneity + completeness) dengan beta=1.
Homogenitas Cluster: Rasio cluster yang memiliki entity yang termasuk dalam entity yang sama.
Kelengkapan Cluster: Rasio cluster tempat semua entity yang termasuk dalam entity yang sama ditempatkan ke dalam cluster yang sama.