
Comprendre le résultat
Enterprise Knowledge Graph écrit les résultats dans une nouvelle table BigQuery pour chaque job. Il s'agit d'un instantané des données au moment de l'exécution du job. Par défaut, chaque job génère un cluster_id aléatoire pour chaque cluster d'entités. Toutefois, si vous souhaitez que l'ID reste stable entre les différentes exécutions de job, utilisez l'option avancée previous BigQuery result table.
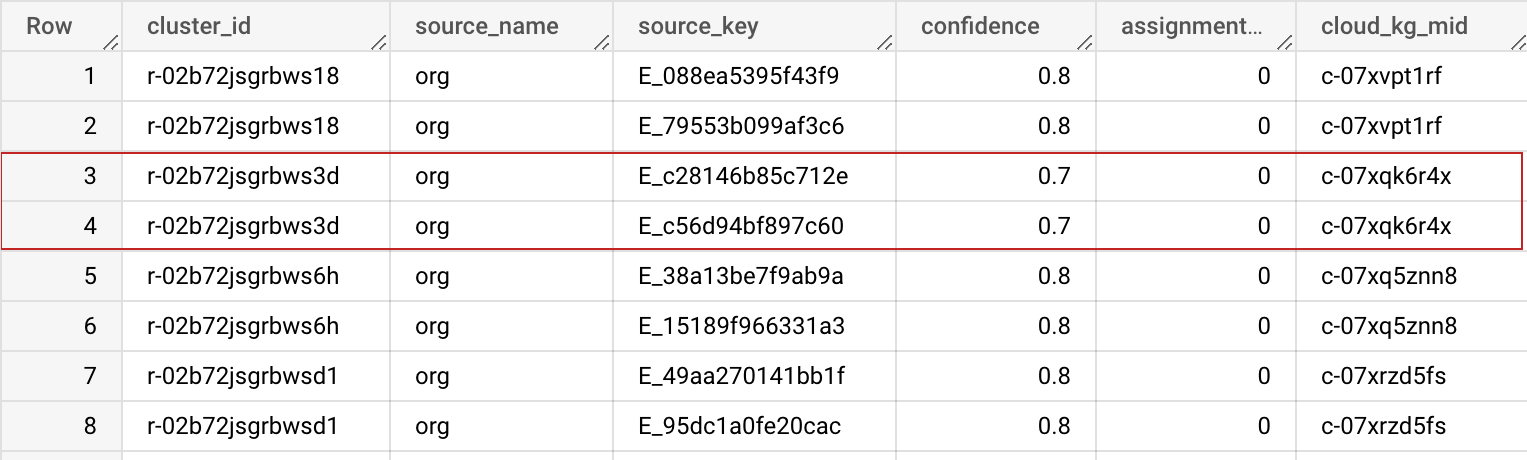
Schéma de sortie
| Nom du champ | Type | Description |
|---|---|---|
| cluster_id | STRING | Cet ID de cluster est un ID machine Knowledge Graph privé (MID) attribué à ce cluster d'enregistrements. Il peut être utilisé pour identifier de manière unique l'enregistrement dans votre ensemble de données. Vous pouvez utiliser la table BigQuery précédente dans les options avancées pour que cette cluster_id reste stable et cohérente sur plusieurs exécutions. |
| source_name | STRING | Nom de la source spécifié dans la configuration d'entrée, pour vous aider à joindre les ensembles de données. |
| source_key | STRING | Clé unique dans votre tableau source, pour vous aider à joindre les ensembles de données. |
| confiance | FLOAT | Score de confiance qui détermine la probabilité que ces enregistrements appartiennent à ce cluster. |
| assignment_age | INTEGER | Utilisé en interne pour la stabilisation de cluster_id (MID) entre différentes tâches. |
| cloud_kg_mid | STRING | MID de l'entité associée Google Cloud Knowledge Graph. Vous pouvez utiliser ce MID comme ID permanent ou rechercher des informations supplémentaires à partir de l'API Cloud Knowledge Graph. |
Utiliser SQL pour joindre l'ensemble de données
Enterprise Knowledge Graph regroupe les entités par ID de cluster. Le moyen le plus simple d'afficher le résultat consiste à utiliser l'ID de cluster comme critère de regroupement de vos résultats. L'exemple suivant effectue une vérification rapide de la cohérence en joignant la table de sortie à la table d'origine.
# get all entity clusters
SELECT distinct (cluster_id) FROM `ekg-test.<dataset>.clusters_9425187210682344597` order by cluster_id LIMIT 1000;
# join data with original table
SELECT confidence, RS., SRC. FROM `ekg-test.<dataset>.clusters_9425187210682344597` as RS join `ekg-api-test.demo.organization` as SRC
on RS.source_key = SRC.source_key where cluster_id = "r-02b72jsgrbws18";
Ce cluster d'entités représente deux enregistrements différents appartenant au même cluster. Le même cluster_id indique que ces deux enregistrements doivent être associés et fusionnés.

Mesurer le succès
Par paires
Précision : rapport entre les entités distinctes identifiées à tort comme des faux positifs similaires (plus facile à détecter par inspection manuelle).
Rappel : ratio d'entités similaires qui ne sont pas identifiées comme faux négatifs ou qui sont plus difficiles à détecter.
Mesure V du cluster
Mesure V du cluster : (1 + bêta) * homogénéité * exhaustivité / (bêta * homogénéité + exhaustivité), où bêta=1.
Homogénéité des clusters : ratio de clusters dont les entités appartiennent à la même entité.
Exhaustivité des clusters : ratio de clusters dans lesquels toutes les entités appartenant à la même entité sont placées dans le même cluster.