
이 빠른 시작에서는 Entity Reconciliation API를 소개합니다. 이 빠른 시작에서는 Google Cloud 콘솔을 사용하여 Google Cloud 프로젝트와 승인을 설정하고 스키마 매핑 파일을 만든 후 Enterprise Knowledge Graph에 항목 조정 작업을 실행하도록 요청합니다.
콘솔에서 이 태스크에 대한 단계별 안내를 직접 수행하려면 Google Cloud 둘러보기를 클릭합니다.
데이터 소스 식별
Entity Reconciliation API는 BigQuery 테이블만 입력으로 지원합니다. 데이터가 BigQuery에 저장되지 않은 경우 커넥터가 더 많이 제공되기 전에 데이터를 BigQuery로 전송하는 것이 좋습니다. 또한 구성한 서비스 계정 또는 OAuth 클라이언트가 사용하려는 테이블에 대한 읽기 액세스 권한과 대상 데이터 세트에 대한 쓰기 권한이 있는지 확인합니다.
스키마 매핑 파일 만들기
각 데이터 소스에 대해 Enterprise Knowledge Graph에 데이터를 수집하는 방법을 알리는 스키마 매핑 파일을 만들어야 합니다.
Enterprise Knowledge Graph는 사람이 읽을 수 있는 간단한 형식 언어인
YARRRML을 사용하여
소스 스키마와 대상 공통 그래프 온톨로지 간의 매핑을 정의합니다.
schema.org.
Enterprise Knowledge Graph는 1:1 간단한 매핑만 지원합니다.
schema.org의 유형에 해당하는 다음 항목 유형이 지원됩니다.
스키마 매핑 파일의 예
조직
prefixes:
ekg: http://cloud.google.com/ekg/0.0.1#
schema: https://schema.org/
mappings:
Organization:
sources:
- [example_project:example_dataset.example_table~bigquery]
s: ekg:company_$(record_id)
po:
- [a, schema:Organization]
- [schema:name, $(company_name_in_source)]
- [schema:streetAddress, $(street)]
- [schema:postalCode, $(postal_code)]
- [schema:addressCountry, $(country)]
- [schema:addressLocality, $(city)]
- [schema:addressRegion, $(state)]
- [ekg:recon.source_name, $(source_system)]
- [ekg:recon.source_key, $(source_key)]
LocalBusiness
prefixes:
ekg: http://cloud.google.com/ekg/0.0.1#
schema: https://schema.org/
mappings:
LocalBusiness:
sources:
- [example_project:example_dataset.example_table~bigquery]
s: ekg:local_business_$(record_id)
po:
- [a, schema:LocalBusiness]
- [schema:name, $(company_name_in_source)]
- [schema:streetAddress, $(street)]
- [schema:postalCode, $(postal_code)]
- [schema:addressCountry, $(country)]
- [schema:addressLocality, $(city)]
- [schema:addressRegion, $(state)]
- [schema:url, $(url)]
- [schema:telephone, $(telephone)]
- [schema:latitude, $(latitude)]
- [schema:longitude, $(longitude)]
- [ekg:recon.source_name, $(source_system)]
- [ekg:recon.source_key, $(source_key)]
사람
prefixes:
ekg: http://cloud.google.com/ekg/0.0.1#
schema: https://schema.org/
mappings:
Person:
sources:
- [example_project:example_dataset.example_table~bigquery]
s: ekg:person_$(record_id)
po:
- [a, schema:Person]
- [schema:postalCode, $(ZIP)]
- [schema:birthDate, $(BIRTHDATE)]
- [schema:name, $(NAME)]
- [schema:gender, $(GENDER)]
- [schema:streetAddress, $(ADDRESS)]
- [ekg:recon.source_name, (Patients)]
- [ekg:recon.source_key, $(source_key)]
소스 문자열 example_project:example_dataset.example_table~bigquery,
~bigquery의 경우 데이터 소스가 BigQuery에서 제공됨을 나타내는 고정 문자열입니다.
술어 목록 (po)에서 ekg:recon.source_name 및 ekg:recon.source_key는 시스템에서 사용하는 예약된 술어 이름이며 항상 매핑 파일에 언급되어야 합니다. 일반적으로 술어 ekg:recon.source_name은 소스에 대한 상수 값을 사용합니다 (이 예에서는 (Patients)). 술어 ekg:recon.source_key는 소스 테이블의 고유 키 (이 예에서는 $(source_key))를 사용하며, 이는 소스 열 ID의 변수 값을 나타냅니다.
매핑 파일에 정의할 테이블 또는 소스가 여러 개 있거나 하나의 API 호출 내에 매핑 파일이 여러 개 있는 경우 여러 소스에서 주제 값이 고유해야 합니다. 프리픽스에 소스 열 키를 더하여 고유하게 만들 수 있습니다. 예를 들어 스키마가 동일한 두 개의 사람 테이블이 있는 경우 주제 (s) 값에
ekg:person1_$(record_id) 및 ekg:person2_$(record_id)와 같은 여러 형식을 할당할 수 있습니다.
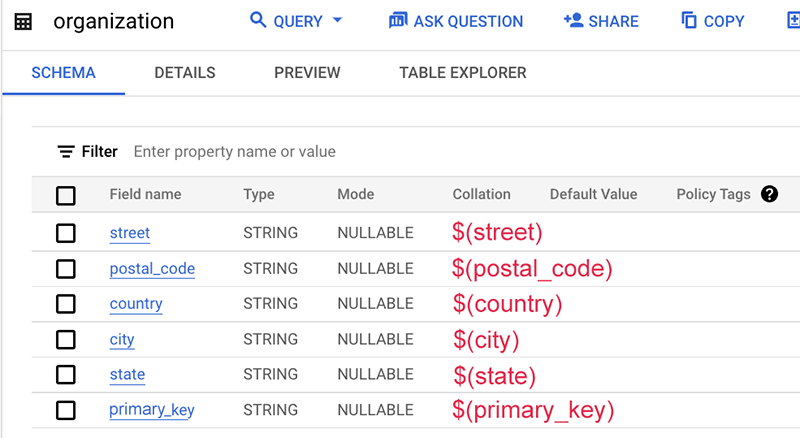
다음은 매핑 파일의 예입니다.
prefixes:
ekg: http://cloud.google.com/ekg/0.0.1#
schema: https://schema.org/
mappings:
organization:
sources:
- [ekg-api-test:demo.organization~bigquery]
s: ekg:company_$(source_key)
po:
- [a, schema:Organization]
- [schema:name, $(source_name)]
- [schema:streetAddress, $(street)]
- [schema:postalCode, $(postal_code)]
- [schema:addressCountry, $(country)]
- [schema:addressLocality, $(city)]
- [schema:addressRegion, $(state)]
- [ekg:recon.source_name, (org)]
- [ekg:recon.source_key, $(primary_key)]
이 예에서 테이블 스키마 자체에는 일반적으로 테이블 이름 또는 데이터베이스 이름인 이 데이터 소스의 이름이 포함되어 있지 않습니다. 따라서 달러 기호 $ 없이 정적 문자열 'org'를 사용합니다.
항목 조정 작업 만들기
콘솔을 사용하여 조정 작업을 만듭니다. Google Cloud
Enterprise Knowledge Graph 대시보드 를 엽니다.
스키마 매핑 을 클릭하여 각 데이터 소스에 대한 템플릿에서 매핑 파일을 만든 후 Cloud Storage에 매핑 파일을 저장합니다.

작업 및 작업 실행 을 클릭하여 작업을 시작하기 전에 작업 매개변수를 구성합니다.
항목 유형
값 모델 이름 설명 Organizationgoogle_brasilOrganization수준에서 항목을 조정합니다. 예를 들어 회사로서의 법인 이름입니다. 이는 여러 회사 캠퍼스 중 하나와 같이 특정 브랜치, 관심 장소 또는 실제 정보에 중점을 두는LocalBusiness와는 다릅니다.LocalBusinessgoogle_cyprus특정 브랜치, 관심 장소 또는 실제 존재를 기반으로 항목을 조정합니다. 지리적 좌표를 모델 입력으로 사용할 수도 있습니다. Persongoogle_atlantisschema.org의 미리 정의된 속성 집합을 기반으로 사람 항목을 조정합니다.데이터 소스
BigQuery 테이블만 지원됩니다.
대상
출력 경로는 Enterprise Knowledge Graph에 쓰기 권한이 있는 BigQuery 데이터 세트여야 합니다.
실행된 각 작업에 대해 Enterprise Knowledge Graph는 타임스탬프가 있는 새 BigQuery 테이블을 만들어 결과를 저장합니다.
Entity Reconciliation API를 사용하는 경우 작업 응답에 전체 출력 테이블 이름과 위치가 포함됩니다.
필요한 경우 고급 옵션 을 구성합니다.
작업을 시작하려면 완료 를 클릭합니다.
작업 상태 모니터링
콘솔과 API 모두에서 작업 상태를 모니터링할 수 있습니다. Google Cloud 데이터 세트의 레코드 수에 따라 작업을 완료하는 데 최대 24시간이 걸릴 수 있습니다. 각 개별 작업을 클릭하여 작업의 세부 구성을 확인합니다.
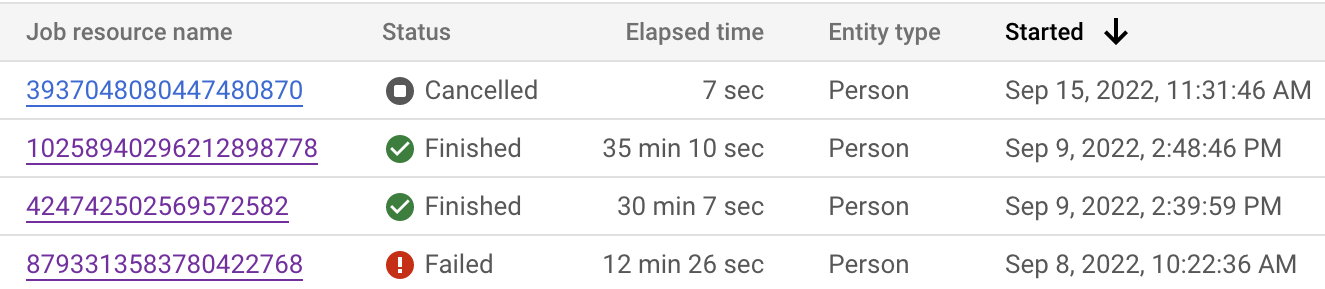
작업 상태를 검사하여 현재 단계가 어디인지 확인할 수도 있습니다.
| 작업 표시 상태 | 코드 상태 | 설명 |
|---|---|---|
| 실행 중 | JOB_STATE_RUNNING |
작업이 진행 중입니다. |
| 지식 추출 | JOB_STATE_KNOWLEDGE_EXTRACTION |
Enterprise Knowledge Graph가 BigQuery에서 데이터를 가져와서 기능을 만들고 있습니다. |
| 조정 전처리 중 | JOB_STATE_RECON_PREPROCESSING |
작업이 조정 전처리 단계에 있습니다. |
| 클러스터링 | JOB_STATE_CLUSTERING |
작업이 클러스터링 단계에 있습니다. |
| 클러스터를 내보내는 중 | JOB_STATE_EXPORTING_CLUSTERS |
작업이 BigQuery 대상 데이터 세트에 출력을 쓰고 있습니다. |
각 작업의 실행 시간은 데이터의 복잡성, 데이터 세트의 크기, 동시에 실행되는 다른 병렬 작업의 수와 같은 여러 요인에 따라 다릅니다. 참고로 작업 실행 시간과 데이터 세트 크기의 대략적인 추정치는 다음과 같습니다. 실제 작업 완료 시간은 다를 수 있습니다.
| 총 레코드 수 | 실행 시간 |
|---|---|
| 10만 | ~2시간 |
| 1억 | ~16시간 |
| 3억 | ~24시간 |
조정 작업 취소
콘솔 (작업 세부정보 페이지)과 API 모두에서 실행 중인 작업을 cancel할 수 있습니다. Enterprise Knowledge Graph는 최선을 다해 가능한 한 빨리 작업을 중지합니다. Google Cloud cancel 명령어의 성공은 보장되지 않습니다.
고급 옵션
| 구성 | 설명 |
|---|---|
| 이전 결과 BigQuery 테이블 | 이전 결과 테이블을 지정하면 여러 작업에서 클러스터 ID가 안정적으로 유지됩니다. 그런 다음 클러스터 ID를 영구 ID로 사용할 수 있습니다. |
| 어피니티 클러스터링 | 대부분의 경우 권장되는 옵션입니다. 계층적 병합형 클러스터링의 병렬 버전이며 확장성이 매우 뛰어납니다. 클러스터링 라운드 (반복) 수는 [1, 5] 범위에서 지정할 수 있습니다. 숫자가 클수록 알고리즘이 클러스터를 과도하게 병합하는 경향이 있습니다.
|
| 연결된 구성요소 클러스터링 | 기본 옵션입니다. 이 옵션은 대체 옵션이자 기존 옵션입니다. 어피니티 클러스터링이 데이터 세트에서 제대로 작동하지 않는 경우에만 이 옵션을 사용해 보세요. 가중치 임곗값은 [0.6, 1] 범위의 숫자일 수 있습니다. |
| 지오코딩 분리 | 이 옵션을 사용하면 서로 다른 지리적 리전의 항목이 함께 클러스터링되지 않습니다. |