
Questa guida rapida offre l'introduzione all'API Entity Reconciliation. In questa guida rapida, utilizzi la console Google Cloud per configurare il progettoGoogle Cloud e l'autorizzazione, creare file di mappatura dello schema e quindi inviare una richiesta a Enterprise Knowledge Graph per eseguire un job di riconciliazione delle entità.
Per seguire le indicazioni dettagliate per questa attività direttamente nella console Google Cloud , fai clic su Procedura guidata:
Identificare l'origine dati
L'API di riconciliazione delle entità supporta solo le tabelle BigQuery come input. Se i tuoi dati non sono archiviati in BigQuery, ti consigliamo di trasferirli in BigQuery prima che diventino disponibili altri connettori. Assicurati inoltre che il account di servizio o il client OAuth che hai configurato disponga dell'accesso in lettura alle tabelle che intendi utilizzare e dell'autorizzazione in scrittura al set di dati di destinazione.
Crea un file di mappatura dello schema
Per ogni origine dati, devi creare un file di mappatura dello schema per comunicare a Enterprise Knowledge Graph come importare i dati.
Enterprise Knowledge Graph utilizza un linguaggio di formato semplice leggibile chiamato
YARRRML per definire i mapping tra
lo schema di origine e le ontologie del grafico comuni,
schema.org.
Enterprise Knowledge Graph supporta solo mappature semplici 1:1.
Sono supportati i seguenti tipi di entità che corrispondono ai tipi in schema.org:
Esempi di file di mappatura dello schema
Organizzazione
prefixes:
ekg: http://cloud.google.com/ekg/0.0.1#
schema: https://schema.org/
mappings:
Organization:
sources:
- [example_project:example_dataset.example_table~bigquery]
s: ekg:company_$(record_id)
po:
- [a, schema:Organization]
- [schema:name, $(company_name_in_source)]
- [schema:streetAddress, $(street)]
- [schema:postalCode, $(postal_code)]
- [schema:addressCountry, $(country)]
- [schema:addressLocality, $(city)]
- [schema:addressRegion, $(state)]
- [ekg:recon.source_name, $(source_system)]
- [ekg:recon.source_key, $(source_key)]
LocalBusiness
prefixes:
ekg: http://cloud.google.com/ekg/0.0.1#
schema: https://schema.org/
mappings:
LocalBusiness:
sources:
- [example_project:example_dataset.example_table~bigquery]
s: ekg:local_business_$(record_id)
po:
- [a, schema:LocalBusiness]
- [schema:name, $(company_name_in_source)]
- [schema:streetAddress, $(street)]
- [schema:postalCode, $(postal_code)]
- [schema:addressCountry, $(country)]
- [schema:addressLocality, $(city)]
- [schema:addressRegion, $(state)]
- [schema:url, $(url)]
- [schema:telephone, $(telephone)]
- [schema:latitude, $(latitude)]
- [schema:longitude, $(longitude)]
- [ekg:recon.source_name, $(source_system)]
- [ekg:recon.source_key, $(source_key)]
Persona
prefixes:
ekg: http://cloud.google.com/ekg/0.0.1#
schema: https://schema.org/
mappings:
Person:
sources:
- [example_project:example_dataset.example_table~bigquery]
s: ekg:person_$(record_id)
po:
- [a, schema:Person]
- [schema:postalCode, $(ZIP)]
- [schema:birthDate, $(BIRTHDATE)]
- [schema:name, $(NAME)]
- [schema:gender, $(GENDER)]
- [schema:streetAddress, $(ADDRESS)]
- [ekg:recon.source_name, (Patients)]
- [ekg:recon.source_key, $(source_key)]
Per la stringa di origine example_project:example_dataset.example_table~bigquery,
~bigquery è la stringa fissa che indica che l'origine dati proviene da BigQuery.
Nell'elenco dei predicati (po), ekg:recon.source_name e ekg:recon.source_key sono
nomi di predicati riservati utilizzati dal sistema e devono sempre essere menzionati nel
file di mapping. Normalmente, il predicato ekg:recon.source_name accetta un valore costante
per l'origine (in questo esempio, (Patients)). Il predicato
ekg:recon.source_key accetta la chiave univoca della tabella di origine (in questo esempio, $(source_key)),
che rappresenta il valore della variabile dell'ID colonna di origine.
Se hai più tabelle o origini da definire nei file di mappatura o
diversi file di mappatura all'interno di una chiamata API, devi assicurarti che il
valore del soggetto sia univoco nelle diverse origini. Puoi utilizzare il prefisso più la chiave della colonna origine per renderlo univoco. Ad esempio, se hai due tabelle di persone con
lo stesso schema, puoi assegnare formati diversi al valore del soggetto (s):
ekg:person1_$(record_id) e ekg:person2_$(record_id).
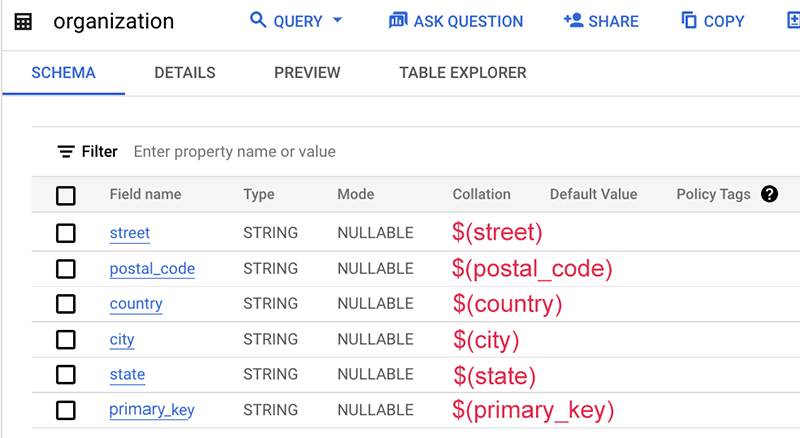
Ecco un esempio del file di mapping:
prefixes:
ekg: http://cloud.google.com/ekg/0.0.1#
schema: https://schema.org/
mappings:
organization:
sources:
- [ekg-api-test:demo.organization~bigquery]
s: ekg:company_$(source_key)
po:
- [a, schema:Organization]
- [schema:name, $(source_name)]
- [schema:streetAddress, $(street)]
- [schema:postalCode, $(postal_code)]
- [schema:addressCountry, $(country)]
- [schema:addressLocality, $(city)]
- [schema:addressRegion, $(state)]
- [ekg:recon.source_name, (org)]
- [ekg:recon.source_key, $(primary_key)]
In questo esempio, lo schema della tabella stesso non contiene il nome di questa origine dati, che in genere è il nome della tabella o del database. Pertanto, utilizziamo la stringa statica "org" senza il simbolo del dollaro $.
Crea un job di riconciliazione delle entità
Utilizza la console Google Cloud per creare un job di riconciliazione.
Apri la dashboard di Enterprise Knowledge Graph.
Fai clic su Mappatura dello schema per creare file di mappatura dal nostro modello per ciascuna delle tue origini dati, quindi salva il file di mappatura in Cloud Storage.

Fai clic su Job e Esegui un job per configurare i parametri del job prima di avviarlo.
Tipo di entità
Valore Nome modello Descrizione Organizationgoogle_brasilRiconcilia le entità a livello di Organization. Ad esempio, il nome di una società. È diverso daLocalBusiness, che si concentra su una particolare filiale, un punto d'interesse o una presenza fisica, ad esempio uno dei tanti campus aziendali.LocalBusinessgoogle_cyprusRiconcilia l'entità in base a una determinata filiale, punto d'interesse o presenza fisica. Potrebbe anche accettare coordinate geografiche come input del modello. Persongoogle_atlantisRiconcilia l'entità persona in base a un insieme di attributi predefiniti in schema.org.Origini dati
Sono supportate solo le tabelle BigQuery.
Destinazione
Il percorso di output deve essere un set di dati BigQuery in cui Enterprise Knowledge Graph ha l'autorizzazione di scrittura.
Per ogni job eseguito, Enterprise Knowledge Graph crea una nuova tabella BigQuery con timestamp per archiviare i risultati.
Se utilizzi l'API Entity Reconciliation, la risposta del job contiene il nome e la posizione completi della tabella di output.
Configura le opzioni avanzate, se necessario.
Per avviare il lavoro, fai clic su Fine.
Monitorare lo stato del job
Puoi monitorare lo stato del job sia dalla console Google Cloud che dall'API. Il completamento del job potrebbe richiedere fino a 24 ore, a seconda del numero di record nei set di dati. Fai clic su ogni singolo job per visualizzarne la configurazione dettagliata.
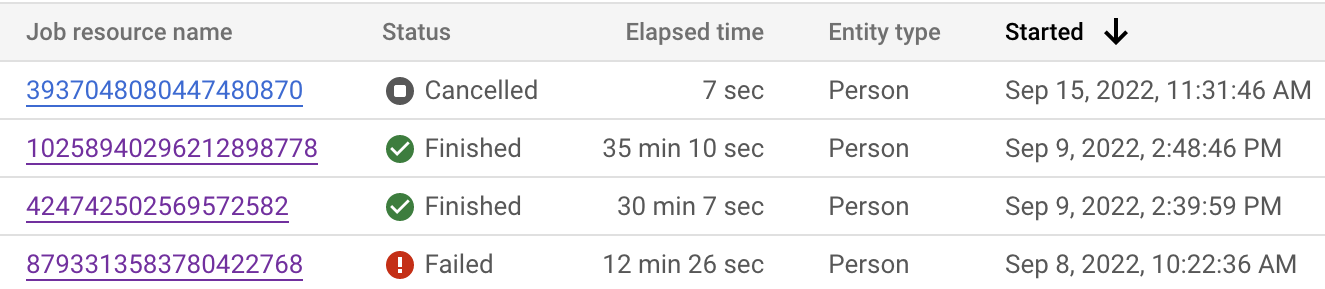
Puoi anche esaminare lo stato del job per vedere a che punto si trova il passaggio corrente.
| Stato di visualizzazione del job | Stato del codice | Descrizione |
|---|---|---|
| In esecuzione | JOB_STATE_RUNNING |
Il job è in corso. |
| Estrazione conoscenze | JOB_STATE_KNOWLEDGE_EXTRACTION |
Enterprise Knowledge Graph estrae i dati da BigQuery e crea funzionalità. |
| Pre-elaborazione riconciliazione | JOB_STATE_RECON_PREPROCESSING |
Il job si trova nella fase di pre-elaborazione della riconciliazione. |
| Clustering | JOB_STATE_CLUSTERING |
Il job si trova nella fase di clustering. |
| Esportazione cluster | JOB_STATE_EXPORTING_CLUSTERS |
Il job sta scrivendo l'output nel set di dati di destinazione BigQuery. |
Il tempo di esecuzione di ogni job varia a seconda di molti fattori, come la complessità dei dati, le dimensioni del set di dati e il numero di altri job paralleli in esecuzione contemporaneamente. Ecco una stima approssimativa del tempo di esecuzione del job rispetto alle dimensioni del set di dati per riferimento. Il tempo effettivo di completamento del job sarà diverso.
| Numero totale di record | Tempo di esecuzione |
|---|---|
| 100.000 | ~2 ore |
| 100 milioni | ~16 ore |
| 300 milioni | ~24 ore |
Annullare un job di riconciliazione
Puoi cancel un job in esecuzione sia dalla console Google Cloud (nella pagina dei dettagli del job) sia dall'API; Enterprise Knowledge Graph interrompe il job alla prima opportunità possibile in base al massimo impegno. L'esito positivo del comando cancel non è garantito.
Opzioni avanzate
| Configurazione | Descrizione |
|---|---|
| Tabella BigQuery risultato precedente | Se specifichi una tabella dei risultati precedenti, l'ID cluster rimane stabile in diversi job. Quindi potresti utilizzare l'ID cluster come ID permanente. |
| Clustering per affinità | Opzione consigliata per la maggior parte dei casi. È una versione parallela del clustering agglomerativo gerarchico e si adatta molto bene. Il numero di cicli di clustering (iterazioni) può essere specificato nell'intervallo [1, 5]. Più elevato è il numero, maggiore è la tendenza dell'algoritmo a unire eccessivamente il cluster.
|
| Clustering dei componenti connessi | Opzione predefinita. Si tratta di un'opzione alternativa e legacy. Provala solo se il clustering di affinità non funziona bene sul tuo set di dati. La soglia di peso può essere un numero compreso nell'intervallo [0.6, 1]. |
| Separazione per geocodifica | Questa opzione garantisce che le entità di regioni geografiche diverse non vengano raggruppate. |