
Panduan memulai ini memperkenalkan Anda pada Entity Reconciliation API. Dalam panduan memulai ini, Anda akan menggunakan konsol Google Cloud untuk menyiapkan project dan otorisasi, membuat file pemetaan skema, lalu membuat permintaan untuk Enterprise Knowledge Graph guna menjalankan tugas rekonsiliasi entitas.Google Cloud
Untuk mengikuti panduan langkah demi langkah untuk tugas ini langsung di Google Cloud konsol, klik Pandu saya:
Mengidentifikasi sumber data Anda
Entity Reconciliation API hanya mendukung tabel BigQuery sebagai input. Jika data Anda tidak disimpan di BigQuery, sebaiknya transfer data Anda ke BigQuery sebelum lebih banyak konektor tersedia. Pastikan juga akun layanan atau klien OAuth yang telah Anda konfigurasi memiliki akses baca ke tabel yang akan Anda gunakan, dan juga izin tulis ke set data tujuan.
Membuat file pemetaan skema
Untuk setiap sumber data, Anda perlu membuat file pemetaan skema untuk memberi tahu Enterprise Knowledge Graph cara menyerap data.
Enterprise Knowledge Graph menggunakan bahasa format sederhana yang mudah dibaca manusia bernama
YARRRML untuk menentukan pemetaan antara
skema sumber dan ontologi grafik umum target,
schema.org.
Enterprise Knowledge Graph hanya mendukung pemetaan sederhana 1:1.
Jenis entitas berikut yang sesuai dengan jenis di schema.org didukung:
Contoh file pemetaan skema
Organisasi
prefixes:
ekg: http://cloud.google.com/ekg/0.0.1#
schema: https://schema.org/
mappings:
Organization:
sources:
- [example_project:example_dataset.example_table~bigquery]
s: ekg:company_$(record_id)
po:
- [a, schema:Organization]
- [schema:name, $(company_name_in_source)]
- [schema:streetAddress, $(street)]
- [schema:postalCode, $(postal_code)]
- [schema:addressCountry, $(country)]
- [schema:addressLocality, $(city)]
- [schema:addressRegion, $(state)]
- [ekg:recon.source_name, $(source_system)]
- [ekg:recon.source_key, $(source_key)]
LocalBusiness
prefixes:
ekg: http://cloud.google.com/ekg/0.0.1#
schema: https://schema.org/
mappings:
LocalBusiness:
sources:
- [example_project:example_dataset.example_table~bigquery]
s: ekg:local_business_$(record_id)
po:
- [a, schema:LocalBusiness]
- [schema:name, $(company_name_in_source)]
- [schema:streetAddress, $(street)]
- [schema:postalCode, $(postal_code)]
- [schema:addressCountry, $(country)]
- [schema:addressLocality, $(city)]
- [schema:addressRegion, $(state)]
- [schema:url, $(url)]
- [schema:telephone, $(telephone)]
- [schema:latitude, $(latitude)]
- [schema:longitude, $(longitude)]
- [ekg:recon.source_name, $(source_system)]
- [ekg:recon.source_key, $(source_key)]
Orang
prefixes:
ekg: http://cloud.google.com/ekg/0.0.1#
schema: https://schema.org/
mappings:
Person:
sources:
- [example_project:example_dataset.example_table~bigquery]
s: ekg:person_$(record_id)
po:
- [a, schema:Person]
- [schema:postalCode, $(ZIP)]
- [schema:birthDate, $(BIRTHDATE)]
- [schema:name, $(NAME)]
- [schema:gender, $(GENDER)]
- [schema:streetAddress, $(ADDRESS)]
- [ekg:recon.source_name, (Patients)]
- [ekg:recon.source_key, $(source_key)]
Untuk string sumber example_project:example_dataset.example_table~bigquery,
~bigquery adalah string tetap yang menunjukkan bahwa sumber data berasal dari BigQuery.
Dalam daftar predikat (po), ekg:recon.source_name dan ekg:recon.source_key adalah
nama predikat khusus yang digunakan oleh sistem dan harus selalu disebutkan dalam
file pemetaan. Biasanya, predikat ekg:recon.source_name mengambil nilai
konstan untuk sumber (dalam contoh ini, (Patients)). Predikat
ekg:recon.source_key mengambil kunci unik dari tabel sumber (dalam contoh ini, $(source_key)),
yang merepresentasikan nilai variabel dari ID kolom sumber).
Jika Anda memiliki beberapa tabel atau sumber yang akan ditentukan dalam file pemetaan atau
file pemetaan yang berbeda dalam satu panggilan API, Anda harus memastikan nilai
subjek unik di berbagai sumber. Anda dapat menggunakan kunci kolom awalan plus sumber untuk membuatnya unik. Misalnya, jika Anda memiliki dua tabel orang dengan
skema yang sama, Anda dapat menetapkan format yang berbeda ke nilai subjek (s):
ekg:person1_$(record_id) dan ekg:person2_$(record_id).
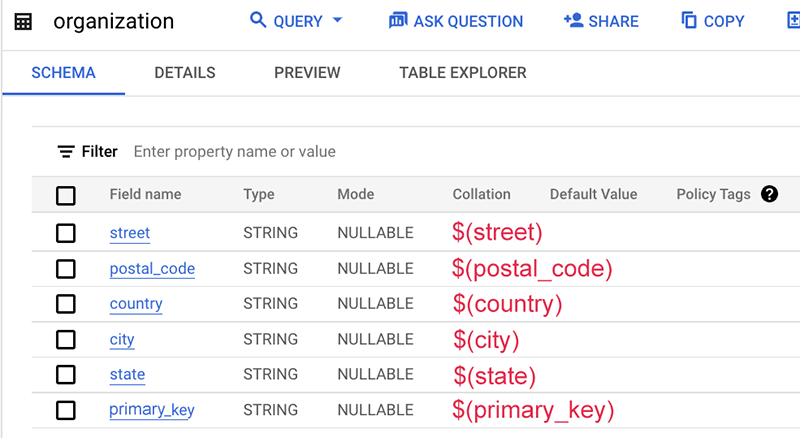
Berikut adalah contoh file pemetaan:
prefixes:
ekg: http://cloud.google.com/ekg/0.0.1#
schema: https://schema.org/
mappings:
organization:
sources:
- [ekg-api-test:demo.organization~bigquery]
s: ekg:company_$(source_key)
po:
- [a, schema:Organization]
- [schema:name, $(source_name)]
- [schema:streetAddress, $(street)]
- [schema:postalCode, $(postal_code)]
- [schema:addressCountry, $(country)]
- [schema:addressLocality, $(city)]
- [schema:addressRegion, $(state)]
- [ekg:recon.source_name, (org)]
- [ekg:recon.source_key, $(primary_key)]
Dalam contoh ini, skema tabel itu sendiri tidak berisi nama sumber data ini, yang biasanya merupakan nama tabel atau nama database. Oleh karena itu, kita menggunakan string statis "org" tanpa tanda dolar $.
Membuat tugas rekonsiliasi entity
Gunakan konsol Google Cloud untuk membuat tugas rekonsiliasi.
Buka dasbor Enterprise Knowledge Graph.
Klik Pemetaan Skema untuk membuat file pemetaan dari template kami untuk setiap sumber data Anda, lalu simpan file pemetaan di Cloud Storage.

Klik Job dan Run A Job untuk mengonfigurasi parameter tugas sebelum memulai tugas.
Jenis entitas
Nilai Nama model Deskripsi Organizationgoogle_brasilMenyelesaikan entity di tingkat Organization. Misalnya, nama perusahaan sebagai perusahaan. Hal ini berbeda denganLocalBusiness, yang berfokus pada cabang tertentu, tempat menarik, atau kehadiran fisik, misalnya, salah satu dari banyak kampus perusahaan.LocalBusinessgoogle_cyprusMencocokkan entitas berdasarkan cabang, tempat menarik, atau kehadiran fisik tertentu. Model ini juga dapat menerima koordinat geografis sebagai input model. Persongoogle_atlantisMencocokkan entity orang berdasarkan serangkaian atribut yang telah ditentukan sebelumnya di schema.org.Sumber data
Hanya tabel BigQuery yang didukung.
Tujuan
Jalur output harus berupa set data BigQuery, tempat Enterprise Knowledge Graph memiliki izin untuk menulis.
Untuk setiap tugas yang dijalankan, Enterprise Knowledge Graph membuat tabel BigQuery baru dengan stempel waktu untuk menyimpan hasilnya.
Jika Anda menggunakan Entity Reconciliation API, respons tugas berisi nama dan lokasi tabel output lengkap.
Konfigurasi Opsi Lanjutan jika diperlukan.
Untuk memulai tugas, klik Selesai.
Memantau status tugas
Anda dapat memantau status tugas dari Google Cloud konsol dan API. Pekerjaan ini mungkin memerlukan waktu hingga 24 jam untuk diselesaikan, bergantung pada jumlah data dalam set data Anda. Klik setiap tugas satu per satu untuk melihat konfigurasi mendetail tugas.
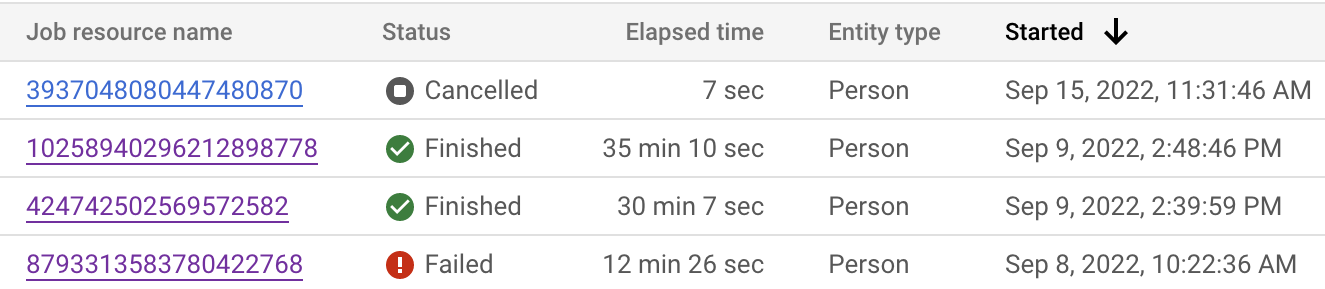
Anda juga dapat memeriksa status tugas untuk melihat langkah saat ini.
| Status tampilan tugas | Status kode | Deskripsi |
|---|---|---|
| Berjalan | JOB_STATE_RUNNING |
Tugas sedang dalam proses. |
| Ekstraksi pengetahuan | JOB_STATE_KNOWLEDGE_EXTRACTION |
Enterprise Knowledge Graph menarik data dari BigQuery dan membuat fitur. |
| Pra-pemrosesan rekonsiliasi | JOB_STATE_RECON_PREPROCESSING |
Tugas berada di langkah pra-pemrosesan rekonsiliasi. |
| Clustering | JOB_STATE_CLUSTERING |
Tugas berada pada langkah pengelompokan. |
| Mengekspor cluster | JOB_STATE_EXPORTING_CLUSTERS |
Tugas sedang menulis output ke set data tujuan BigQuery. |
Waktu proses untuk setiap tugas bervariasi bergantung pada banyak faktor, seperti kompleksitas data, ukuran set data, dan jumlah tugas paralel lain yang berjalan pada saat yang sama. Berikut estimasi kasar waktu eksekusi tugas vs. ukuran set data untuk referensi Anda. Waktu penyelesaian tugas sebenarnya akan berbeda.
| Jumlah total data | Waktu eksekusi |
|---|---|
| 100.000 | ~2 jam |
| 100 JT | ~16 jam |
| 300 JT | ~24 jam |
Membatalkan tugas rekonsiliasi
Anda dapat cancel tugas yang sedang berjalan dari konsol Google Cloud (di halaman detail tugas) dan API; Enterprise Knowledge Graph akan menghentikan tugas sesegera mungkin berdasarkan upaya terbaik. Keberhasilan perintah cancel tidak dijamin.
Opsi lanjutan
| Konfigurasi | Deskripsi |
|---|---|
| Tabel BigQuery hasil sebelumnya | Menentukan tabel hasil sebelumnya membuat ID cluster tetap stabil di berbagai tugas. Kemudian, Anda dapat menggunakan ID cluster sebagai ID permanen Anda. |
| Pengelompokan minat | Opsi yang direkomendasikan untuk sebagian besar kasus. Ini adalah versi paralel dari pengelompokan aglomeratif hierarkis dan menskalakan dengan sangat baik. Jumlah putaran pengelompokan (iterasi) dapat ditentukan dalam rentang [1, 5]. Makin tinggi angkanya, makin cenderung algoritma menggabungkan cluster secara berlebihan.
|
| Pengelompokan komponen yang terhubung | Opsi default. Ini adalah opsi alternatif dan lama; coba opsi ini hanya jika pengelompokan afinitas tidak berfungsi dengan baik pada set data Anda. Nilai minimum bobot dapat berupa angka dalam rentang [0.6, 1]. |
| Pemisahan geocoding | Opsi ini memastikan bahwa entitas dari wilayah geografis yang berbeda tidak dikelompokkan bersama. |