
במדריך למתחילים הזה נסביר איך משתמשים ב-Entity Reconciliation API. במדריך למתחילים הזה נשתמש במסוף Google Cloud כדי להגדיר את הפרויקט ואת ההרשאה, ליצור קובצי מיפוי סכמה, ואז לשלוח בקשה ל-Enterprise Knowledge Graph כדי להריץ משימת התאמת ישויות.Google Cloud
לחצו על תראו לי איך כדי לקרוא הסבר מפורט על המשימה ישירות במסוף Google Cloud :
זיהוי מקור הנתונים
ממשק Entity Reconciliation API תומך רק בטבלאות BigQuery כקלט. אם הנתונים שלכם לא מאוחסנים ב-BigQuery, מומלץ להעביר אותם ל-BigQuery לפני שיהיו זמינים מחברים נוספים. בנוסף, צריך לוודא שלחשבון השירות או ללקוח OAuth שהגדרתם יש גישת קריאה לטבלאות שבהן אתם מתכננים להשתמש, וגם הרשאת כתיבה למערך נתוני היעד.
יצירת קובץ מיפוי סכימה
לכל אחד ממקורות הנתונים צריך ליצור קובץ מיפוי סכימה כדי להודיע ל-Enterprise Knowledge Graph איך להטמיע את הנתונים.
ב-Enterprise Knowledge Graph נעשה שימוש בשפה פשוטה בפורמט קריא לאדם שנקראת YARRRML כדי להגדיר את המיפויים בין סכימת המקור לבין אונטולוגיות של גרפים משותפים של היעד, schema.org.
Enterprise Knowledge Graph תומך רק במיפויים פשוטים של יחסים של אחד לאחד.
נתמכים סוגי הישויות הבאים שתואמים לסוגים ב-schema.org:
קבצים של מיפוי סכימה לדוגמה
ארגון
prefixes:
ekg: http://cloud.google.com/ekg/0.0.1#
schema: https://schema.org/
mappings:
Organization:
sources:
- [example_project:example_dataset.example_table~bigquery]
s: ekg:company_$(record_id)
po:
- [a, schema:Organization]
- [schema:name, $(company_name_in_source)]
- [schema:streetAddress, $(street)]
- [schema:postalCode, $(postal_code)]
- [schema:addressCountry, $(country)]
- [schema:addressLocality, $(city)]
- [schema:addressRegion, $(state)]
- [ekg:recon.source_name, $(source_system)]
- [ekg:recon.source_key, $(source_key)]
LocalBusiness
prefixes:
ekg: http://cloud.google.com/ekg/0.0.1#
schema: https://schema.org/
mappings:
LocalBusiness:
sources:
- [example_project:example_dataset.example_table~bigquery]
s: ekg:local_business_$(record_id)
po:
- [a, schema:LocalBusiness]
- [schema:name, $(company_name_in_source)]
- [schema:streetAddress, $(street)]
- [schema:postalCode, $(postal_code)]
- [schema:addressCountry, $(country)]
- [schema:addressLocality, $(city)]
- [schema:addressRegion, $(state)]
- [schema:url, $(url)]
- [schema:telephone, $(telephone)]
- [schema:latitude, $(latitude)]
- [schema:longitude, $(longitude)]
- [ekg:recon.source_name, $(source_system)]
- [ekg:recon.source_key, $(source_key)]
אדם
prefixes:
ekg: http://cloud.google.com/ekg/0.0.1#
schema: https://schema.org/
mappings:
Person:
sources:
- [example_project:example_dataset.example_table~bigquery]
s: ekg:person_$(record_id)
po:
- [a, schema:Person]
- [schema:postalCode, $(ZIP)]
- [schema:birthDate, $(BIRTHDATE)]
- [schema:name, $(NAME)]
- [schema:gender, $(GENDER)]
- [schema:streetAddress, $(ADDRESS)]
- [ekg:recon.source_name, (Patients)]
- [ekg:recon.source_key, $(source_key)]
במחרוזת המקור example_project:example_dataset.example_table~bigquery, ~bigquery היא המחרוזת הקבועה שמציינת שמקור הנתונים הוא BigQuery.
ברשימת התנאים (po), התנאים ekg:recon.source_name ו-ekg:recon.source_key הם שמות תנאים שמורים שמשמשים את המערכת, ותמיד צריך לציין אותם בקובץ המיפוי. בדרך כלל, הפרדיקט ekg:recon.source_name מקבל ערך קבוע למקור (בדוגמה הזו, (Patients)). הפרדיקט ekg:recon.source_key מקבל את המפתח הייחודי מטבלת המקור (בדוגמה הזו, $(source_key)), שמייצג את ערך המשתנה ממזהה עמודת המקור).
אם יש לכם כמה טבלאות או מקורות שצריך להגדיר בקובצי המיפוי או קובצי מיפוי שונים בקריאה ל-API אחת, אתם צריכים לוודא שהערך של הנושא ייחודי במקורות השונים. כדי להפוך את המפתח לייחודי, אפשר להשתמש בקידומת בתוספת מפתח עמודת המקור. לדוגמה, אם יש לכם שתי טבלאות של אנשים עם אותה סכימה, אתם יכולים להקצות פורמטים שונים לערך הנושא (s): ekg:person1_$(record_id) ו-ekg:person2_$(record_id).
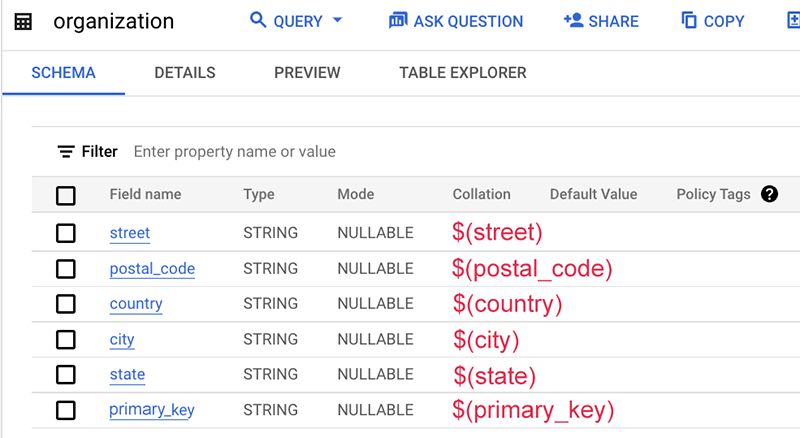
דוגמה לקובץ המיפוי:
prefixes:
ekg: http://cloud.google.com/ekg/0.0.1#
schema: https://schema.org/
mappings:
organization:
sources:
- [ekg-api-test:demo.organization~bigquery]
s: ekg:company_$(source_key)
po:
- [a, schema:Organization]
- [schema:name, $(source_name)]
- [schema:streetAddress, $(street)]
- [schema:postalCode, $(postal_code)]
- [schema:addressCountry, $(country)]
- [schema:addressLocality, $(city)]
- [schema:addressRegion, $(state)]
- [ekg:recon.source_name, (org)]
- [ekg:recon.source_key, $(primary_key)]
בדוגמה הזו, סכימת הטבלה עצמה לא מכילה את השם של מקור הנתונים הזה, שהוא בדרך כלל שם הטבלה או שם מסד הנתונים. לכן, אנחנו משתמשים במחרוזת סטטית org ללא סימן הדולר $.
יצירת משימת התאמה של ישויות
משתמשים במסוף Google Cloud כדי ליצור משימת התאמה.
פותחים את לוח הבקרה של Enterprise Knowledge Graph.
לוחצים על מיפוי סכימה כדי ליצור קובצי מיפוי מהתבנית שלנו לכל אחד ממקורות הנתונים, ואז שומרים את קובץ המיפוי ב-Cloud Storage.

לוחצים על Job (משימה) ואז על Run A Job (הפעלת משימה) כדי להגדיר את הפרמטרים של המשימה לפני שמתחילים אותה.
סוג ישות
ערך שם הדגם תיאור Organizationgoogle_brasilהתאמת ישויות ברמה Organization. לדוגמה, שם של תאגיד בתור חברה. זה שונה מLocalBusiness, שמתמקד בסניף מסוים, בנקודת עניין או במיקום פיזי, למשל, אחד מתוך כמה קמפוסים של חברה.LocalBusinessgoogle_cyprusהתאמת ישות על סמך סניף מסוים, נקודת עניין או נוכחות פיזית. הוא יכול גם לקבל קואורדינטות גיאוגרפיות כקלט למודל. Persongoogle_atlantisהתאמה של ישות מסוג אדם על סמך קבוצה של מאפיינים מוגדרים מראש ב- schema.org.מקורות נתונים
יש תמיכה רק בטבלאות BigQuery.
יעד
נתיב הפלט צריך להיות מערך נתונים ב-BigQuery, שבו יש לתרשים הידע הארגוני הרשאה לכתוב.
לכל משימה שמופעלת, Enterprise Knowledge Graph יוצר טבלת BigQuery חדשה עם חותמת זמן כדי לאחסן את התוצאות.
אם משתמשים ב-Entity Reconciliation API, התגובה של העבודה מכילה את השם המלא של טבלת הפלט ואת המיקום שלה.
אם צריך, מגדירים את האפשרויות המתקדמות.
כדי להתחיל את העבודה, לוחצים על סיום.
מעקב אחר סטטוס העבודה
אפשר לעקוב אחרי סטטוס העבודה גם במסוף Google Cloud וגם ב-API. התהליך עשוי להימשך עד 24 שעות, בהתאם למספר הרשומות במערכי הנתונים. לוחצים על כל משימה כדי לראות את ההגדרה המפורטת שלה.
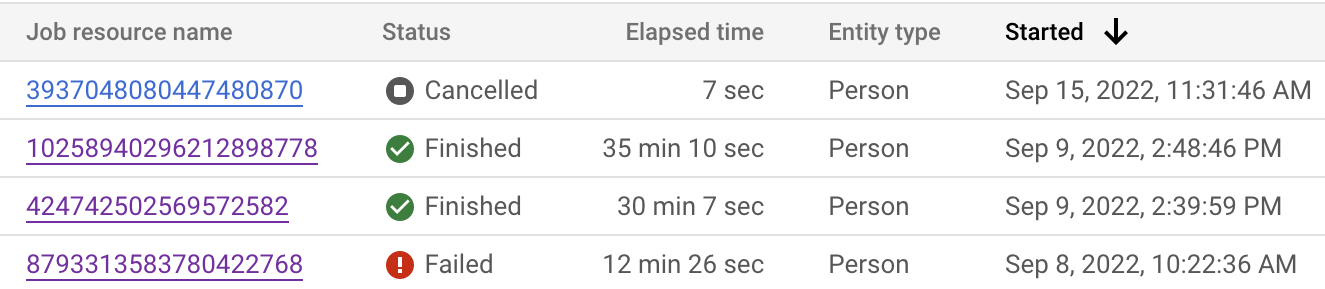
אפשר גם לבדוק את סטטוס העבודה כדי לראות איפה נמצא השלב הנוכחי.
| מצב התצוגה של המשרה | מצב הקוד | תיאור |
|---|---|---|
| פועל | JOB_STATE_RUNNING |
העבודה מתבצעת. |
| חילוץ ידע | JOB_STATE_KNOWLEDGE_EXTRACTION |
תרשים הידע הארגוני שולף נתונים מ-BigQuery ויוצר תכונות. |
| עיבוד מקדים של התאמה | JOB_STATE_RECON_PREPROCESSING |
העבודה נמצאת בשלב של עיבוד מקדים של התאמה. |
| סידור באשכולות | JOB_STATE_CLUSTERING |
המשימה נמצאת בשלב של יצירת אשכולות. |
| ייצוא אשכולות | JOB_STATE_EXPORTING_CLUSTERS |
המשימה כותבת פלט למערך נתוני היעד ב-BigQuery. |
זמן הריצה של כל עבודה משתנה בהתאם להרבה גורמים, כמו מורכבות הנתונים, גודל מערך הנתונים ומספר העבודות המקבילות האחרות שפועלות בו-זמנית. לעיון שלכם, הנה הערכה גסה של זמן ההרצה של העבודה לעומת גודל מערך הנתונים. הזמן בפועל להשלמת העבודה יהיה שונה.
| מספר הרשומות הכולל | זמן הביצוע |
|---|---|
| 100k | בערך שעתיים |
| 100 מיליון | כ-16 שעות |
| 300 מיליון | בערך 24 שעות |
ביטול של משימת התאמה
אפשר cancel משימה פעילה גם דרך Google Cloud המסוף (בדף פרטי המשימה) וגם דרך ה-API. גרף הידע הארגוני מפסיק את המשימה בהזדמנות הראשונה האפשרית, על בסיס מיטב המאמצים. הצלחת הפקודה cancel לא מובטחת.
אפשרויות מתקדמות
| הגדרות אישיות | תיאור |
|---|---|
| טבלה ב-BigQuery עם התוצאה הקודמת | אם מציינים טבלת תוצאות קודמת, מזהה האשכול נשאר יציב בין משימות שונות. אחר כך תוכלו להשתמש במזהה האשכול כמזהה קבוע. |
| אשכולות של תחום עניין משותף | האפשרות המומלצת ברוב המקרים. זוהי גרסה מקבילית של קיבוץ היררכי לאשכולות, והיא מתאימה מאוד לשימוש בקנה מידה גדול. אפשר לציין את מספר סבבי האשכולות (איטרציות) בטווח [1, 5]. ככל שהמספר גבוה יותר, כך האלגוריתם נוטה למזג את האשכול בצורה מוגזמת.
|
| אשכולות של רכיבים מחוברים | אפשרות ברירת המחדל. זוהי אפשרות חלופית מדור קודם. כדאי לנסות את האפשרות הזו רק אם האפשרות 'אשכולות של קירבה' לא פועלת טוב במערך הנתונים שלכם. סף המשקל יכול להיות מספר בטווח [0.6, 1]. |
| הפרדה של המרת כתובות לקואורדינטות (geocoding) | האפשרות הזו מבטיחה שישויות מאזורים גיאוגרפיים שונים לא יקובצו יחד. |