
Questo documento descrive come esportare i documenti da Document AI Warehouse nel set di dati di un estrattore di documenti personalizzato (CDE) in Document AI Workbench.
CDE consente agli utenti di creare estrattori di documenti. Importano i documenti nel set di dati del processore, quindi li etichettano prima di addestrare il modello. Quando gli utenti esportano i documenti selezionati nel set di dati di un CDE, possono creare il set di dati gestendo o cercando i documenti in Document AI Warehouse.
Creare un CDE in Document AI Workbench
Puoi trovare le istruzioni complete su come creare un CDE in questa guida ufficiale. In questa guida evidenziamo alcuni passaggi chiave.
Creare un CDE dall'elenco dei processori
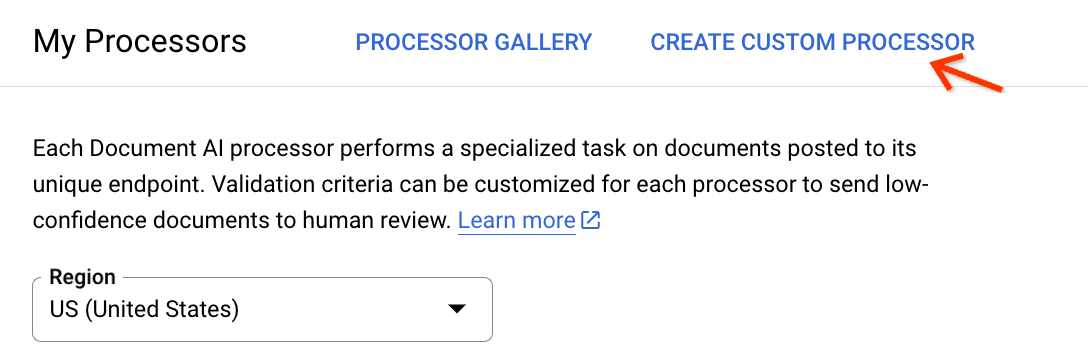
Vai alla pagina I miei processori e fai clic su Crea processore personalizzato:
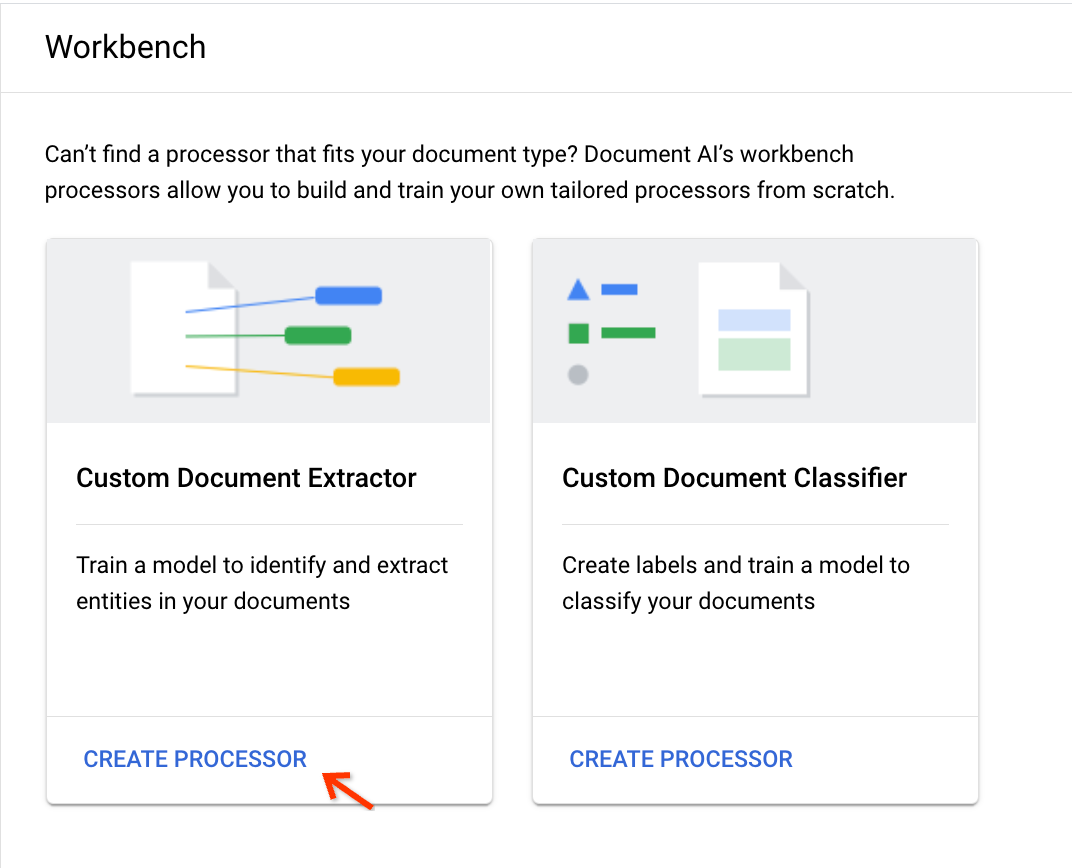
Scegli Crea processore nella scheda Estrattore di documenti personalizzato:
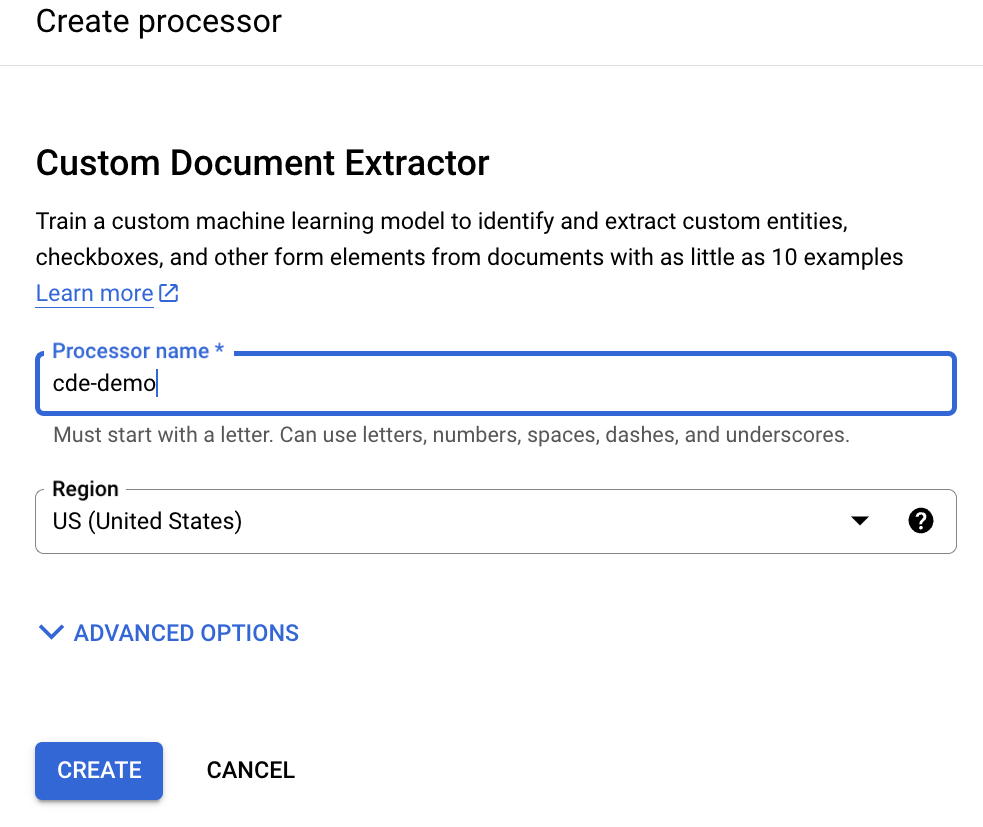
Inserisci un nome visualizzato e fai clic su Crea:
Il CDE dovrebbe essere creato rapidamente.
Configurare il set di dati del CDE
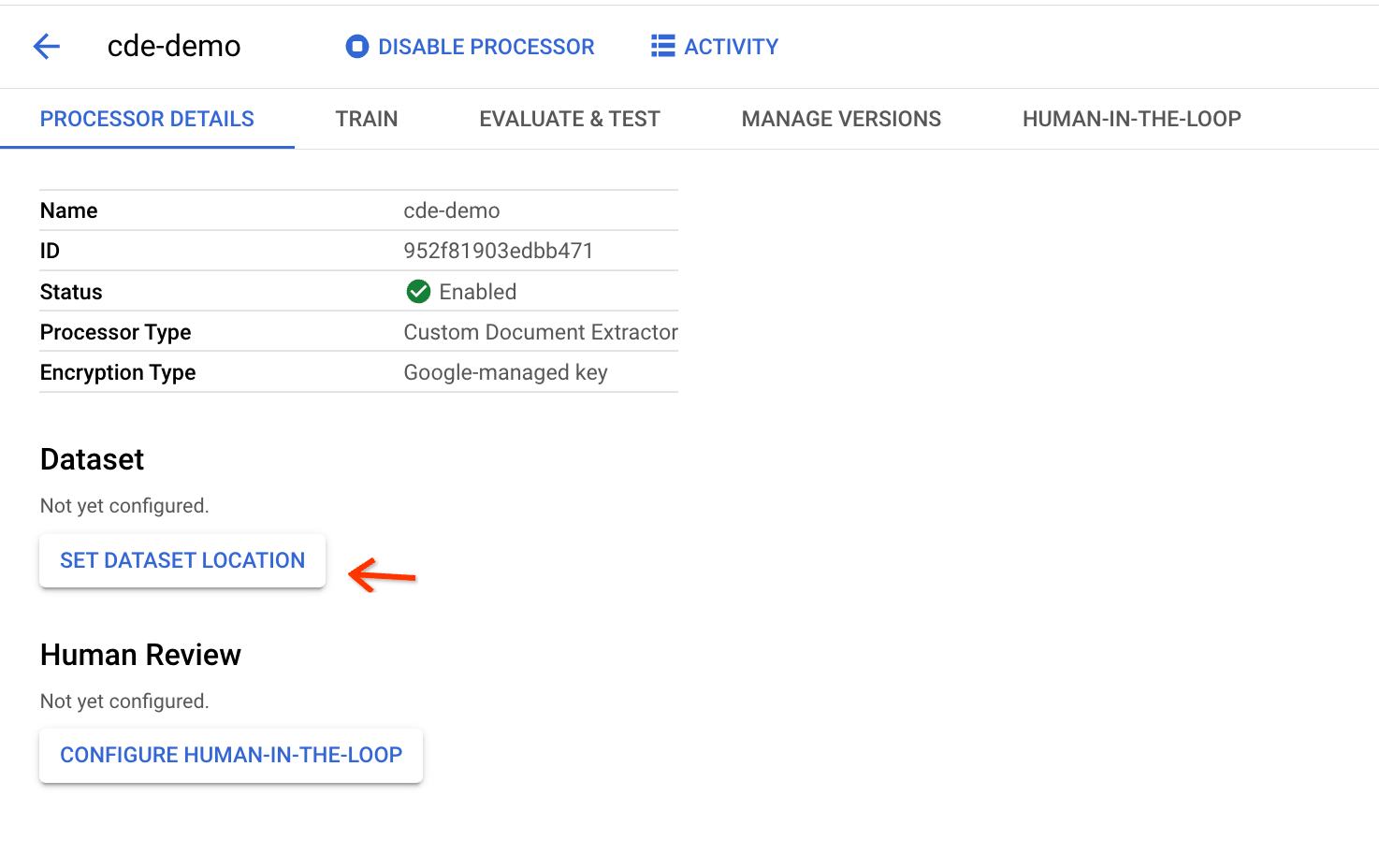
Nella pagina dei dettagli del processore, fai clic su Imposta la località del set di dati:
Specifica un percorso del bucket da utilizzare per archiviare i documenti nel set di dati:
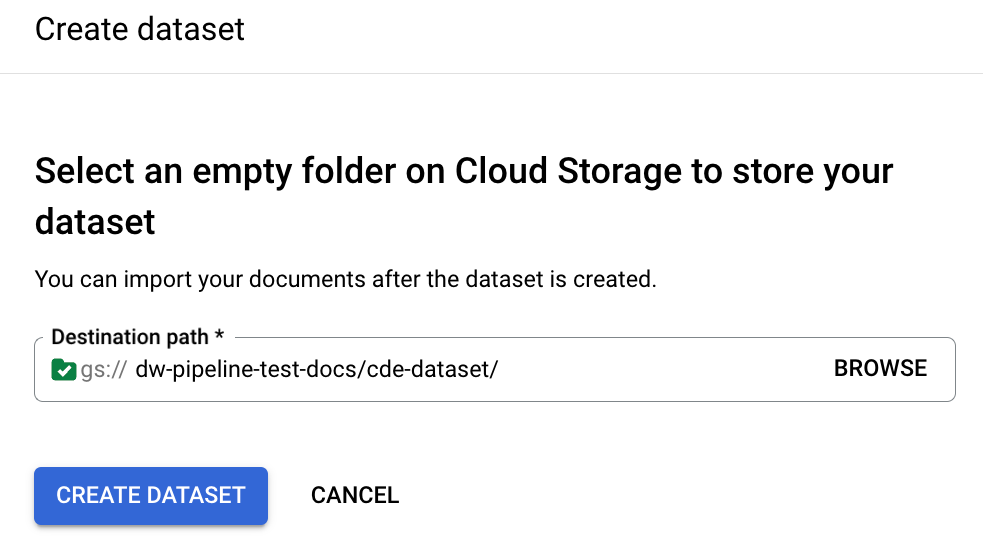
Il completamento della configurazione richiede alcuni minuti. Dopodiché, puoi visualizzare il percorso e il conteggio del bucket nella pagina dei dettagli:
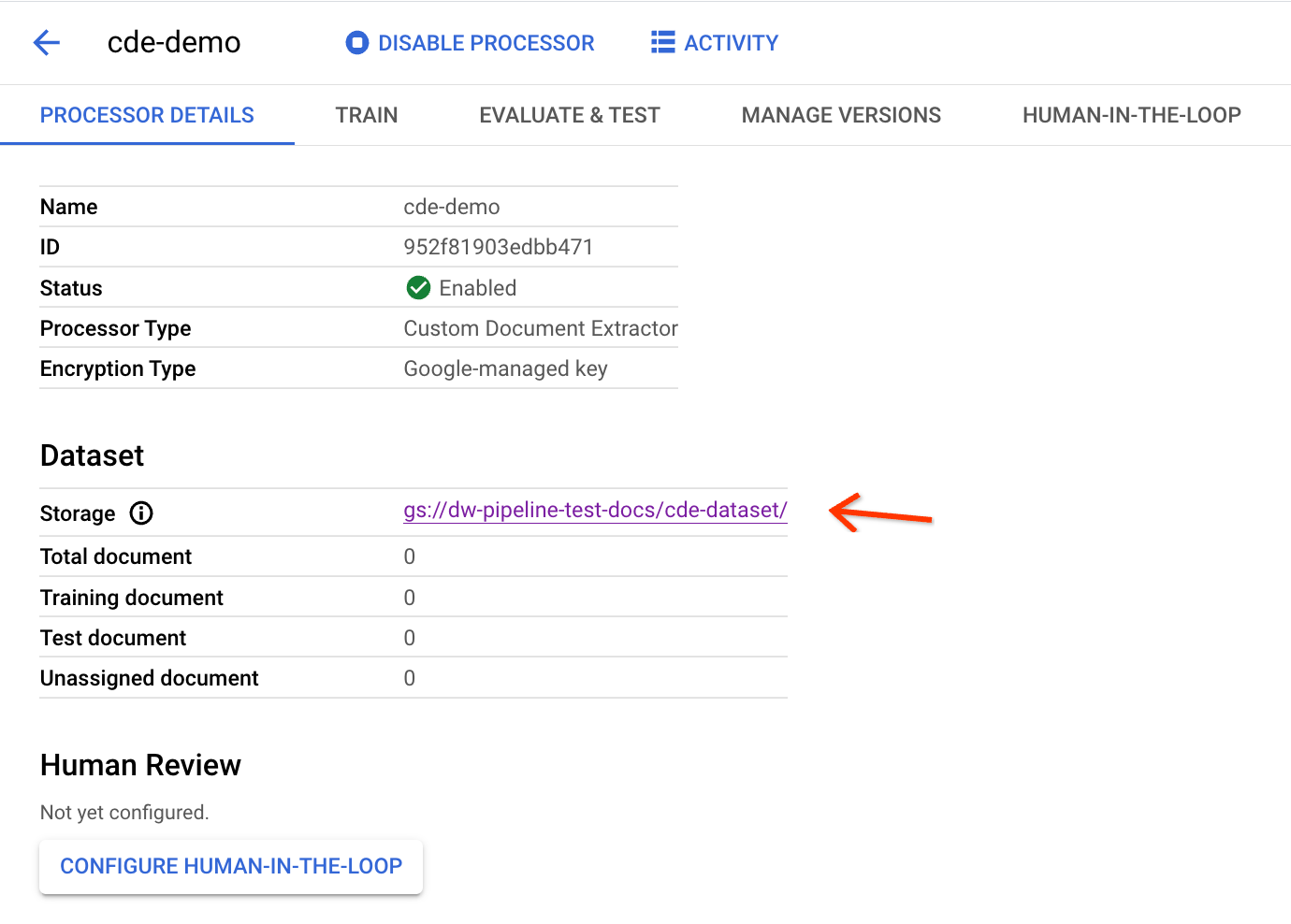
Per attivare la pipeline di esportazione in Workbench, devi avere l'ID processore riportato sopra.
Attivare la pipeline di esportazione in Workbench
Seleziona i documenti da esportare e fai clic su Esporta in Document AI Workbench nella barra delle azioni:
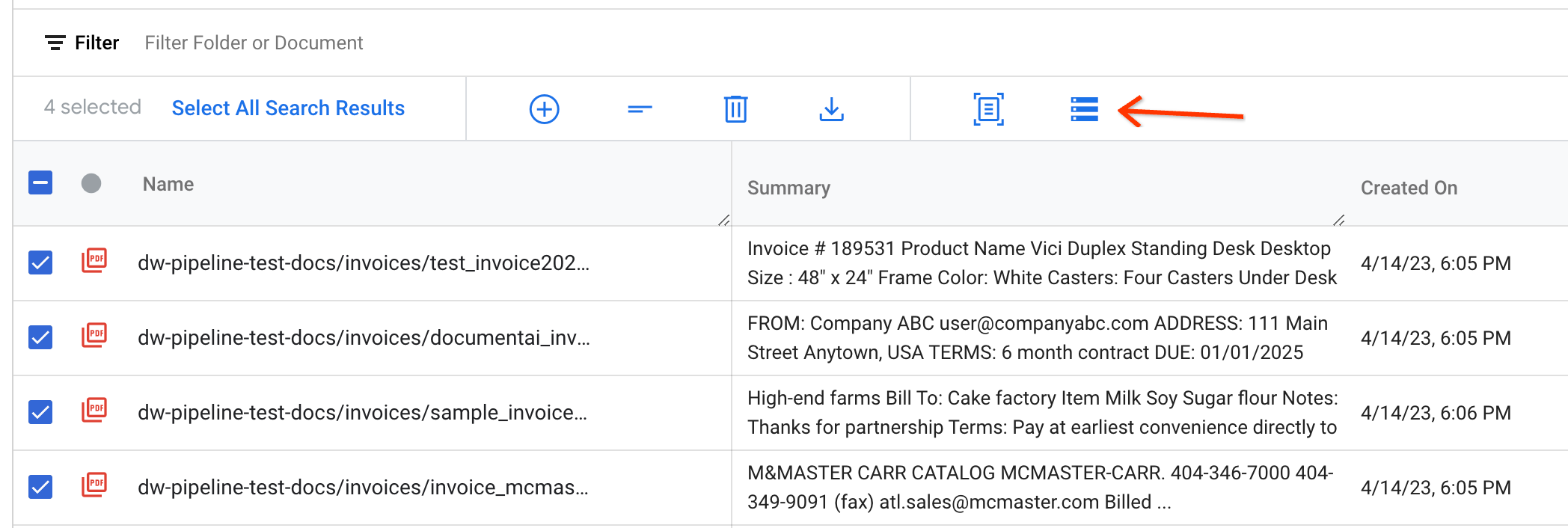
Inserisci i parametri di input e attiva la pipeline copiando l'ID processore dal CDE e incollandolo nella finestra di dialogo.
Prima di esportare i documenti, devi avere un percorso del bucket di gestione temporanea per archiviarli temporaneamente. L'opzione Suddivisione dei dati consente agli utenti di inserire casualmente il documento in un set di addestramento o di test. Il rapporto tra le suddivisioni si basa su questo valore.
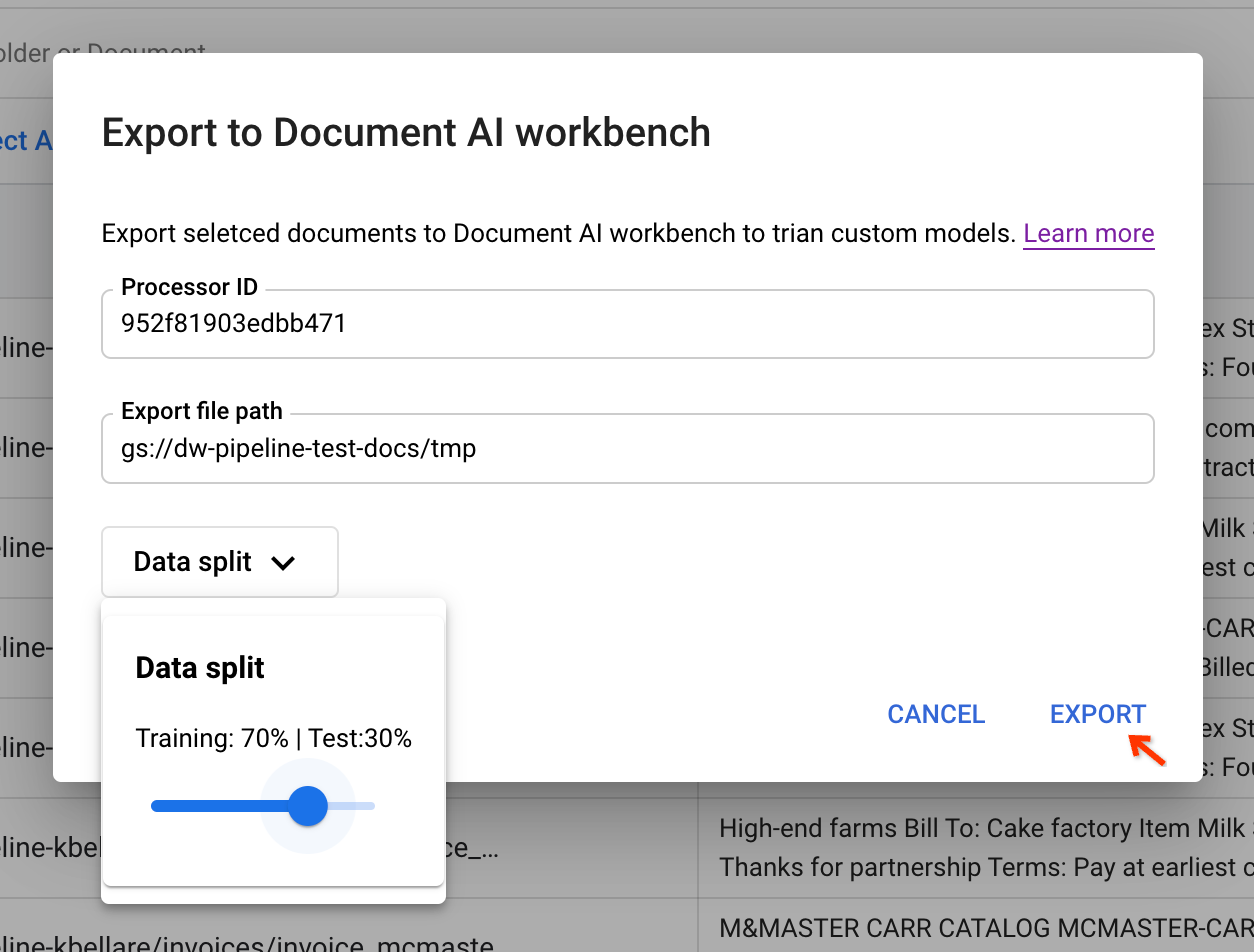
Facendo clic su Esporta, viene attivato il job della pipeline.
Stato del canale.
Dopo aver attivato la pipeline, viene visualizzata una pagina di monitoraggio dello stato. Al momento, la pagina non ha un monitoraggio in corso. La pagina di stato mostra In attesa fino al completamento del job.
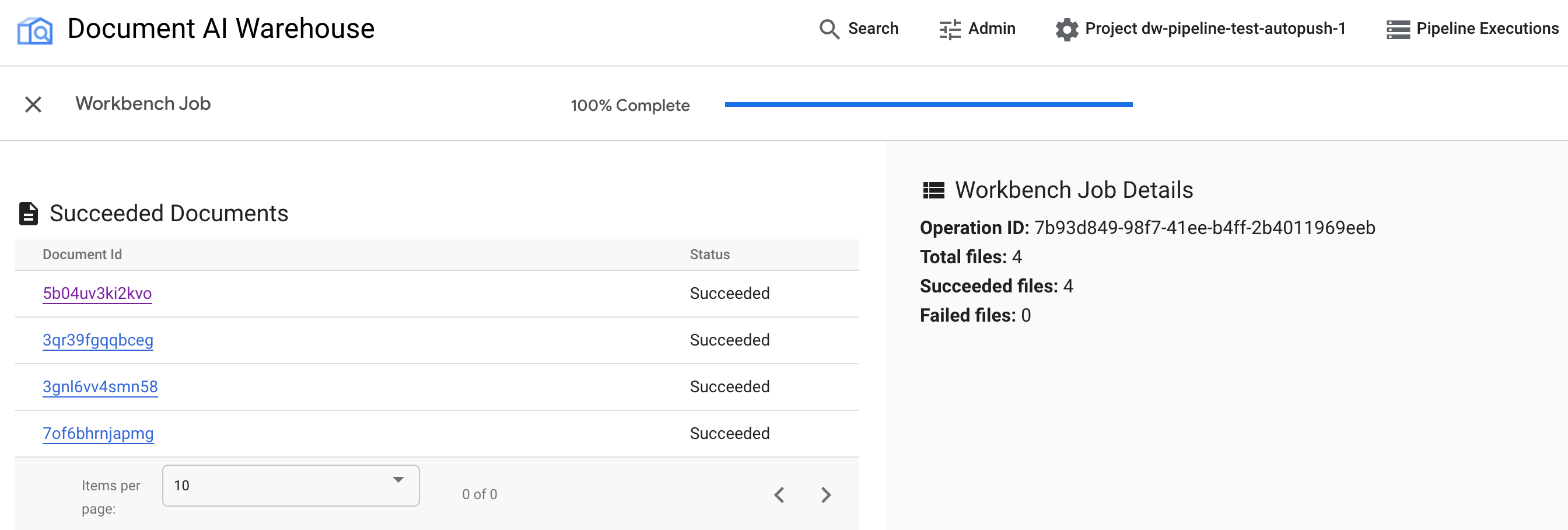
Esamina i risultati.
Al termine del job, puoi visualizzare i documenti riusciti e quelli non riusciti.
Per verificare se i documenti sono stati esportati correttamente, torna alla pagina dei dettagli del CDE:
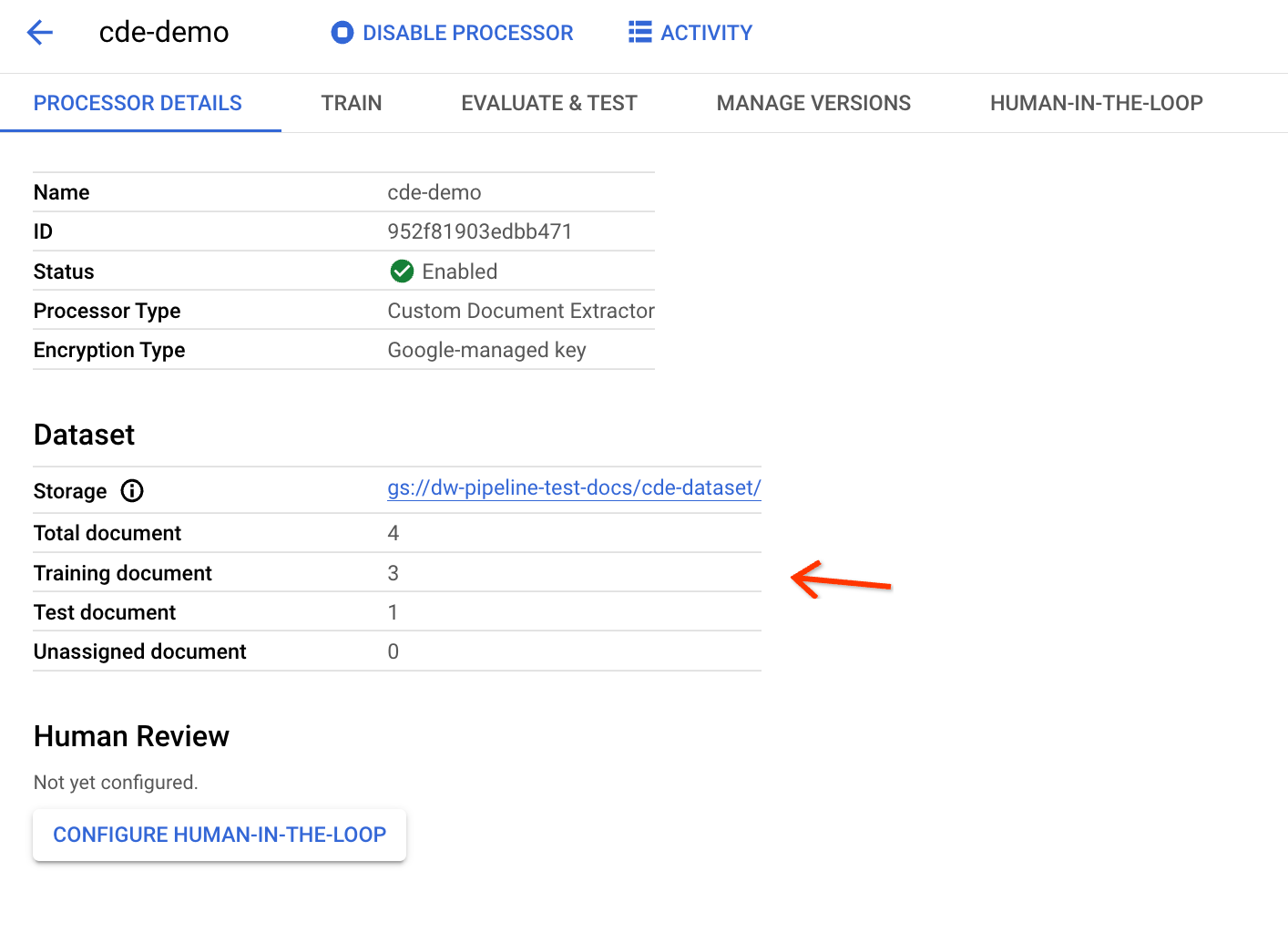
Se la pagina è aperta prima dell'esecuzione della pipeline, aggiornala per trovare le statistiche aggiornate. Le distribuzioni dei set di addestramento e di test si basano sul rapporto di suddivisione dei dati.
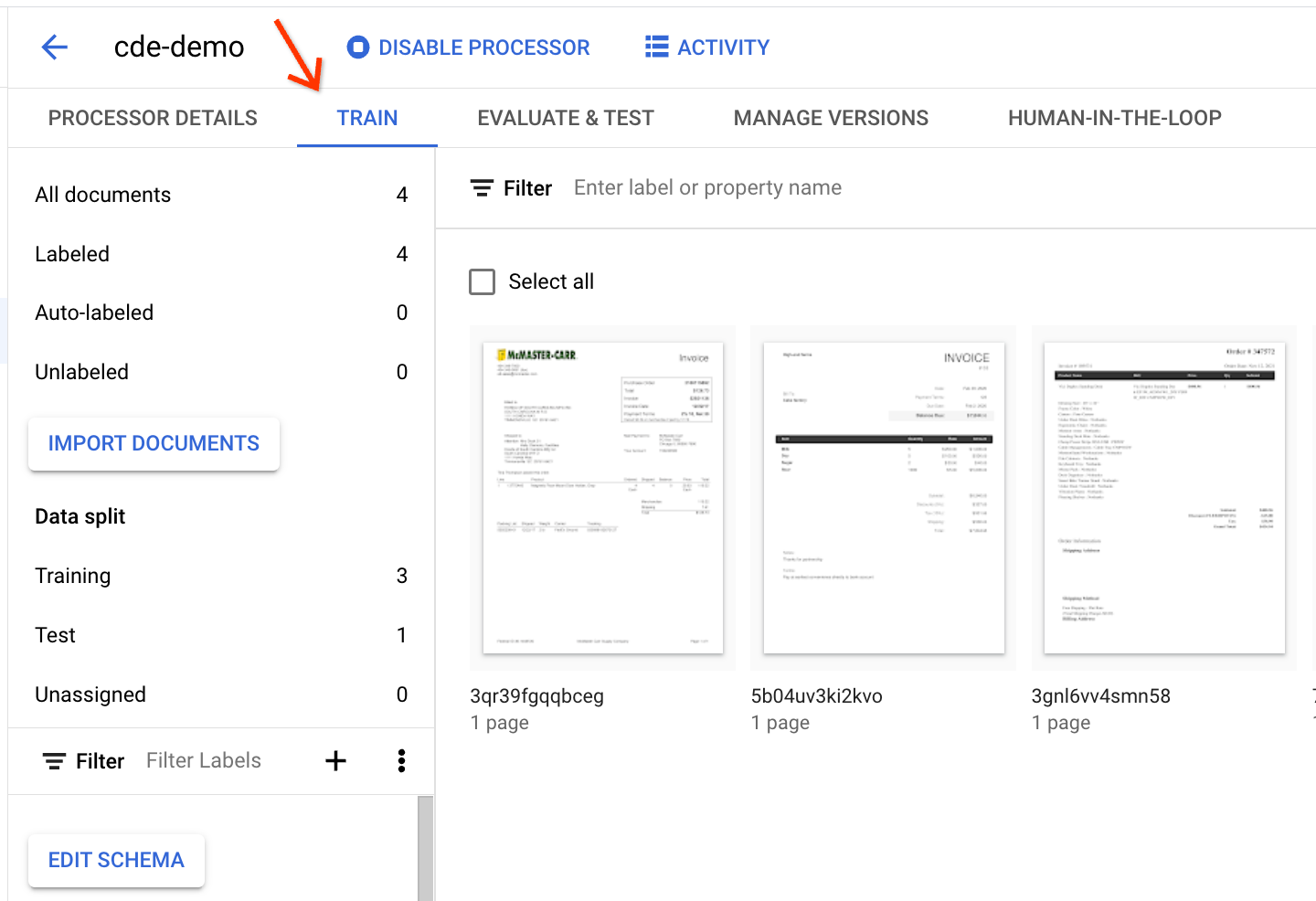
Per visualizzare i documenti in dettaglio, vai alla scheda Addestra:
Passaggio successivo
Scopri di più sull'API runPipeline.