
במאמר הזה מוסבר איך לייצא מסמכים מ-Document AI Warehouse אל מערך הנתונים של כלי מותאם אישית לחילוץ מסמכים (CDE) ב-Document AI Workbench.
הכלי CDE מאפשר למשתמשים ליצור כלי לחילוץ מסמכים. הם מייבאים מסמכים למערך הנתונים של המעבד, ואז מתייגים אותם לפני אימון המודל. כשמשתמשים מייצאים מסמכים נבחרים למערך נתונים של CDE, הם יכולים לבנות את מערך הנתונים על ידי ניהול או חיפוש המסמכים ב-Document AI Warehouse.
יצירת CDE ב-Document AI Workbench
הוראות מלאות ליצירת CDE מופיעות במדריך הרשמי הזה. במדריך הזה אנחנו מדגישים כמה שלבים חשובים.
יצירת CDE מתוך רשימת המעבדים
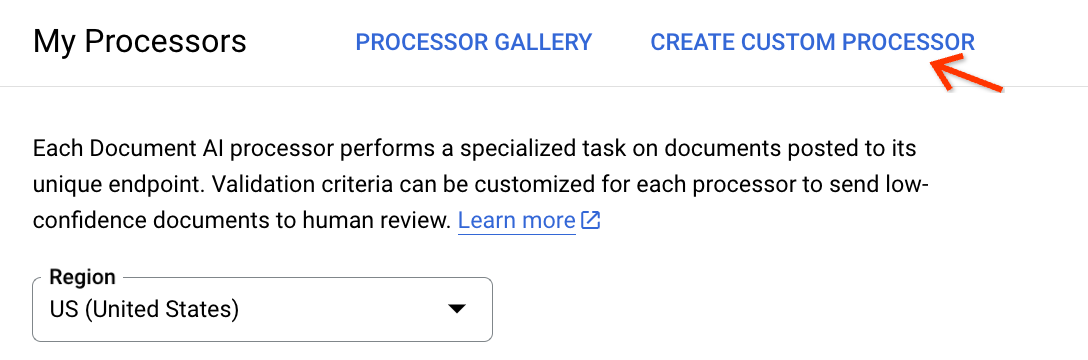
עוברים לדף My processors (המעבדים שלי) ולוחצים על Create Custom Processor (יצירת מעבד בהתאמה אישית):
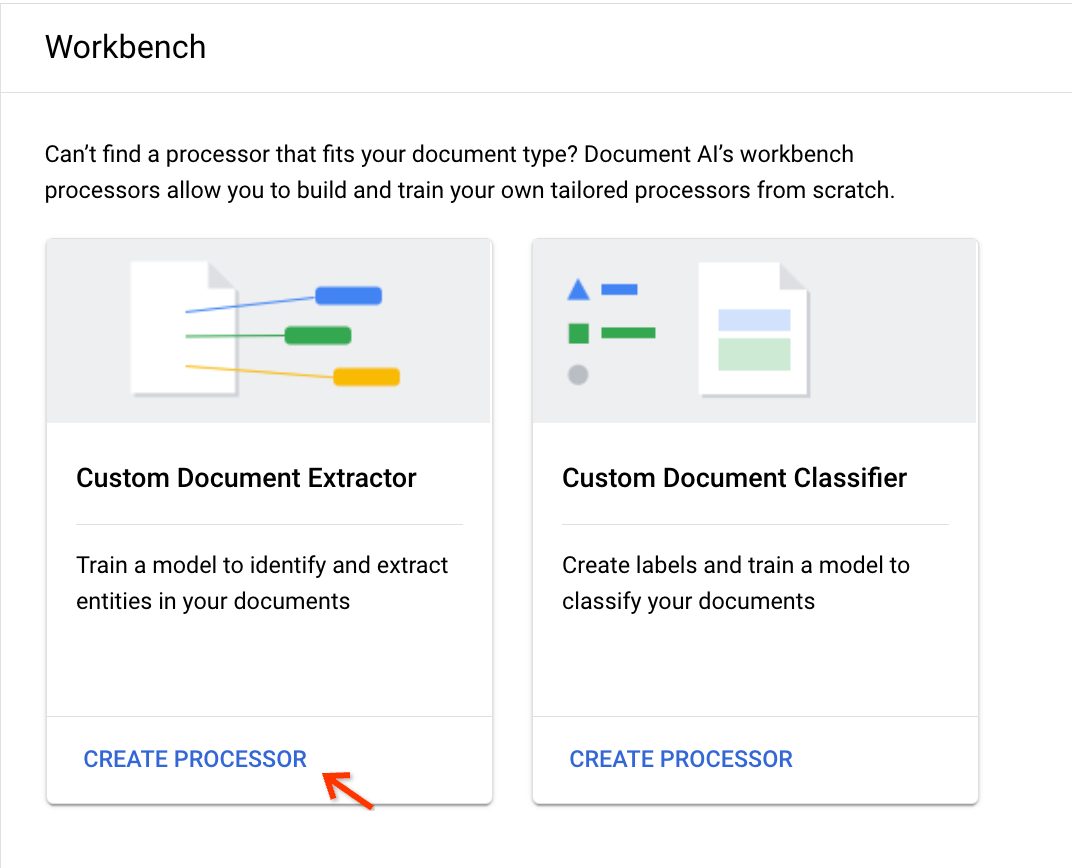
בכרטיס Custom Document Extractor (כלי לחילוץ נתונים ממסמכים בהתאמה אישית), בוחרים באפשרות Create Processor (יצירת מעבד):
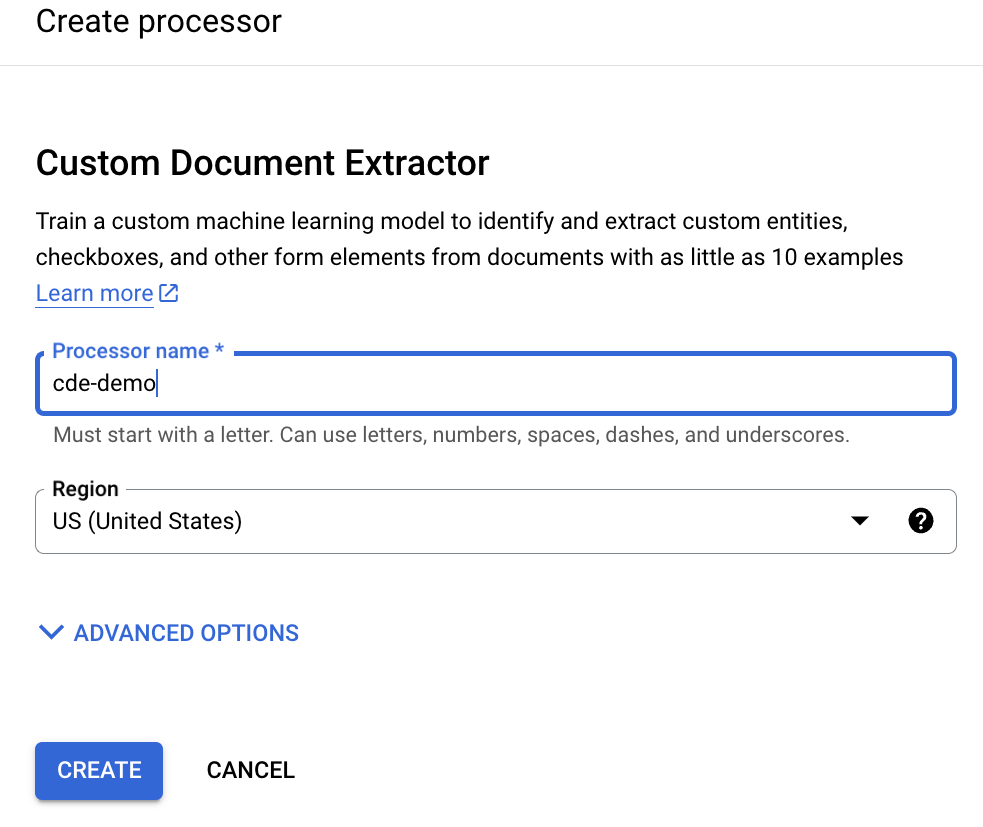
מזינים שם לתצוגה ולוחצים על יצירה:
ה-CDE אמור להיווצר במהירות.
הגדרת מערך הנתונים של CDE
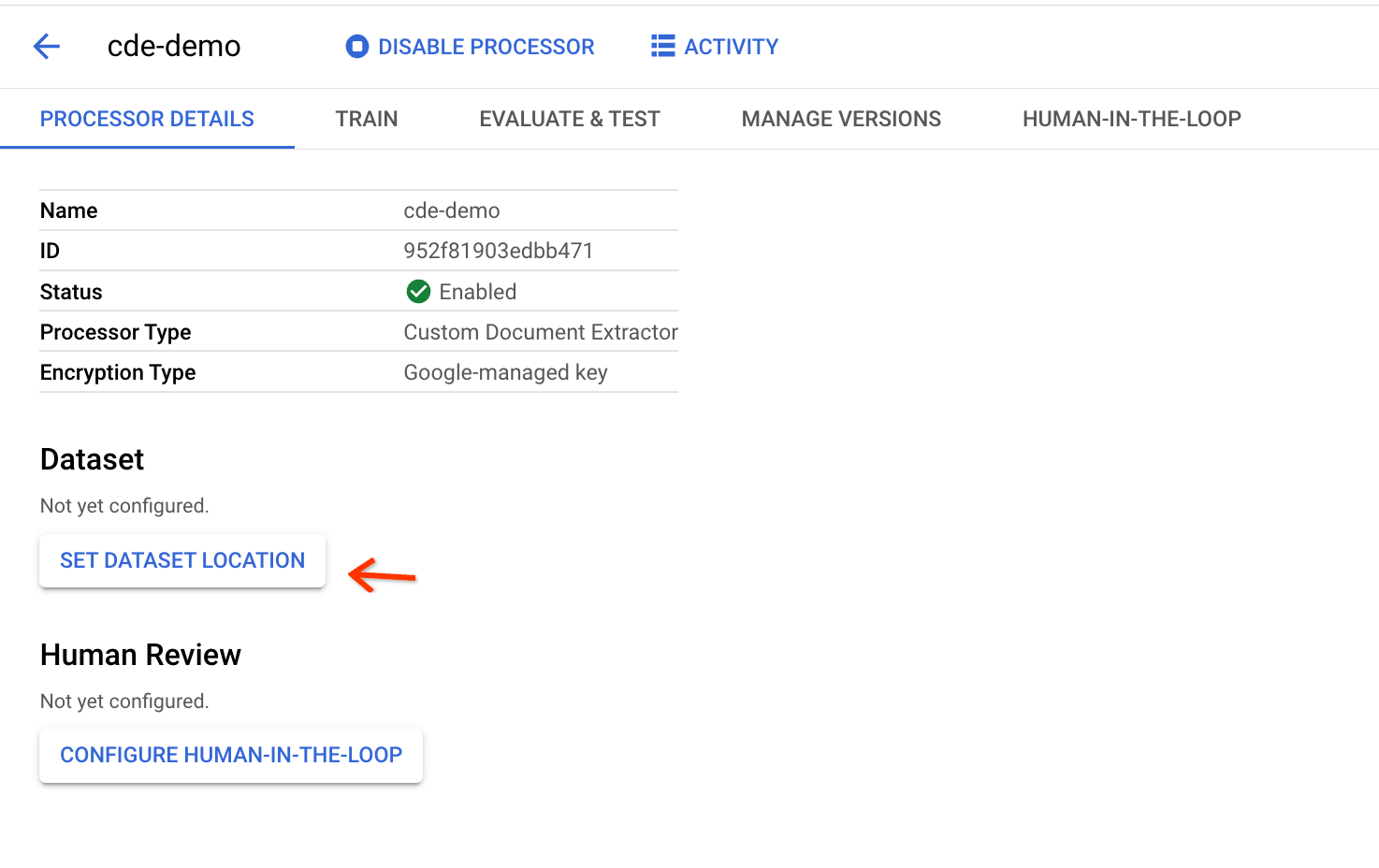
בדף הפרטים של המעבד, לוחצים על הגדרת המיקום של מערך הנתונים:
מציינים נתיב של קטגוריה שבה יישמרו המסמכים במערך הנתונים:
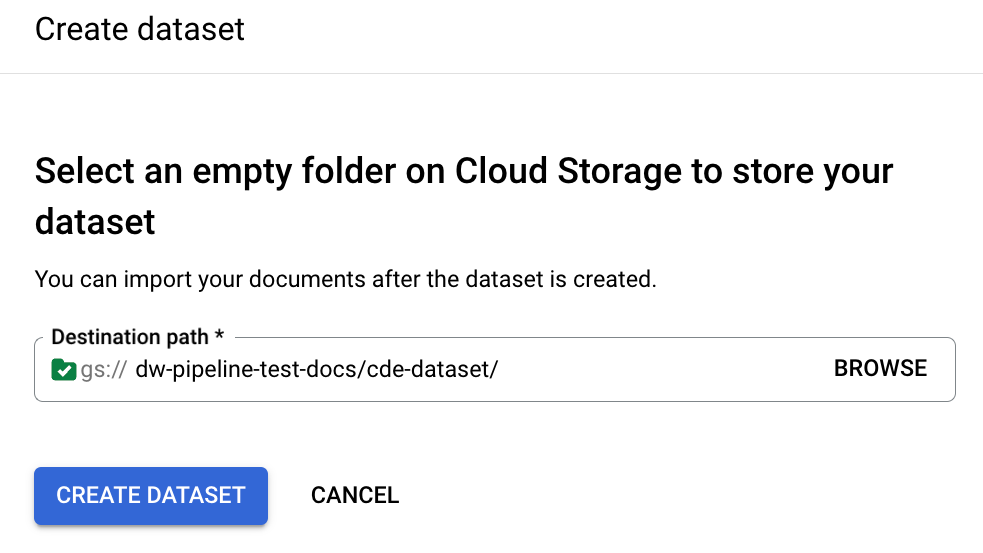
תהליך ההגדרה נמשך כמה דקות. אחרי כן, תוכלו לראות את נתיב הדלי ואת מספר הפריטים בדף הפרטים:
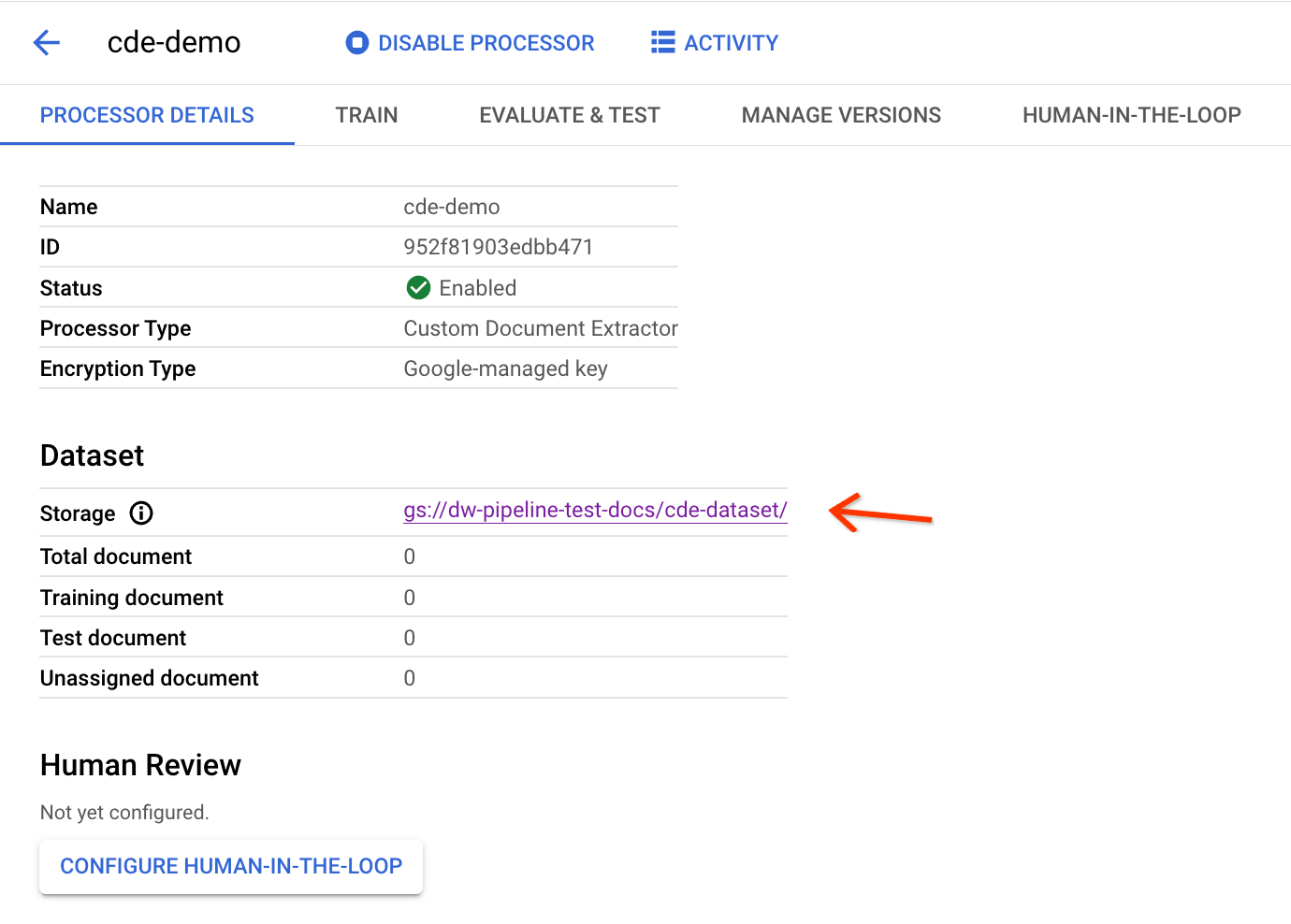
כדי להפעיל את צינור הנתונים של export-to-Workbench, צריך את מזהה המעבד שמופיע למעלה.
הפעלת צינור עיבוד הנתונים לייצוא ל-Workbench
בוחרים את המסמכים לייצוא ולוחצים על ייצוא ל-Document AI Workbench בסרגל הפעולות:
כדאי לצמצם את החיפוש או את קריטריוני הסינון.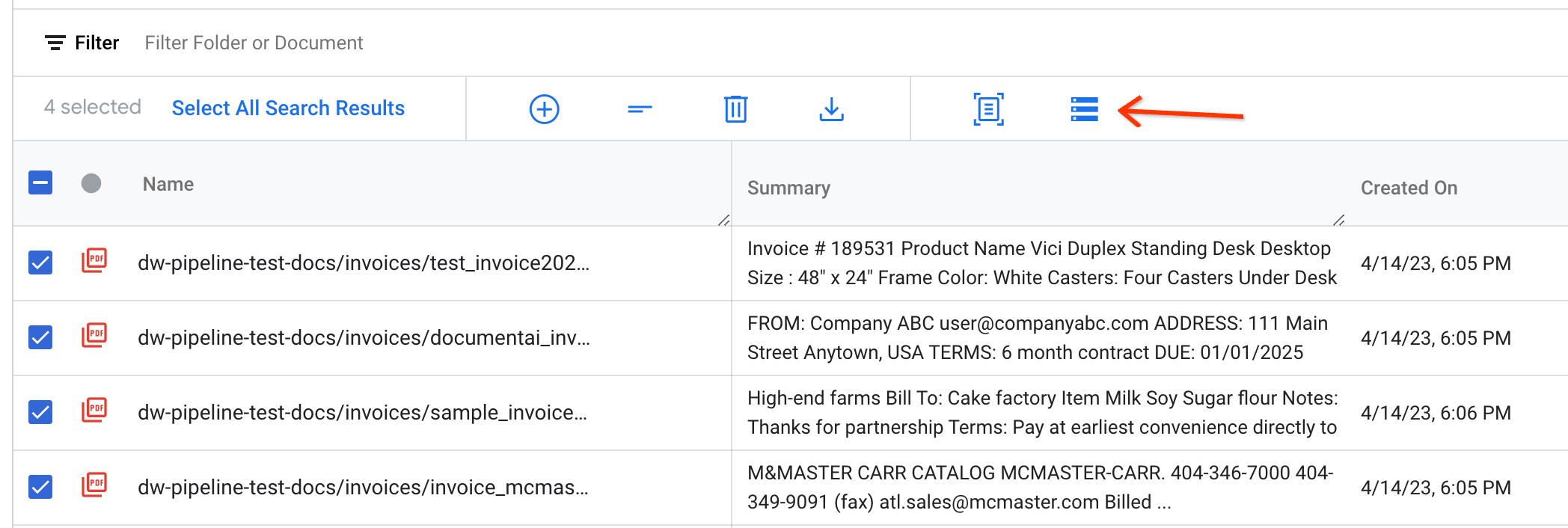
מזינים פרמטרים של קלט ומפעילים את צינור העיבוד על ידי העתקת מזהה המעבד מ-CDE והדבקתו בתיבת הדו-שיח.
צריך נתיב של מאגר זמני כדי לאחסן את המסמכים באופן זמני לפני ייצוא שלהם. פיצול נתונים מאפשר למשתמשים להוסיף את המסמך באופן אקראי למערך אימון או לקבוצת נתונים לבדיקה. היחס בין החלקים מבוסס על הערך הזה.
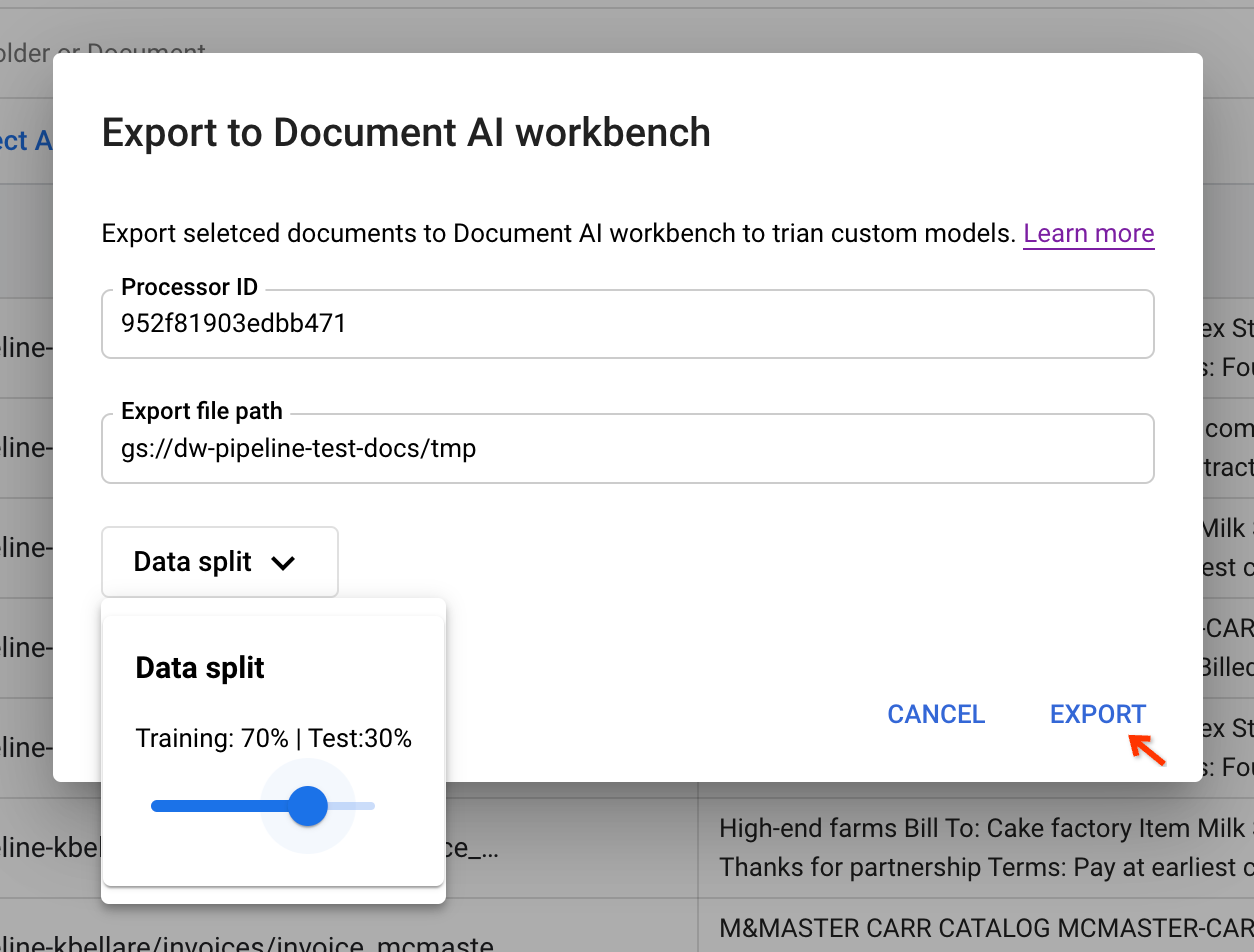
לחיצה על ייצוא מפעילה את עבודת צינור עיבוד הנתונים.
סטטוס המסלול
אחרי הפעלת הצינור, מופיע דף למעקב אחר הסטטוס. נכון לעכשיו, אין מעקב פעיל בדף. בדף הסטטוס מוצג סטטוס ההמתנה עד שהמשימה מסתיימת.
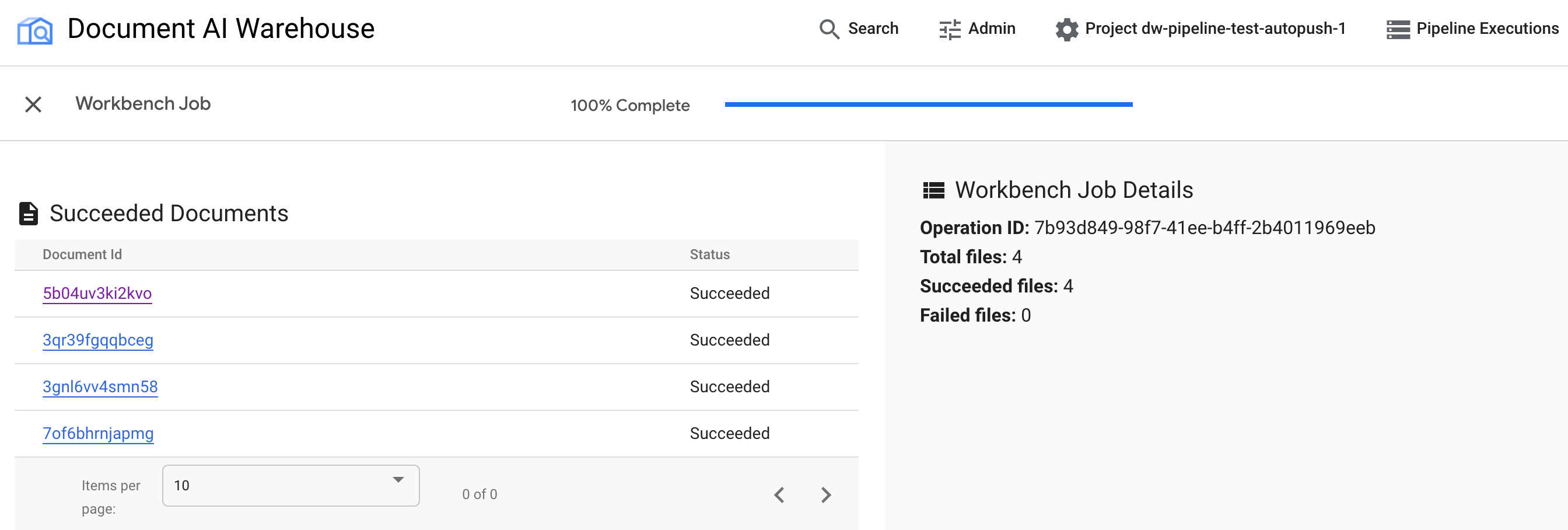
בודקים את התוצאות.
אחרי שהמשימה מסתיימת, אפשר לראות את המסמכים שהועלו בהצלחה ואת המסמכים שלא הועלו.
כדי לבדוק אם המסמכים יוצאו בצורה נכונה, חוזרים לדף הפרטים של CDE:
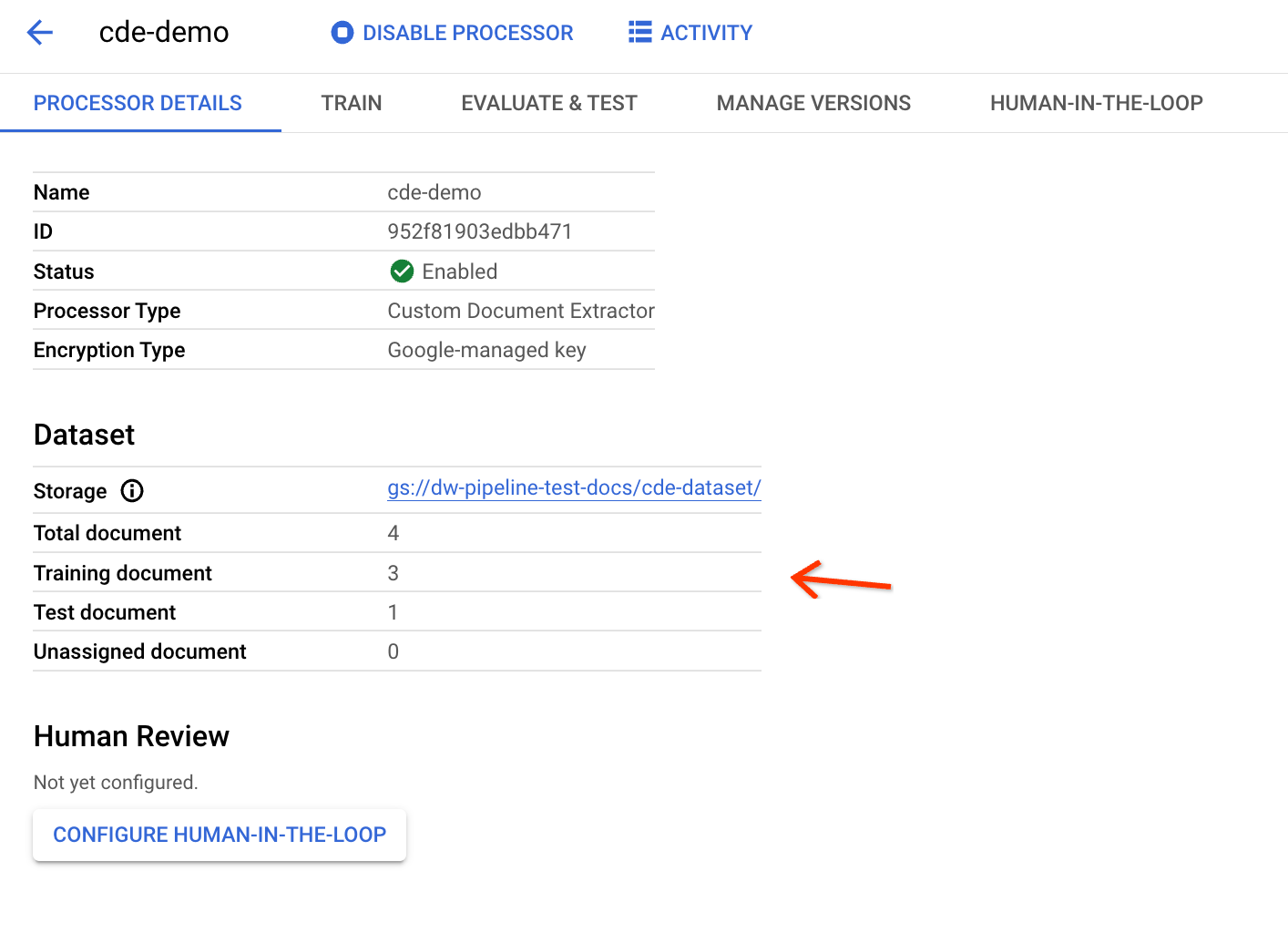
אם הדף פתוח לפני הפעלת צינור הנתונים, צריך לרענן אותו כדי לראות את הנתונים הסטטיסטיים המעודכנים. ההתפלגויות של קבוצת האימון וקבוצת נתונים לבדיקה מבוססות על יחס פיצול הנתונים.
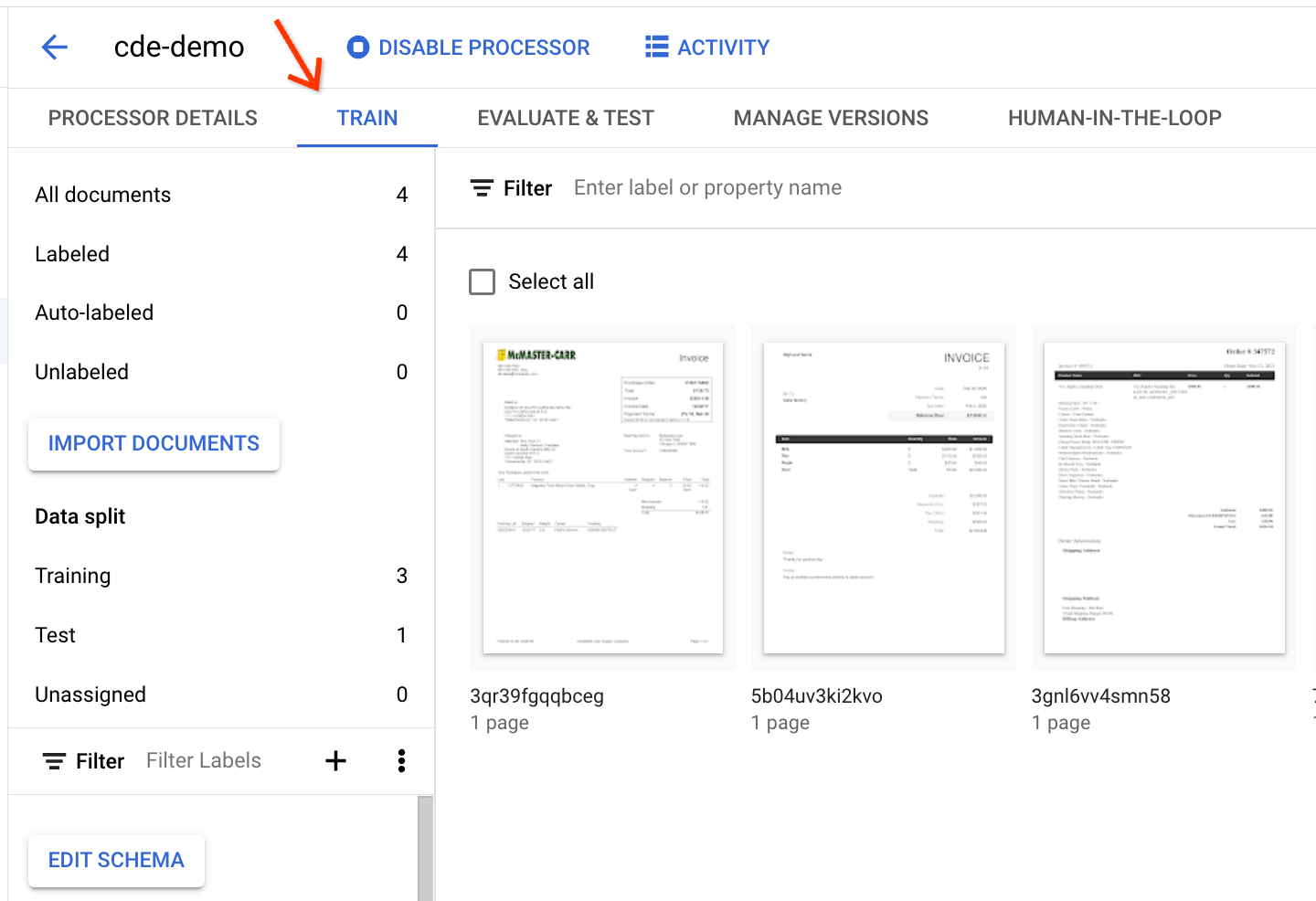
כדי לראות את המסמכים בפירוט, עוברים לכרטיסייה Train (אימון):
השלב הבא
מידע נוסף על runPipeline API