
이 문서에서는 백그라운드에서 Cloud Storage 수집 파이프라인을 트리거하는 일괄 업로드를 실행하는 방법을 설명합니다.
전처리 옵션
현재 일괄 업로드에서는 다음과 같은 세 가지 전처리 옵션을 제공합니다.
전처리 없이 일괄 업로드: Document AI 프로세서로 문서를 처리하지 않고 GcsIngestPipeline을 사용하여 runPipeline API를 트리거합니다.
Document AI 프로세서로 항목 추출: GcsIngestWithDocAiProcessorsPipeline을 사용하여 runPipeline API를 트리거합니다. 파이프라인은 먼저 지정된 Document AI 프로세서를 호출한 다음 처리된 결과로 문서를 수집합니다.
문서 유형 분류 및 유형별 항목 추출: 이 경우에도 GcsIngestWithDocAiProcessorsPipeline을 사용하여 runPipeline API가 트리거되며, 이 API는 먼저 분류기를 호출합니다. 그런 다음 각 문서 유형에 대해 해당 스키마와 프로세서를 지정하여 특정 문서 유형을 처리할 수 있습니다. 결과와 함께 수집되고 이 스키마로 설정됩니다.
각 전처리 유형은 UI의 다음 옵션에 해당합니다.
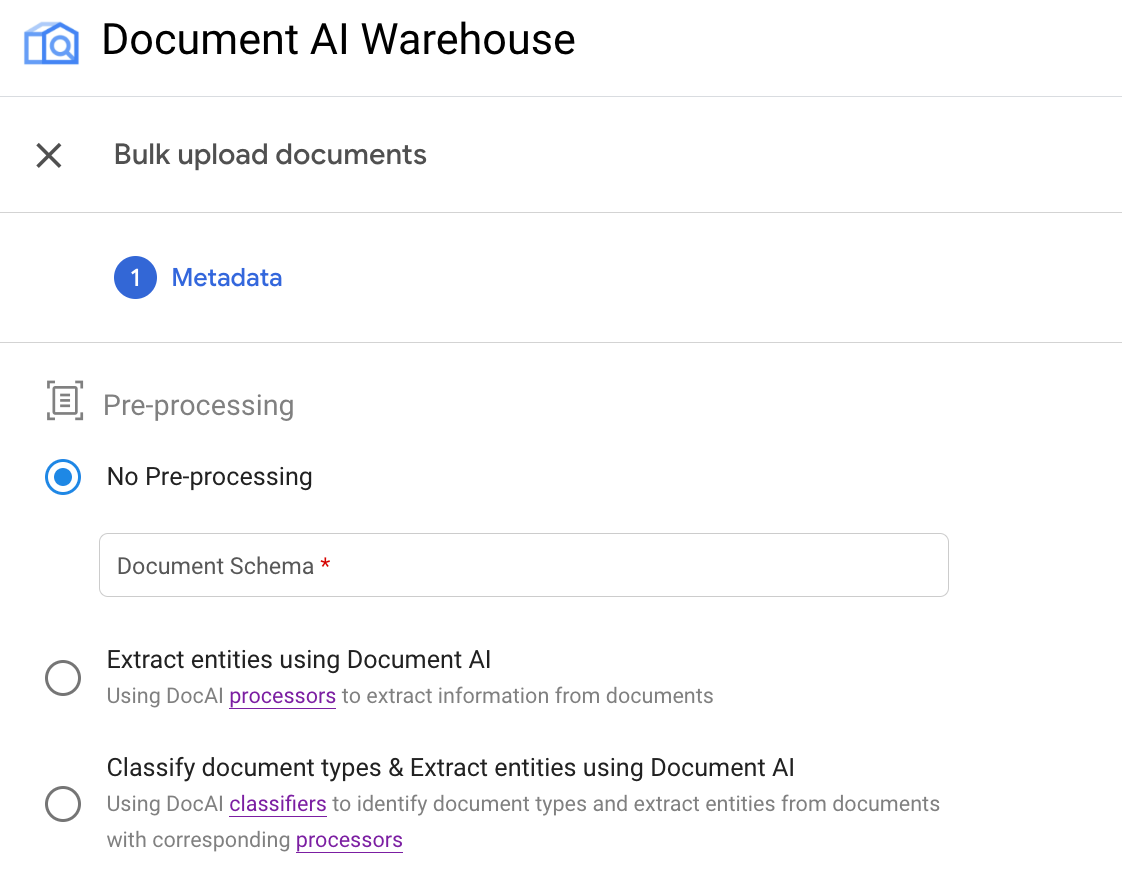
예: OCR 프로세서로 일괄 업로드 트리거
이 예에서는 파이프라인의 두 번째 사용 사례를 보여줍니다.
OCR 프로세서 만들기 및 프로세서 ID 가져오기
이전에 OCR 프로세서를 만든 적이 있다면 프로세서 목록에서 프로세서를 찾아 프로세서의 세부정보 페이지로 이동하여 프로세서 ID를 가져오면 됩니다.
아직 만들지 않았다면 다음 단계를 따르세요.
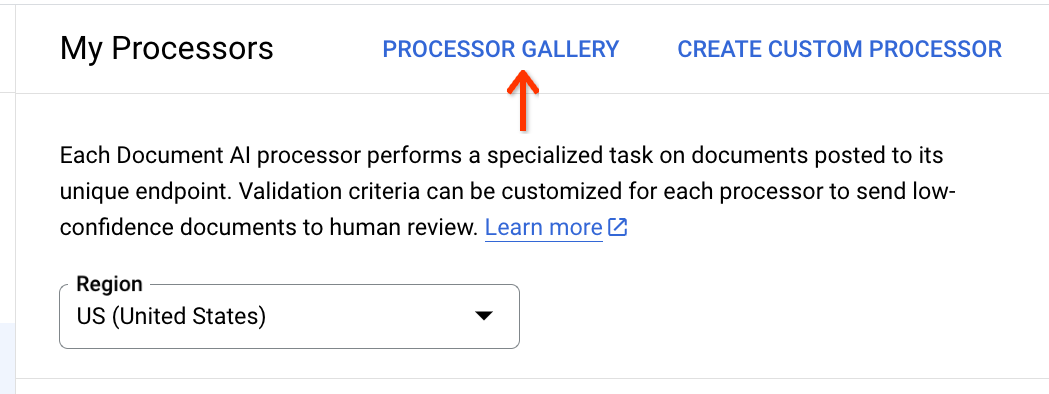
프로세서 목록 상단에서 프로세서 갤러리를 클릭합니다.
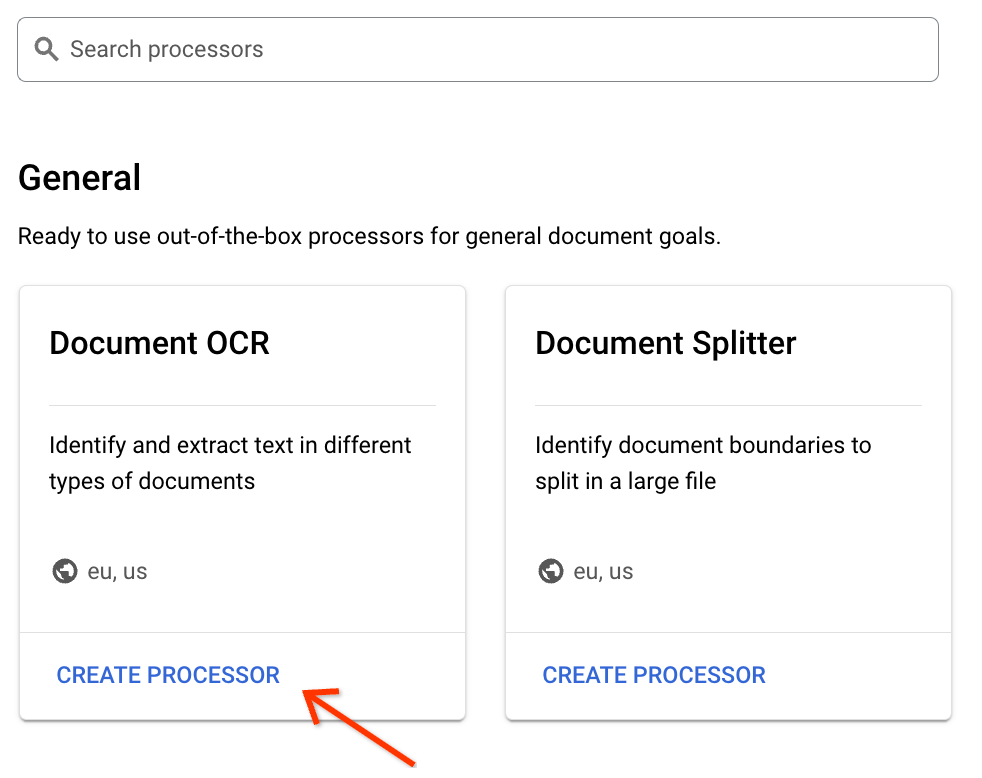
갤러리에서 문서 OCR 프로세서를 찾아 카드 하단에 있는 프로세서 만들기를 클릭합니다.
프로세서 표시 이름을 입력합니다.
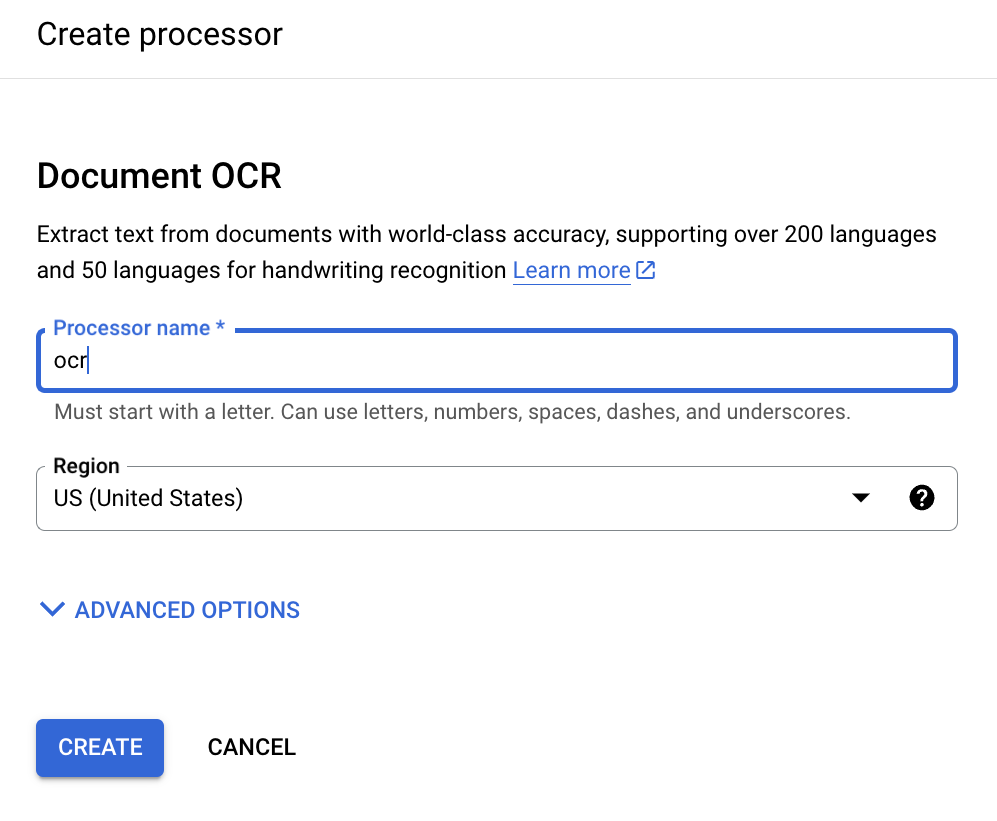
만들기를 클릭하고 프로세서 세부정보 페이지로 리디렉션되면 ID를 찾습니다.
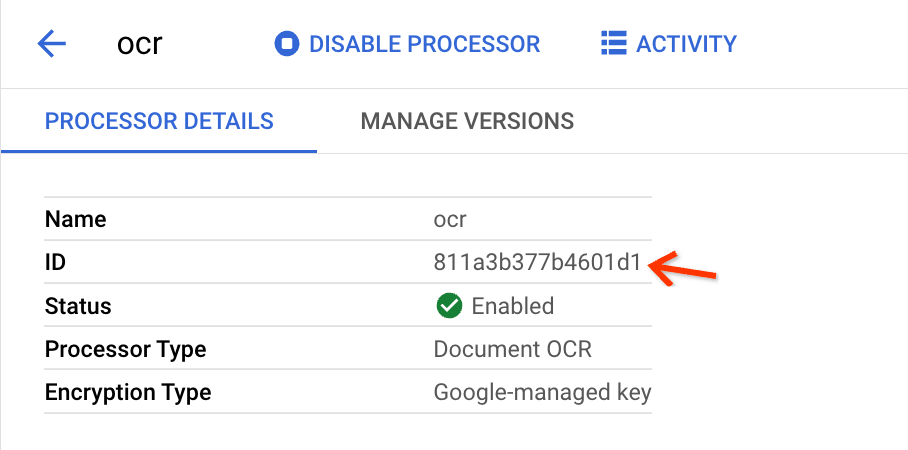
일괄 업로드 뷰의 입력 필드에 복사해야 하는 내용입니다.
일괄 업로드 트리거
일괄 업로드 보기를 엽니다.
새로 추가 옆에 있는 일괄 업로드를 클릭합니다.
올바른 프로세서를 찾습니다.
두 번째 전처리 옵션을 선택합니다.
스키마를 선택하고 추출 결과를 JSON 형식으로 저장할 프로세서와 Cloud Storage 버킷 경로를 지정합니다.
설명 텍스트의 링크를 통해 프로세서 ID를 찾습니다.
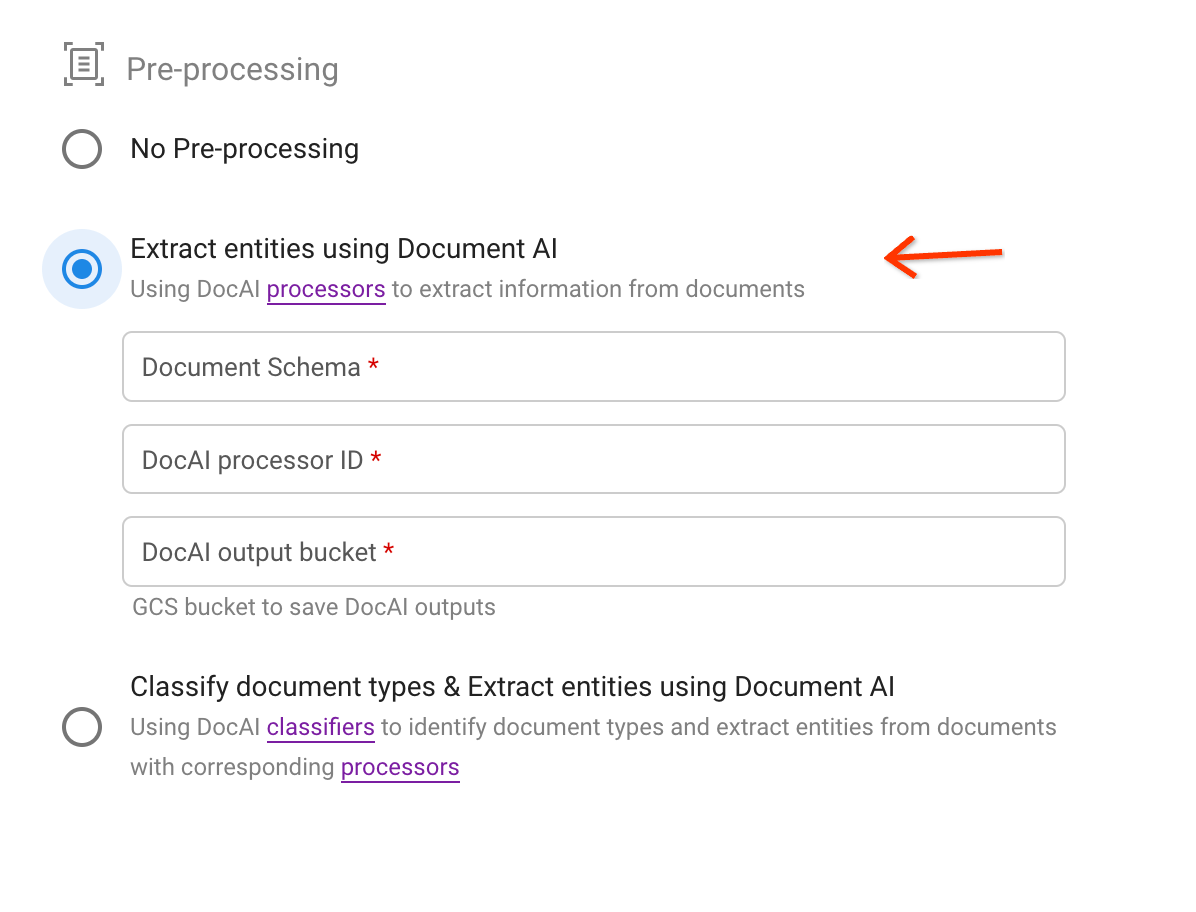
업로드 트리거:
이전 단계에서 복사한 프로세서 ID를 사용하여 입력 필드를 지정합니다. 소스 파일 버킷 경로는 버킷 또는 버킷의 폴더나 하위 폴더일 수 있습니다.
입력 필드가 유효하면 일괄 업로드를 트리거하기 위해 오른쪽 상단에서 업로드를 클릭합니다.
상태 페이지에서 진행 상황 확인
일괄 업로드가 트리거되면 상태 추적 페이지로 리디렉션됩니다.
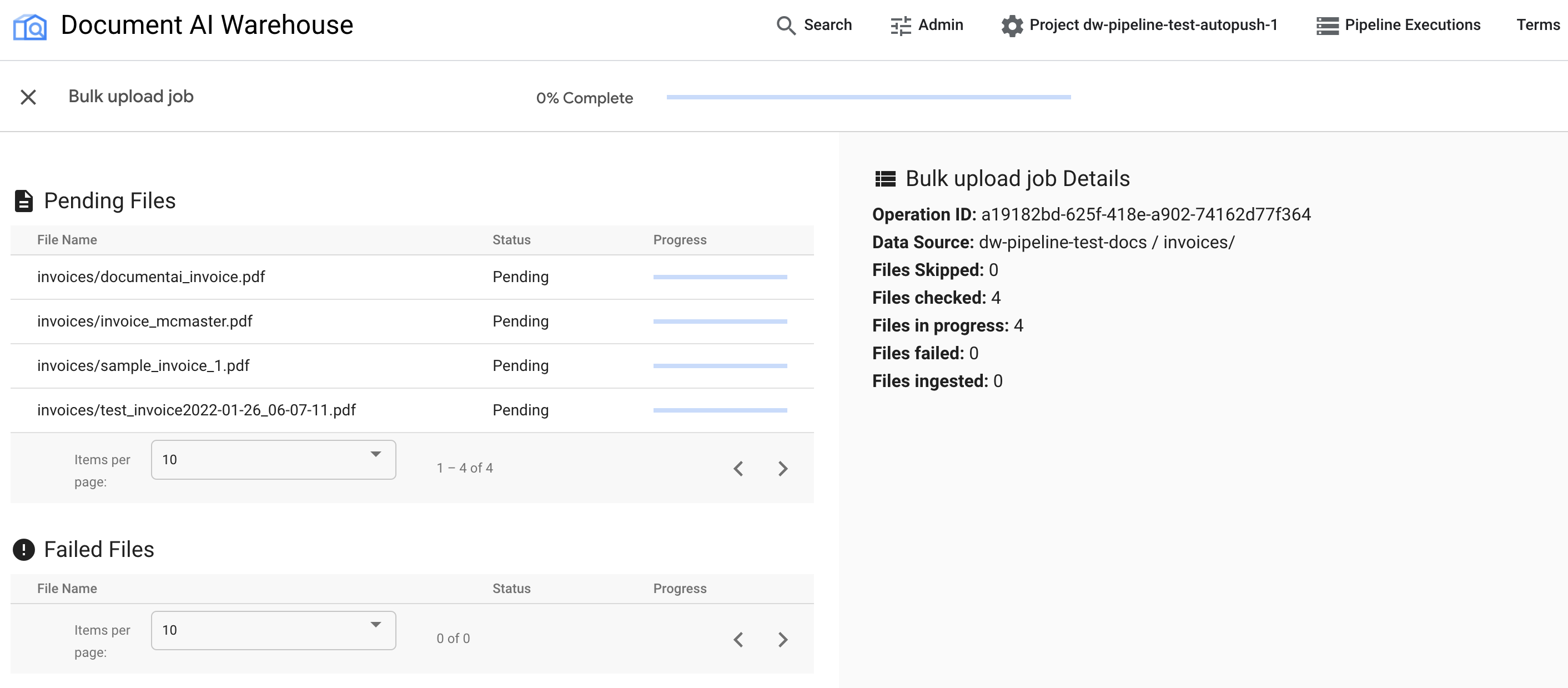
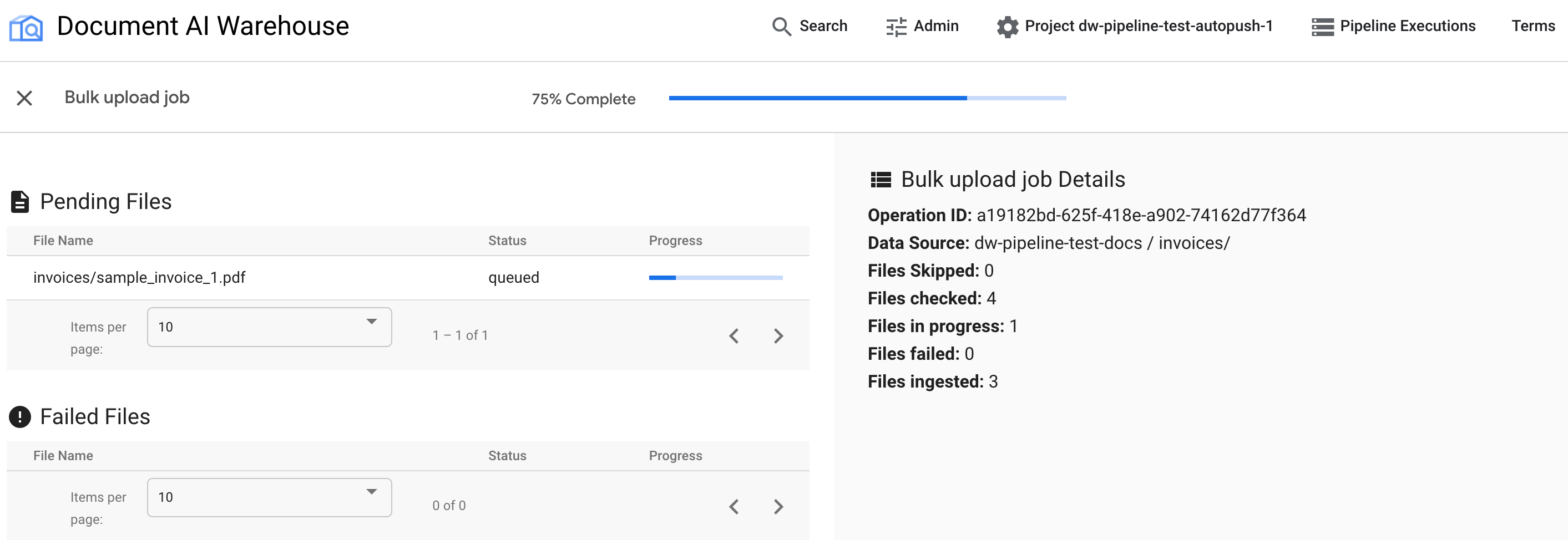
첫 번째 표에는 대기 중이거나 처리된 문서가 표시됩니다. 문서가 수집된 후에는 더 이상 첫 번째 표에 나열되지 않습니다. 업로드에 실패한 문서는 두 번째 표에 표시됩니다. 오른쪽에는 수집된 문서, 실패한 문서, 대기 중인 문서의 수가 표시됩니다.
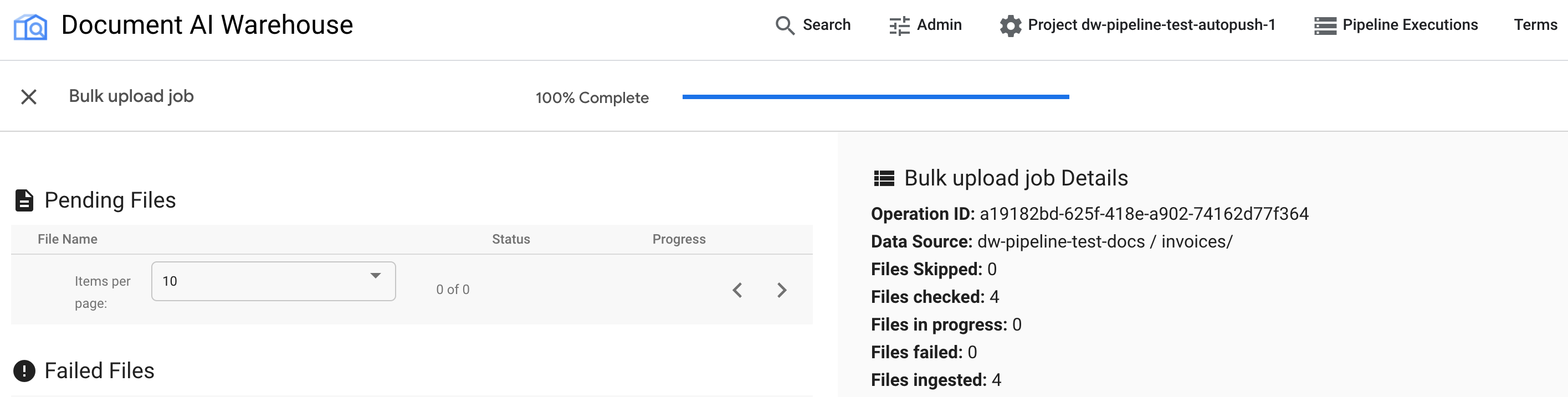
작업이 완료되면 상태 페이지에 보류 중인 문서 없이 100% 완료로 표시됩니다.
업로드된 문서 검토
검색 뷰로 돌아가 새로 수집된 문서를 찾습니다. 상단 탐색 메뉴에서 Document AI Warehouse 로고 또는 검색을 클릭합니다.

문서 이름을 클릭하여 새로 수집된 문서를 엽니다. 문서 뷰어에서 AI 뷰를 열 수 있습니다.
텍스트 블록 탭으로 이동합니다. OCR 결과는 문서에 저장됩니다.
다음 단계
Document AI로 추출 파이프라인을 사용하여 기존 문서를 업데이트합니다.