
Questo documento descrive come eseguire il caricamento collettivo, che attiva la pipeline di importazione di Cloud Storage in background.
Opzioni di pre-elaborazione
Al momento, il caricamento collettivo offre tre opzioni di pre-elaborazione:
Caricamento collettivo senza pre-elaborazione: attiva l'API runPipeline con GcsIngestPipeline senza elaborare i documenti con i processori Document AI.
Estrai entità con i processori Document AI: questo attiva l'API runPipeline con GcsIngestWithDocAiProcessorsPipeline. La pipeline chiamerà prima il processore Document AI specificato e poi importerà i documenti con i risultati elaborati.
Classifica i tipi di documenti ed estrai le entità per ogni tipo: questa operazione attiva anche l'API runPipeline con GcsIngestWithDocAiProcessorsPipeline, che prima chiama un classificatore. Poi, per ogni tipo di documento, puoi specificare uno schema e un processore corrispondenti per elaborare questi particolari tipi di documento. Vengono inseriti con i risultati e impostati su questo schema.
Ciascuno dei tipi di preelaborazione corrisponde alle seguenti opzioni nell'interfaccia utente:
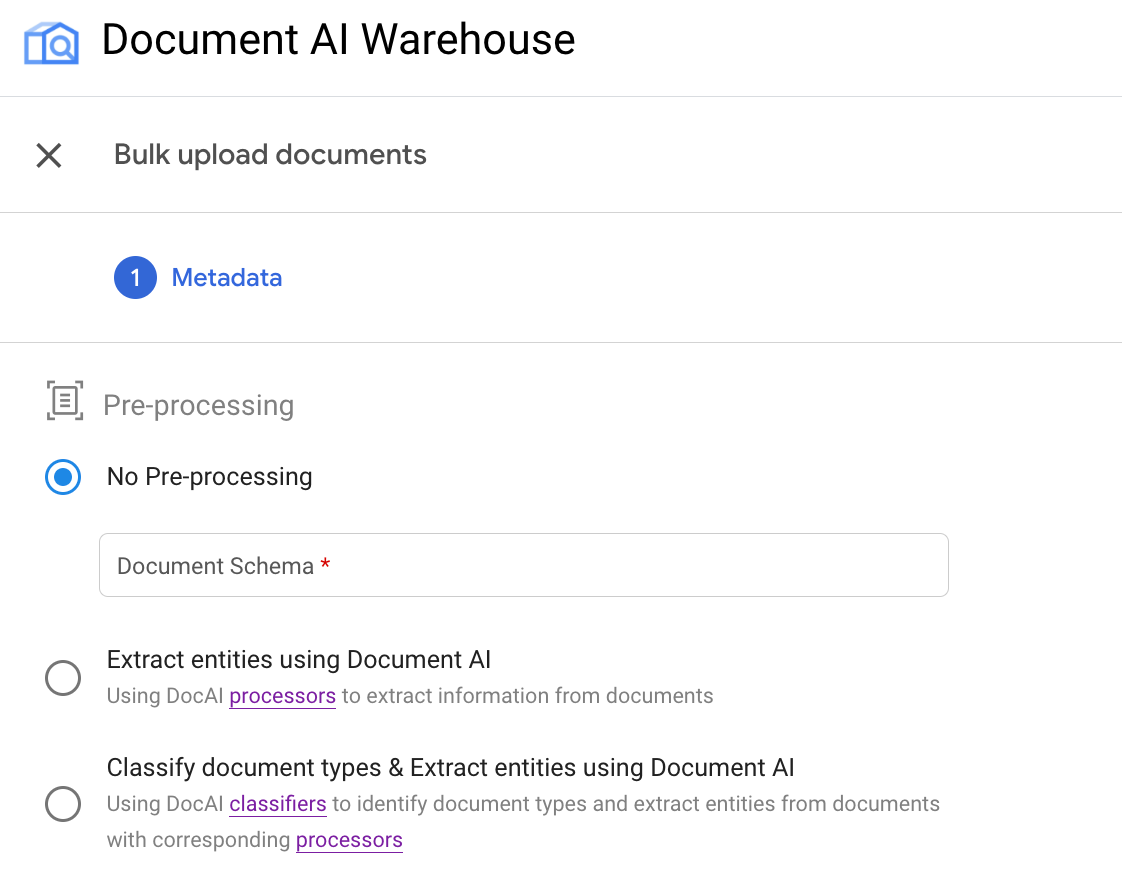
Esempio: attiva il caricamento collettivo con un processore OCR
Questo esempio illustra il secondo utilizzo della pipeline.
Crea un processore OCR e ottieni l'ID processore
Se hai già creato un processore OCR, cercalo nell'elenco dei processori, vai alla pagina dei dettagli del processore e recupera l'ID processore.
Se non ne hai ancora creato uno, segui questi passaggi:
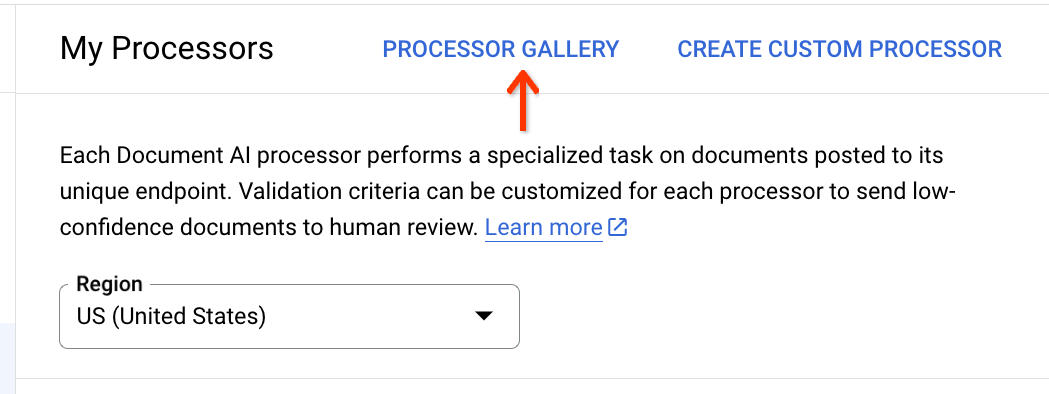
Nella parte superiore dell'elenco dei processori, fai clic sulla galleria dei processori:
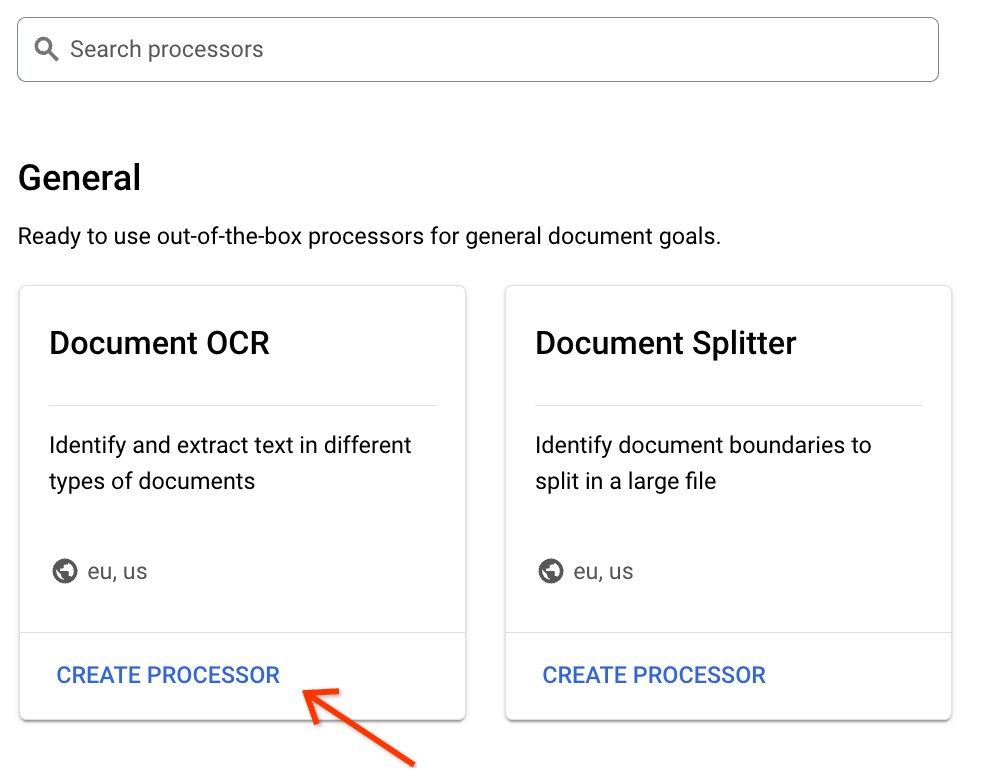
Trova il processore OCR di documenti nella galleria e, in fondo alla scheda, fai clic su Crea processore:
Inserisci un nome visualizzato per il processore:
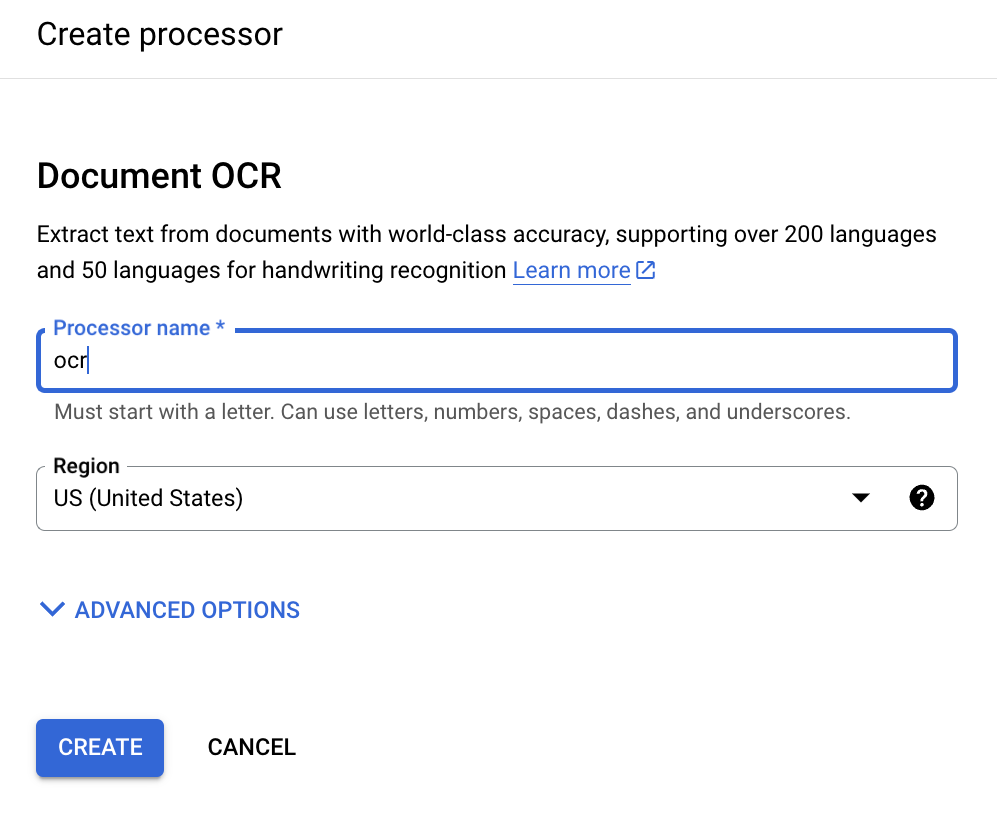
Fai clic su Crea e, quando viene visualizzata la pagina Dettagli del processore, trova l'ID:
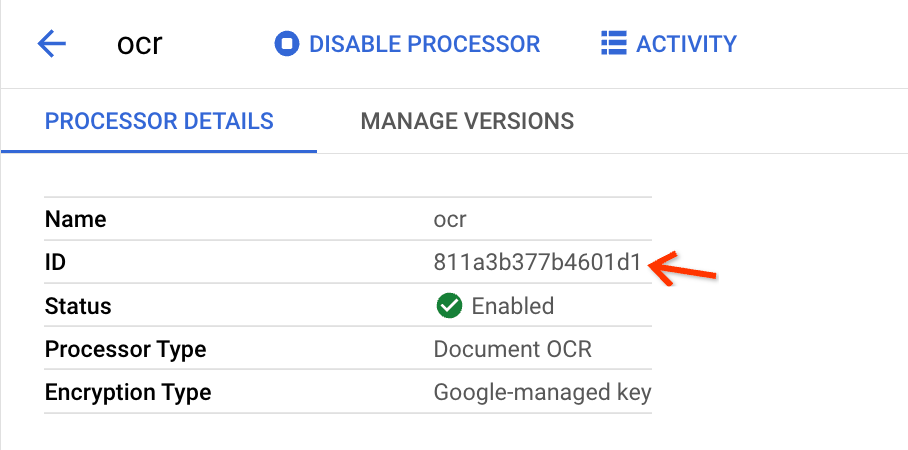
Queste sono le informazioni che devi copiare nei campi di input della visualizzazione del caricamento collettivo.
Attivare il caricamento collettivo
Apri la visualizzazione del caricamento collettivo.
Accanto ad Aggiungi nuovo, fai clic su Caricamento collettivo:
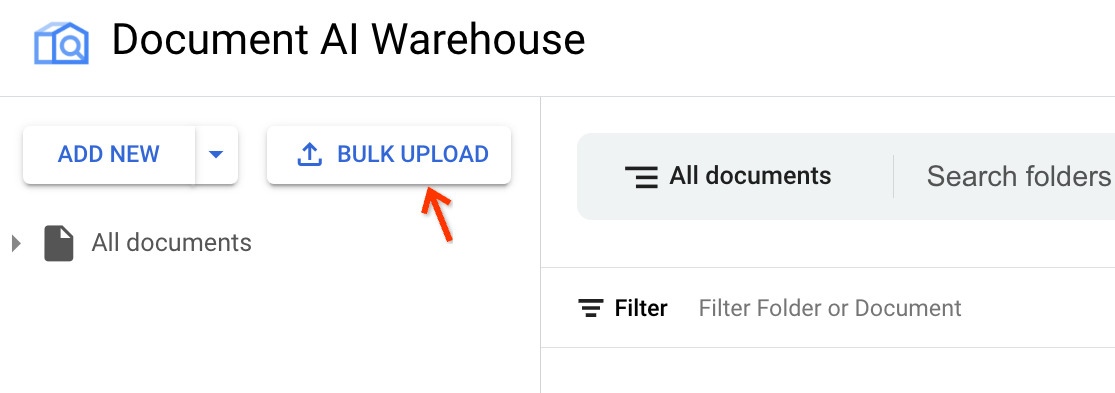
Trova il processore corretto.
Seleziona la seconda opzione di preelaborazione.
Scegli uno schema e specifica un processore e un percorso del bucket Cloud Storage per salvare i risultati dell'estrazione in formato JSON.
Trova l'ID processore tramite il link nel testo della descrizione:
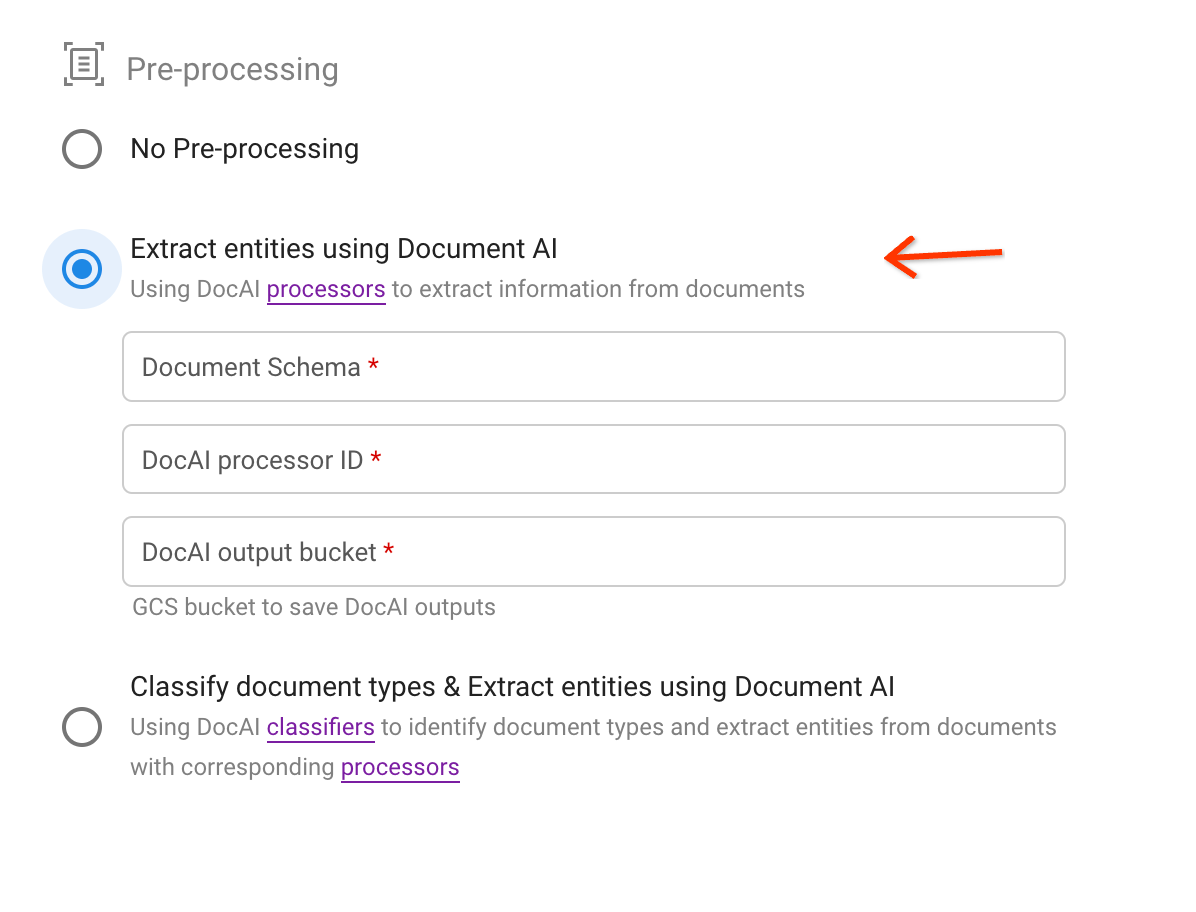
Attiva caricamento:
Con l'ID processore copiato dall'ultimo passaggio, specifica i campi di input. Il percorso del bucket del file di origine può essere un bucket o una cartella o una sottocartella nel bucket.
Quando i campi di input sono validi, per attivare il caricamento collettivo, fai clic su Carica in alto a destra.
Controllare l'avanzamento nella pagina di stato
Una volta attivato il caricamento collettivo, viene visualizzata la pagina di monitoraggio dello stato:
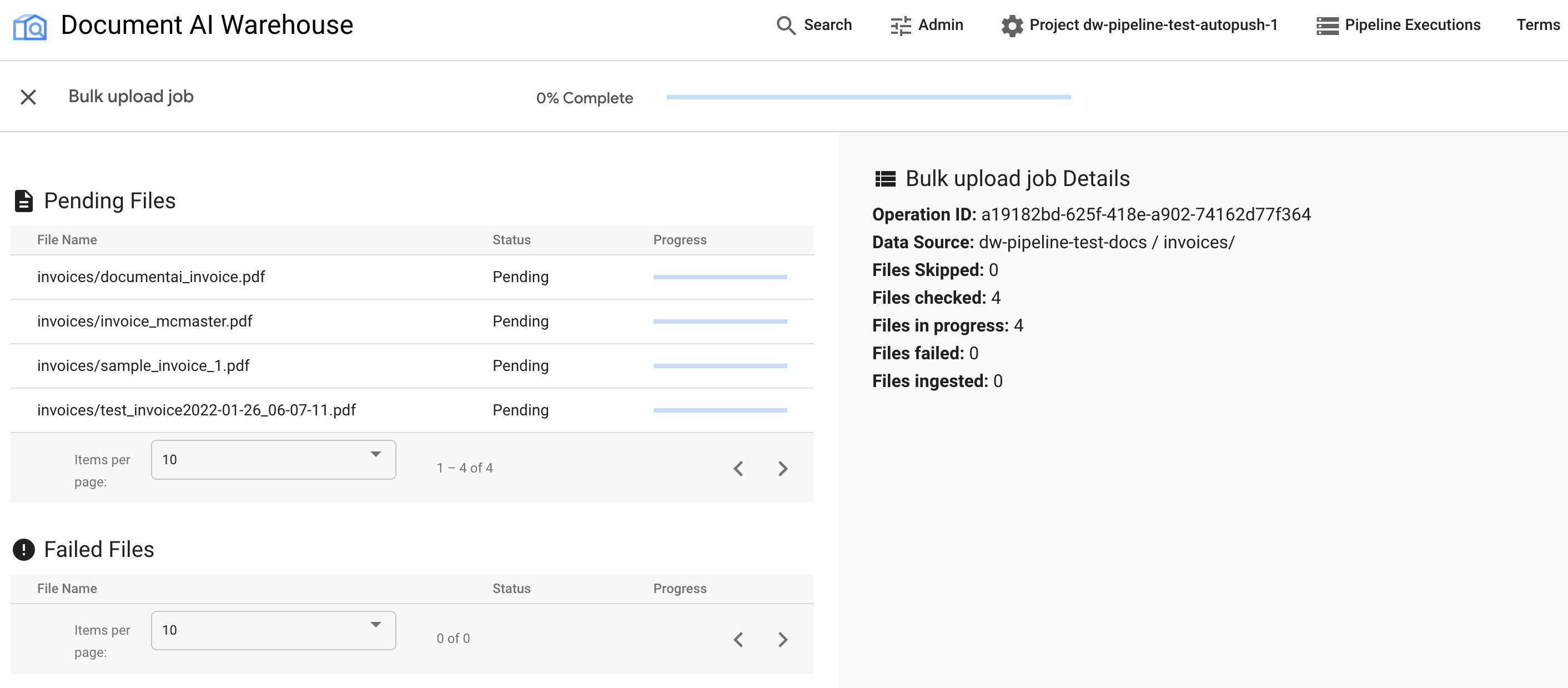
La prima tabella mostra i documenti in attesa o elaborati. Una volta inserito, il documento non viene più elencato nella prima tabella. I documenti che non sono stati caricati vengono visualizzati nella seconda tabella. A destra, le statistiche mostrano il numero di documenti caricati, non riusciti e in attesa.
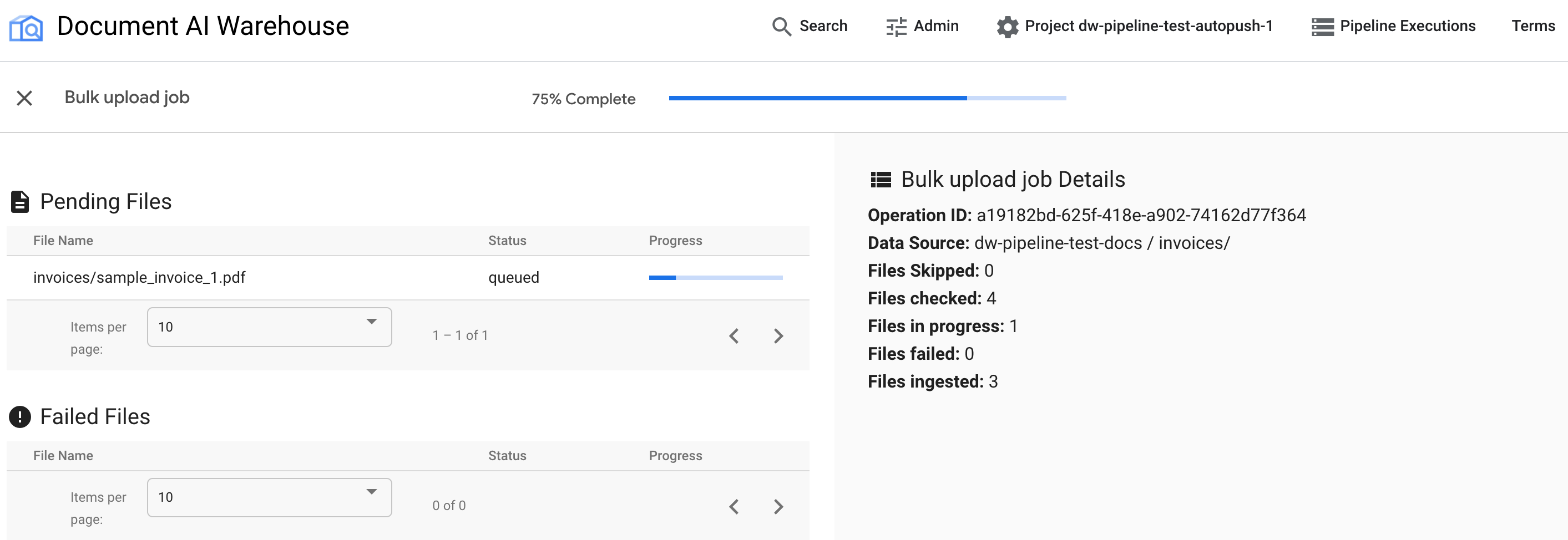
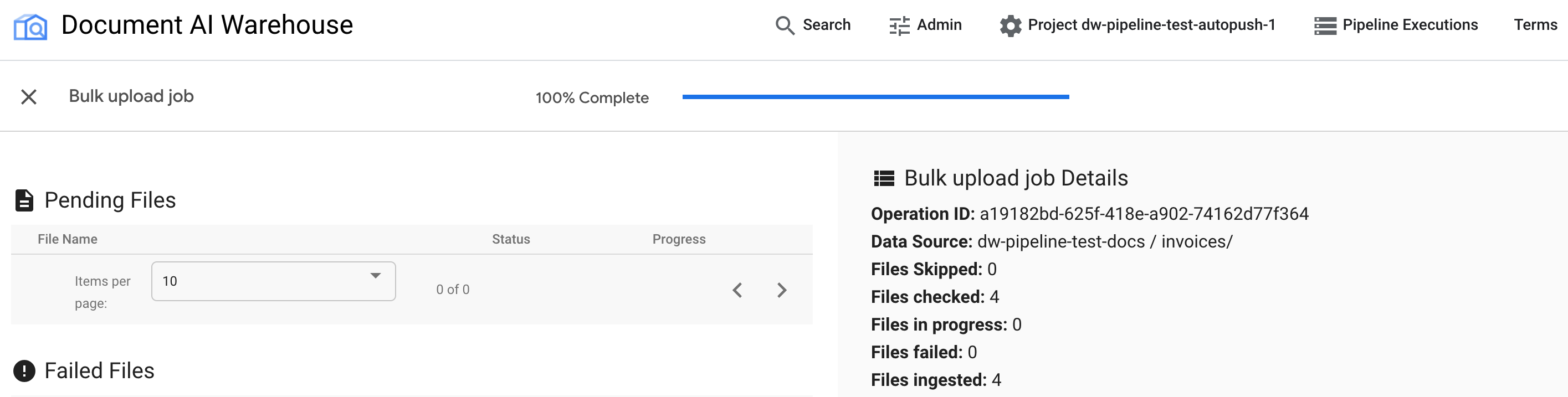
Al termine del job, la pagina di stato mostra il completamento al 100% senza documenti in attesa:
Esaminare i documenti caricati
Trova i documenti appena caricati tornando alla visualizzazione di ricerca. Fai clic sul logo di Document AI Warehouse o su Cerca nella barra di navigazione in alto:

Apri uno dei documenti appena caricati facendo clic sul nome del documento. Nel visualizzatore di documenti, puoi aprire la visualizzazione AI.
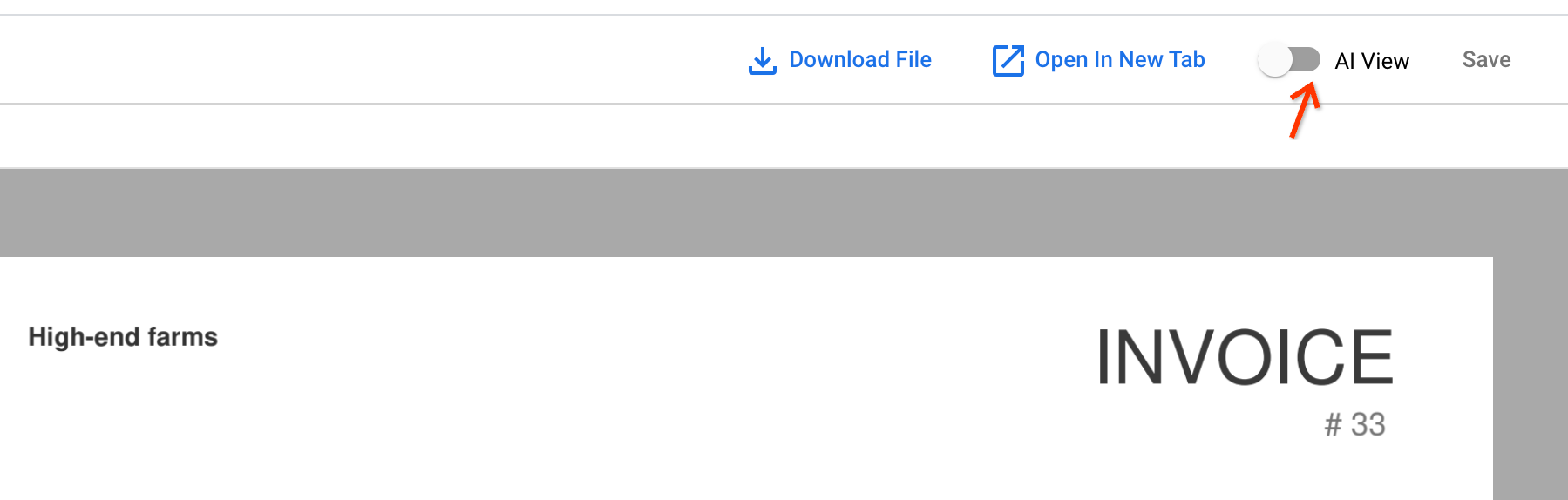
Vai alla scheda Blocco di testo. I risultati dell'OCR sono archiviati nel documento:
Passaggio successivo
Aggiorna i documenti esistenti con la pipeline di estrazione con Document AI.