
Dokumen ini menjelaskan cara melakukan upload massal, yang memicu pipeline penyerapan Cloud Storage di balik layar.
Opsi praproses
Saat ini, upload massal menyediakan tiga opsi praproses:
Upload massal tanpa pra-pemrosesan: Hal ini memicu runPipeline API dengan GcsIngestPipeline tanpa memproses dokumen dengan pemroses Document AI.
Mengekstrak entitas dengan prosesor Document AI: Tindakan ini memicu API runPipeline dengan GcsIngestWithDocAiProcessorsPipeline. Pipeline akan memanggil pemroses Document AI yang diberikan terlebih dahulu, lalu menyerap dokumen dengan hasil yang diproses.
Mengklasifikasikan jenis dokumen dan mengekstrak entitas untuk setiap jenis: Hal ini juga memicu API runPipeline dengan GcsIngestWithDocAiProcessorsPipeline, yang pertama-tama memanggil pengklasifikasi. Kemudian, untuk setiap jenis dokumen, Anda dapat menentukan skema dan pemroses yang sesuai untuk memproses jenis dokumen tertentu tersebut. Data tersebut di-ingest dengan hasil dan ditetapkan ke skema ini.
Setiap jenis praproses sesuai dengan opsi berikut di UI:
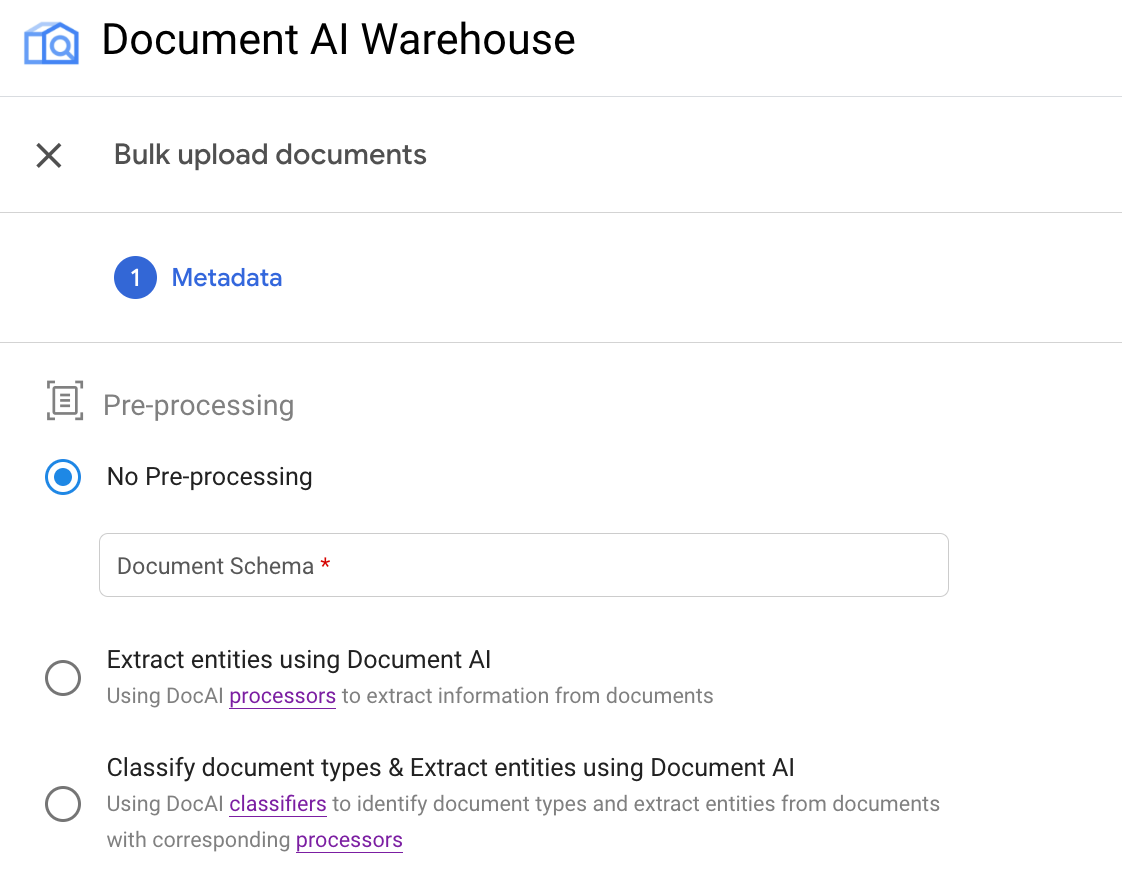
Contoh: Memicu upload massal dengan pemroses OCR
Contoh ini mengilustrasikan penggunaan pipeline kedua.
Membuat pemroses OCR dan mendapatkan ID pemroses
Jika Anda telah membuat pemroses OCR sebelumnya, cukup temukan di daftar pemroses, lalu buka halaman detail pemroses dan dapatkan ID pemroses.
Jika Anda belum membuatnya, ikuti langkah-langkah berikut:
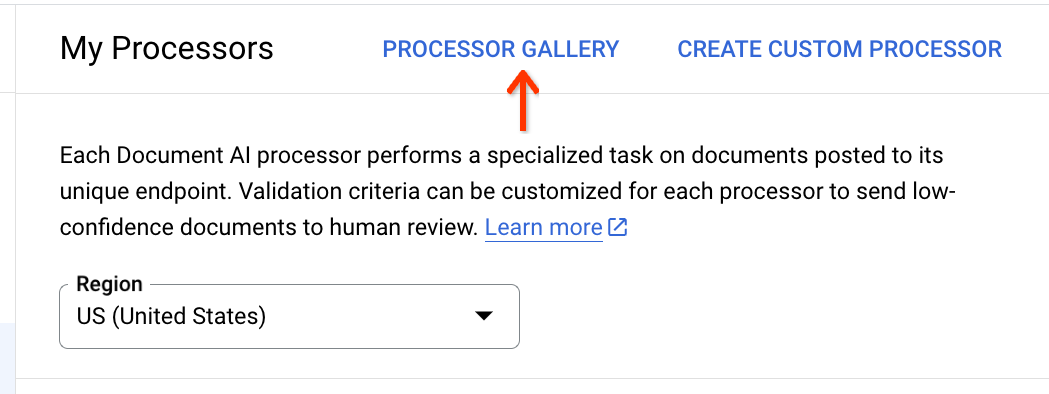
Di bagian atas daftar pemroses, klik Galeri Pemroses:
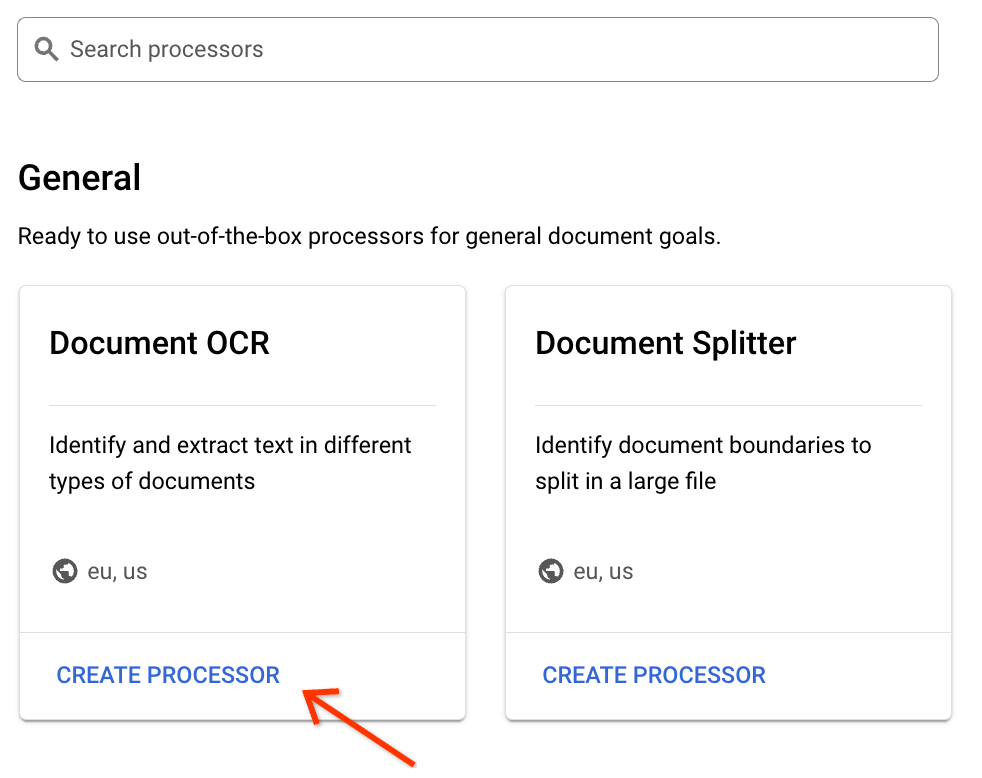
Temukan pemroses Document OCR di galeri, lalu di bagian bawah kartu, klik Create Processor:
Masukkan nama tampilan prosesor:
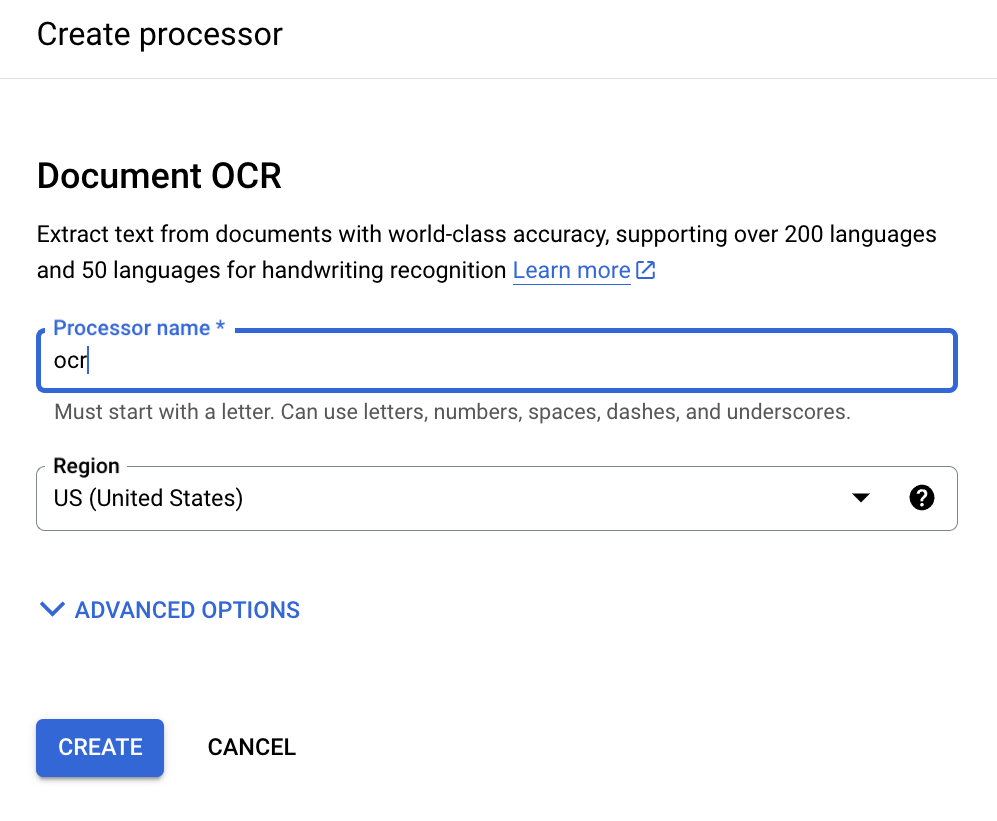
Klik Buat dan saat Anda dialihkan ke halaman Detail Pemroses, temukan ID:
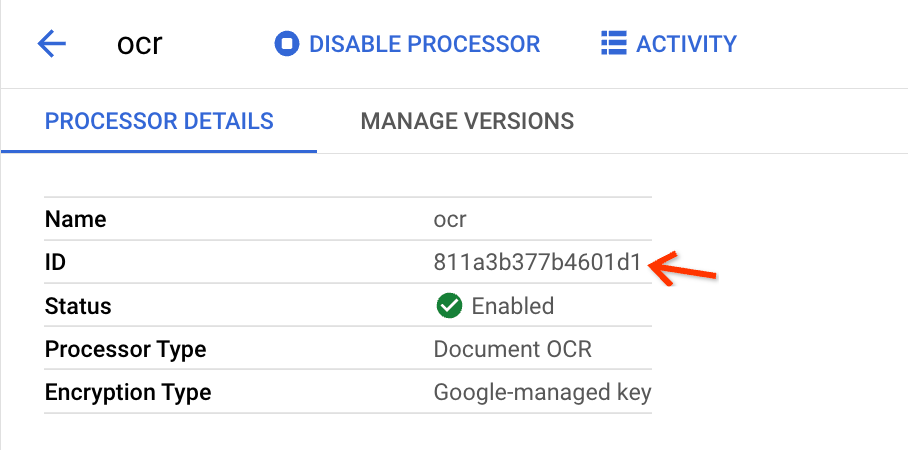
Inilah yang perlu Anda salin ke kolom input di tampilan upload massal.
Memicu upload massal
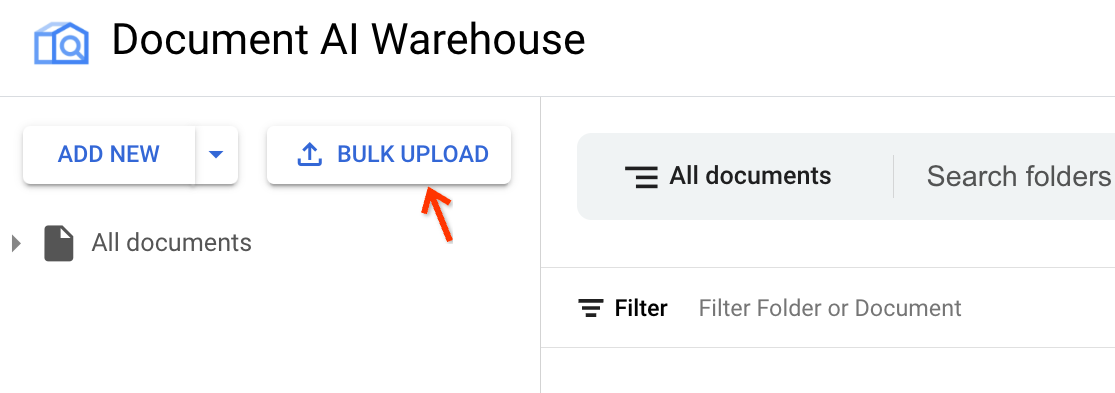
Buka tampilan upload massal.
Di samping Tambahkan Baru, klik Upload Massal:
Temukan prosesor yang benar.
Pilih opsi praproses kedua.
Pilih skema dan tentukan jalur bucket Cloud Storage dan prosesor untuk menyimpan hasil ekstraksi dalam format JSON.
Temukan ID prosesor melalui link di teks deskripsi:
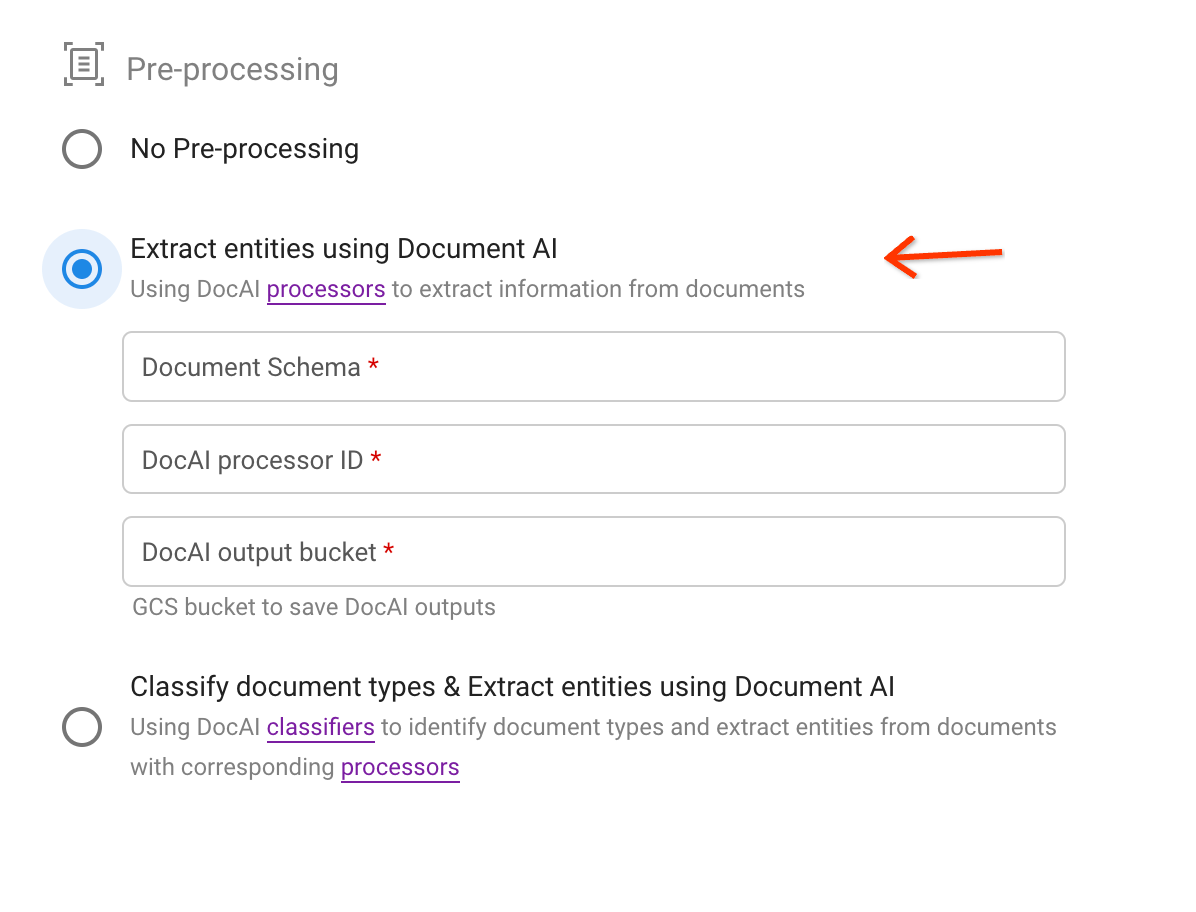
Pemicu upload:
Dengan ID prosesor yang disalin dari langkah terakhir, tentukan kolom input. Jalur bucket file sumber dapat berupa bucket atau folder atau subfolder dalam bucket.
Jika kolom input valid, untuk memicu upload massal, klik Upload di kanan atas.
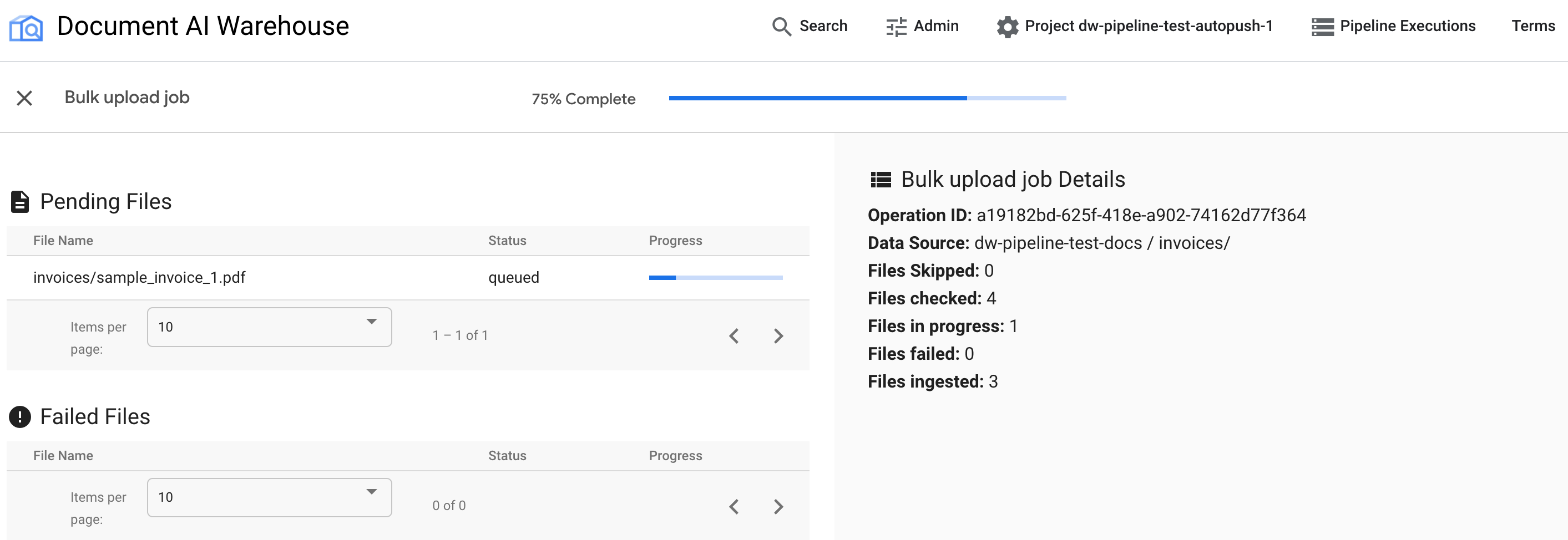
Memeriksa progres di halaman status
Setelah upload massal dipicu, Anda akan dialihkan ke halaman pelacakan status:
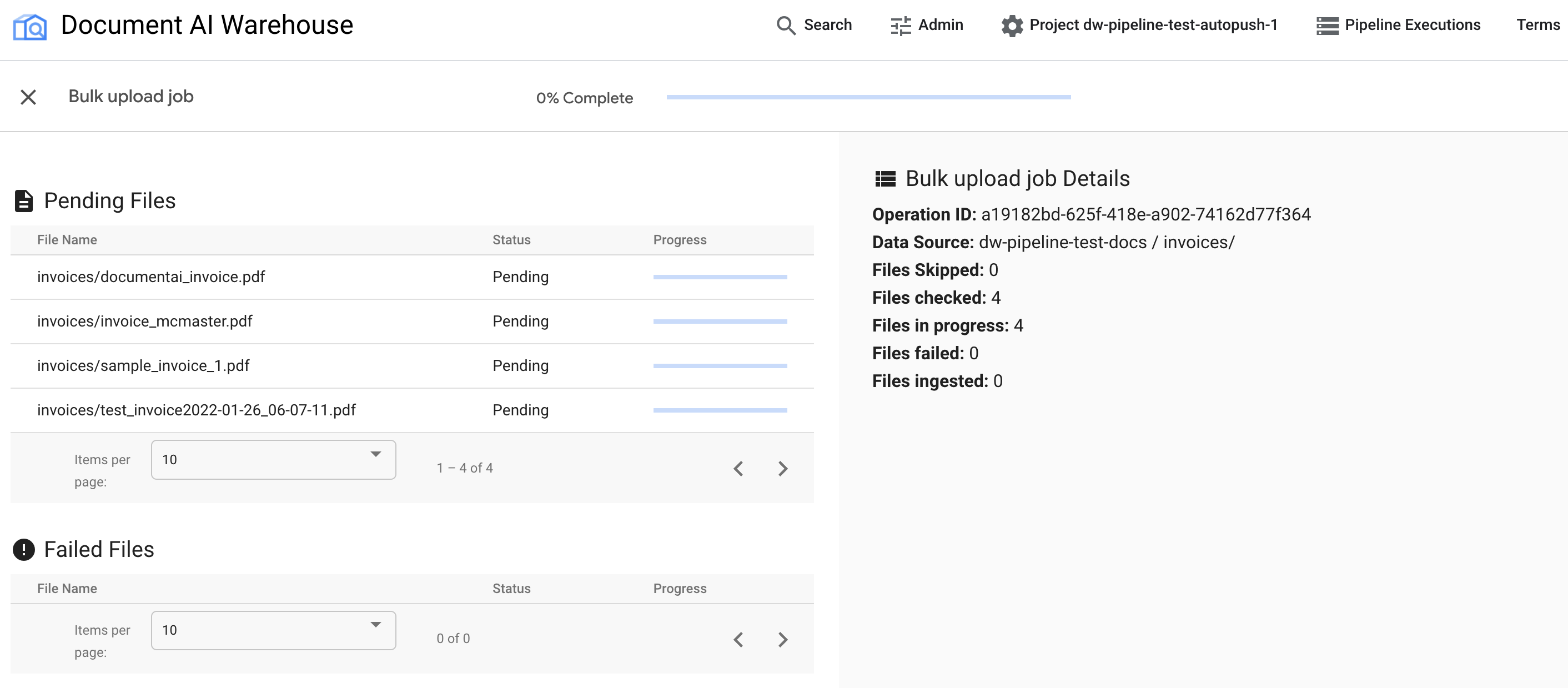
Tabel pertama menampilkan dokumen yang tertunda atau diproses. Setelah diserap, dokumen tidak lagi tercantum dalam tabel pertama. Dokumen yang gagal diupload akan muncul di tabel kedua. Di sebelah kanan, statistik menampilkan jumlah dokumen yang diproses, gagal, dan tertunda.
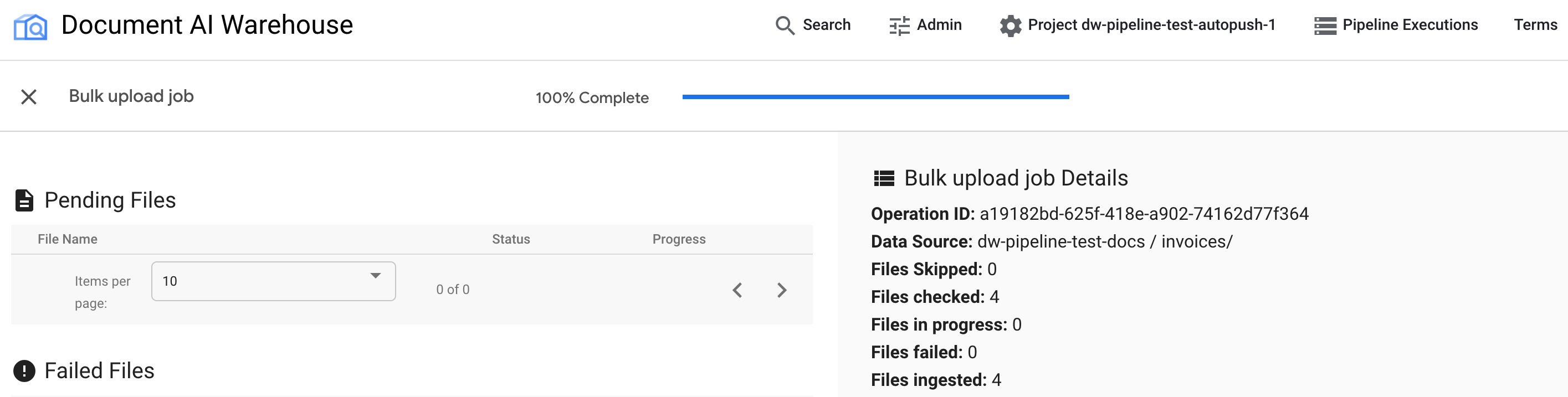
Setelah tugas selesai, halaman status akan menampilkan 100% selesai tanpa ada dokumen yang tertunda:
Memeriksa dokumen yang diupload
Temukan dokumen yang baru di-ingest dengan kembali ke tampilan penelusuran. Klik logo Document AI Warehouse atau Penelusuran di menu navigasi atas:

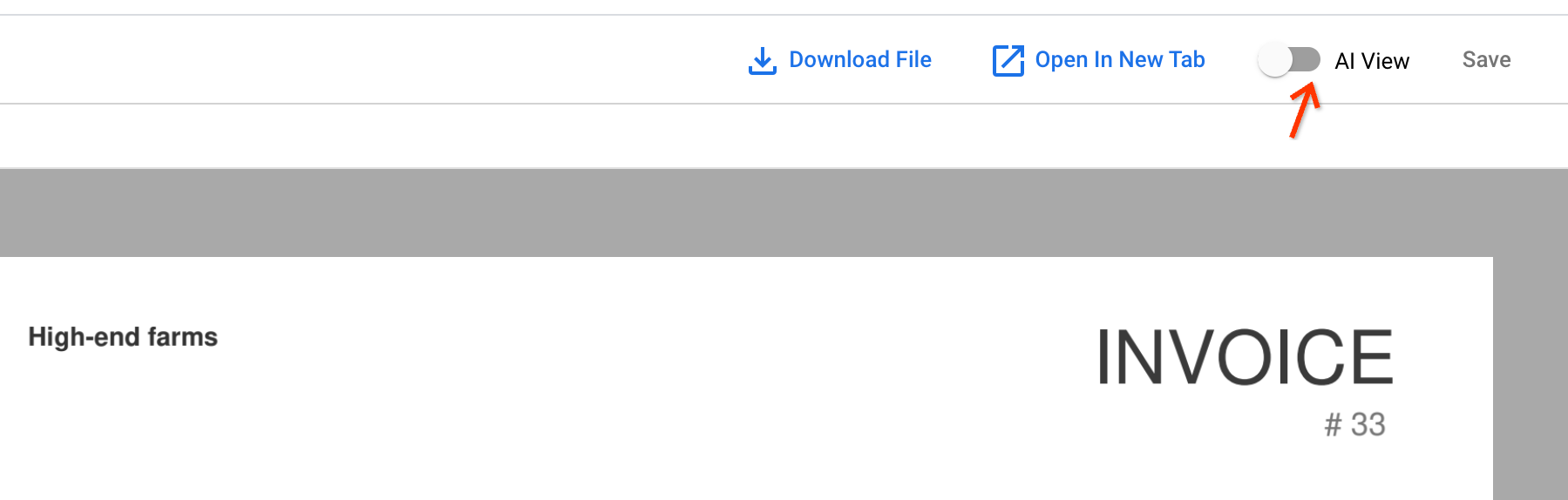
Buka salah satu dokumen yang baru di-ingest dengan mengklik nama dokumen. Di penampil dokumen, Anda dapat membuka Tampilan AI.
Buka tab Blok teks. Hasil OCR disimpan dalam dokumen:
Langkah berikutnya
Perbarui dokumen yang ada dengan extract with Document AI pipeline.