
Ce document explique comment effectuer une importation groupée, ce qui déclenche le pipeline d'ingestion Cloud Storage en arrière-plan.
Options de prétraitement
L'importation groupée fournit actuellement trois options de prétraitement :
Importation groupée sans prétraitement : déclenche l'API runPipeline avec GcsIngestPipeline sans traiter les documents avec les processeurs Document AI.
Extraire des entités avec les processeurs Document AI : ceci déclenche l'API runPipeline avec GcsIngestWithDocAiProcessorsPipeline. Le pipeline appelle d'abord le processeur Document AI donné, puis ingère les documents avec les résultats traités.
Classer les types de documents et extraire les entités pour chaque type : déclenche également l'API runPipeline avec GcsIngestWithDocAiProcessorsPipeline, qui appelle d'abord un classifieur. Ensuite, pour chaque type de document, vous pouvez spécifier un schéma et un processeur correspondants pour traiter ces types de documents spécifiques. Ils sont ingérés avec les résultats et définis sur ce schéma.
Chacun des types de prétraitement correspond aux options suivantes dans l'interface utilisateur :
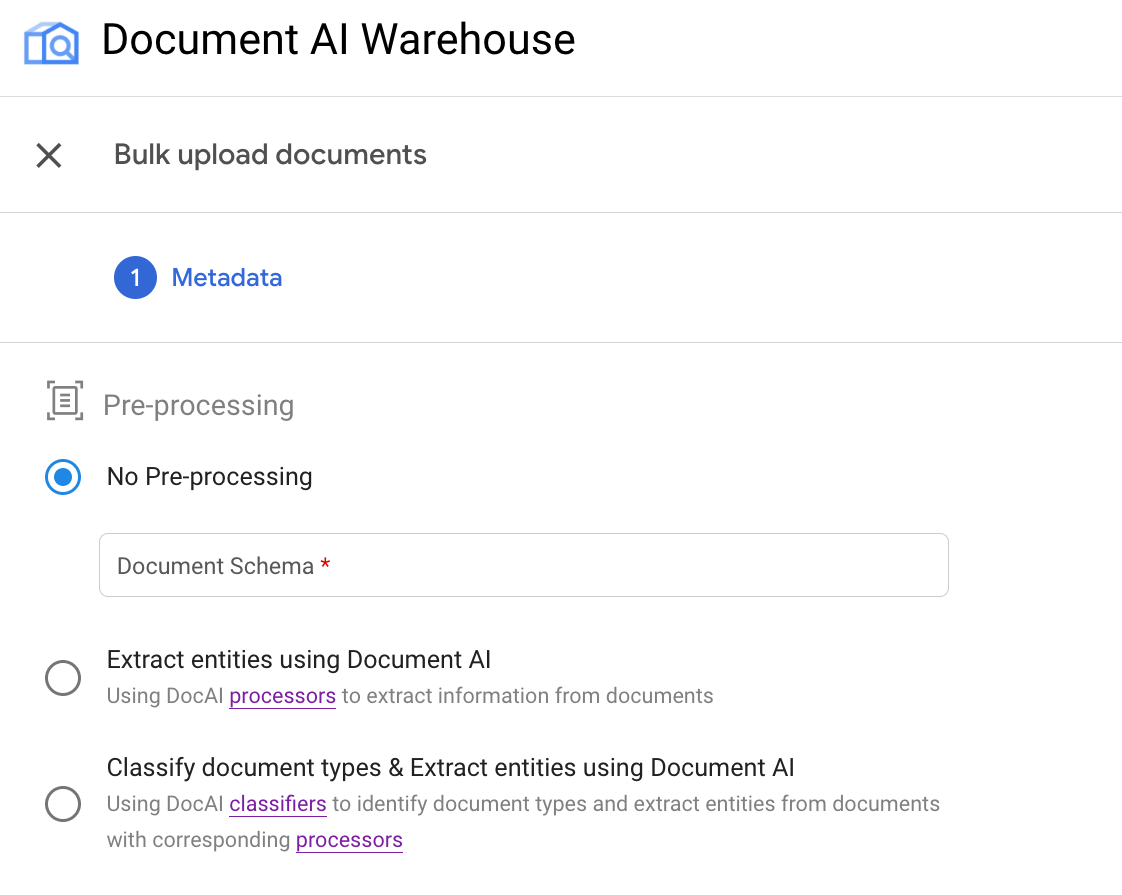
Exemple : Déclencher une importation groupée avec un processeur OCR
Cet exemple illustre la deuxième utilisation du pipeline.
Créer un processeur OCR et obtenir l'ID du processeur
Si vous avez déjà créé un processeur OCR, il vous suffit de le trouver dans la liste des processeurs, d'accéder à la page de détails du processeur et d'obtenir l'ID du processeur.
Si vous n'en avez pas créé, procédez comme suit :
En haut de la liste des processeurs, cliquez sur Galerie de processeurs :
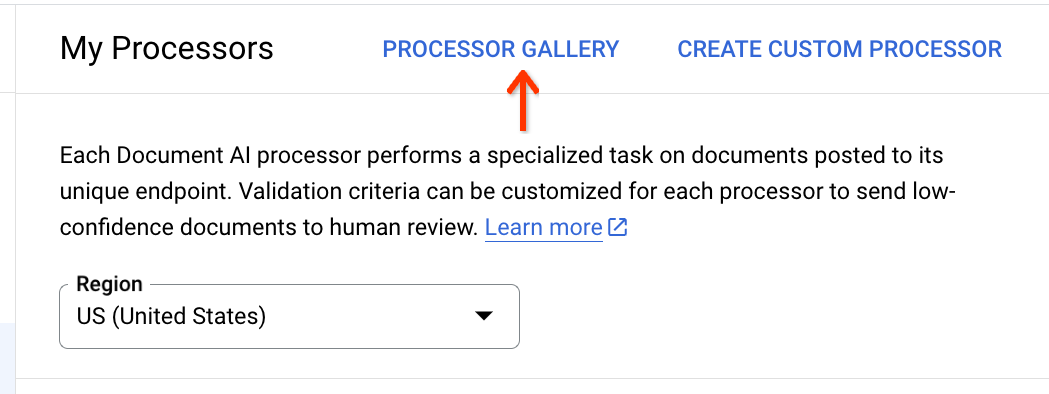
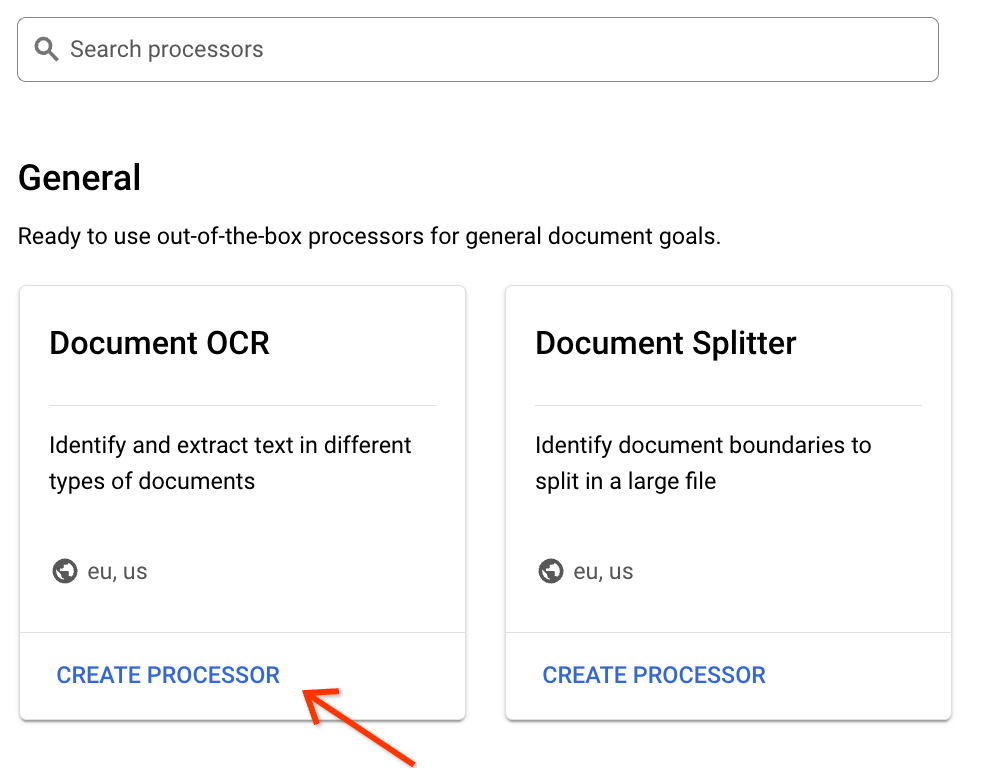
Recherchez le processeur OCR dans les documents dans la galerie, puis en bas de la fiche, cliquez sur Créer un processeur:
Saisissez un nom à afficher pour le processeur :
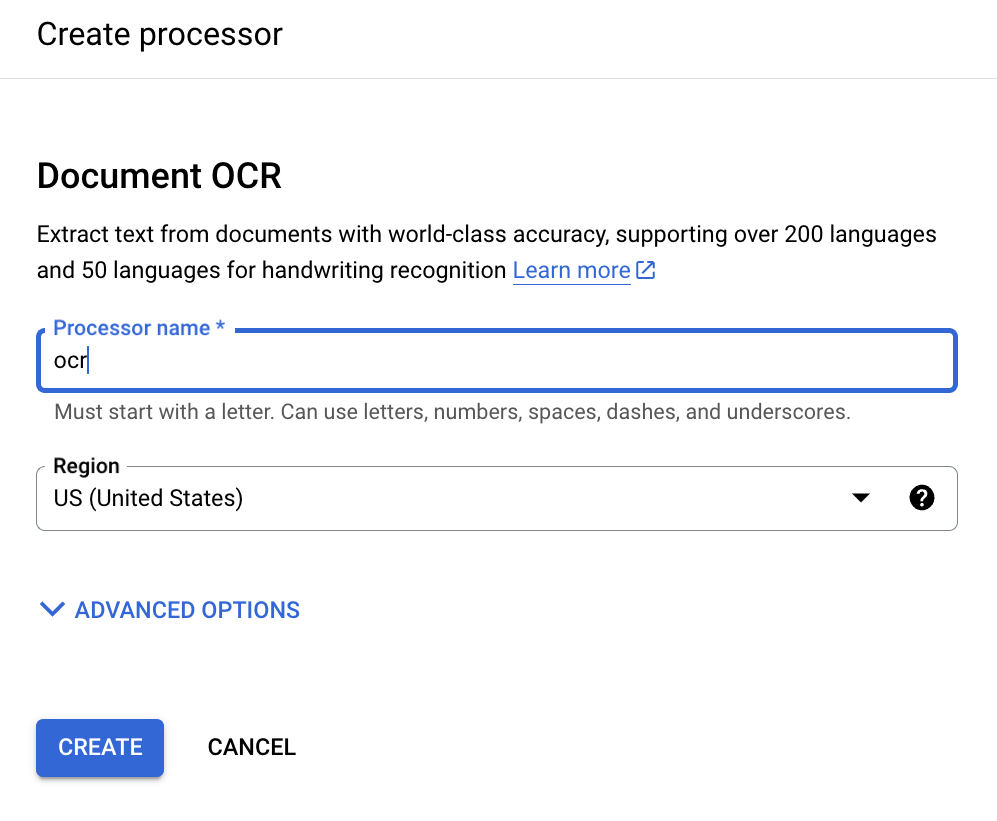
Cliquez sur Créer , puis lorsque vous êtes redirigé vers la page Détails du processeur , recherchez l'ID :
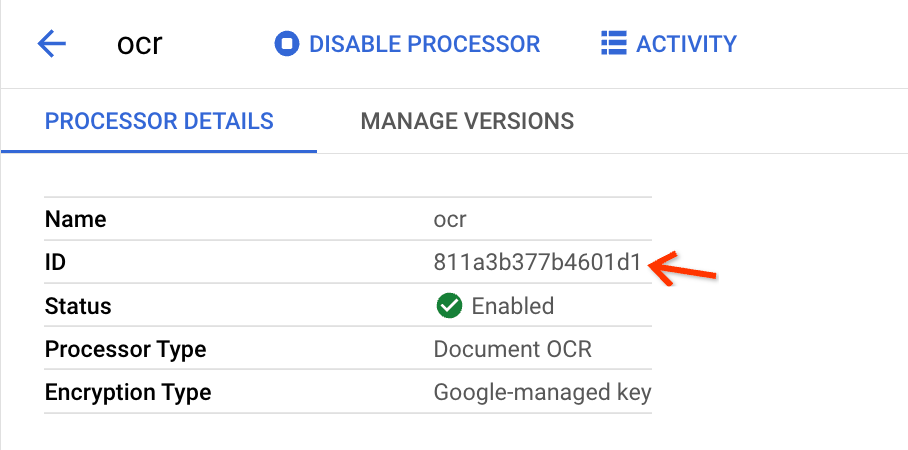
Vous devez copier ces informations dans les champs d'entrée de la vue d'importation groupée.
Déclencher une importation groupée
Ouvrez la vue d'importation groupée.
À côté de Ajouter, cliquez sur Importation groupée :
Recherchez le processeur approprié.
Sélectionnez la deuxième option de prétraitement.
Choisissez un schéma, puis spécifiez un processeur et un chemin de bucket Cloud Storage pour enregistrer les résultats de l'extraction au format JSON.
Recherchez l'ID du processeur via le lien dans le texte de description :
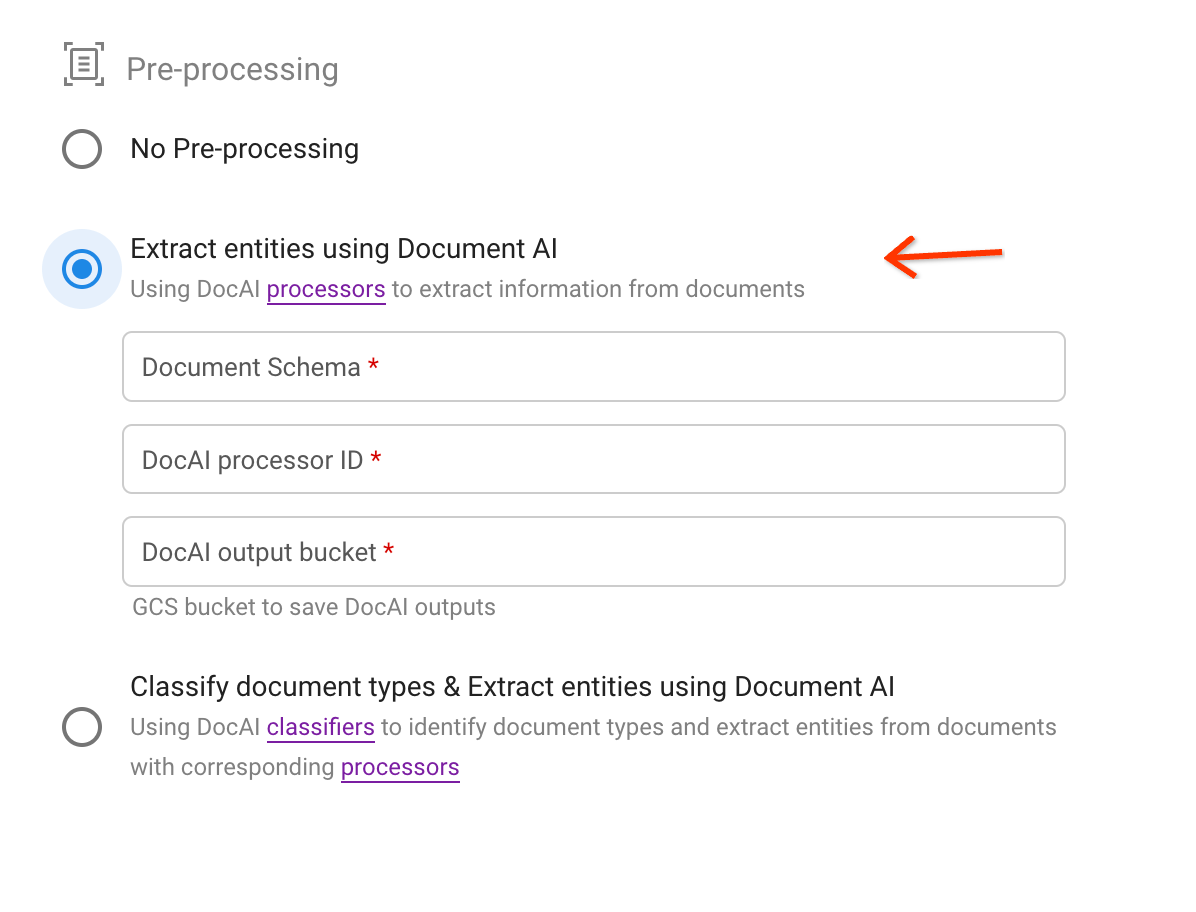
Déclenchez l'importation :
Une fois l'ID du processeur copié à l'étape précédente, spécifiez les champs d'entrée. Le chemin du bucket du fichier source peut être un bucket, un dossier ou un sous-dossier dans le bucket.
Lorsque les champs d'entrée sont valides, pour déclencher l'importation groupée, en haut à droite, cliquez sur Importer.
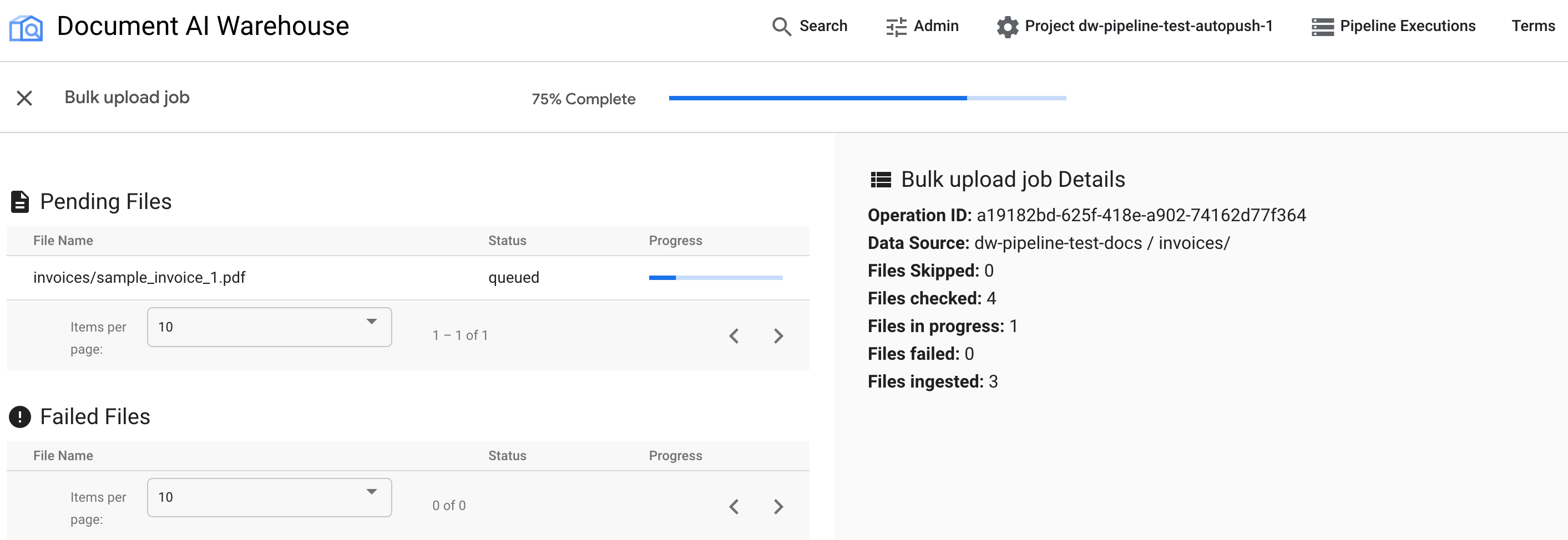
Vérifier la progression sur la page d'état
Une fois l'importation groupée déclenchée, vous êtes redirigé vers la page de suivi de l'état :
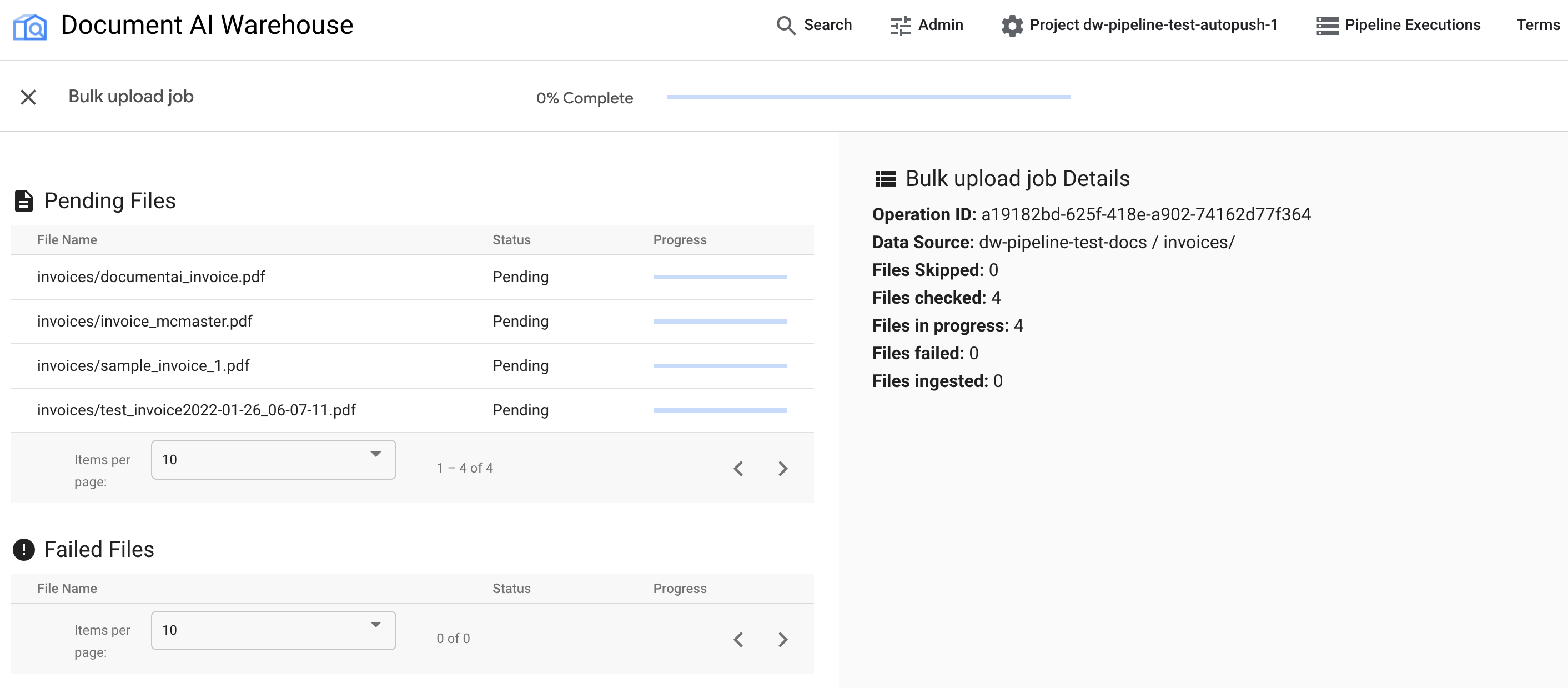
Le premier tableau affiche tous les documents en attente ou traités. Une fois ingéré, le document n'est plus listé dans le premier tableau. Les documents qui n'ont pas pu être importés apparaissent dans le deuxième tableau. À droite, les statistiques indiquent le nombre de documents ingérés, en échec et en attente.
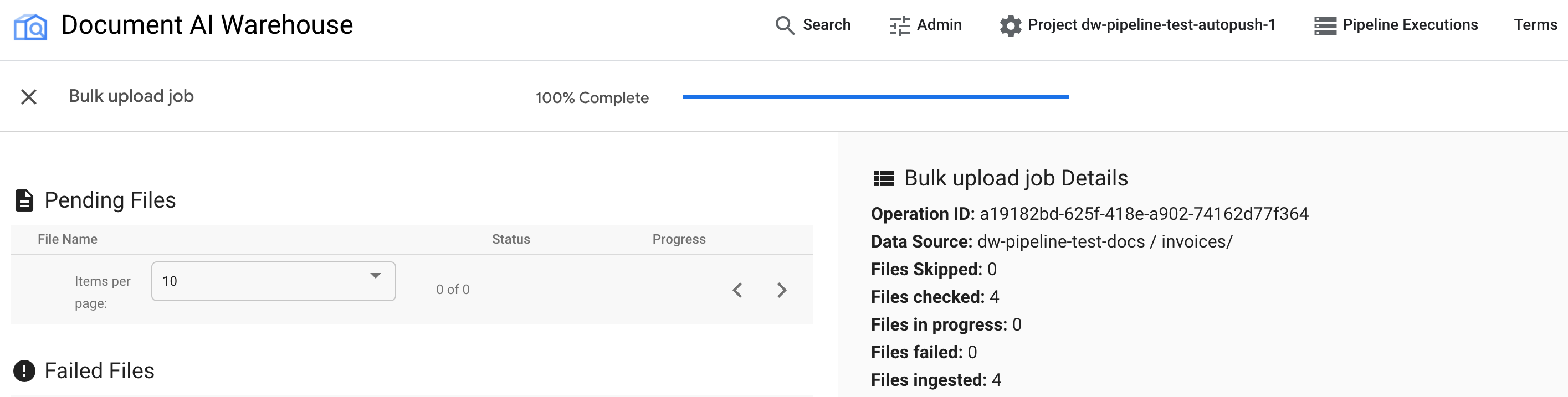
Une fois la tâche terminée, la page d'état affiche 100 % sans aucun document en attente :
Examiner les documents importés
Recherchez les documents nouvellement ingérés en revenant à la vue de recherche. Cliquez sur le logo Document AI Warehouse ou sur Rechercher dans la barre de navigation en haut :

Ouvrez l'un des documents nouvellement ingérés en cliquant sur son nom. Dans le lecteur de documents, vous pouvez ouvrir la vue IA.
Accédez à l'onglet Bloc de texte. Les résultats de l'OCR sont stockés dans le document :
Étape suivante
Mettez à jour les documents existants avec l'extraction à l'aide du pipeline Document AI.