
BigQuery コネクタの概要
BigQuery コネクタを使用すると、Document AI ウェアハウスに保存されているドキュメントのメタデータ (プロパティを含む)を BigQuery テーブルにエクスポートできます。BigQuery にデータを取り込むと、分析を実行したり、レポートやダッシュボードを作成してビジネス上の意思決定に役立てることができます。
BigQuery コネクタを有効にするには、必要な権限が付与された BigQuery テーブルを設定し、API を使用して非同期タスクを構成する必要があります。BigQuery コネクタは、Document AI ウェアハウスから BigQuery テーブルにデータをエクスポートします。
始める前に
Document AI ウェアハウスを設定し、ドキュメントを取り込みます。詳細については、クイックスタートをご覧ください。
BigQuery テーブルをホストするプロジェクトが、Document AI ウェアハウスでドキュメントの保存に使用されるプロジェクトと同じであることを確認する必要があります。つまり、データは常に同じプロジェクト内の Document AI ウェアハウスから BigQuery テーブルにエクスポートする必要があります。
プロジェクトで Owner(roles/owner)ロールが付与されているか、resourcemanager.projects.getIamPolicy と resourcemanager.projects.setIamPolicy
権限が付与されている必要があります。
BigQuery アクセスを設定する
サービス アカウント doc-ai-warehouse-dw-bq-connector@system.gserviceaccount.com
を BigQuery Admin ロールにバインドします。
gcloud projects add-iam-policy-binding <var>PROJECT_ID</var> --member serviceAccount:doc-ai-warehouse-dw-bq-connector@system.gserviceaccount.com --role=roles/bigquery.admin
BigQuery データセットとテーブルを設定する
Document AI ウェアハウスがデータをエクスポートするための BigQuery データセットとテーブルを設定します。BigQuery データセットがない場合は、 データセットの作成に沿って作成します。
BigQuery データセットに BigQuery テーブルを作成します。BigQuery の手順に沿って、DDL サンプル ステートメントを使用してテーブルを作成します。
CREATE TABLE `PROJECT_ID.DATASET_NAME.TABLE_NAME`
(
project_number INT64,
location STRING,
mod_type STRING,
document_id STRING,
document_json JSON,
create_time TIMESTAMP,
creator STRING,
update_time TIMESTAMP,
updater STRING,
document_state STRING,
export_time TIMESTAMP
)
PARTITION BY TIMESTAMP_TRUNC(export_time, HOUR)
OPTIONS(
partition_expiration_days=150,
description="table partitioned by export_time on hour with expiry"
);
DDL により、新しい BigQuery テーブルが作成されます。テーブルは 1 時間ごとにパーティション分割され、パーティションは 150 日後に削除されます。
BigQuery コネクタを構成する
データ エクスポート構成を作成する
次の手順では、新しいデータ エクスポート ジョブを作成します。これにより、データをエクスポートする非同期ジョブが設定されます。新しいデータ エクスポート ジョブごとに空のテーブルから始めることをおすすめします。構成の詳細については、API リファレンス をご覧ください。
次の実行オプションがあります。これらは FREQUENCY を使用して構成できます。
API
リファレンスをご覧ください。
- ADHOC: ジョブは 1 回のみ実行されます。すべてのデータが BigQuery テーブルにエクスポートされます。
- DAILY: ジョブは毎日実行されます。初回実行時には、すべてのデータが BigQuery テーブルにエクスポートされます。初回エクスポートが完了すると、前日のデータの変更(または最後に同期が成功した時点からの差分)のみが BigQuery テーブルにエクスポートされます。
- HOURLY: ジョブは 1 時間ごとに実行されます。初回実行時には、すべてのデータが BigQuery テーブルにエクスポートされます。初回エクスポートが完了すると、前時間のデータの変更(または最後に同期が成功した時点からの差分)のみが BigQuery テーブルにエクスポートされます。
リクエストのデータを使用する前に、 次のように置き換えます。
- PROJECT_NUMBER: あなたの Google Cloud プロジェクト番号
- LOCATION:Document AI ウェアハウスのロケーション(`us` など)。
- DATASET_LOCATION: データセットのロケーション。
- DATASET_NAME: データセットの名前。
- TABLE_NAME: テーブルの名前。
-
FREQUENCY:
ADHOC、DAILY、HOURLYのいずれか。
リクエストの本文(JSON):
{
"projectNumber": PROJECT_NUMBER,
"location": "DATASET_LOCATION",
"dataset": "DATASET_NAME",
"table": "TABLE_NAME",
"frequency": "FREQUENCY",
"state": "ACTIVE"
}
リクエストを送信するには、次のいずれかのオプションを展開します。
次のような JSON レスポンスが返されます。
ジョブの実行
ジョブが正常に作成されると、構成に基づいてジョブが実行されます。ジョブの実行には時間がかかるため、非同期で実行されます。エクスポートするデータの量によっては、初回実行が完了するまでに時間がかかることがあります。毎日実行されるジョブの場合、結果が BigQuery テーブルに表示されるまでに 24 時間かかります。
データ エクスポート構成を削除する
次のコマンドは、作成したジョブを削除(アーカイブ)します。
リクエストのデータを使用する前に、 次のように置き換えます。
- PROJECT_NUMBER: あなたの Google Cloud プロジェクト番号
- LOCATION:Document AI ウェアハウスのロケーション(`us` など)。
- JOB_ID: 作成時にレスポンスで返されたジョブ ID。
リクエストの本文(JSON):
{}
リクエストを送信するには、次のいずれかのオプションを展開します。
次のような JSON レスポンスが返されます。
これで、エクスポート ジョブが削除(アーカイブ)され、Document AI ウェアハウスで実行されなくなります。
BigQuery に取り込まれたデータを探索する
分析のニーズに合わせて、ドキュメントのメタデータとプロパティを BigQuery の個別のテーブル フィールドに抽出するには、次の DDL クエリを使用します。抽出されたフィールドは、データポータルや BI ダッシュボード ツールで使用して、データ内の関係を可視化することもできます。
document_json からキーフィールドを抽出する
このクエリは、データ エクスポートから関連するフィールド(document_json フィールドに保存されているドキュメント メタデータのキーフィールドを含む)を選択します。
DROP VIEW IF EXISTS
`DATASET_NAME.VIEW_NAME_1`;
CREATE VIEW
`DATASET_NAME.VIEW_NAME_1` AS
SELECT
project_number,
document_id,
mod_type,
create_time,
update_time,
location,
creator,
updater,
document_state,
SPLIT(JSON_EXTRACT_SCALAR(document_json,'$.documentSchemaName' ), '/')[SAFE_OFFSET(ARRAY_LENGTH(SPLIT(JSON_EXTRACT_SCALAR(document_json,'$.documentSchemaName' ), '/')) - 1)] AS document_schema_name,
JSON_EXTRACT_SCALAR(document_json,'$.name') AS document_name,
JSON_EXTRACT_SCALAR(document_json,'$.rawDocumentFileType')
AS raw_document_file_type,
JSON_EXTRACT(document_json,'$.properties') AS properties
FROM
`DATASET_NAME.SYSTEM_METADATA_AND_DOC_PROPERTIES_TABLE_EXPORT_NAME`;
document_json からプロパティをネスト解除する
このクエリは、ドキュメント メタデータ(document_json)からプロパティをネスト解除して、キーと値のペア(プロパティ名、値)を作成します。これらのキーと値のペアは、次のクエリで個別のテーブル フィールドに変換され、プロパティ レベルのデータ探索とダッシュボードの可視化が可能になります。
DROP VIEW IF EXISTS
`DATASET_NAME.VIEW_NAME_2`;
CREATE VIEW
`DATASET_NAME.VIEW_NAME_2` AS
SELECT
* EXCEPT(key_value_pair,
properties,raw_document_file_type)
FROM (
SELECT
*,
REPLACE(JSON_VALUE(key_value_pair,'$.name'),'/','-') property_name,
-- Note: values are either text OR float values
CASE
WHEN JSON_VALUE(key_value_pair,'$.textValues.values[0]') IS NULL THEN JSON_VALUE(key_value_pair,'$.floatValues.values[0]')
ELSE
JSON_VALUE(key_value_pair,'$.textValues.values[0]')
END
AS value,
CASE
WHEN raw_document_file_type IS NULL THEN "RAW_DOCUMENT_FILE_TYPE_UNSPECIFIED"
ELSE
raw_document_file_type
END
AS document_file_type
FROM
`DATASET_NAME.VIEW_NAME_1`,
UNNEST(JSON_EXTRACT_ARRAY(properties)) AS key_value_pair);
document_json からプロパティをピボットして BigQuery にテーブル フィールドを作成する
次の手順では、プロパティと関連する値をピボットして、すべてのドキュメント プロパティが個別のテーブル フィールドとして変換されたテーブルを作成します。このテーブルの結果を活用して、データポータルや他の BI 可視化ツールで後続のクエリを実行することで、さらに分析情報を得ることができます。
DECLARE
property_field STRING;
-- Extracting distinct property_names from the previous view and storing it in property_field, declared above
EXECUTE IMMEDIATE
"""SELECT string_agg(CONCAT("'",property_name,"'")) from (select distinct property_name from DATASET.VIEW_NAME_2)""" INTO property_field;
DROP TABLE IF EXISTS `DATASET_NAME.ANALYTICS_TABLE_NAME`;
-- Creating pivot table with the aid of extracted distinct property_names
-- Casting numerical values to float/int
-- Pivot on property_name and value (ie. create a new column for each of the property_name, substitute the value)
EXECUTE IMMEDIATE
FORMAT ("""
CREATE TABLE `DATASET_NAME.ANALYTICS_TABLE_NAME` AS
SELECT * FROM `DATASET_NAME.VIEW_NAME_2`
PIVOT(min(value) FOR property_name IN (%s))""", property_field);
データ クリーニングと変換の手順(ビジネス ケース固有)
BigQuery に取り込まれたデータによっては、詳細な分析を行うために、追加のデータ クリーニングと変換の手順が必要になる場合があります。 このような手順はケースごとに(データセットごとに)異なり、必要に応じて実行する必要があります。
データ クリーニングの手順の例を次に示します(これらに限定されません)。
- 日付形式の統一。
- プロパティ値の統合。
- データ型の文字列、浮動小数点数、整数へのキャストなど。
データポータルでデータを可視化する
BigQuery でデータの抽出、クレンジング、変換が完了したら、最終的なデータセットをデータポータルにエクスポートして視覚的に分析できます。
Looker ダッシュボード
サンプル ダッシュボードには、データセットから作成できる可視化の例が示されています。このシナリオでは、Document AI ウェアハウスからのサンプルデータ エクスポートは、W2 と請求書(2 つのスキーマ)で構成されています。
サンプルビュー: Document AI ウェアハウスの分析の概要
次のダッシュボードでは、Document AI ウェアハウス インスタンスに取り込まれたさまざまなドキュメントの概要を確認できます。
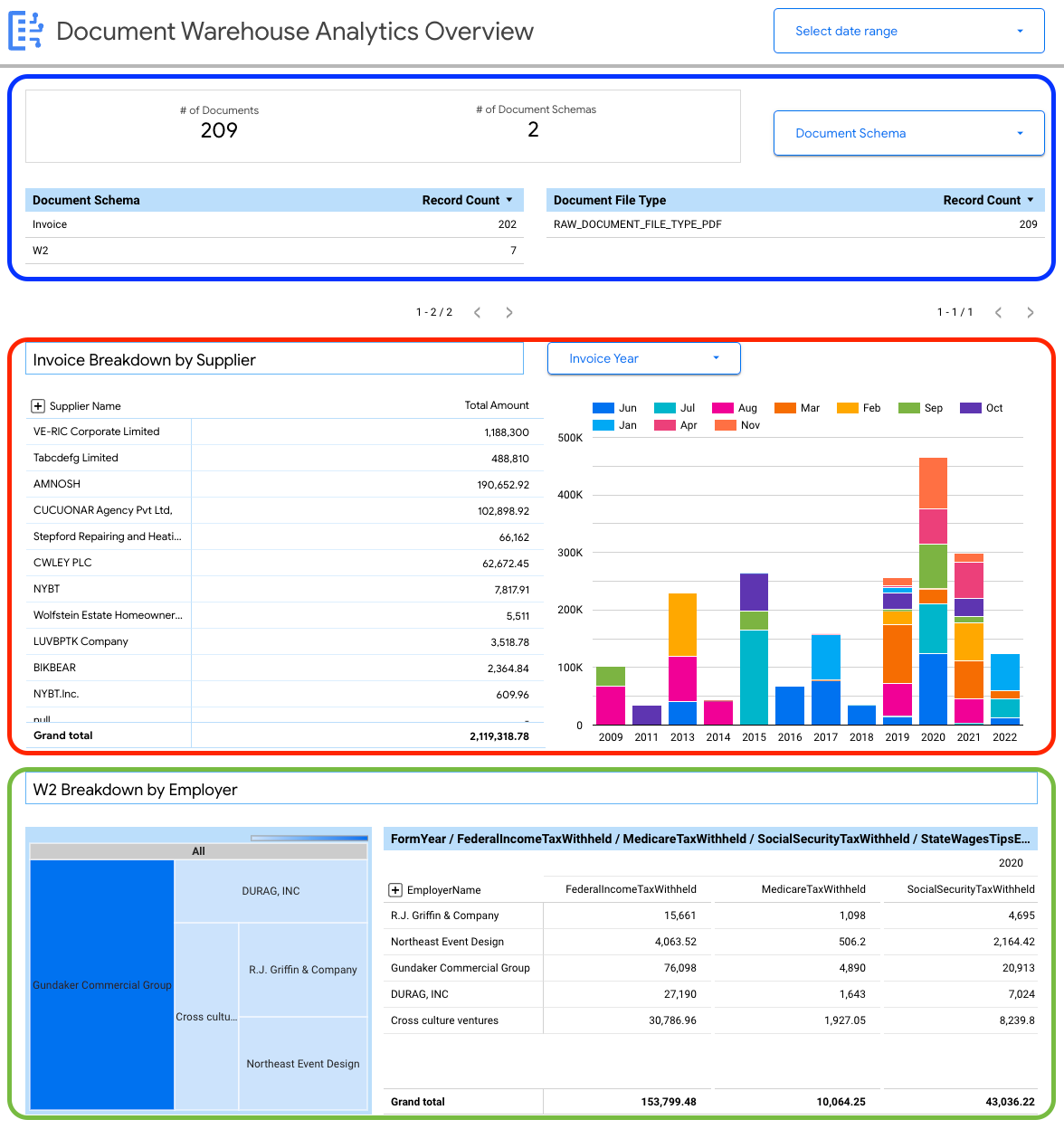
ドキュメント レベルの詳細を表示できます。
- ドキュメントの合計数。
- ドキュメント スキーマの合計数。
- ドキュメント スキーマ別のレコード数。
- ドキュメント ファイル形式(PDF、テキスト、指定されていないタイプなど)。
さらに、ドキュメント メタデータ(document_json)から抽出したプロパティを使用して、BigQuery に取り込まれた請求書と W2 のキーの内訳を作成できます。
サンプルビュー: ビジネス固有の分析情報ダッシュボード(請求書)
次のダッシュボードでは、1 つのドキュメント スキーマ(請求書)の詳細を確認して、Document AI ウェアハウスに取り込まれたすべての請求書に関する分析情報を取得できます。
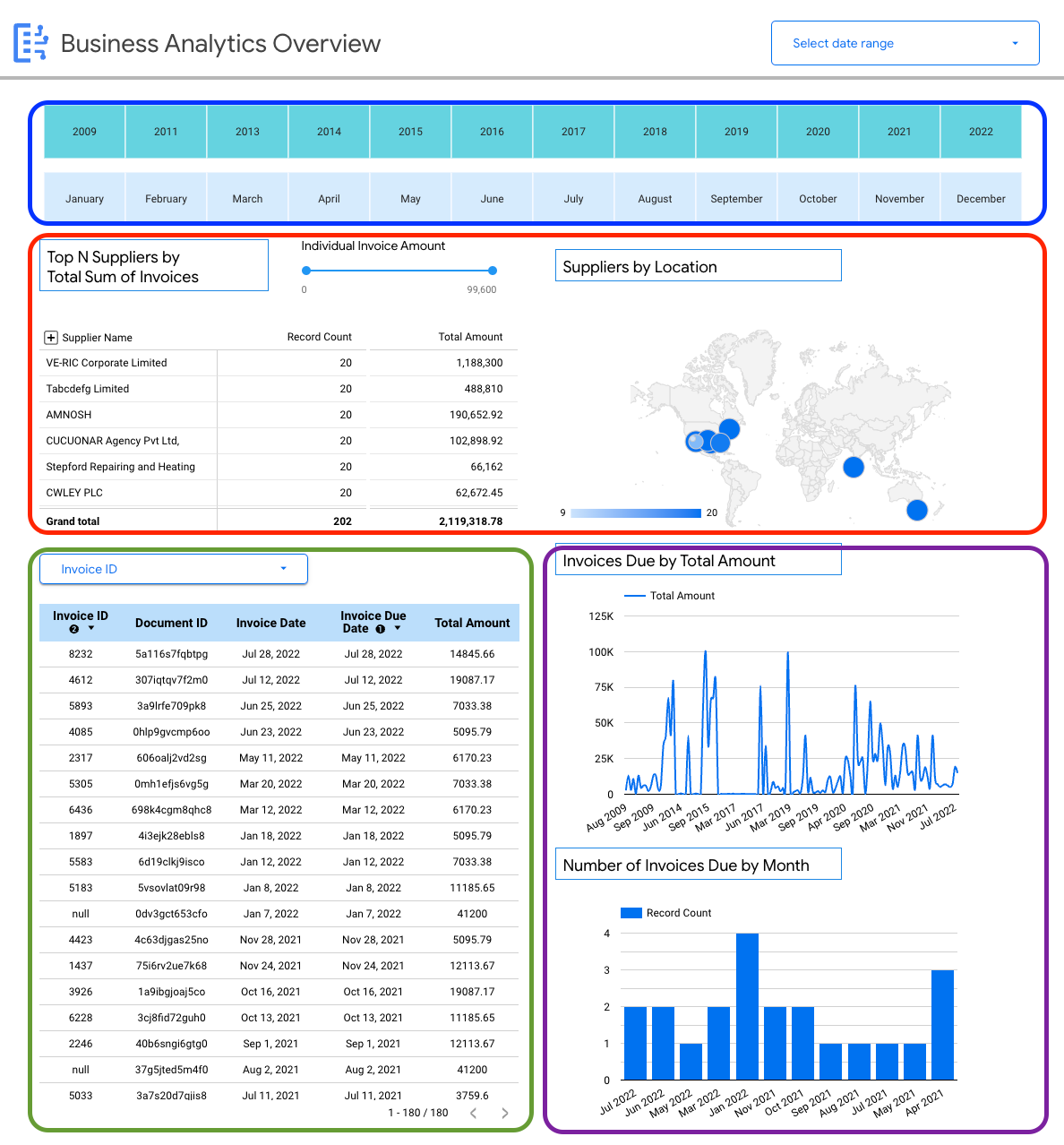
請求書のスキーマ固有の詳細を表示できます。
- 請求金額で上位のサプライヤー。
- ロケーション別のサプライヤー。
- 請求日とその期日。
- 金額とレコード数による請求書の月ごとの推移。
データソースをダッシュボードに接続する
これらのダッシュボード サンプル をデータセットの可視化の出発点として使用するには、BigQuery からデータソースを接続します。
サンプル ダッシュボードを BigQuery データソースに接続する前に、 環境に関連付けられているアカウントにログインしていることを確認してください。 Google Cloud

ハイライト表示されたボタンを選択して、プルダウン オプションを表示します。

[コピーを作成] を選択します。
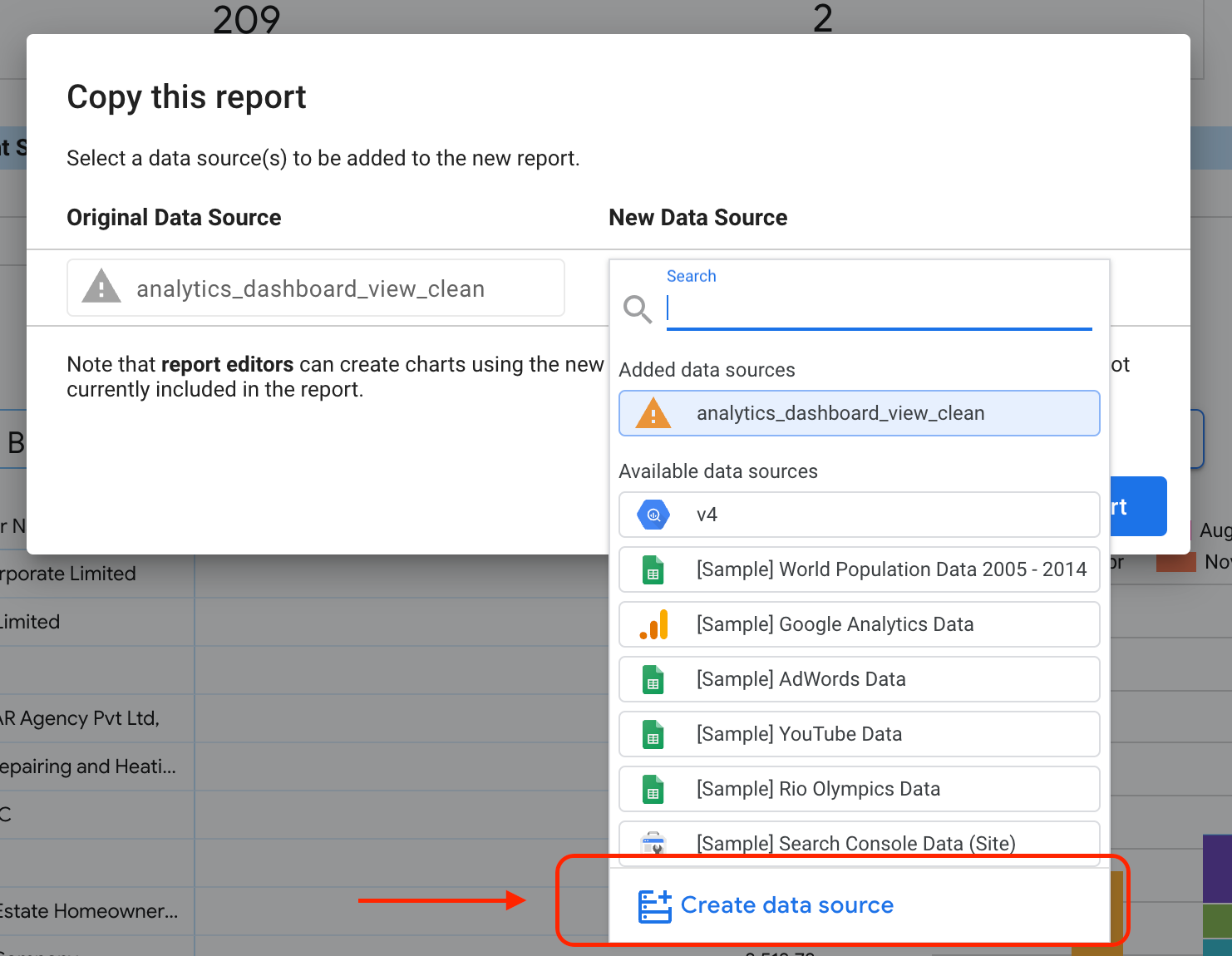
[新しいデータソース] サブセクションで、[データソースを作成] を選択します。
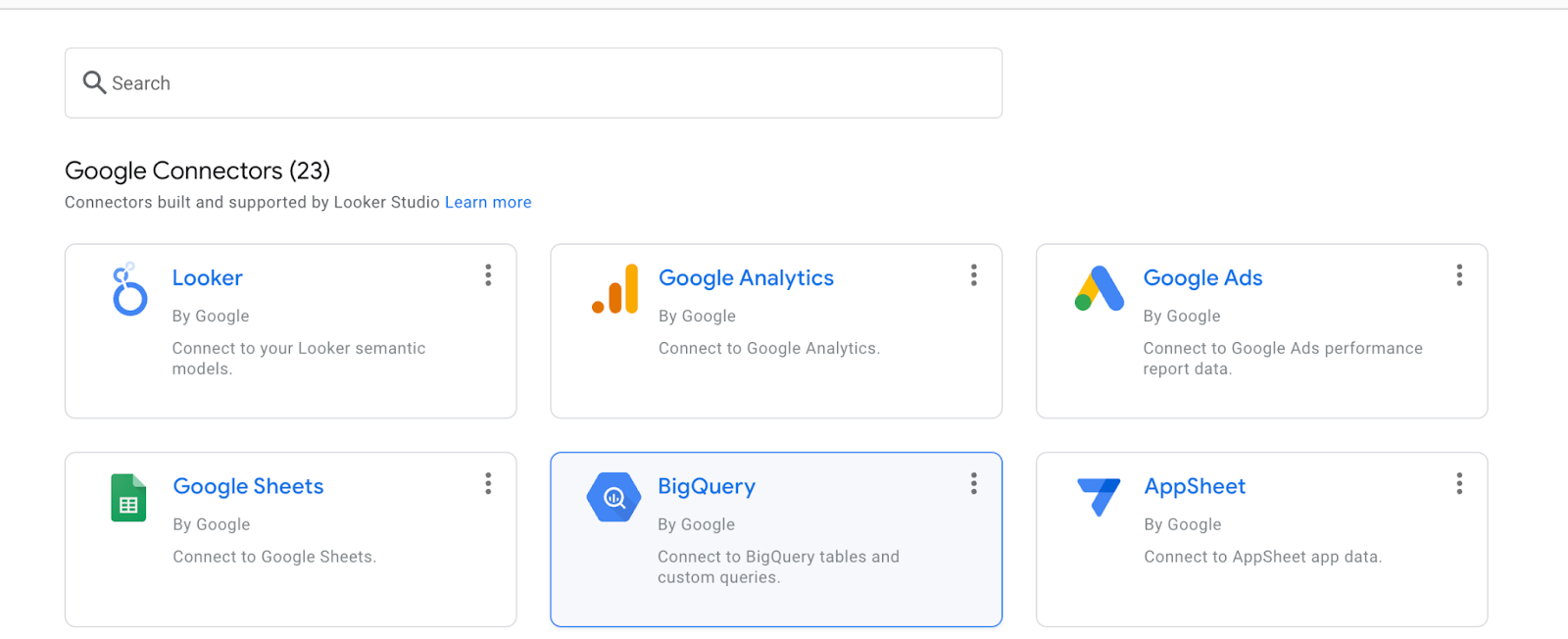
[BigQuery] を選択します。
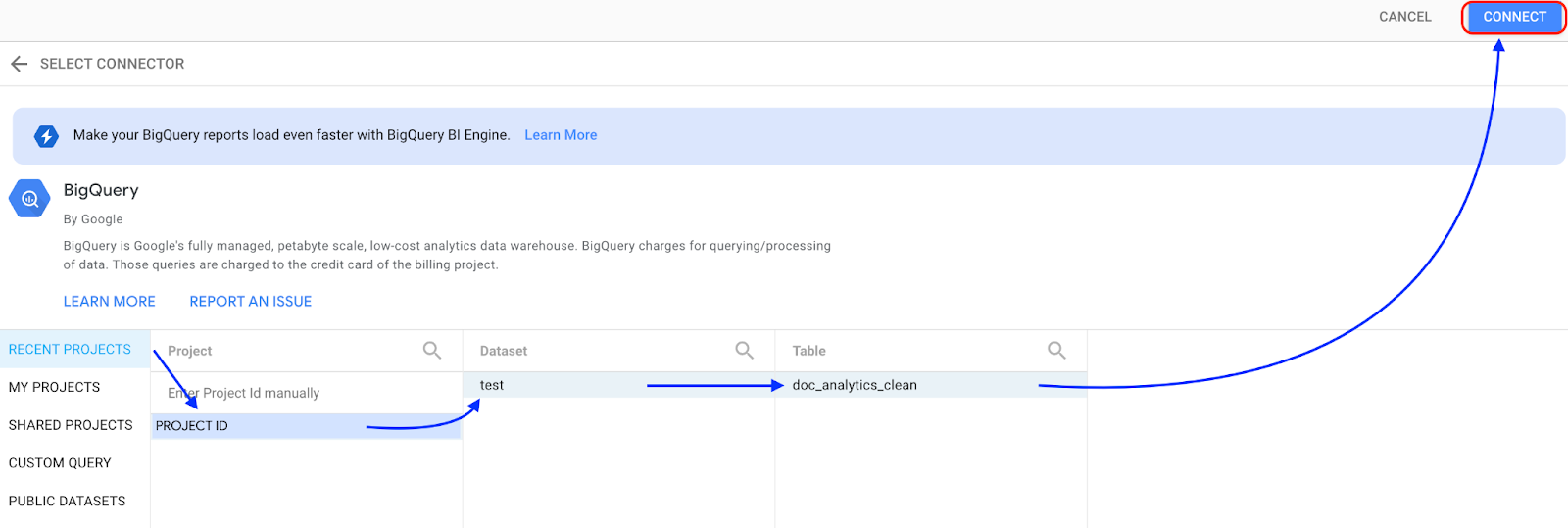
データセットが保存されているプロジェクトを選択し、プロンプトに沿ってデータセットとテーブルを選択します。[接続] をクリックします。

[レポートに追加] をクリックします。
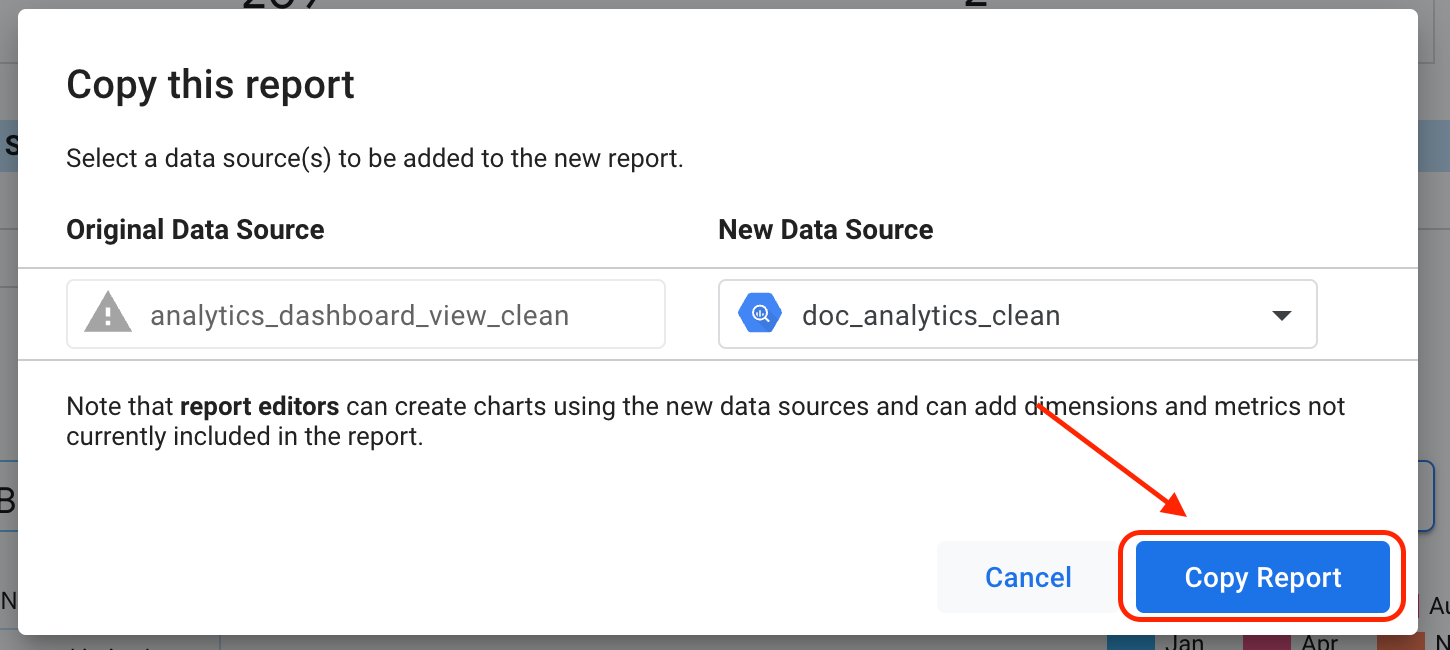
[レポートをコピー] をクリックします。
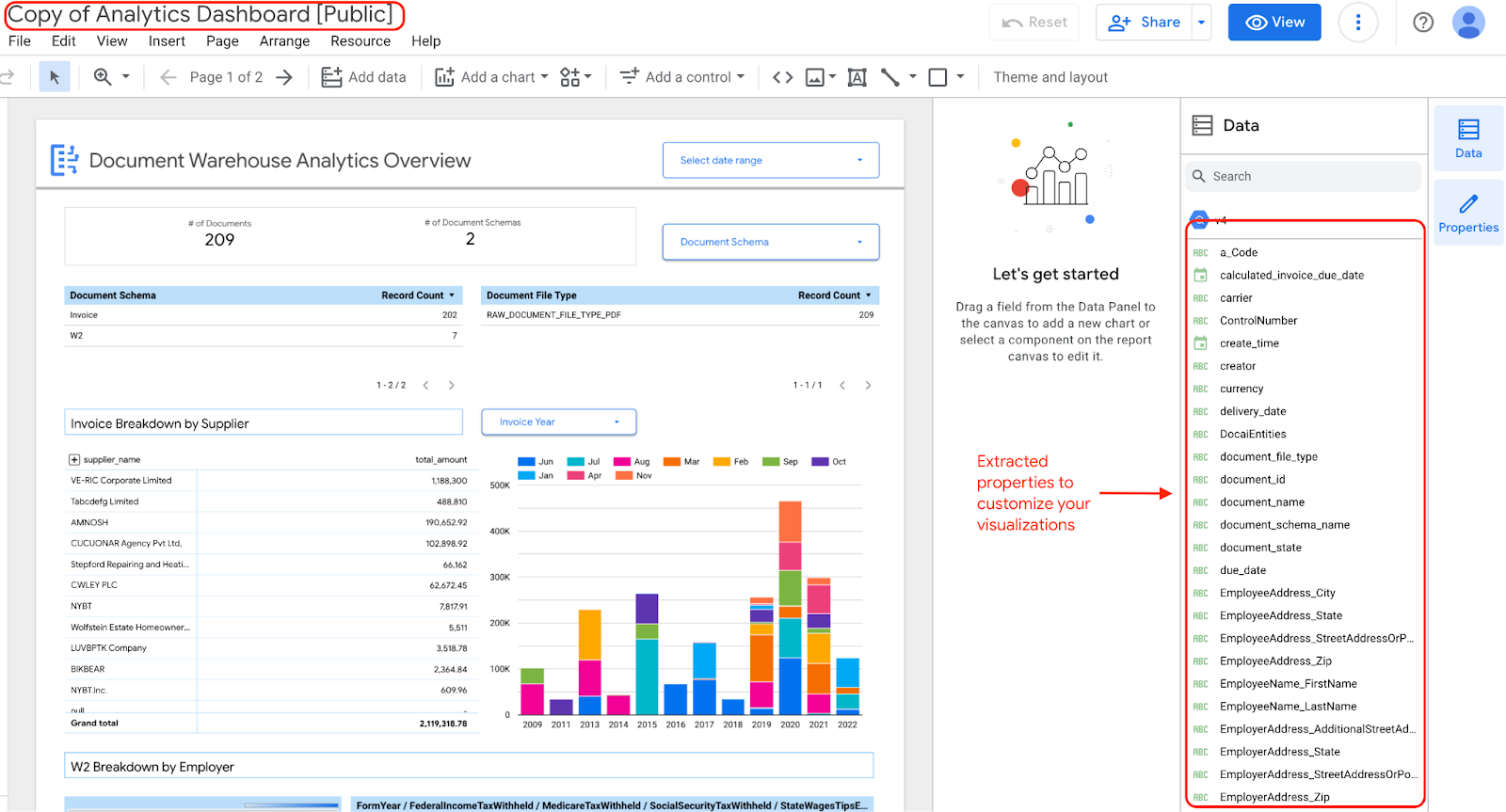
ダッシュボードのウィジェットを編集して更新する場合は、抽出されたプロパティを含むダッシュボードのコピーがあるため、編集できます。