
Pengantar konektor BigQuery
Konektor BigQuery membantu Anda mengekspor metadata dokumen (termasuk properti) yang disimpan di Document AI Warehouse ke tabel BigQuery Anda. Dengan data Anda di BigQuery, Anda dapat menjalankan analisis, membuat laporan, dan dasbor untuk membantu Anda membuat keputusan bisnis.
Untuk mengaktifkan konektor BigQuery, Anda perlu menyiapkan tabel BigQuery dengan izin yang diperlukan diberikan, dan mengonfigurasi tugas asinkron melalui API. Konektor BigQuery mengekspor data dari Document AI Warehouse ke tabel BigQuery Anda.
Sebelum memulai
Siapkan Document AI Warehouse, dan serap dokumen Anda. Untuk mengetahui informasi selengkapnya, ikuti panduan memulai cepat.
Anda harus memastikan bahwa project yang menghosting tabel BigQuery Anda adalah project yang sama dengan yang digunakan oleh Document AI Warehouse untuk menyimpan dokumen Anda. Dengan kata lain, data harus selalu diekspor dari Document AI Warehouse ke tabel BigQuery dalam project yang sama.
Di project, Anda harus memiliki peran Owner (roles/owner), atau Anda harus memiliki peran resourcemanager.projects.getIamPolicy dan resourcemanager.projects.setIamPolicy
izin.
Menyiapkan Akses BigQuery
Ikat akun layanan doc-ai-warehouse-dw-bq-connector@system.gserviceaccount.com
ke peran BigQuery Admin:
gcloud projects add-iam-policy-binding <var>PROJECT_ID</var> --member serviceAccount:doc-ai-warehouse-dw-bq-connector@system.gserviceaccount.com --role=roles/bigquery.admin
Menyiapkan set data dan tabel BigQuery
Siapkan set data dan tabel BigQuery agar Document AI Warehouse dapat mengekspor data. Jika Anda tidak memiliki set data BigQuery, ikuti langkah-langkah membuat set data untuk membuatnya.
Buat tabel BigQuery di set data BigQuery Anda. Dengan mengikuti petunjuk BigQuery, Anda membuat tabel dengan pernyataan contoh DDL:
CREATE TABLE `PROJECT_ID.DATASET_NAME.TABLE_NAME`
(
project_number INT64,
location STRING,
mod_type STRING,
document_id STRING,
document_json JSON,
create_time TIMESTAMP,
creator STRING,
update_time TIMESTAMP,
updater STRING,
document_state STRING,
export_time TIMESTAMP
)
PARTITION BY TIMESTAMP_TRUNC(export_time, HOUR)
OPTIONS(
partition_expiration_days=150,
description="table partitioned by export_time on hour with expiry"
);
DDL akan membuat tabel BigQuery baru untuk Anda. Tabel dipartisi menurut waktu per jam, dan partisi dihapus dalam 150 hari.
Mengonfigurasi konektor BigQuery
Membuat konfigurasi ekspor data
Petunjuk berikut membuat tugas ekspor data baru, yang menyiapkan tugas asinkron untuk mengekspor data. Sebaiknya mulai dengan tabel kosong untuk setiap tugas ekspor data baru. Lihat referensi API untuk mengetahui detail konfigurasi.
Anda memiliki opsi menjalankan berikut. Aplikasi ini dapat dikonfigurasi menggunakan
FREQUENCY.
Lihat referensi
API.
- ADHOC: Tugas hanya berjalan satu kali. Semua data diekspor ke tabel BigQuery Anda.
- HARIAN: Tugas berjalan setiap hari. Untuk menjalankan pertama kali, semua data akan diekspor ke tabel BigQuery Anda. Setelah ekspor awal selesai, hanya perubahan data hari sebelumnya (atau delta dari sinkronisasi terakhir yang berhasil) yang diekspor ke tabel BigQuery Anda.
- HOURLY: Tugas berjalan setiap jam. Untuk menjalankan pertama kali, semua data akan diekspor ke tabel BigQuery Anda. Setelah ekspor awal selesai, hanya perubahan data jam sebelumnya (atau delta dari sinkronisasi terakhir yang berhasil) yang diekspor ke tabel BigQuery Anda.
Sebelum menggunakan salah satu data permintaan, lakukan penggantian berikut:
- PROJECT_NUMBER: Google Cloud nomor project Anda
- LOCATION: lokasi Document AI Warehouse Anda (seperti `us`)
- DATASET_LOCATION: lokasi set data Anda
- DATASET_NAME: nama set data Anda
- TABLE_NAME: nama tabel Anda
-
FREQUENCY: salah satu dari
ADHOC,DAILY, atauHOURLY.
Meminta isi JSON:
{
"projectNumber": PROJECT_NUMBER,
"location": "DATASET_LOCATION",
"dataset": "DATASET_NAME",
"table": "TABLE_NAME",
"frequency": "FREQUENCY",
"state": "ACTIVE"
}
Untuk mengirim permintaan Anda, perluas salah satu opsi berikut:
Anda akan melihat respons JSON seperti berikut:
Pelaksanaan tugas
Setelah Anda berhasil membuat tugas, tugas akan berjalan berdasarkan konfigurasi Anda. Perhatikan bahwa tugas berjalan secara asinkron karena memerlukan waktu untuk dijalankan. Bergantung pada jumlah data yang akan diekspor, proses pertama dapat memerlukan waktu untuk selesai. Untuk tugas harian, tunggu 24 jam hingga hasilnya ditampilkan di tabel BigQuery.
Menghapus konfigurasi ekspor data
Perintah berikut akan menghapus (dengan mengarsipkan) tugas yang Anda buat.
Sebelum menggunakan salah satu data permintaan, lakukan penggantian berikut:
- PROJECT_NUMBER: Google Cloud nomor project Anda
- LOCATION: lokasi Document AI Warehouse Anda (seperti `us`)
- JOB_ID: ID tugas Anda, dalam respons saat Anda membuatnya
Meminta isi JSON:
{}
Untuk mengirim permintaan Anda, perluas salah satu opsi berikut:
Anda akan melihat respons JSON seperti berikut:
Setelah itu, tugas ekspor Anda akan dihapus (diarsipkan) dan Document AI Warehouse tidak akan menjalankannya lagi.
Menjelajahi data yang di-ingest ke BigQuery
Untuk mengekstrak metadata dan properti dokumen ke dalam kolom tabel yang berbeda di BigQuery untuk kebutuhan analisis Anda, Anda dapat menggunakan contoh kueri DDL di bawah. Kolom yang diekstrak ini juga dapat digunakan di Data Studio atau alat Dasbor BI mana pun untuk memvisualisasikan hubungan dalam data.
Ekstrak kolom utama dari document_json
Kueri ini memilih kolom yang relevan dari ekspor data, termasuk kolom kunci dari metadata dokumen (disimpan di kolom document_json).
DROP VIEW IF EXISTS
`DATASET_NAME.VIEW_NAME_1`;
CREATE VIEW
`DATASET_NAME.VIEW_NAME_1` AS
SELECT
project_number,
document_id,
mod_type,
create_time,
update_time,
location,
creator,
updater,
document_state,
SPLIT(JSON_EXTRACT_SCALAR(document_json,'$.documentSchemaName' ), '/')[SAFE_OFFSET(ARRAY_LENGTH(SPLIT(JSON_EXTRACT_SCALAR(document_json,'$.documentSchemaName' ), '/')) - 1)] AS document_schema_name,
JSON_EXTRACT_SCALAR(document_json,'$.name') AS document_name,
JSON_EXTRACT_SCALAR(document_json,'$.rawDocumentFileType')
AS raw_document_file_type,
JSON_EXTRACT(document_json,'$.properties') AS properties
FROM
`DATASET_NAME.SYSTEM_METADATA_AND_DOC_PROPERTIES_TABLE_EXPORT_NAME`;
Membatalkan properti dari document_json
Kueri ini memisahkan properti dari metadata dokumen (document_json) untuk membuat pasangan nilai kunci (nama properti, nilai). Pasangan nilai kunci ini akan diubah menjadi kolom tabel individual dalam kueri berikutnya untuk memungkinkan eksplorasi data tingkat properti dan visualisasi dasbor.
DROP VIEW IF EXISTS
`DATASET_NAME.VIEW_NAME_2`;
CREATE VIEW
`DATASET_NAME.VIEW_NAME_2` AS
SELECT
* EXCEPT(key_value_pair,
properties,raw_document_file_type)
FROM (
SELECT
*,
REPLACE(JSON_VALUE(key_value_pair,'$.name'),'/','-') property_name,
-- Note: values are either text OR float values
CASE
WHEN JSON_VALUE(key_value_pair,'$.textValues.values[0]') IS NULL THEN JSON_VALUE(key_value_pair,'$.floatValues.values[0]')
ELSE
JSON_VALUE(key_value_pair,'$.textValues.values[0]')
END
AS value,
CASE
WHEN raw_document_file_type IS NULL THEN "RAW_DOCUMENT_FILE_TYPE_UNSPECIFIED"
ELSE
raw_document_file_type
END
AS document_file_type
FROM
`DATASET_NAME.VIEW_NAME_1`,
UNNEST(JSON_EXTRACT_ARRAY(properties)) AS key_value_pair);
Membuat properti dari document_json untuk membuat kolom tabel di BigQuery
Prosedur berikut membuat tabel dengan semua properti dokumen yang diubah sebagai kolom tabel individual dengan memutar properti dan nilai terkait. Hasil tabel ini dapat dimanfaatkan untuk mendapatkan insight lebih lanjut melalui kueri berikutnya di Data Studio dan di alat visualisasi BI lainnya.
DECLARE
property_field STRING;
-- Extracting distinct property_names from the previous view and storing it in property_field, declared above
EXECUTE IMMEDIATE
"""SELECT string_agg(CONCAT("'",property_name,"'")) from (select distinct property_name from DATASET.VIEW_NAME_2)""" INTO property_field;
DROP TABLE IF EXISTS `DATASET_NAME.ANALYTICS_TABLE_NAME`;
-- Creating pivot table with the aid of extracted distinct property_names
-- Casting numerical values to float/int
-- Pivot on property_name and value (ie. create a new column for each of the property_name, substitute the value)
EXECUTE IMMEDIATE
FORMAT ("""
CREATE TABLE `DATASET_NAME.ANALYTICS_TABLE_NAME` AS
SELECT * FROM `DATASET_NAME.VIEW_NAME_2`
PIVOT(min(value) FOR property_name IN (%s))""", property_field);
Prosedur Pembersihan & Transformasi Data (Khusus Kasus Bisnis)
Bergantung pada data yang dimasukkan ke BigQuery, Anda mungkin perlu melakukan prosedur pembersihan dan transformasi data tambahan untuk memungkinkan analisis lebih lanjut. Prosedur tersebut bervariasi dari kasus ke kasus (set data ke set data) dan harus dilakukan sebagaimana mestinya.
Beberapa contoh prosedur pembersihan data dapat mencakup (tidak terbatas pada):
- Menyatukan format tanggal.
- Menggabungkan nilai properti.
- Misalnya, mentransmisikan jenis data ke string, float, dan bilangan bulat.
Memvisualisasikan data di Data Studio
Setelah data diekstrak, dibersihkan, dan diubah di BigQuery, set data akhir Anda dapat diekspor ke Data Studio untuk analisis visual.
Dasbor Looker
Contoh dasbor yang diuraikan menampilkan kemungkinan visualisasi yang dapat dibuat dari set data Anda. Dalam skenario ini, ekspor data sampel dari Document AI Warehouse terdiri dari W2 & Invoice (dua skema).
Dasbor Looker yang Dapat Diakses Publik
Tampilan contoh: Ringkasan analisis Document AI Warehouse
Dasbor berikut memberi Anda insight tingkat tinggi tentang berbagai jenis dokumen yang di-ingest ke instance Document AI Warehouse Anda.
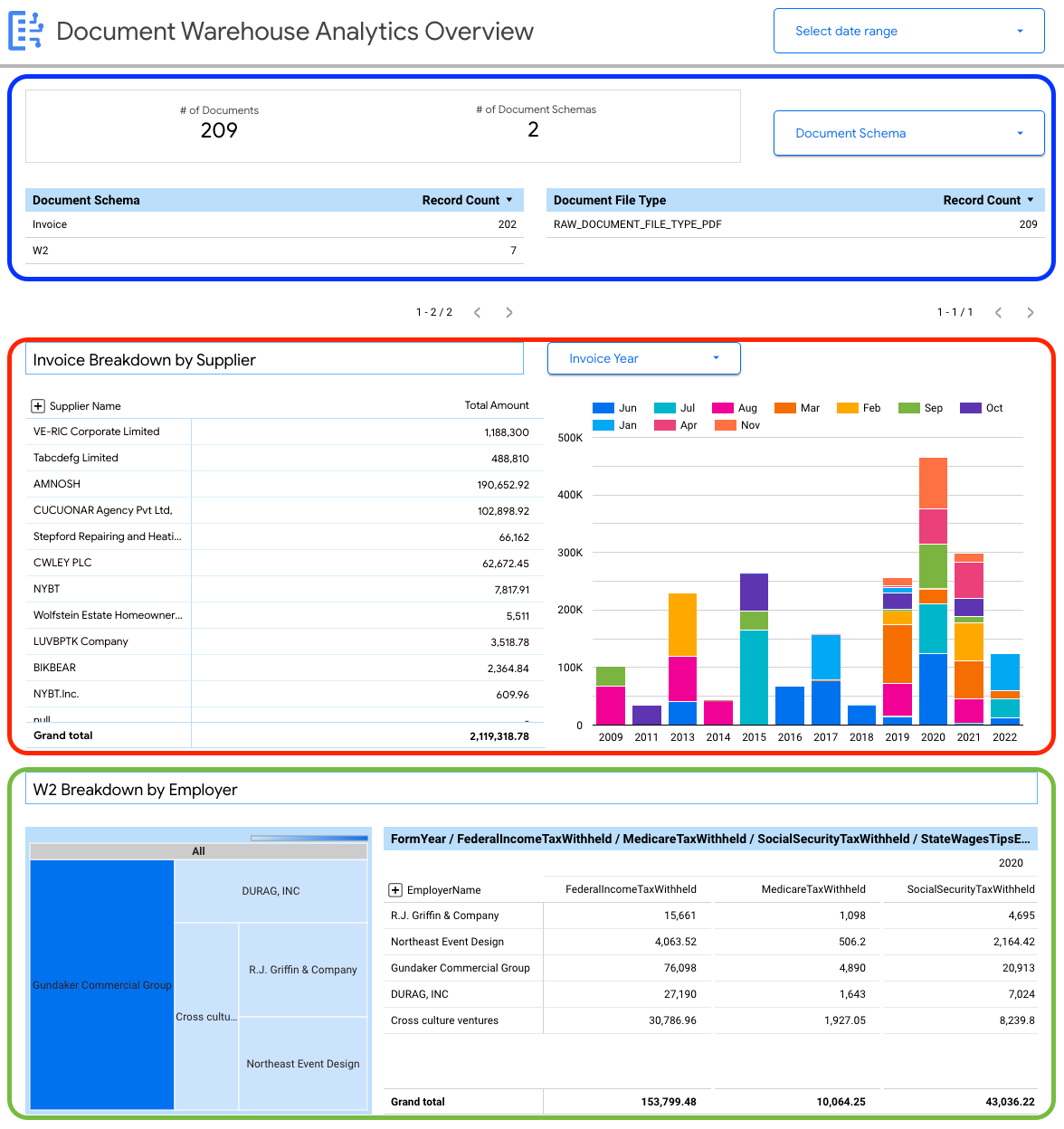
Anda dapat melihat detail tingkat dokumen, termasuk:
- Jumlah total dokumen.
- Jumlah total skema dokumen.
- Jumlah kumpulan data menurut skema dokumen.
- Jenis file dokumen (seperti PDF, teks, jenis tidak ditentukan]).
Anda juga dapat menggunakan properti yang diekstrak dari metadata dokumen (document_json) untuk membuat perincian utama bagi Invoice dan W2 yang di-ingest ke BigQuery.
Contoh tampilan: dasbor insight khusus bisnis (invoice)
Dasbor berikut memberi pengguna tampilan mendetail tentang satu skema dokumen (invoice) untuk mengaktifkan insight pada semua invoice yang dimasukkan ke Document AI Warehouse.
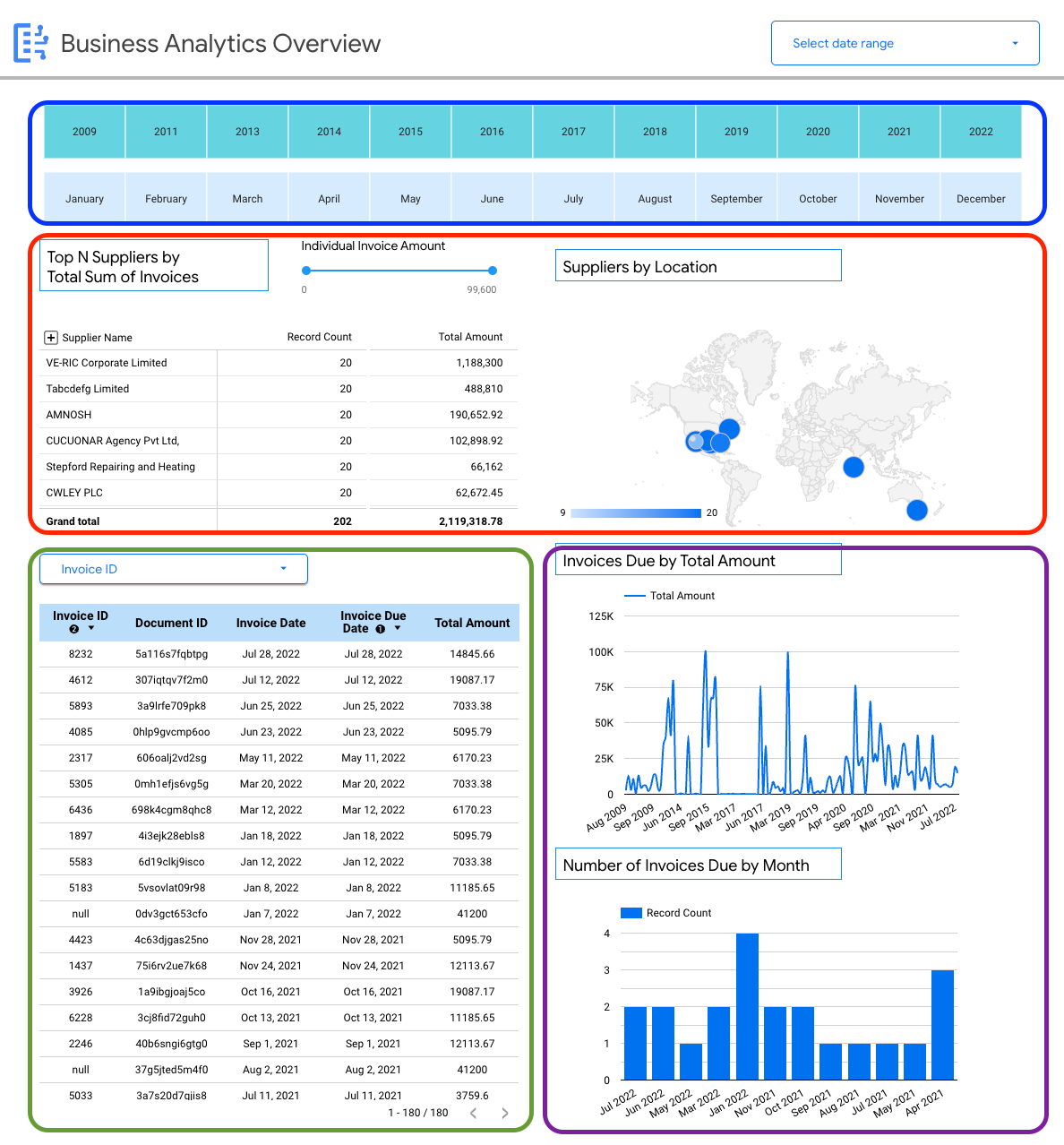
Anda dapat melihat detail khusus skema pada invoice, misalnya:
- Pemasok teratas berdasarkan jumlah invoice.
- Pemasok menurut lokasi.
- Tanggal invoice dan tanggal jatuh tempo yang sesuai.
- Tren invoice dari bulan ke bulan menurut jumlah dan jumlah data.
Menghubungkan sumber data ke dasbor
Untuk menggunakan contoh dasbor ini sebagai titik awal untuk memvisualisasikan set data, Anda dapat menghubungkan sumber data dari BigQuery.
Sebelum menghubungkan dasbor contoh ke sumber data BigQuery, pastikan Anda login ke akun yang terkait dengan lingkungan Google CloudAnda.

Pilih tombol yang disorot untuk melihat opsi dropdown.

Pilih Buat Salinan.
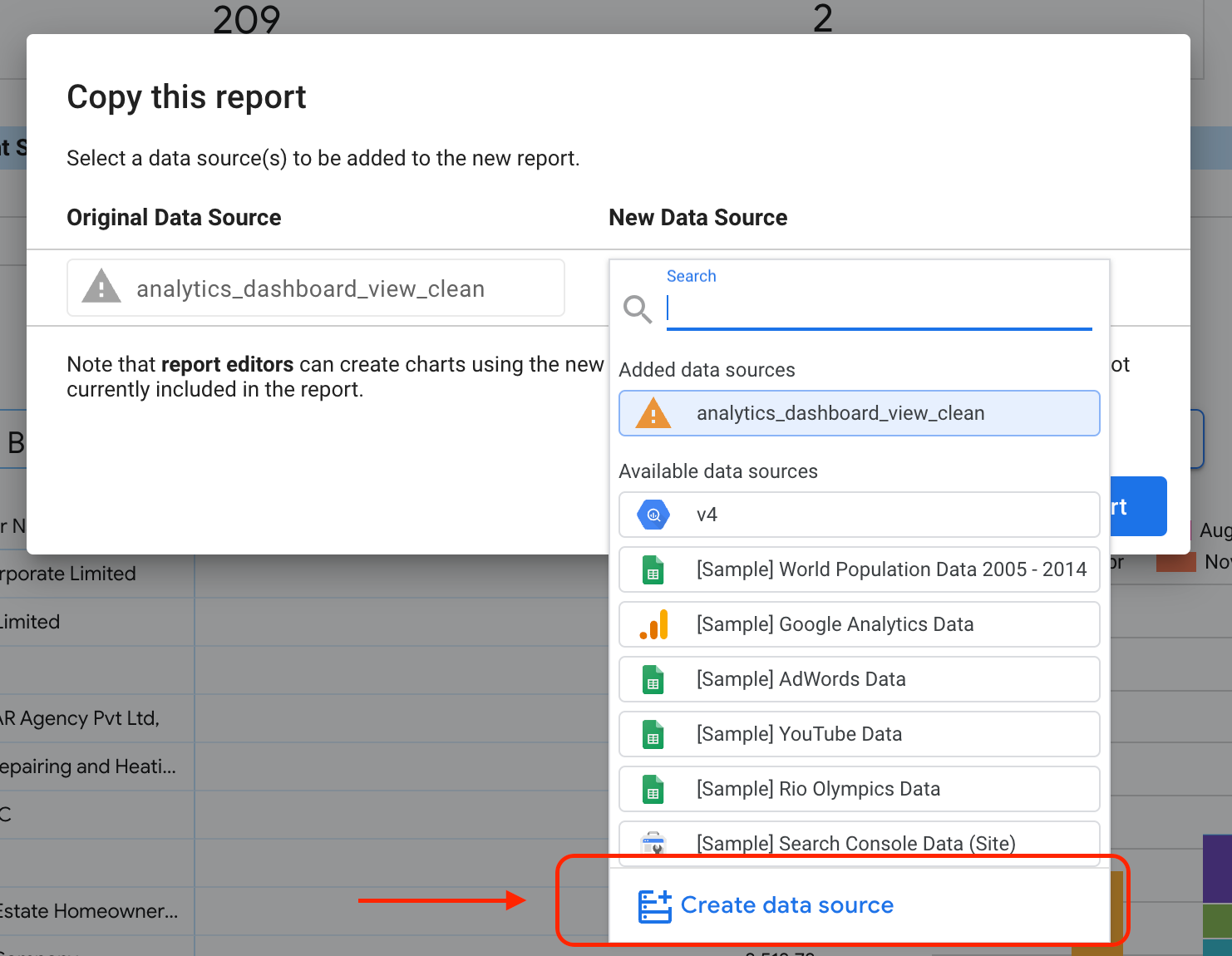
Di subbagian Sumber Data Baru, pilih Buat sumber data.
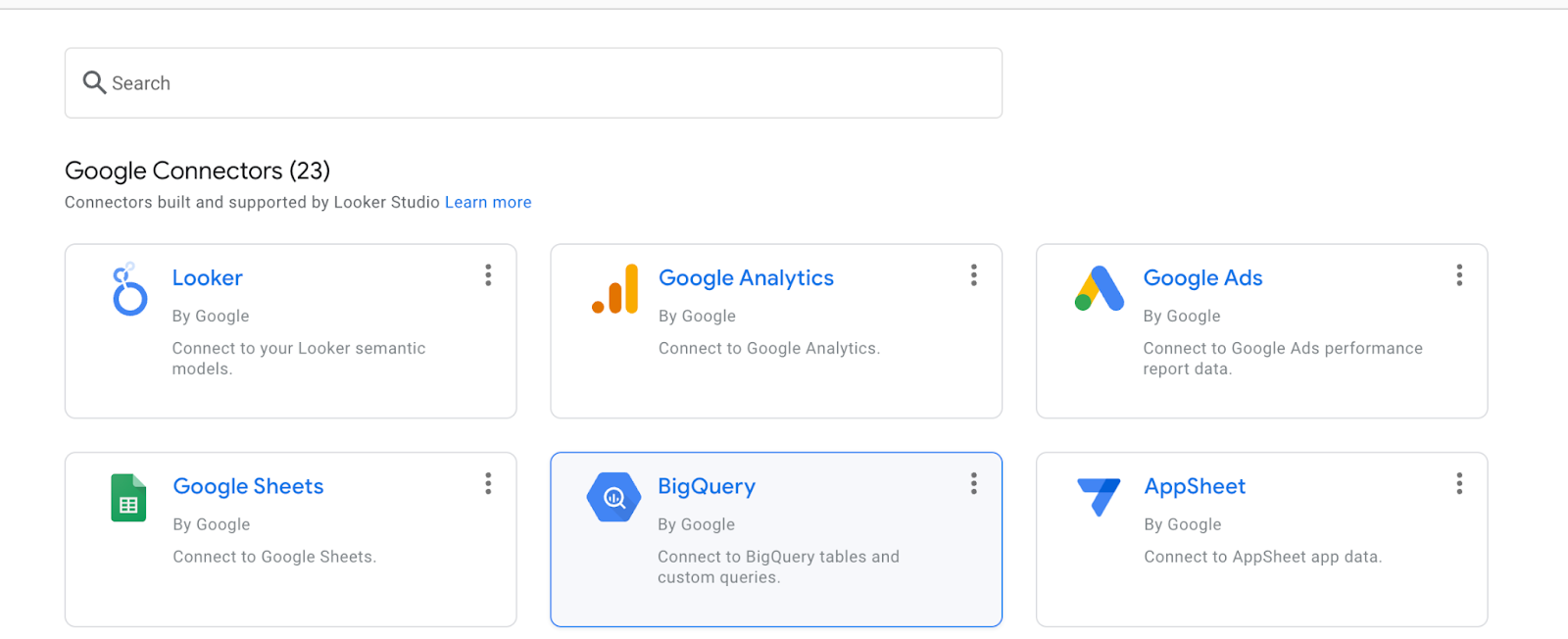
Pilih BigQuery.
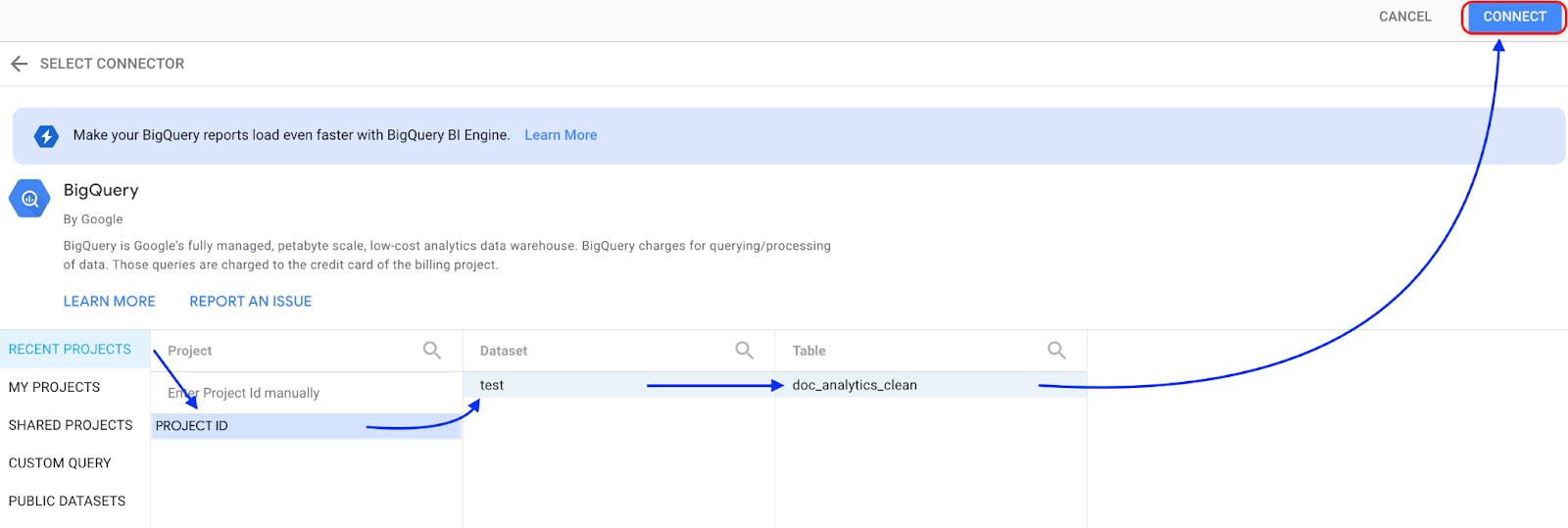
Pilih project tempat set data Anda disimpan, lalu ikuti petunjuk untuk memilih set data dan tabel Anda. Klik Hubungkan.

Klik Add to Report.
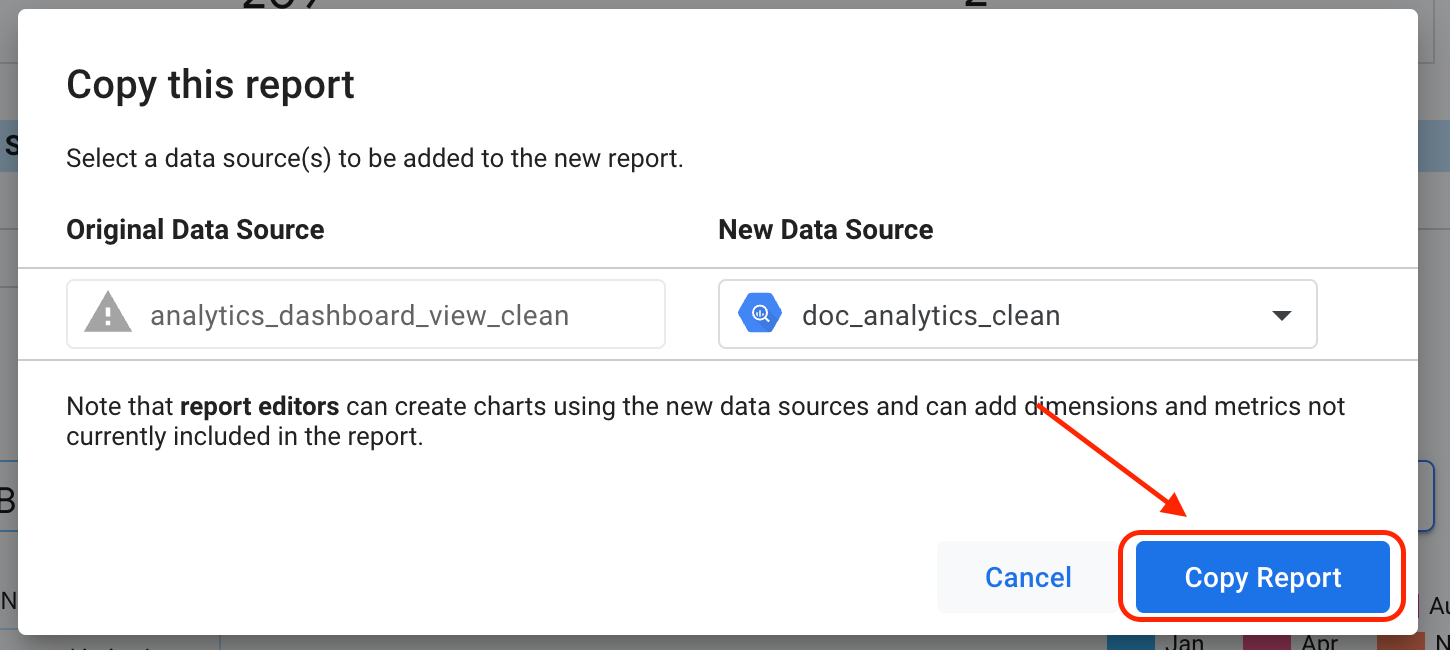
Klik Salin Laporan.
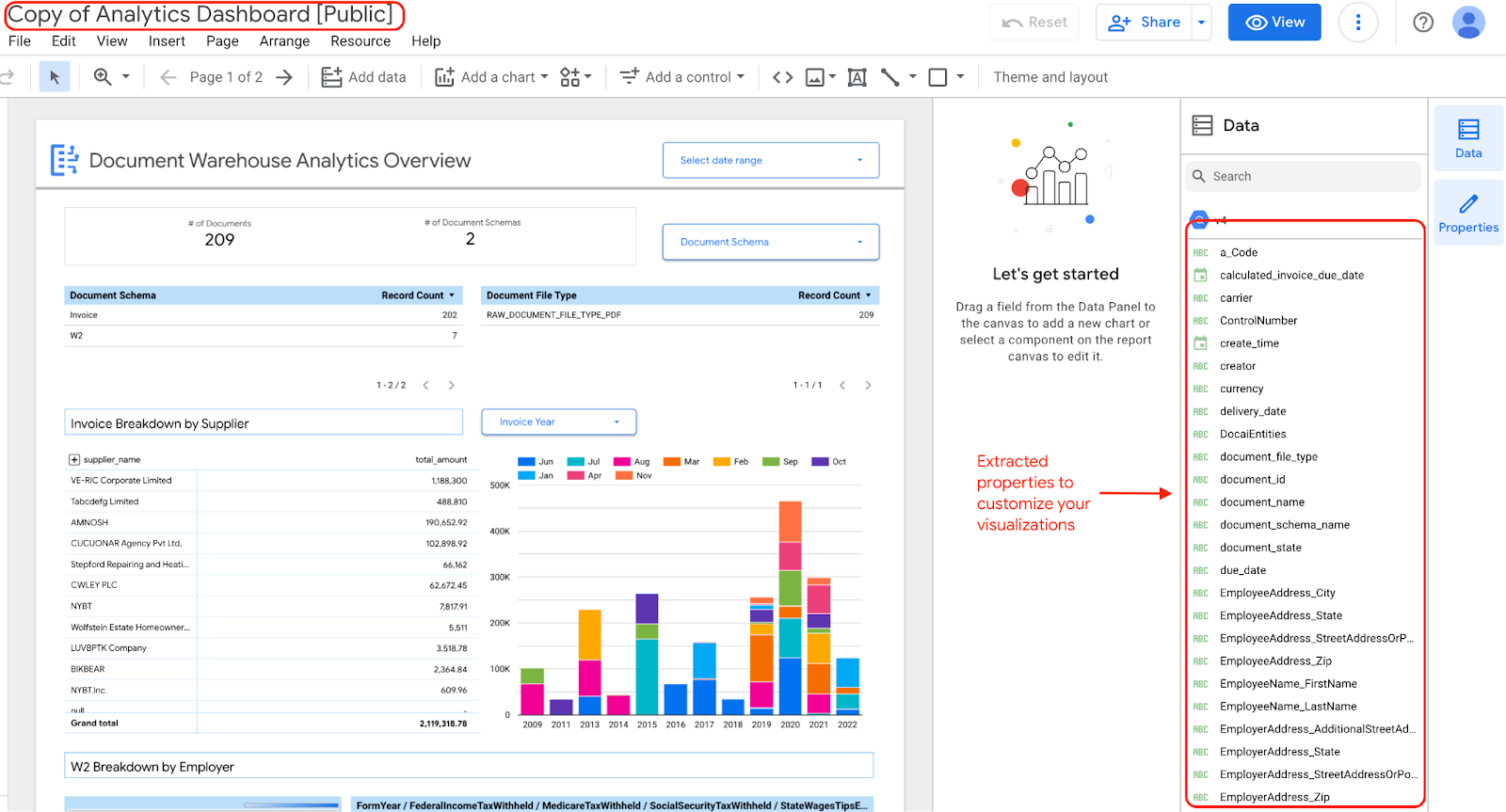
Jika memilih untuk mengedit dan memperbarui widget di dasbor, Anda dapat mengeditnya, karena Anda memiliki salinan dasbor dengan properti yang diekstrak.