
Introducción al conector de BigQuery
El conector de BigQuery te ayuda a exportar los metadatos del documento (incluidas las propiedades) almacenados en Document AI Warehouse a tu tabla de BigQuery. Con tus datos en BigQuery, puedes ejecutar análisis, crear informes y paneles para ayudarte a tomar decisiones empresariales.
Para habilitar el conector de BigQuery, debes configurar una tabla de BigQuery con los permisos necesarios y configurar las tareas asíncronas a través de la API. El conector de BigQuery exporta los datos de Document AI Warehouse a tus tablas de BigQuery.
Antes de comenzar
Configura Document AI Warehouse y transfiere tus documentos. Para obtener más información, sigue la guía de inicio rápido.
Debes asegurarte de que el proyecto que aloja tu tabla de BigQuery sea el mismo que usa Document AI Warehouse para almacenar tus documentos. En otras palabras, los datos siempre se deben exportar desde Document AI Warehouse a la tabla de BigQuery en el mismo proyecto.
En el proyecto, debes tener el rol de Owner (roles/owner) o los roles de resourcemanager.projects.getIamPolicy y resourcemanager.projects.setIamPolicy.
obligatorios de tu app.
Configura el acceso a BigQuery
Vincula la cuenta de servicio doc-ai-warehouse-dw-bq-connector@system.gserviceaccount.com
al rol BigQuery Admin:
gcloud projects add-iam-policy-binding <var>PROJECT_ID</var> --member serviceAccount:doc-ai-warehouse-dw-bq-connector@system.gserviceaccount.com --role=roles/bigquery.admin
Configura un conjunto de datos y una tabla de BigQuery
Configura un conjunto de datos y una tabla de BigQuery para que Document AI Warehouse exporte los datos. Si no tienes un conjunto de datos de BigQuery, sigue los pasos para crear conjuntos de datos.
Crea una tabla de BigQuery en tu conjunto de datos de BigQuery. Siguiendo las instrucciones de BigQuery, crea tablas con las sentencias de ejemplo de DDL:
CREATE TABLE `PROJECT_ID.DATASET_NAME.TABLE_NAME`
(
project_number INT64,
location STRING,
mod_type STRING,
document_id STRING,
document_json JSON,
create_time TIMESTAMP,
creator STRING,
update_time TIMESTAMP,
updater STRING,
document_state STRING,
export_time TIMESTAMP
)
PARTITION BY TIMESTAMP_TRUNC(export_time, HOUR)
OPTIONS(
partition_expiration_days=150,
description="table partitioned by export_time on hour with expiry"
);
El DDL crea una tabla de BigQuery nueva para ti. La tabla está particionada por hora, y la partición se borra en 150 días.
Configura el conector de BigQuery
Crea la configuración de exportación de datos
En las siguientes instrucciones, se crea un trabajo nuevo de exportación de datos, que configura los trabajos asíncronos para exportar datos. Te recomendamos que comiences con una tabla vacía para cada nuevo trabajo de exportación de datos. Consulta la referencia de la API para obtener detalles sobre la configuración.
Tienes las siguientes opciones de ejecución. Se pueden configurar con FREQUENCY.
Consulta la referencia de la API.
- ADHOC: El trabajo se ejecuta solo una vez. Todos los datos se exportan a tu tabla de BigQuery.
- DAILY: El trabajo se ejecuta a diario. En la primera ejecución, todos los datos se exportan a tu tabla de BigQuery. Una vez que se completa la exportación inicial, solo se exportan a tu tabla de BigQuery los cambios en los datos del día anterior (o el delta desde la última sincronización exitosa).
- HOURLY: El trabajo se ejecuta cada hora. En la primera ejecución, todos los datos se exportan a tu tabla de BigQuery. Una vez que se completa la exportación inicial, solo se exportan a tu tabla de BigQuery los cambios en los datos de la hora anterior (o el delta desde la última sincronización exitosa).
Antes de usar cualquiera de los datos de solicitud a continuación, realiza los siguientes reemplazos:
- PROJECT_NUMBER: Es el número de tu proyecto de Google Cloud .
- LOCATION: Es la ubicación de Document AI Warehouse (por ejemplo, "us").
- DATASET_LOCATION: Es la ubicación de tu conjunto de datos.
- DATASET_NAME: Es el nombre de tu conjunto de datos.
- TABLE_NAME: El nombre de tu tabla
-
FREQUENCY: Uno de
ADHOC,DAILYoHOURLY.
Cuerpo JSON de la solicitud:
{
"projectNumber": PROJECT_NUMBER,
"location": "DATASET_LOCATION",
"dataset": "DATASET_NAME",
"table": "TABLE_NAME",
"frequency": "FREQUENCY",
"state": "ACTIVE"
}
Para enviar tu solicitud, expande una de estas opciones:
Deberías recibir una respuesta JSON similar a la que se muestra a continuación:
Ejecución del trabajo
Una vez que creaste un trabajo correctamente, este se ejecutará según tu configuración. Ten en cuenta que los trabajos se ejecutan de forma asíncrona porque tardan en ejecutarse. Según la cantidad de datos que se exportarán, la primera ejecución puede tardar en finalizar. En el caso de los trabajos diarios, espera 24 horas para que los resultados se muestren en la tabla de BigQuery.
Borra la configuración de exportación de datos
El siguiente comando borra (archiva) un trabajo que creaste.
Antes de usar cualquiera de los datos de solicitud a continuación, realiza los siguientes reemplazos:
- PROJECT_NUMBER: Es el número de tu proyecto de Google Cloud .
- LOCATION: Es la ubicación de Document AI Warehouse (por ejemplo, "us").
- JOB_ID: Es el ID del trabajo, que se muestra en la respuesta que recibiste cuando lo creaste.
Cuerpo JSON de la solicitud:
{}
Para enviar tu solicitud, expande una de estas opciones:
Deberías recibir una respuesta JSON similar a la que se muestra a continuación:
Después de esto, se borrará (archivar) tu trabajo de exportación y Document AI Warehouse ya no lo ejecutará.
Explora los datos que se transfirieron a BigQuery
Para extraer los metadatos y las propiedades del documento en campos de tabla distintos en BigQuery para tus necesidades de análisis, puedes usar las siguientes consultas de DDL de muestra. Estos campos extraídos también se pueden usar en Data Studio o en cualquier herramienta de panel de BI para visualizar las relaciones dentro de los datos.
Extrae campos clave de document_json
Esta consulta selecciona los campos pertinentes de la exportación de datos, incluidos los campos clave de los metadatos del documento (almacenados en el campo document_json).
DROP VIEW IF EXISTS
`DATASET_NAME.VIEW_NAME_1`;
CREATE VIEW
`DATASET_NAME.VIEW_NAME_1` AS
SELECT
project_number,
document_id,
mod_type,
create_time,
update_time,
location,
creator,
updater,
document_state,
SPLIT(JSON_EXTRACT_SCALAR(document_json,'$.documentSchemaName' ), '/')[SAFE_OFFSET(ARRAY_LENGTH(SPLIT(JSON_EXTRACT_SCALAR(document_json,'$.documentSchemaName' ), '/')) - 1)] AS document_schema_name,
JSON_EXTRACT_SCALAR(document_json,'$.name') AS document_name,
JSON_EXTRACT_SCALAR(document_json,'$.rawDocumentFileType')
AS raw_document_file_type,
JSON_EXTRACT(document_json,'$.properties') AS properties
FROM
`DATASET_NAME.SYSTEM_METADATA_AND_DOC_PROPERTIES_TABLE_EXPORT_NAME`;
Cómo anular el anidamiento de propiedades de document_json
Esta consulta anula el anidamiento de las propiedades de los metadatos del documento (document_json) para crear pares clave-valor (nombre de la propiedad, valor). Estos pares clave-valor se transformarán en campos de tabla individuales en la siguiente consulta para habilitar la exploración de datos a nivel de la propiedad y la visualización del panel.
DROP VIEW IF EXISTS
`DATASET_NAME.VIEW_NAME_2`;
CREATE VIEW
`DATASET_NAME.VIEW_NAME_2` AS
SELECT
* EXCEPT(key_value_pair,
properties,raw_document_file_type)
FROM (
SELECT
*,
REPLACE(JSON_VALUE(key_value_pair,'$.name'),'/','-') property_name,
-- Note: values are either text OR float values
CASE
WHEN JSON_VALUE(key_value_pair,'$.textValues.values[0]') IS NULL THEN JSON_VALUE(key_value_pair,'$.floatValues.values[0]')
ELSE
JSON_VALUE(key_value_pair,'$.textValues.values[0]')
END
AS value,
CASE
WHEN raw_document_file_type IS NULL THEN "RAW_DOCUMENT_FILE_TYPE_UNSPECIFIED"
ELSE
raw_document_file_type
END
AS document_file_type
FROM
`DATASET_NAME.VIEW_NAME_1`,
UNNEST(JSON_EXTRACT_ARRAY(properties)) AS key_value_pair);
Cómo pivotar propiedades de document_json para crear campos de tabla en BigQuery
En los siguientes procedimientos, se crea una tabla con todas las propiedades del documento transformadas como campos de tabla individuales mediante la rotación de las propiedades y los valores asociados. Los resultados de esta tabla se pueden aprovechar para obtener más estadísticas a través de consultas posteriores en Data Studio y en otras herramientas de visualización de IE.
DECLARE
property_field STRING;
-- Extracting distinct property_names from the previous view and storing it in property_field, declared above
EXECUTE IMMEDIATE
"""SELECT string_agg(CONCAT("'",property_name,"'")) from (select distinct property_name from DATASET.VIEW_NAME_2)""" INTO property_field;
DROP TABLE IF EXISTS `DATASET_NAME.ANALYTICS_TABLE_NAME`;
-- Creating pivot table with the aid of extracted distinct property_names
-- Casting numerical values to float/int
-- Pivot on property_name and value (ie. create a new column for each of the property_name, substitute the value)
EXECUTE IMMEDIATE
FORMAT ("""
CREATE TABLE `DATASET_NAME.ANALYTICS_TABLE_NAME` AS
SELECT * FROM `DATASET_NAME.VIEW_NAME_2`
PIVOT(min(value) FOR property_name IN (%s))""", property_field);
Procedimientos de limpieza y transformación de datos (específicos para cada caso de uso)
Según los datos que se transfieran a BigQuery, es posible que debas realizar procedimientos adicionales de limpieza y transformación de datos para habilitar análisis posteriores. Estos procedimientos varían según el caso (conjunto de datos a conjunto de datos) y deben realizarse según corresponda.
Algunos ejemplos de procedimientos de limpieza de datos pueden incluir los siguientes (sin limitaciones):
- Unificar los formatos de fecha
- Consolidación de los valores de las propiedades
- Por ejemplo, convertir tipos de datos en cadenas, números de punto flotante y números enteros
Cómo visualizar los datos en Data Studio
Una vez que tus datos se hayan extraído, limpiado y transformado en BigQuery, tu conjunto de datos final se puede exportar a Data Studio para realizar un análisis visual.
Paneles de Looker
Los paneles de ejemplo que se describen muestran las posibles visualizaciones que se pueden crear a partir de tu conjunto de datos. En este caso, la exportación de datos de muestra de Document AI Warehouse consta de formularios W2 y facturas (dos esquemas).
Vista de ejemplo: Descripción general de las estadísticas de Document AI Warehouse
En el siguiente panel, se proporciona información general sobre la variedad de documentos que se transfirieron a tu instancia de Document AI Warehouse.
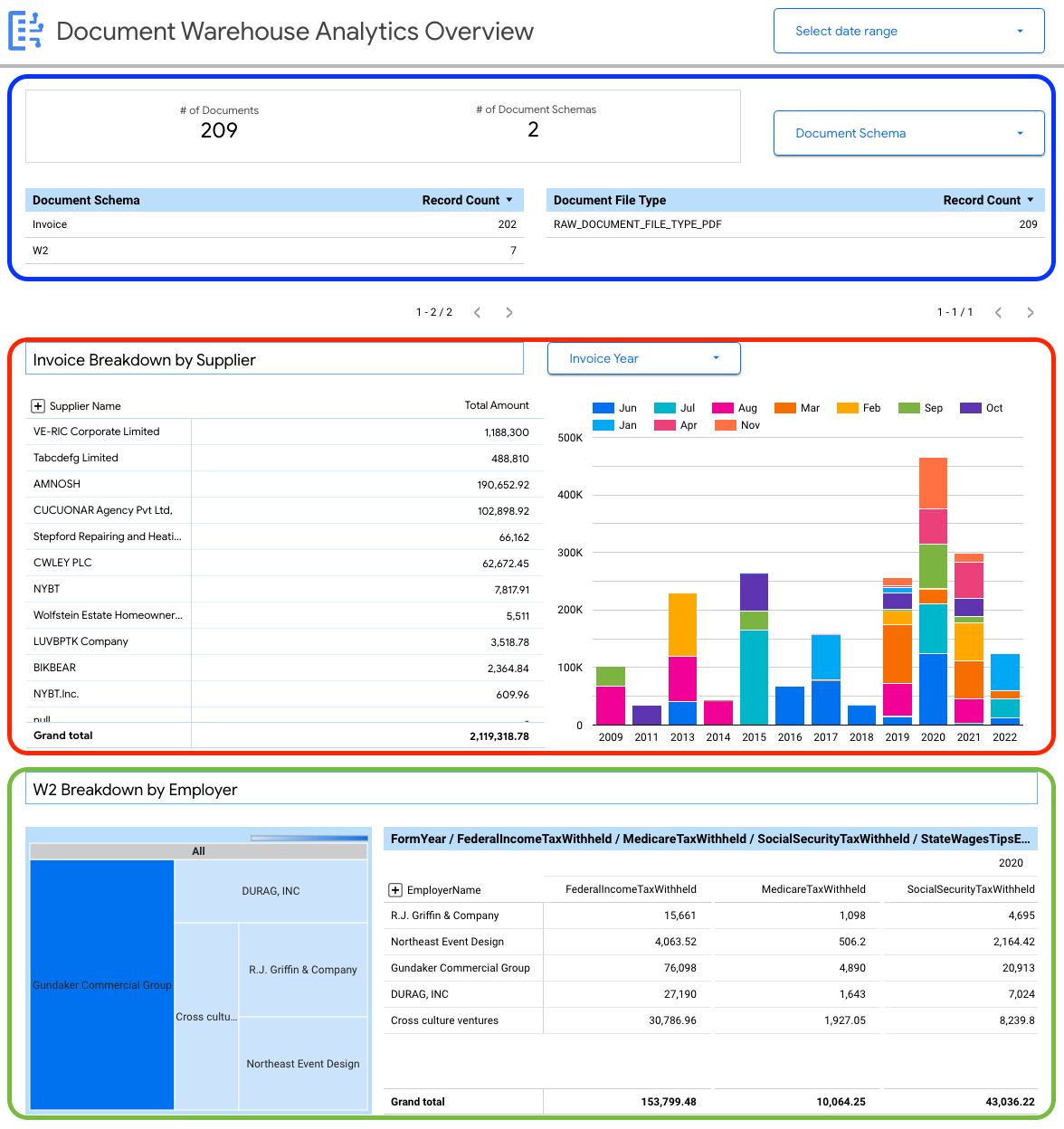
Puedes ver detalles a nivel del documento, incluidos los siguientes:
- Es la cantidad total de documentos.
- Es la cantidad total de esquemas de documentos.
- Es el recuento de registros por esquema de documento.
- Tipo de archivo del documento (como PDF, texto o tipo no especificado).
También puedes usar las propiedades extraídas de los metadatos del documento (document_json) para generar desgloses clave de las facturas y los formularios W-2 que se transfirieron a BigQuery.
Vista de ejemplo: Panel de estadísticas específicas de la empresa (facturas)
El siguiente panel proporciona al usuario una vista detallada de un solo esquema de documento (facturas) para habilitar estadísticas sobre todas las facturas que se transfirieron a Document AI Warehouse.
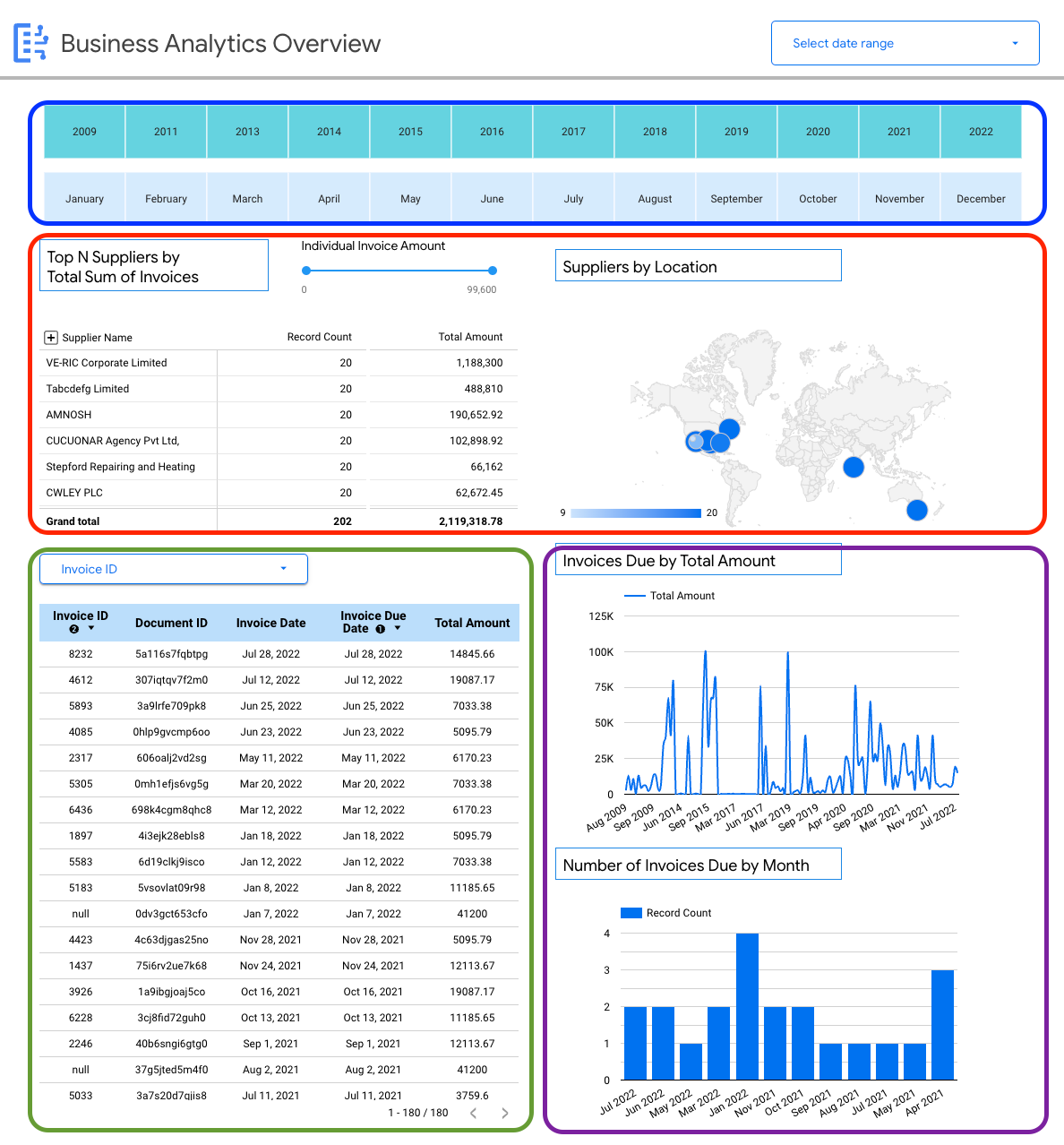
Puedes ver detalles específicos del esquema en las facturas, por ejemplo:
- Proveedores principales según los importes de las facturas
- Proveedores por ubicación
- Fechas de las facturas y sus correspondientes fechas de vencimiento
- Trends en las facturas mes a mes por importe y recuento de registros.
Conecta la fuente de datos a los paneles
Para usar estos ejemplos de paneles como punto de partida para visualizar tu conjunto de datos, puedes conectar tu fuente de datos desde BigQuery.
Antes de conectar los paneles de muestra a tu fuente de datos de BigQuery, asegúrate de haber accedido a tu cuenta asociada con tu entorno de Google Cloud.

Selecciona el botón destacado para mostrar las opciones del menú desplegable.

Selecciona Crear una copia.
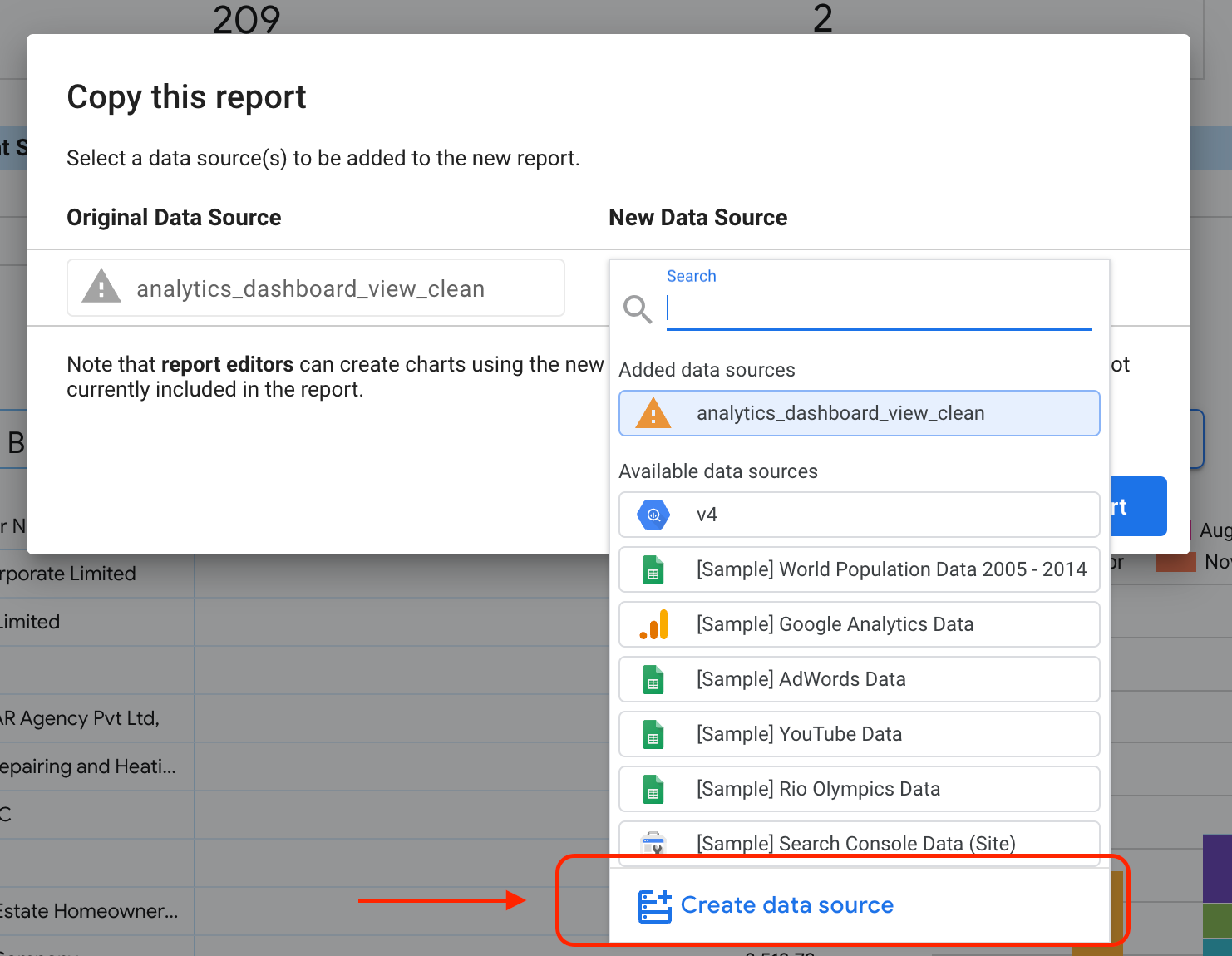
En la subsección Fuente de datos nueva, selecciona Crear fuente de datos.
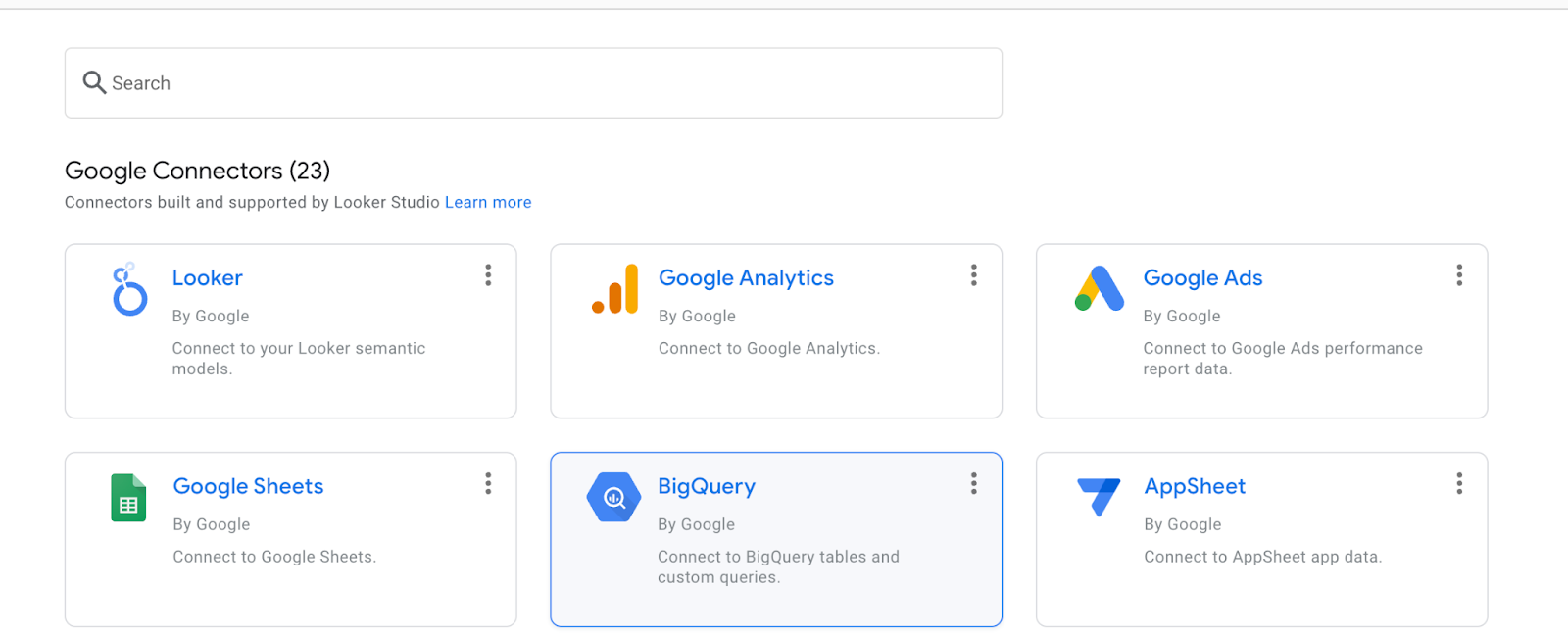
Selecciona BigQuery.
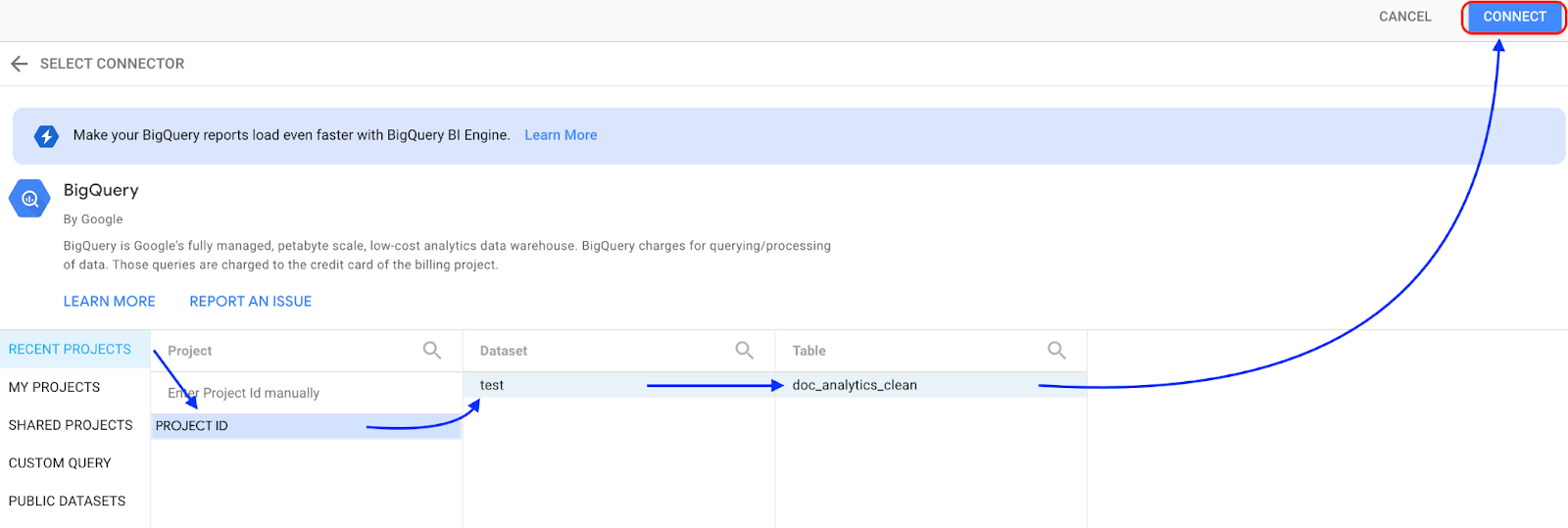
Selecciona el proyecto en el que se almacena tu conjunto de datos y, luego, sigue las indicaciones para seleccionar tu conjunto de datos y tu tabla. Haz clic en Conectar.

Haz clic en Agregar al informe.
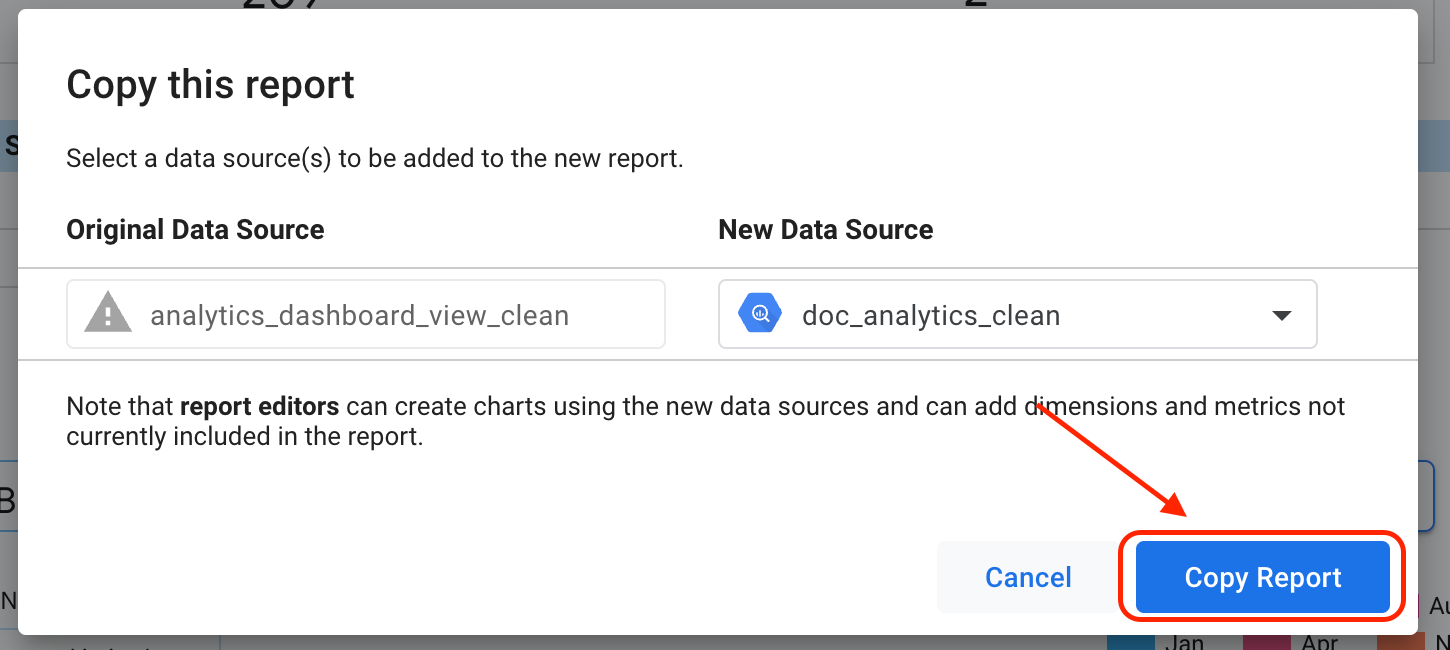
Haz clic en Copiar informe.
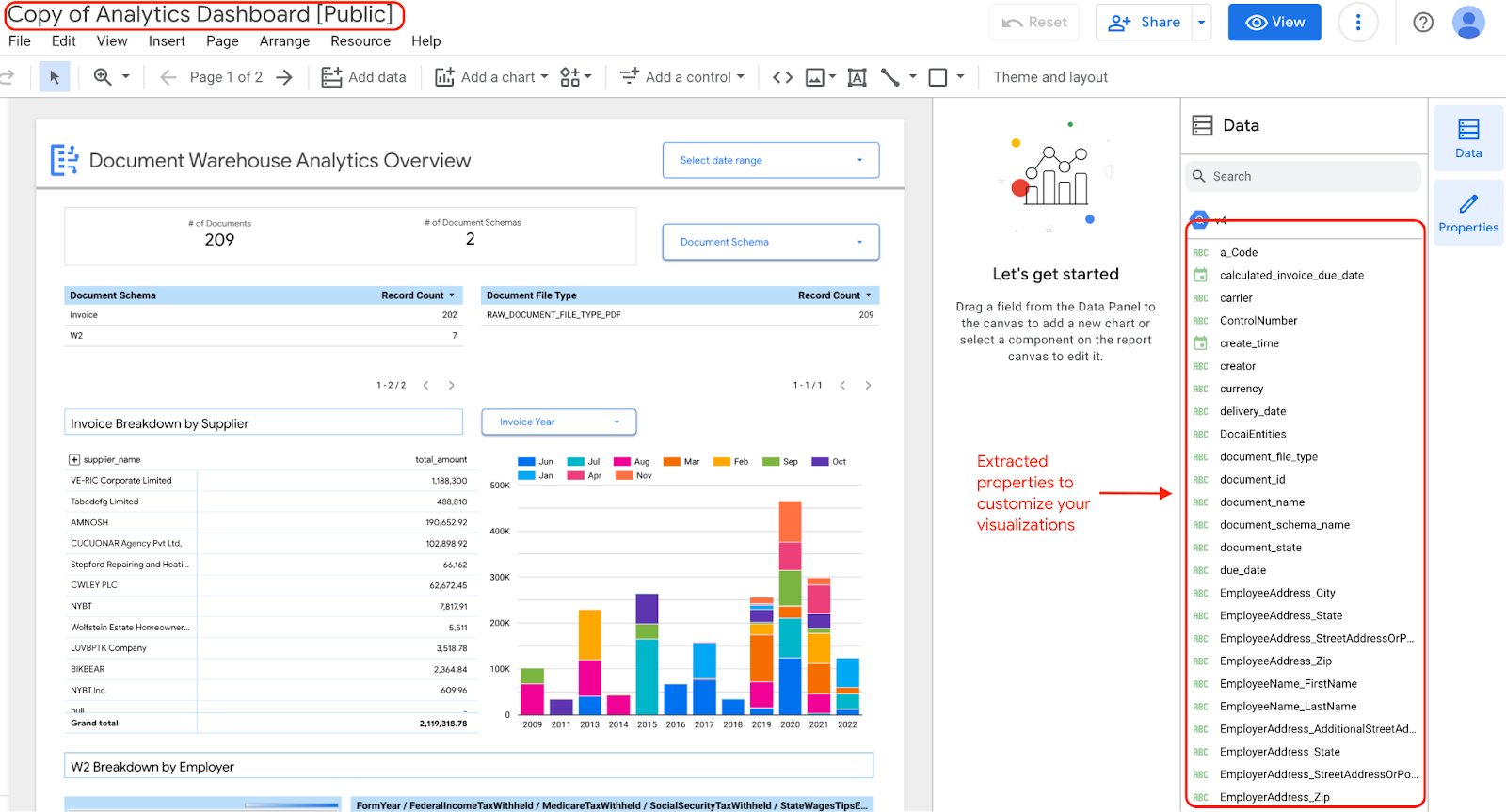
Si decides editar y actualizar los widgets de tu panel, puedes hacerlo, ya que tienes una copia del panel con las propiedades extraídas.