
Einführung in den BigQuery-Connector
Mit dem BigQuery-Connector können Sie die in Document AI Warehouse gespeicherten Metadaten des Dokuments (einschließlich Eigenschaften) in Ihre BigQuery-Tabelle exportieren. Mit Ihren Daten in BigQuery können Sie Analysen ausführen und Berichte und Dashboards erstellen, um Geschäftsentscheidungen zu treffen.
Um den BigQuery-Connector zu aktivieren, müssen Sie eine BigQuery-Tabelle mit den erforderlichen Berechtigungen einrichten und die asynchronen Aufgaben über die API konfigurieren. Der BigQuery-Connector exportiert die Daten aus Document AI Warehouse in Ihre BigQuery-Tabellen.
Vorbereitung
Richten Sie Document AI Warehouse ein und nehmen Sie Ihre Dokumente auf. Weitere Informationen finden Sie in der Kurzanleitung.
Das Projekt, in dem Ihre BigQuery-Tabelle gehostet wird, muss dasselbe Projekt sein, das von Document AI Warehouse zum Speichern Ihrer Dokumente verwendet wird. Mit anderen Worten: Die Daten müssen immer aus Document AI Warehouse in die BigQuery-Tabelle im selben Projekt exportiert werden.
Sie müssen im Projekt die Rolle Owner (roles/owner) oder die Berechtigungen resourcemanager.projects.getIamPolicy und resourcemanager.projects.setIamPolicy haben.
Berechtigungen.
um Zugriff zu erhalten.BigQuery-Zugriff einrichten
Binden Sie das Dienstkonto doc-ai-warehouse-dw-bq-connector@system.gserviceaccount.com
an die Rolle BigQuery Admin:
gcloud projects add-iam-policy-binding <var>PROJECT_ID</var> --member serviceAccount:doc-ai-warehouse-dw-bq-connector@system.gserviceaccount.com --role=roles/bigquery.admin
BigQuery-Dataset und -Tabelle einrichten
Richten Sie ein BigQuery-Dataset und eine BigQuery-Tabelle für Document AI Warehouse ein, um die Daten zu exportieren. Wenn Sie kein BigQuery-Dataset haben, folgen Sie der Anleitung zum Erstellen von Datasets.
Erstellen Sie eine BigQuery-Tabelle in Ihrem BigQuery-Dataset. Folgen Sie der BigQuery Anleitung, um Tabellen mit den DDL-Beispielanweisungen zu erstellen:
CREATE TABLE `PROJECT_ID.DATASET_NAME.TABLE_NAME`
(
project_number INT64,
location STRING,
mod_type STRING,
document_id STRING,
document_json JSON,
create_time TIMESTAMP,
creator STRING,
update_time TIMESTAMP,
updater STRING,
document_state STRING,
export_time TIMESTAMP
)
PARTITION BY TIMESTAMP_TRUNC(export_time, HOUR)
OPTIONS(
partition_expiration_days=150,
description="table partitioned by export_time on hour with expiry"
);
Die DDL erstellt eine neue BigQuery-Tabelle für Sie. Die Tabelle ist stündlich zeitpartitioniert und die Partition wird nach 150 Tagen gelöscht.
BigQuery-Connector konfigurieren
Datenexportkonfiguration erstellen
Mit der folgenden Anleitung wird ein neuer Datenexportjob erstellt, der die asynchronen Jobs zum Exportieren von Daten einrichtet. Wir empfehlen, für jeden neuen Datenexportjob mit einer leeren Tabelle zu beginnen. Weitere Informationen zur Konfiguration finden Sie in der API Referenz.
Sie haben die folgenden Ausführungsoptionen. Sie können mit FREQUENCY konfiguriert werden.
Weitere Informationen finden Sie in der API
Referenz.
- ADHOC:Der Job wird nur einmal ausgeführt. Alle Daten werden in Ihre BigQuery-Tabelle exportiert.
- DAILY:Der Job wird täglich ausgeführt. Bei der ersten Ausführung werden alle Daten in Ihre BigQuery-Tabelle exportiert. Nach Abschluss des ersten Exports werden nur die Datenänderungen des Vortags (oder die Differenz seit der letzten erfolgreichen Synchronisierung) in Ihre BigQuery-Tabelle exportiert.
- HOURLY:Der Job wird stündlich ausgeführt. Bei der ersten Ausführung werden alle Daten in Ihre BigQuery-Tabelle exportiert. Nach Abschluss des ersten Exports werden nur die Datenänderungen der letzten Stunde (oder die Differenz seit der letzten erfolgreichen Synchronisierung) in Ihre BigQuery-Tabelle exportiert.
Ersetzen Sie diese Werte in den folgenden Anfragedaten:
- PROJECT_NUMBER: Ihre Google Cloud Projektnummer
- LOCATION: Ihr Document AI Warehouse-Standort (z. B. `us`)
- DATASET_LOCATION: Ihr Dataset-Standort
- DATASET_NAME: Ihr Dataset-Name
- TABLE_NAME: Ihr Tabellenname
-
FREQUENCY: einer der Werte
ADHOC,DAILYoderHOURLY.
JSON-Text der Anfrage:
{
"projectNumber": PROJECT_NUMBER,
"location": "DATASET_LOCATION",
"dataset": "DATASET_NAME",
"table": "TABLE_NAME",
"frequency": "FREQUENCY",
"state": "ACTIVE"
}
Wenn Sie die Anfrage senden möchten, maximieren Sie eine der folgenden Optionen:
Sie sollten eine JSON-Antwort ähnlich wie diese erhalten:
Jobausführung
Nachdem Sie einen Job erfolgreich erstellt haben, wird er gemäß Ihrer Konfiguration ausgeführt. Die Jobs werden asynchron ausgeführt, da die Ausführung Zeit in Anspruch nimmt. Je nach Menge der zu exportierenden Daten kann es einige Zeit dauern, bis die erste Ausführung abgeschlossen ist. Bei einem täglichen Job kann es bis zu 24 Stunden dauern, bis die Ergebnisse in der BigQuery-Tabelle angezeigt werden.
Datenexportkonfiguration löschen
Mit dem folgenden Befehl wird ein von Ihnen erstellter Job gelöscht (archiviert).
Ersetzen Sie diese Werte in den folgenden Anfragedaten:
- PROJECT_NUMBER: Ihre Google Cloud Projektnummer
- LOCATION: Ihr Document AI Warehouse-Standort (z. B. `us`)
- JOB_ID: Ihre Job-ID aus der Antwort, die Sie beim Erstellen des Jobs erhalten haben
JSON-Text der Anfrage:
{}
Wenn Sie die Anfrage senden möchten, maximieren Sie eine der folgenden Optionen:
Sie sollten eine JSON-Antwort ähnlich wie diese erhalten:
Danach wird Ihr Exportjob gelöscht (archiviert) und Document AI Warehouse führt ihn nicht mehr aus.
In BigQuery aufgenommene Daten untersuchen
Wenn Sie Dokumentmetadaten und -eigenschaften für Ihre Analysen in separate Tabellenfelder in BigQuery extrahieren möchten, können Sie die folgenden DDL-Beispielabfragen verwenden. Diese extrahierten Felder können auch in Data Studio oder einem beliebigen BI-Dashboard-Tool verwendet werden, um Beziehungen in den Daten zu visualisieren.
Schlüsselfelder aus document_json extrahieren
Mit dieser Abfrage werden relevante Felder aus dem Datenexport ausgewählt, einschließlich Schlüsselfeldern aus Dokumentmetadaten (gespeichert im Feld „document_json“).
DROP VIEW IF EXISTS
`DATASET_NAME.VIEW_NAME_1`;
CREATE VIEW
`DATASET_NAME.VIEW_NAME_1` AS
SELECT
project_number,
document_id,
mod_type,
create_time,
update_time,
location,
creator,
updater,
document_state,
SPLIT(JSON_EXTRACT_SCALAR(document_json,'$.documentSchemaName' ), '/')[SAFE_OFFSET(ARRAY_LENGTH(SPLIT(JSON_EXTRACT_SCALAR(document_json,'$.documentSchemaName' ), '/')) - 1)] AS document_schema_name,
JSON_EXTRACT_SCALAR(document_json,'$.name') AS document_name,
JSON_EXTRACT_SCALAR(document_json,'$.rawDocumentFileType')
AS raw_document_file_type,
JSON_EXTRACT(document_json,'$.properties') AS properties
FROM
`DATASET_NAME.SYSTEM_METADATA_AND_DOC_PROPERTIES_TABLE_EXPORT_NAME`;
Eigenschaften aus document_json aufheben
Mit dieser Abfrage werden Eigenschaften aus den Dokumentmetadaten (document_json) aufgehoben, um Schlüssel-Wert-Paare zu erstellen (Eigenschaftsname, Wert). Diese Schlüssel-Wert-Paare werden in der nächsten Abfrage in einzelne Tabellenfelder umgewandelt, um die Datenexploration auf Eigenschaftsebene und die Dashboard-Visualisierung zu ermöglichen.
DROP VIEW IF EXISTS
`DATASET_NAME.VIEW_NAME_2`;
CREATE VIEW
`DATASET_NAME.VIEW_NAME_2` AS
SELECT
* EXCEPT(key_value_pair,
properties,raw_document_file_type)
FROM (
SELECT
*,
REPLACE(JSON_VALUE(key_value_pair,'$.name'),'/','-') property_name,
-- Note: values are either text OR float values
CASE
WHEN JSON_VALUE(key_value_pair,'$.textValues.values[0]') IS NULL THEN JSON_VALUE(key_value_pair,'$.floatValues.values[0]')
ELSE
JSON_VALUE(key_value_pair,'$.textValues.values[0]')
END
AS value,
CASE
WHEN raw_document_file_type IS NULL THEN "RAW_DOCUMENT_FILE_TYPE_UNSPECIFIED"
ELSE
raw_document_file_type
END
AS document_file_type
FROM
`DATASET_NAME.VIEW_NAME_1`,
UNNEST(JSON_EXTRACT_ARRAY(properties)) AS key_value_pair);
Eigenschaften aus document_json pivotieren, um Tabellenfelder in BigQuery zu erstellen
Mit den folgenden Schritten wird eine Tabelle mit allen Dokumenteigenschaften erstellt, die durch Pivotieren der Eigenschaften und zugehörigen Werte in einzelne Tabellenfelder umgewandelt wurden. Die Ergebnisse dieser Tabelle können verwendet werden, um durch nachfolgende Abfragen in Data Studio und anderen BI-Visualisierungstools weitere Erkenntnisse zu gewinnen.
DECLARE
property_field STRING;
-- Extracting distinct property_names from the previous view and storing it in property_field, declared above
EXECUTE IMMEDIATE
"""SELECT string_agg(CONCAT("'",property_name,"'")) from (select distinct property_name from DATASET.VIEW_NAME_2)""" INTO property_field;
DROP TABLE IF EXISTS `DATASET_NAME.ANALYTICS_TABLE_NAME`;
-- Creating pivot table with the aid of extracted distinct property_names
-- Casting numerical values to float/int
-- Pivot on property_name and value (ie. create a new column for each of the property_name, substitute the value)
EXECUTE IMMEDIATE
FORMAT ("""
CREATE TABLE `DATASET_NAME.ANALYTICS_TABLE_NAME` AS
SELECT * FROM `DATASET_NAME.VIEW_NAME_2`
PIVOT(min(value) FOR property_name IN (%s))""", property_field);
Verfahren zur Datenbereinigung und -transformation (geschäftsspezifisch)
Je nach in BigQuery aufgenommenen Daten müssen Sie möglicherweise zusätzliche Verfahren zur Datenbereinigung und -transformation durchführen, um weitere Analysen zu ermöglichen. Solche Verfahren variieren von Fall zu Fall (Dataset zu Dataset) und sollten nach Bedarf durchgeführt werden.
Beispiele für Verfahren zur Datenbereinigung:
- Datumsformate vereinheitlichen
- Eigenschaftswerte zusammenführen
- Datentypen in Strings, Gleitkommazahlen und Ganzzahlen umwandeln
Daten in Data Studio visualisieren
Nachdem Ihre Daten in BigQuery extrahiert, bereinigt und transformiert wurden, kann Ihr endgültiges Dataset zur visuellen Analyse in Data Studio exportiert werden.
Looker-Dashboards
Die Beispiel-Dashboards zeigen mögliche Visualisierungen, die aus Ihrem Dataset erstellt werden können. In diesem Szenario besteht der Beispiel-Datenexport aus Document AI Warehouse aus W2s und Rechnungen (zwei Schemas).
Öffentlich zugängliche Looker-Dashboards
Beispielansicht: Document AI Warehouse-Analyseübersicht
Das folgende Dashboard bietet Ihnen einen allgemeinen Überblick über die verschiedenen Dokumente, die in Ihre Document AI Warehouse-Instanz aufgenommen wurden.
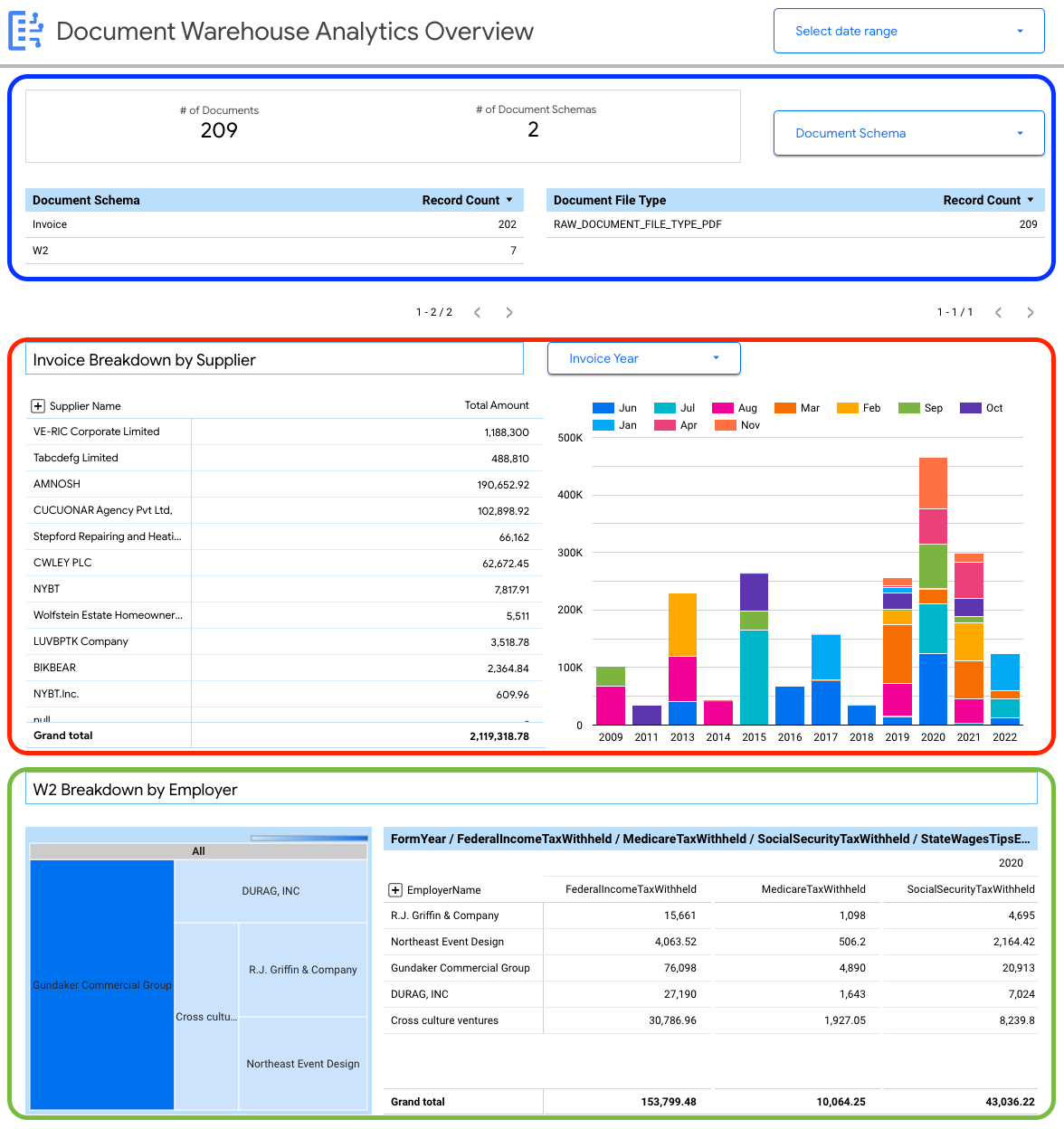
Sie können Details auf Dokumentebene ansehen, darunter:
- Gesamtzahl der Dokumente
- Gesamtzahl der Dokumentschemas
- Anzahl der Datensätze nach Dokumentschema
- Dokumentdateityp (z. B. PDF, Text, nicht angegebener Typ)
Außerdem können Sie Eigenschaften verwenden, die aus den Dokumentmetadaten (document_json) extrahiert wurden, um wichtige Aufschlüsselungen für die in BigQuery aufgenommenen Rechnungen und W2s zu erstellen.
Beispielansicht: Geschäftsspezifisches Dashboard mit Analysen (Rechnungen)
Das folgende Dashboard bietet dem Nutzer einen detaillierten Einblick in ein einzelnes Dokumentschema (Rechnungen), um Analysen zu allen in Document AI Warehouse aufgenommenen Rechnungen zu ermöglichen.
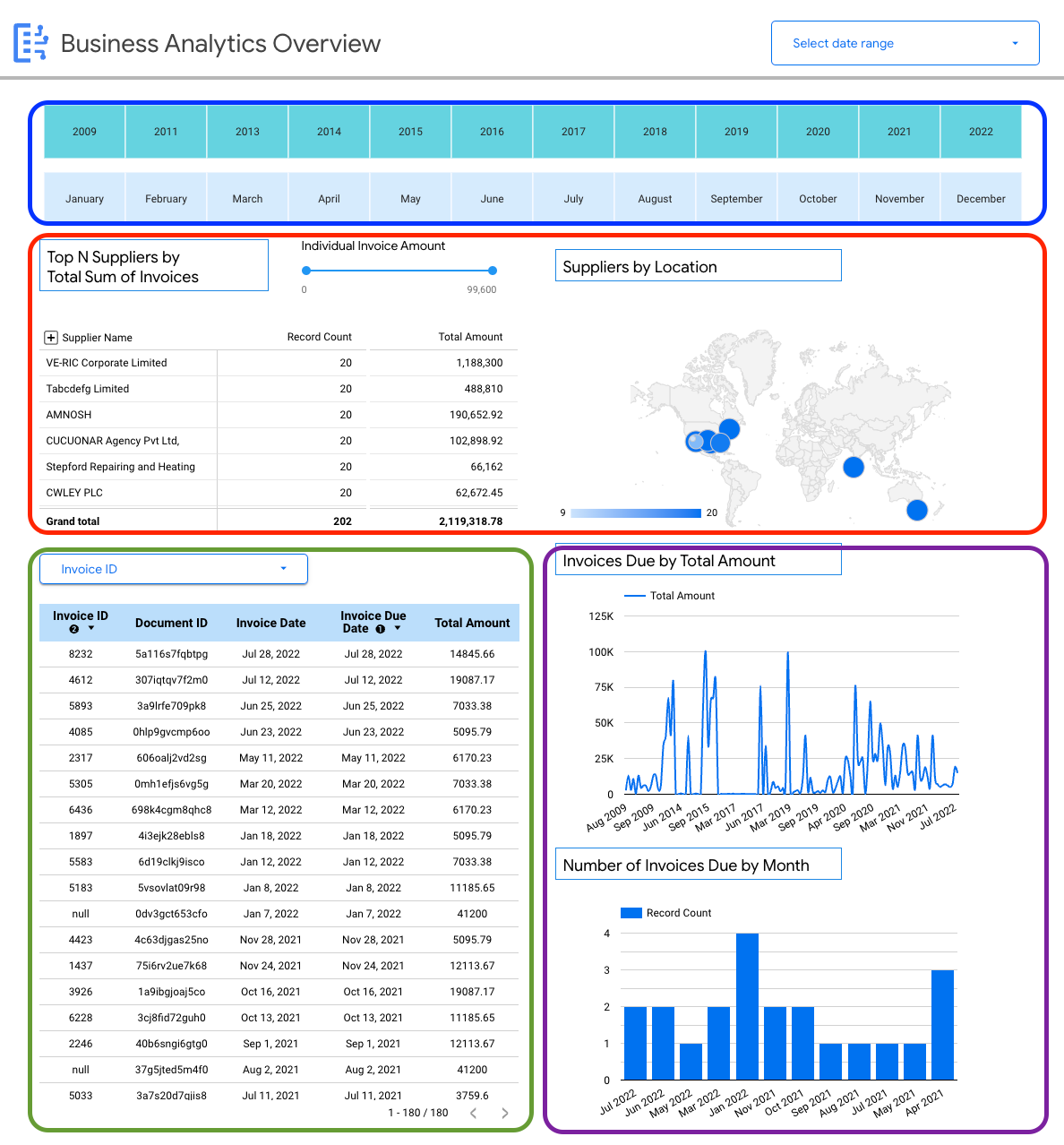
Sie können schemaspezifische Details zu Rechnungen ansehen, z. B.:
- Top-Lieferanten nach Rechnungsbeträgen
- Lieferanten nach Standort
- Rechnungsdaten und die entsprechenden Fälligkeitsdaten
- Trends bei Rechnungen im Monatsvergleich nach Betrag und Anzahl der Datensätze
Datenquelle mit Dashboards verbinden
Wenn Sie diese Dashboard Beispiele als Ausgangspunkt für die Visualisierung Ihres Datasets verwenden möchten, können Sie Ihre Datenquelle aus BigQuery verbinden.
Bevor Sie die Beispiel-Dashboards mit Ihrer BigQuery-Datenquelle verbinden, müssen Sie in Ihrem Konto angemeldet sein, das mit Ihrer Google Cloud Umgebung verknüpft ist.

Wählen Sie die hervorgehobene Schaltfläche aus, um die Drop-down-Optionen aufzurufen.

Wählen Sie Kopie erstellen aus.
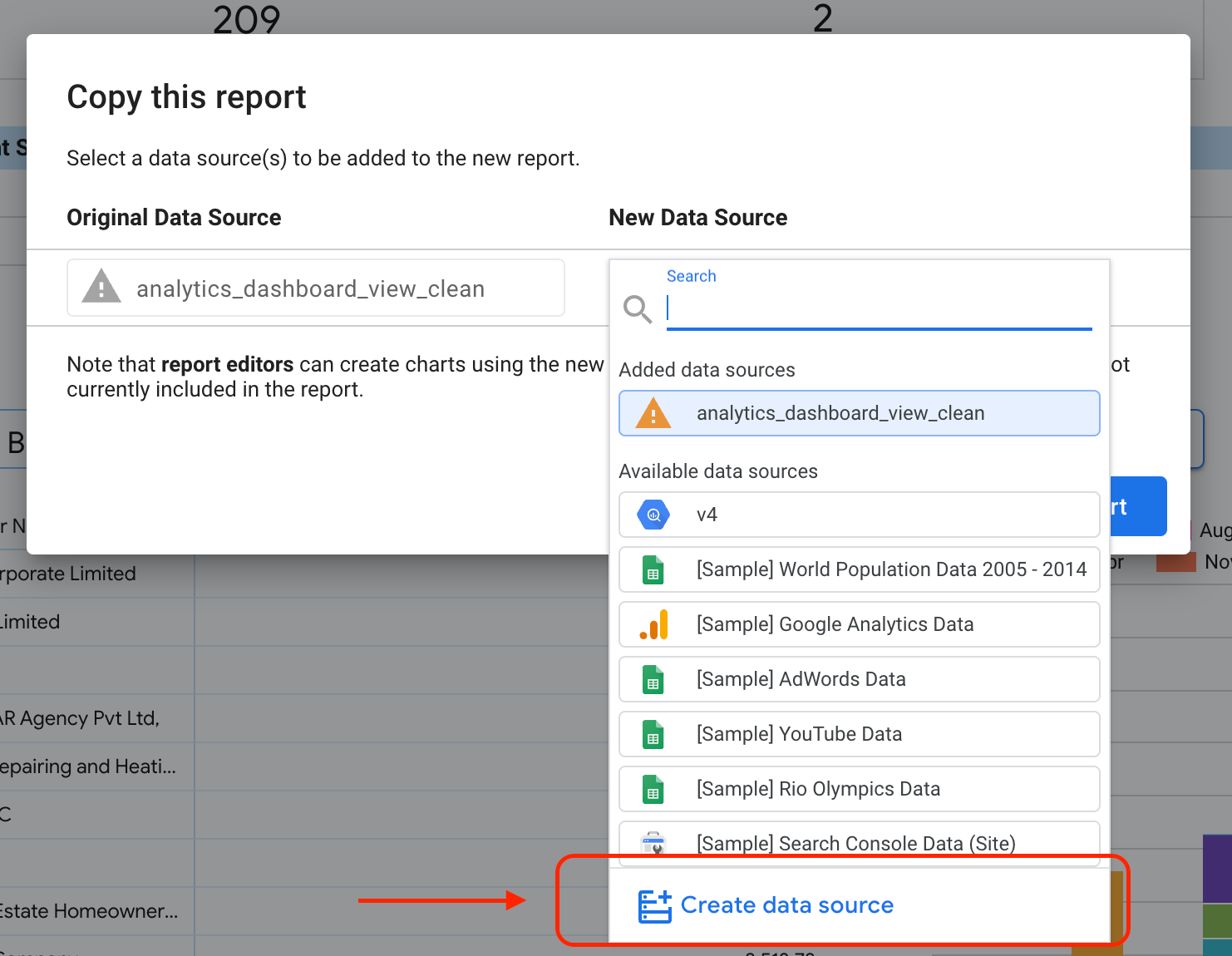
Wählen Sie im Unterabschnitt „Neue Datenquelle“ die Option Datenquelle erstellen aus.
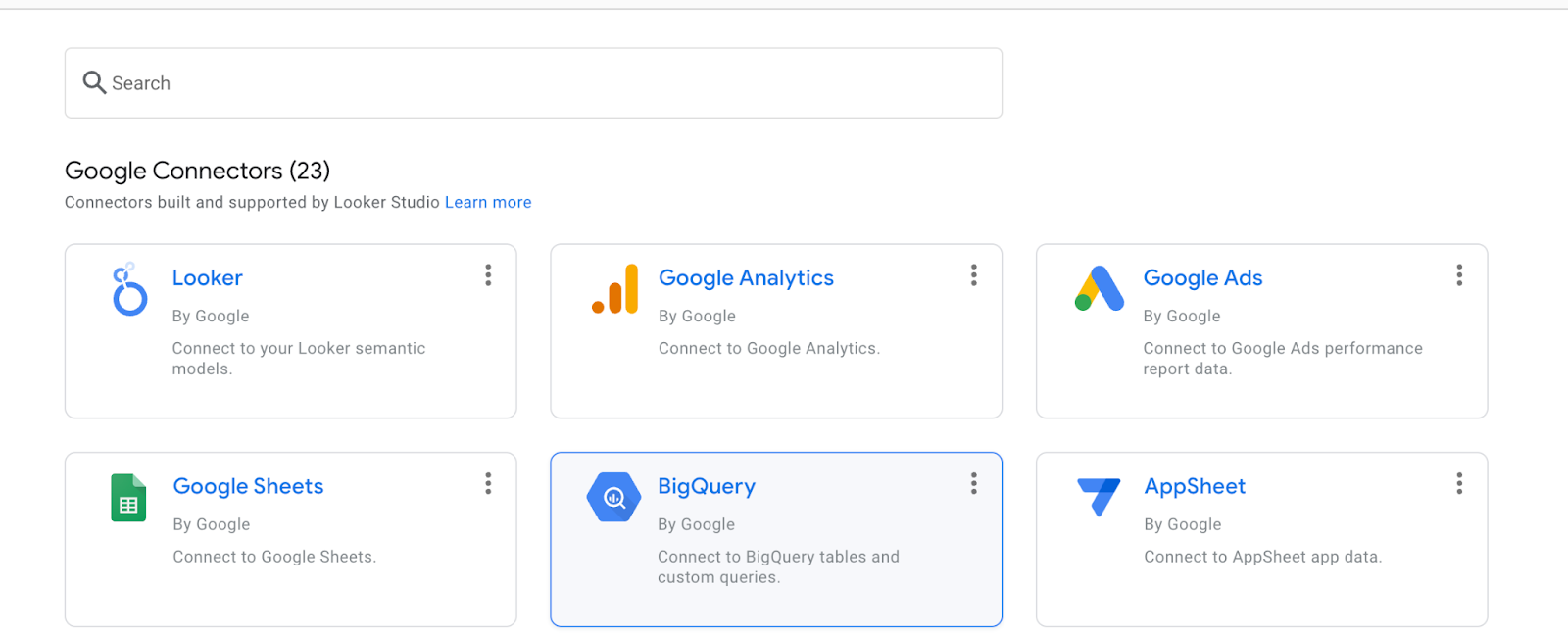
Wählen Sie BigQuery aus.
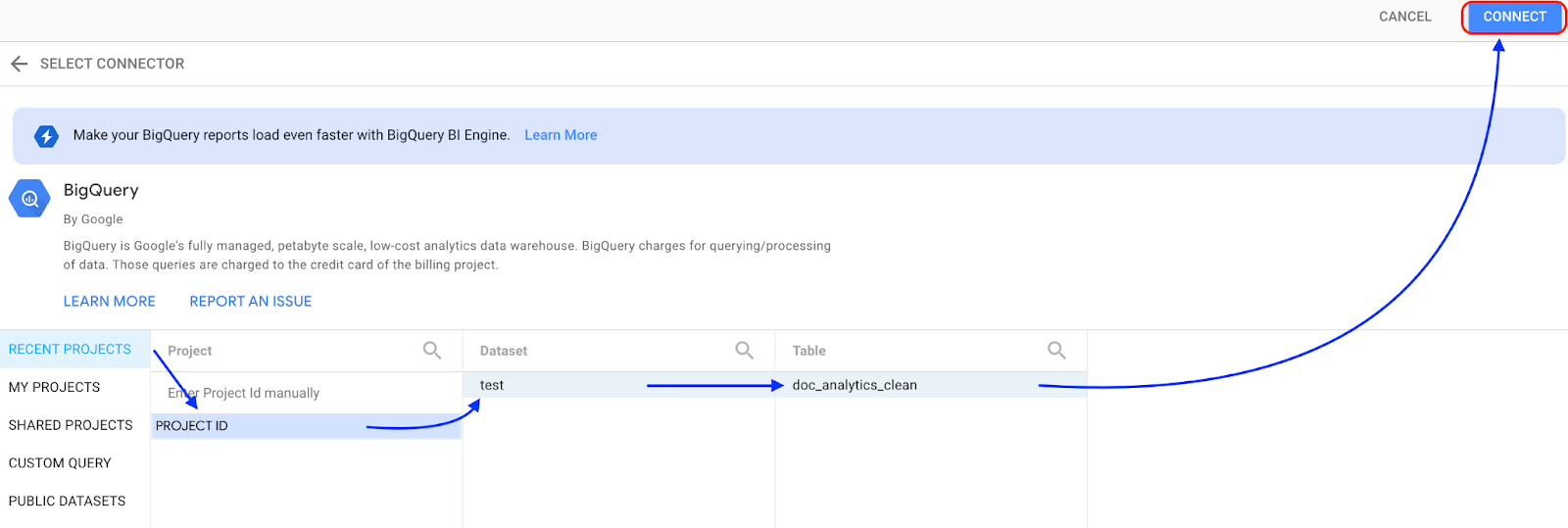
Wählen Sie das Projekt aus, in dem Ihr Dataset gespeichert ist, und folgen Sie der Anleitung, um Ihr Dataset und Ihre Tabelle auszuwählen. Klicken Sie auf Verbinden.

Klicken Sie auf Zum Bericht hinzufügen.
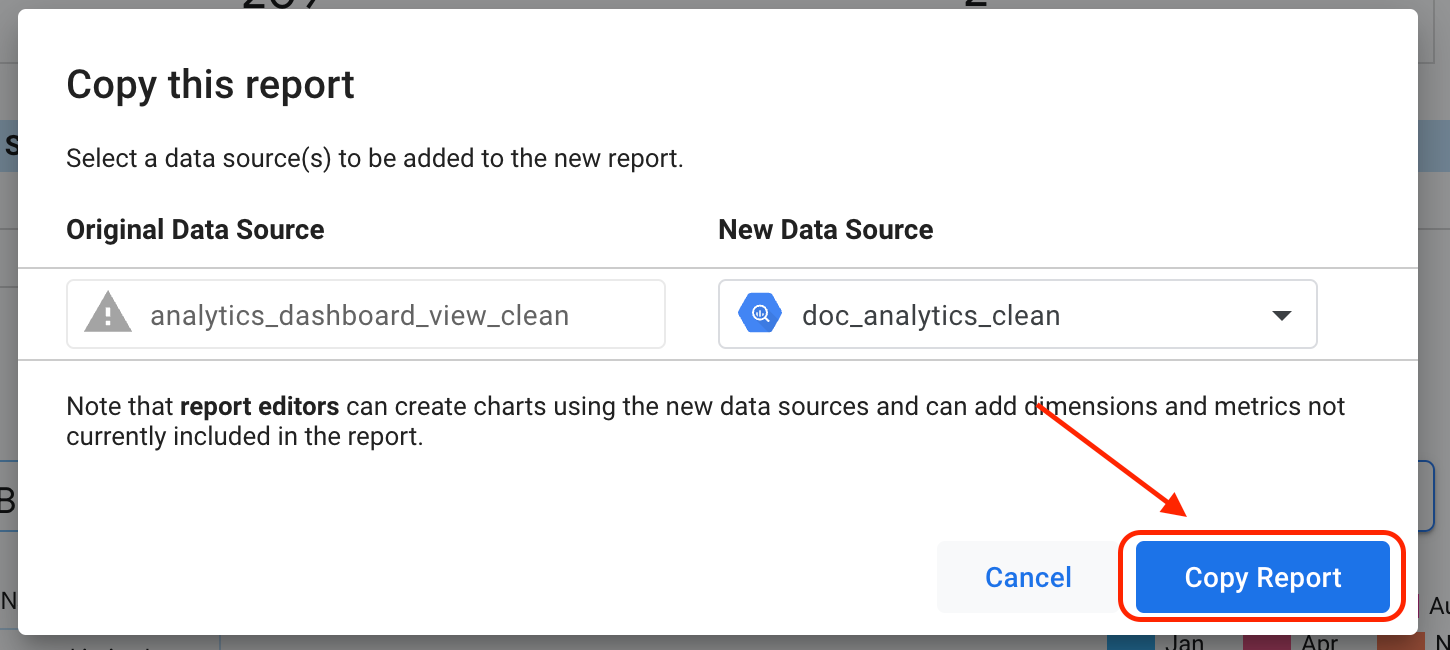
Klicken Sie auf Bericht kopieren.
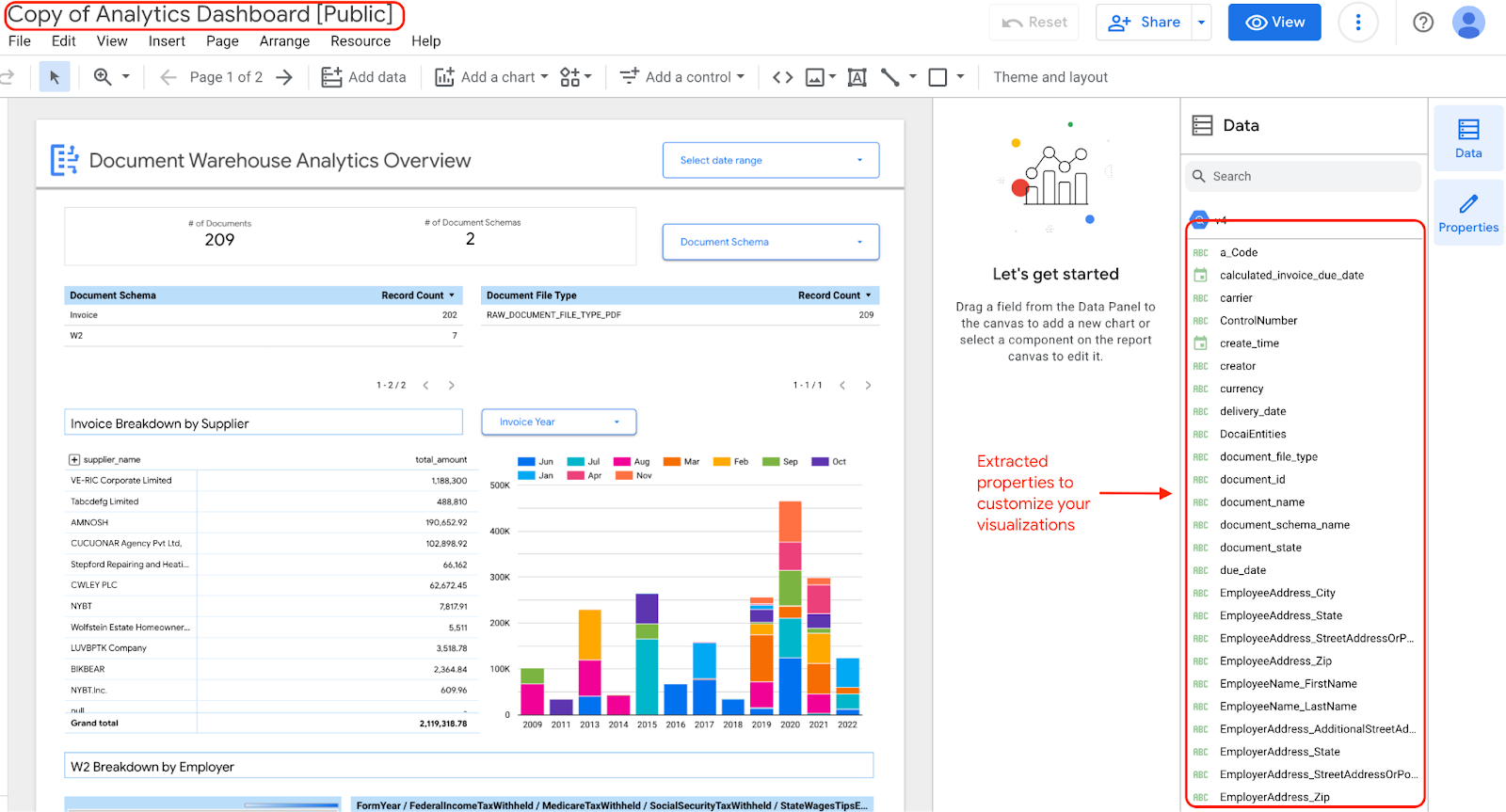
Wenn Sie die Widgets in Ihrem Dashboard bearbeiten und aktualisieren möchten, können Sie es bearbeiten, da Sie eine Kopie des Dashboards mit den extrahierten Eigenschaften haben.