
Document AI 可讓您使用自己的訓練資料訓練新的處理器版本,並根據自己的測試資料評估處理器版本的品質。
如果您想使用自訂處理器,這項功能就非常實用。Document AI 針對您的文件類型提供處理器,但您可以進階訓練自訂版本,以滿足需求。
訓練和評估通常會同步進行,以便反覆運算,最終產生高品質且可用的處理器版本。
Document AI
Document AI 可讓您建構自己的自訂擷取器,從特定類型的文件中擷取實體,例如菜單中的項目,或是履歷表中的姓名和聯絡資訊。
與其他處理器不同,自訂處理器不會隨附任何預先訓練的處理器版本,因此必須從頭訓練版本,才能處理文件。
如要開始使用 Document AI,請參閱「建立自訂處理器」。
進階訓練處理器
您可以進階訓練新的處理器版本,提高資料準確率、從文件中擷取其他自訂欄位,以及新增語言支援。
升級訓練會對 Google 預先訓練的處理器版本套用遷移學習,通常需要的資料量少於從頭開始訓練。
如要開始,請參閱「對預先訓練的處理器展開進階訓練」。
支援的處理器
並非所有專用處理器都支援升級訓練。這些處理器支援訓練。
資料注意事項和建議
資料的品質和數量會決定訓練、再訓練和評估的品質。
取得一組具代表性的實際文件,並提供足夠的高品質標籤,通常是這個程序中最耗時且耗費資源的部分。
文件數量
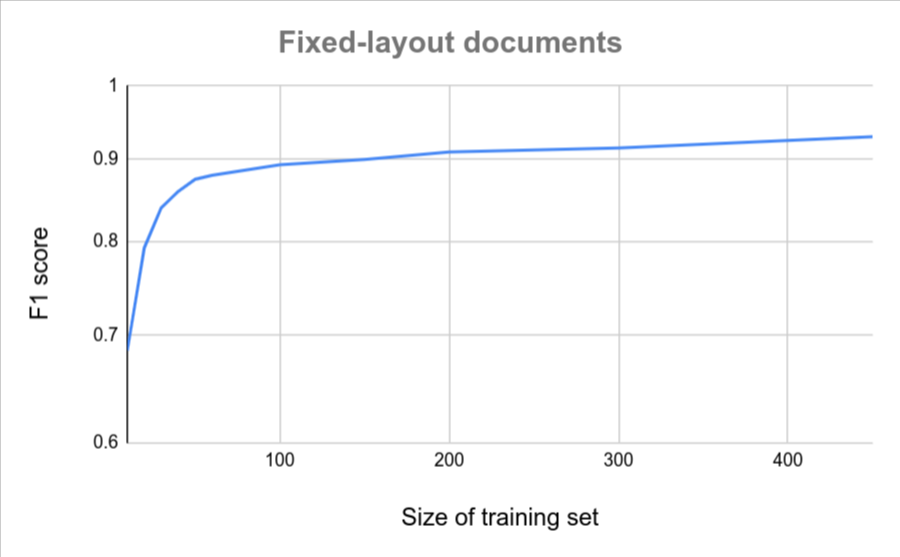
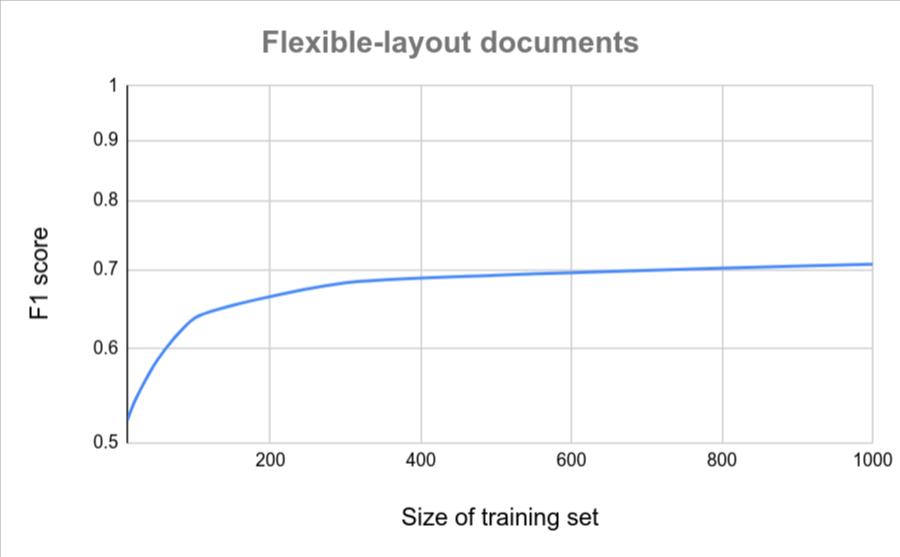
如果所有文件格式類似 (例如變異程度極低的固定表單),則只需較少文件即可達到準確度。變異程度越高,所需文件就越多。
下圖提供粗略估計,說明自訂文件擷取工具達到特定品質分數所需的檔案數量。
| 變化較小 | 變化較大 |
|---|---|
 |
 |
資料標籤
請考慮標記文件的選項,並確保有足夠的資源可為資料集中的文件加上註解。
訓練模型
自訂擷取器處理器可根據特定用途和可用的訓練資料,使用不同類型的模型。
- 自訂模型:使用加上標籤的訓練資料的模型。
- 以範本為基礎:版面配置固定的文件。
- 以模型為基礎:版面配置變化量適中的文件。
- 生成式 AI 模型:以預先訓練的基礎模型為基礎,只需少量額外訓練。
下表說明各模型類型對應的使用案例。
| 自訂模型 | 生成式 AI | ||
|---|---|---|---|
| 以範本為準 | 以模型為準 | ||
| 版面配置變化 | 無 | 低至中 | 高 |
| 任意形式文字的數量 (例如合約中的段落) | 低 | 低 | 高 |
| 所需訓練資料量 | 低 | 高 | 低 |
| 訓練資料有限時的準確度 | 較高 | 較低 | 較高 |
瞭解如何使用屬性說明微調處理器。
使用其他處理器的時機
在下列情況中,您可能需要考慮 Document AI Document AI Workbench 以外的選項,或調整工作流程。
- Document AI Workbench 不支援特定文字格式的輸入內容 (.txt、.html、.docx、.md 等)。考慮使用 Google Cloud中的其他預先建構或自訂語言處理服務,例如 Cloud Natural Language API。
- 自訂文件擷取器結構定義最多支援 150 個實體標籤。如果您的商業邏輯需要在結構定義中納入超過 150 個實體,建議訓練多個處理器,每個處理器都以實體子集為目標。
如何訓練處理器
假設您已建立支援訓練或進階訓練的處理器,並為資料集加上標籤,即可從頭開始訓練新的處理器版本。您也可以根據現有版本,對新的處理器版本進行進階訓練。
訓練處理器版本
網路使用者介面
前往 Google Cloud 控制台的處理器「Train」(訓練) 分頁。
按一下「編輯結構定義」,開啟「管理標籤」頁面。驗證處理器的標籤。
訓練時啟用的標籤會決定新版處理器擷取的實體。如果標籤在結構定義中處於非使用中狀態,即使文件已加上標籤,處理器版本也不會擷取該標籤。
在「Train」(訓練) 分頁中,按一下「View Label Stats」(查看標籤統計資料),然後驗證測試和訓練集。自動加上標籤、未加上標籤或未指派的文件不會用於訓練和評估。
按一下「訓練新版本」。
「版本名稱」會定義
processorVersion的name欄位。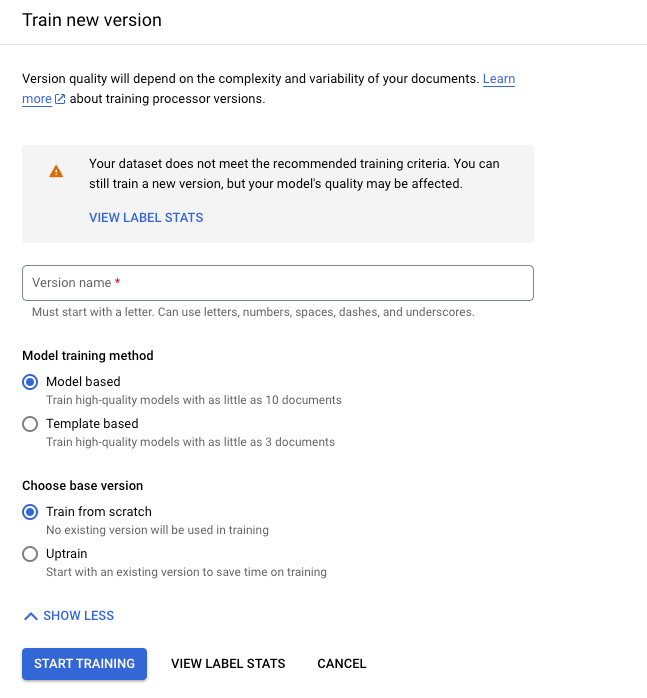
按一下「開始訓練」,等待系統訓練及評估新的處理器版本。
您可以在「管理版本」分頁中監控訓練進度:
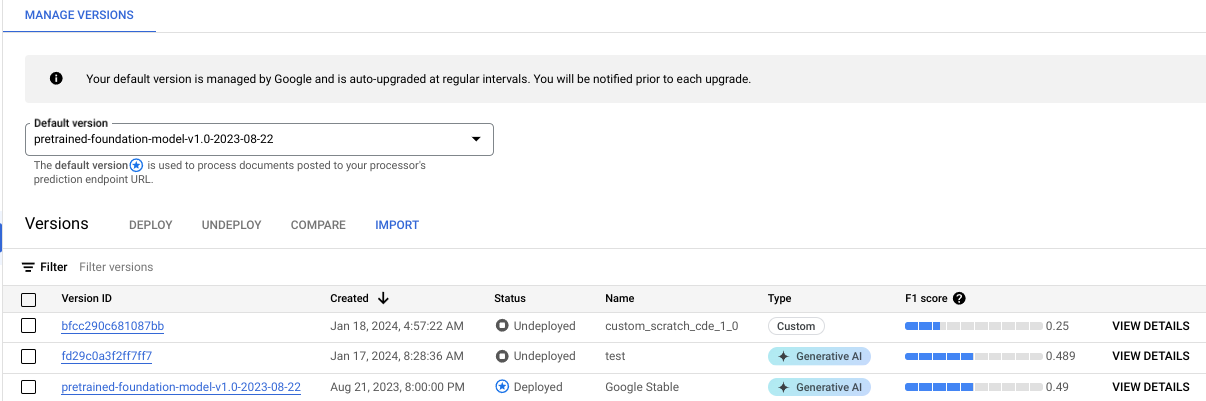
按一下「評估與測試」分頁標籤,查看新版處理器在測試集上的成效。詳情請參閱「評估處理器版本」。
Python
詳情請參閱 Document AI Python API 參考文件。
如要向 Document AI 進行驗證,請設定應用程式預設憑證。詳情請參閱「為本機開發環境設定驗證機制」。
部署及使用處理器版本
您可以部署及管理處理器版本,就像其他處理器版本一樣。詳情請參閱「管理處理器版本」。
部署完成後,您可以傳送處理要求至自訂處理器。
停用或刪除處理器
如果不想再使用處理器,可以停用或刪除。如果停用處理器,可以重新啟用。處理器刪除後就無法復原。
在左側的「Document AI」面板中,按一下「My processors」(我的處理器)。
按一下處理器名稱右側的垂直三點圖示,按一下「停用處理器」或「刪除處理器」。
詳情請參閱「管理處理器版本」。
升級微調的處理器版本
您可以將微調的自訂擷取器處理器版本升級至較新的基礎版本。新版基礎版本的設定會沿用舊版設定。 並使用原始版本中的處理器訓練資料。
在 Google Google Cloud 控制台中,前往處理器的「Deploy & use」(部署及使用) 分頁,然後選取要升級的支援處理器版本核取方塊。新處理器版本的設定將以這個版本為準。
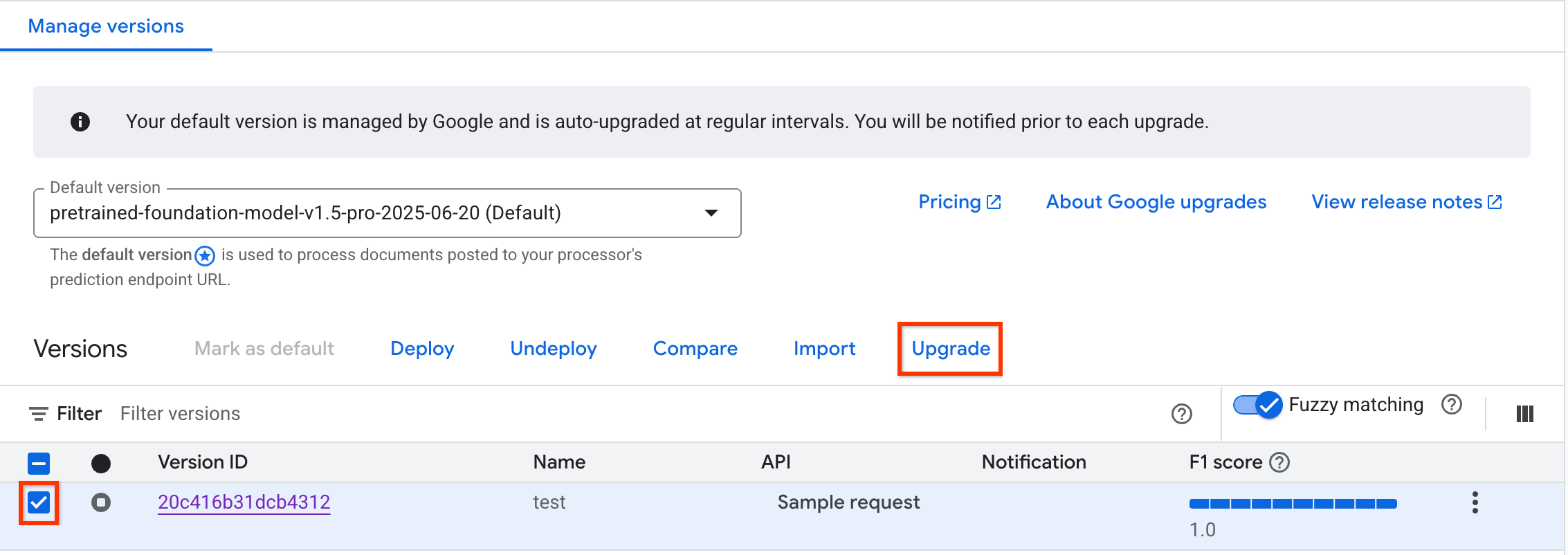
選取已啟用的「升級」。輸入新處理器版本的名稱和基礎版本。
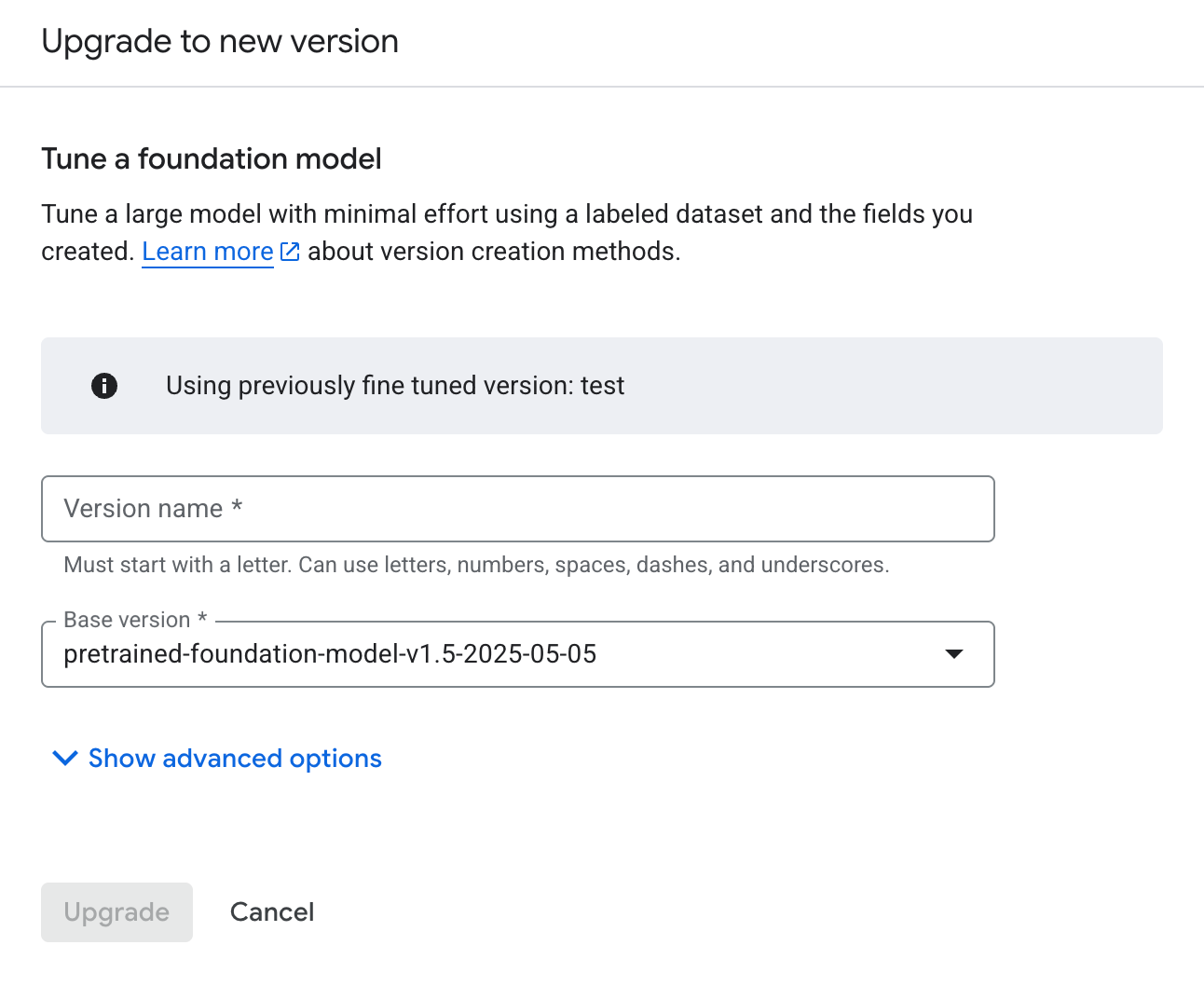
按一下「升級」,然後等待系統訓練新的處理器版本。
使用 API 升級
您也可以使用 API 呼叫,將微調的自訂擷取器處理器版本升級至較新的基礎版本。
curl
這個範例說明如何使用 TrainingMethod 中的 FoundationModelTuningOptions 欄位,遷移現有的微調 processor。
使用任何要求資料之前,請先替換以下項目,並使用處理器的 Document AI Google Cloud 控制台「總覽」分頁資訊。
- LOCATION:處理器的位置。
- PROJECT_ID:專案 ID。
- PROCESSOR_ID:處理器 ID。
- DISPLAY_NAME:處理器的全新顯示名稱。
- BASE_PROCESSOR_VERSION: 目前模型處理器版本的名稱
PROCESSOR_VERSION:要升級的現有處理器 ID
curl -X POST -v -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ "https://LOCATION-documentai.googleapis.com/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions:train" \ -d '{ "processor_version": { "display_name": "DISPLAY_NAME" }, "base_processor_version": "projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/BASE_PROCESSOR_VERSION", "foundation_model_tuning_options": { "train_steps": 10, "learning_rate_multiplier": 1, "previous_fine_tuned_processor_version_name": "projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION", } }'
訓練資料加密
Document AI 訓練資料會儲存在 Cloud Storage 中,且視需要可使用客戶管理的加密金鑰加密。
刪除訓練資料
Document AI 訓練工作完成後,儲存在 Cloud Storage 中的所有訓練資料會在兩天的保留期限過後失效。後續的資料刪除活動會遵循「資料刪除 Google Cloud」一文所述的程序。
定價
訓練或進修訓練都不會產生費用。您需要支付主機和預測費用。 詳情請參閱「Document AI 定價」。