
É necessário um conjunto de dados etiquetado de documentos para treinar, atualizar ou avaliar uma versão do processador.
Esta página descreve como criar um conjunto de dados, importar documentos e definir um esquema. Para etiquetar os documentos importados, consulte o artigo Etiquete documentos.
Esta página pressupõe que já criou um processador que suporta a preparação, a preparação adicional ou a avaliação. Se o seu processador for suportado, vê o separador Formar na Google Cloud consola.
Opções de armazenamento de conjuntos de dados
Pode escolher entre duas opções para guardar o seu conjunto de dados:
- Gerido pela Google
- Localização personalizada do Cloud Storage
A menos que tenha requisitos especiais (por exemplo, para manter documentos num conjunto de pastas com CMEK ativadas), recomendamos a opção de armazenamento mais simples gerida pela Google. Depois de criado, não é possível alterar a opção de armazenamento do conjunto de dados para o processador.
A pasta ou a subpasta de uma localização personalizada do Cloud Storage tem de começar vazia e ser tratada como estritamente de leitura. Quaisquer alterações manuais ao respetivo conteúdo podem tornar o conjunto de dados inutilizável, o que representa um risco de perda. A opção de armazenamento gerido pela Google não tem este risco.
Siga estes passos para aprovisionar a sua localização de armazenamento.
Armazenamento gerido pela Google (recomendado)
Apresente opções avançadas durante a criação de um novo processador.
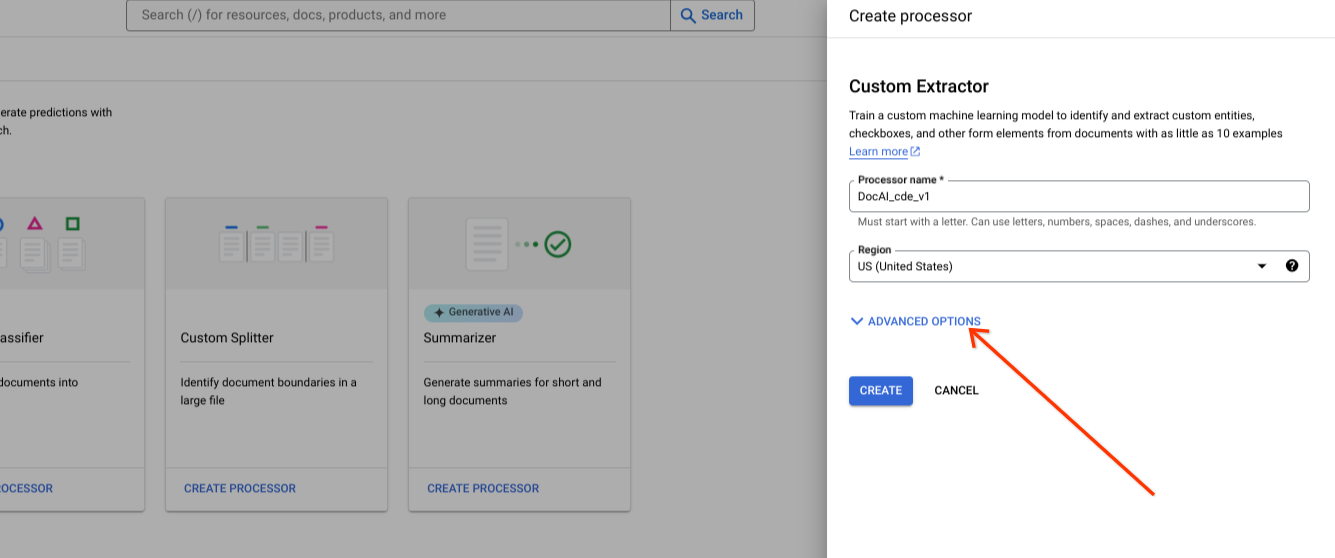
Mantenha a opção de grupo de botões de opção predefinida para o armazenamento gerido pela Google.

Selecione Criar.
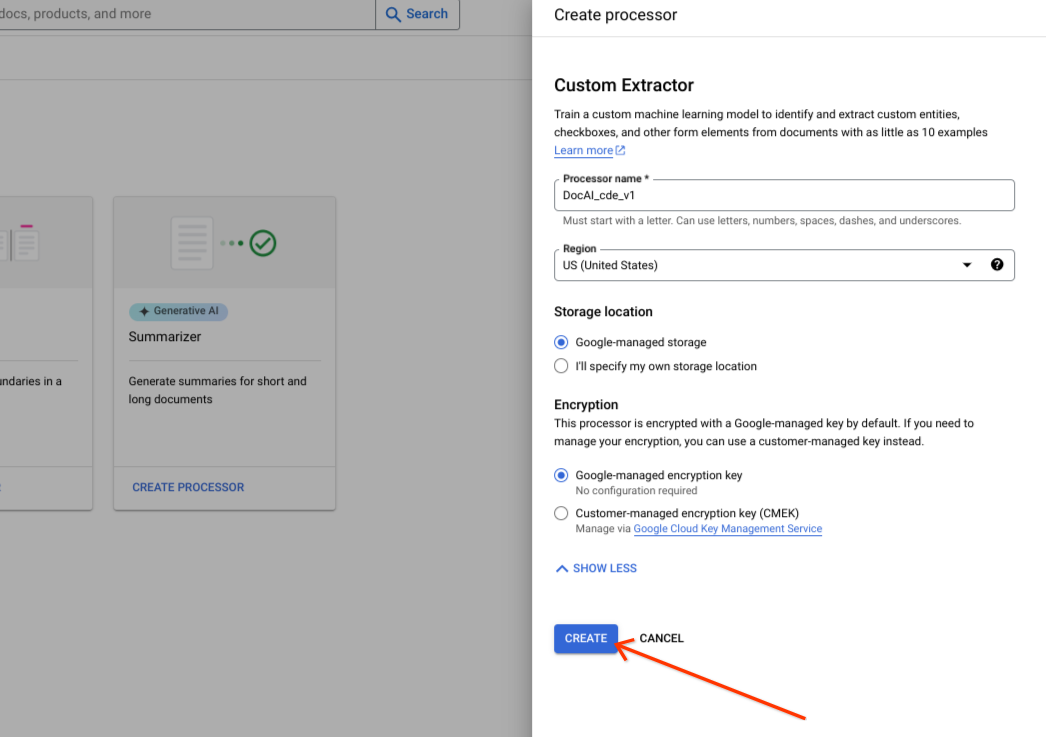
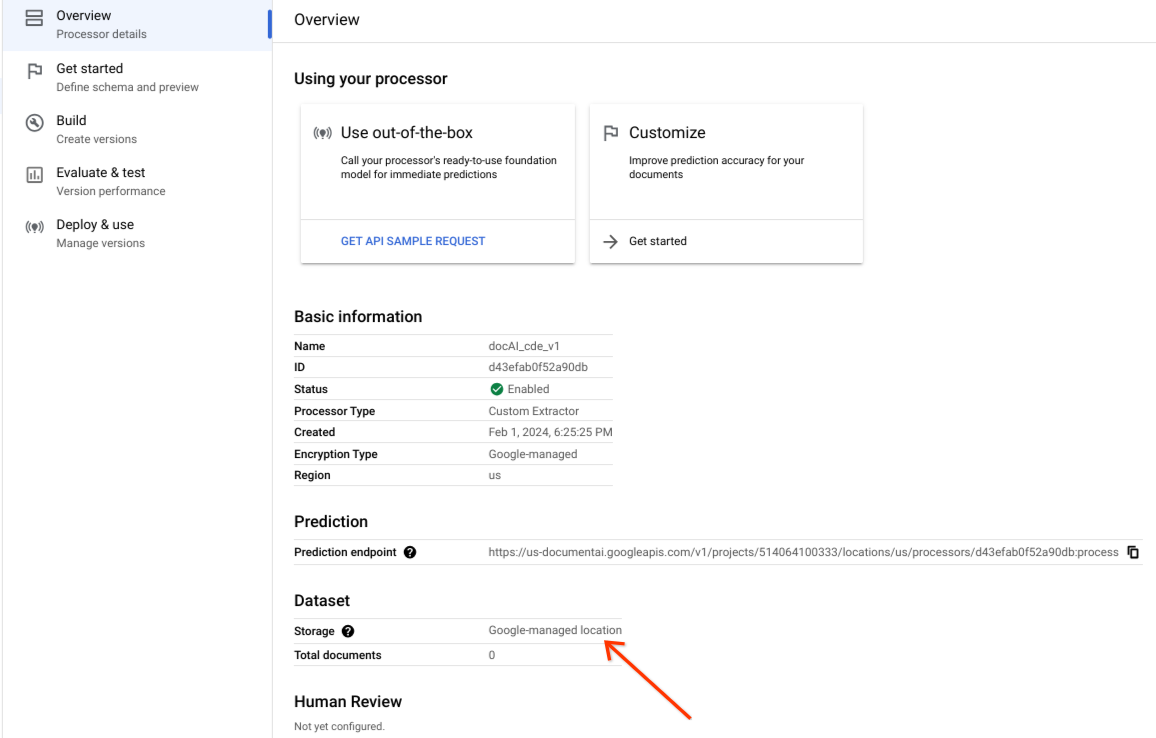
Confirme que o conjunto de dados foi criado com êxito e que a localização do conjunto de dados é uma localização gerida pela Google.
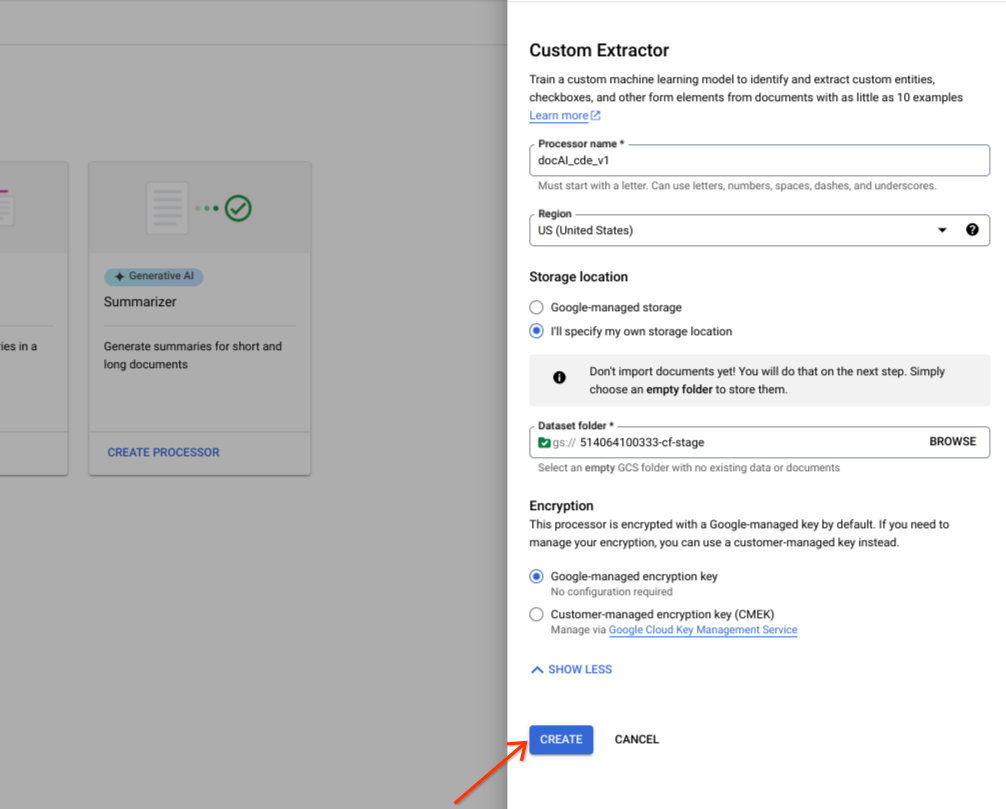
Opção de armazenamento personalizada
Ative ou desative as opções avançadas.
Selecione Especificar a minha própria localização de armazenamento.
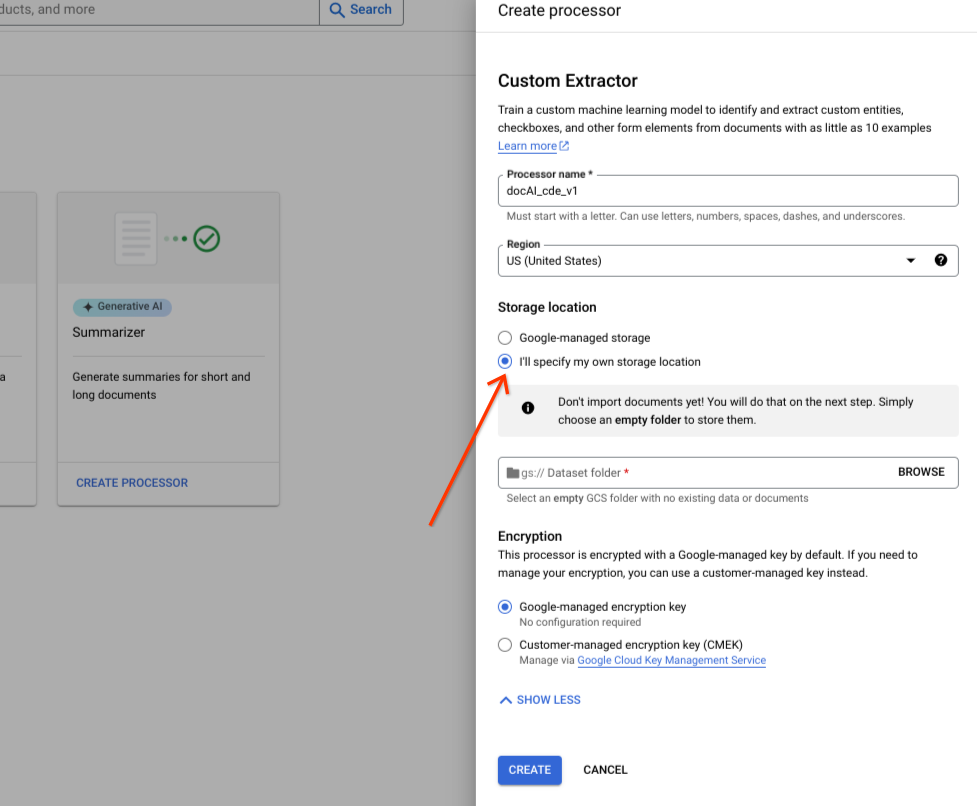
Escolha uma pasta do Cloud Storage no componente de entrada.
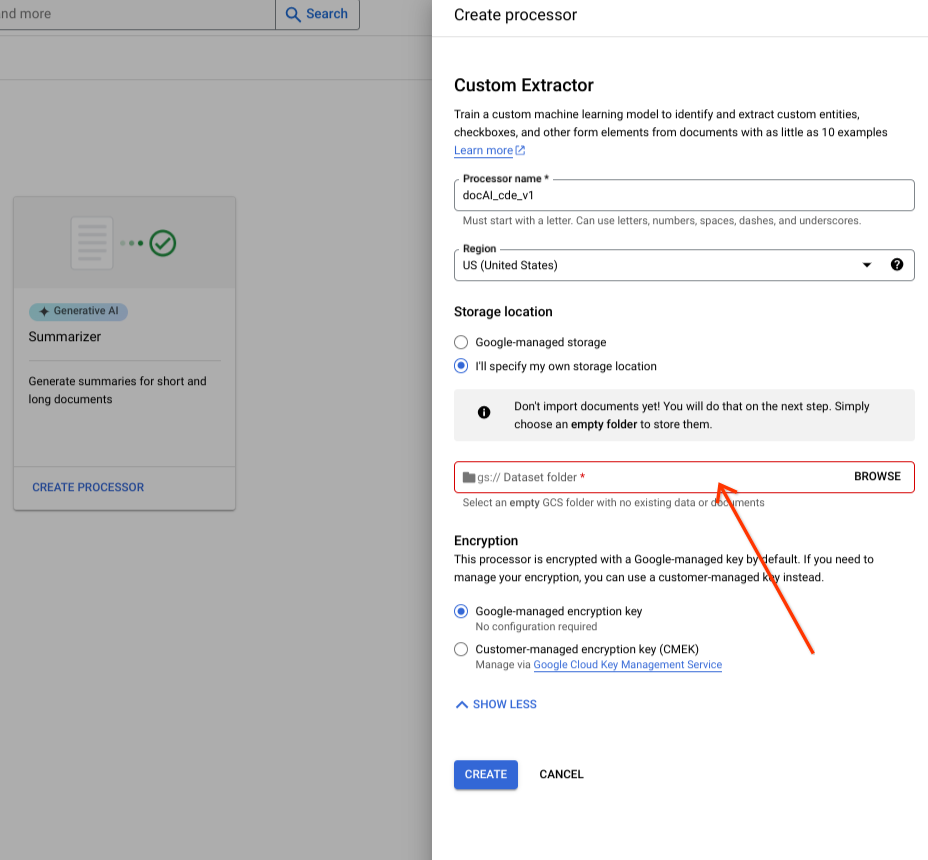
Selecione Criar.
Operações da API Dataset
Este exemplo mostra como usar o método
processors.updateDataset
para criar um conjunto de dados. Um recurso de conjunto de dados é um recurso único num processador, o que significa que não existe um RPC de recurso de criação. Em alternativa, pode usar o RPC updateDataset para definir as preferências. O Document AI oferece uma opção para armazenar os documentos do conjunto de dados num contentor do Cloud Storage que indicar ou para que sejam geridos automaticamente pela Google.
Antes de usar qualquer um dos dados do pedido, faça as seguintes substituições:
LOCATION: Your processor location
PROJECT_ID: Your Google Cloud project ID
PROCESSOR_ID The ID of your custom processor
GCS_URI: Your Cloud Storage URI where dataset documents are stored
Segmento fornecido
Siga os passos seguintes para criar um pedido de conjunto de dados com um contentor do Cloud Storage que indicar.
Método HTTP
PATCH https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/datasetJSON do pedido:
{
"name":"projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset"
"gcs_managed_config" {
"gcs_prefix" {
"gcs_uri_prefix": "GCS_URI"
}
}
"spanner_indexing_config" {}
}Gerido pela Google
Caso queira criar o conjunto de dados gerido pela Google, atualize as seguintes informações:
Método HTTP
PATCH https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/datasetJSON do pedido:
{
"name":"projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset"
"unmanaged_dataset_config": {}
"spanner_indexing_config": {}
}Para enviar o seu pedido, pode usar o Curl:
Guarde o corpo do pedido num ficheiro denominado request.json. Execute o seguinte comando:
CURL
curl -X PATCH \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset"Deve receber uma resposta JSON semelhante à seguinte:
{
"name": "projects/PROJECT_ID/locations/LOCATION/operations/OPERATION_ID"
}Importe documentos
Um conjunto de dados recém-criado está vazio. Para adicionar documentos, selecione Importar documentos e selecione uma ou mais pastas do Cloud Storage que contenham os documentos que quer adicionar ao seu conjunto de dados.
Se o Cloud Storage estiver num Google Cloud projeto diferente, certifique-se de que
concede acesso para que o Document AI possa ler ficheiros dessa
localização. Em concreto, tem de conceder a função de
Visualizador de objetos de armazenamento ao
agente do serviço principal da IA Documental
service-{project-id}@gcp-sa-prod-dai-core.iam.gserviceaccount.com. Para mais
informações, consulte
Agentes de serviços.
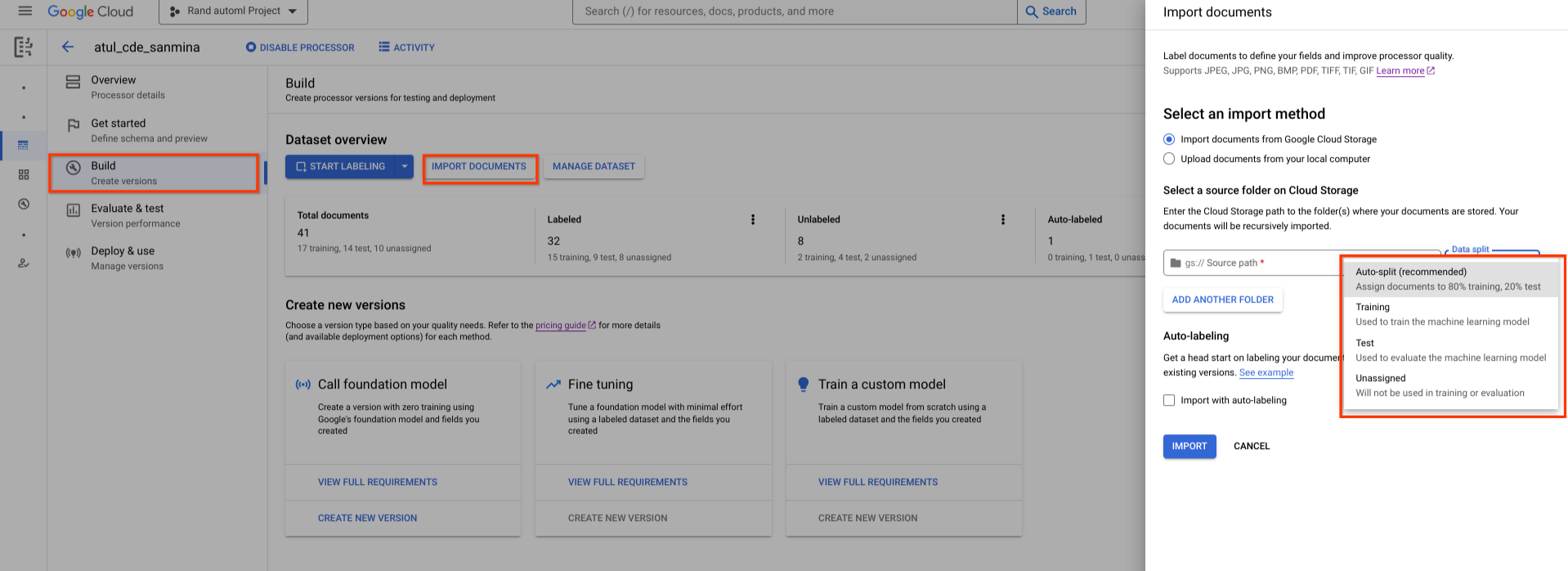
Em seguida, escolha uma das seguintes opções de atribuição:
- Preparação: atribua ao conjunto de preparação.
- Teste: atribuir ao conjunto de testes.
- Divisão automática: baralha aleatoriamente os documentos no conjunto de teste e de preparação.
- Não atribuído: não é usado na preparação nem na avaliação. Pode atribuir manualmente mais tarde.
Pode sempre modificar as atribuições mais tarde.
Quando seleciona Importar, o Document AI importa todos os
tipos de ficheiros suportados, bem como ficheiros JSON
Document, para o conjunto de dados. Para ficheiros JSON Document, o Document AI importa o documento e converte o respetivo entities
em instâncias de etiquetas.
A IA Documentos não modifica a pasta de importação nem lê a partir da pasta após a conclusão da importação.
Selecione Atividade na parte superior da página para abrir o painel Atividade, que apresenta os ficheiros que foram importados com êxito, bem como os que não foram importados.
Se já tiver uma versão existente do processador, pode selecionar a caixa de verificação Importar com etiquetagem automática na caixa de diálogo Importar documentos. Os documentos são etiquetados automaticamente com o processador anterior quando são importados. Não pode preparar nem atualizar a preparação em documentos etiquetados automaticamente nem usá-los no conjunto de testes sem os marcar como etiquetados. Depois de importar documentos etiquetados automaticamente, reveja e corrija manualmente os documentos etiquetados automaticamente. Em seguida, selecione Guardar para guardar as correções e marcar o documento como etiquetado. Em seguida, pode atribuir os documentos conforme adequado. Consulte o artigo Etiquetagem automática.
RPC Import documents
Este exemplo mostra como usar o método dataset.importDocuments para importar documentos para o conjunto de dados.
Antes de usar qualquer um dos dados do pedido, faça as seguintes substituições:
LOCATION: Your processor location
PROJECT_ID: Your Google Cloud project ID
PROCESSOR_ID: The ID of your custom processor
GCS_URI: Your Cloud Storage URI where dataset documents are stored
DATASET_TYPE: The dataset type to which you want to add documents. The value should be either `DATASET_SPLIT_TRAIN` or `DATASET_SPLIT_TEST`.
TRAINING_SPLIT_RATIO: The ratio of documents which you want to autoassign to the training set.
Conjunto de dados de teste ou de preparação
Se quiser adicionar documentos ao conjunto de dados de teste ou de preparação:
Método HTTP
POST https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/importDocumentsJSON do pedido:
{
"batch_documents_import_configs": {
"dataset_split": DATASET_TYPE
"batch_input_config": {
"gcs_prefix": {
"gcs_uri_prefix": GCS_URI
}
}
}
}Conjunto de dados de preparação e teste
Se quiser dividir automaticamente os documentos entre o conjunto de dados de preparação e de teste:
Método HTTP
POST https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/importDocumentsJSON do pedido:
{
"batch_documents_import_configs": {
"auto_split_config": {
"training_split_ratio": TRAINING_SPLIT_RATIO
},
"batch_input_config": {
"gcs_prefix": {
"gcs_uri_prefix": "gs://test_sbindal/pdfs-1-page/"
}
}
}
}Guarde o corpo do pedido num ficheiro denominado request.json e execute o seguinte comando:
CURL
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/importDocuments"Deve receber uma resposta JSON semelhante à seguinte:
{
"name": "projects/PROJECT_ID/locations/LOCATION/operations/OPERATION_ID"
}Delete documents RPC
Este exemplo mostra como usar o método dataset.batchDeleteDocuments para eliminar documentos do conjunto de dados.
Antes de usar qualquer um dos dados do pedido, faça as seguintes substituições:
LOCATION: Your processor location
PROJECT_ID: Your Google Cloud project ID
PROCESSOR_ID: The ID of your custom processor
DOCUMENT_ID: The document ID blob returned by <code>ImportDocuments</code> request
Elimine documentos
Método HTTP
POST https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/batchDeleteDocumentsJSON do pedido:
{
"dataset_documents": {
"individual_document_ids": {
"document_ids": DOCUMENT_ID
}
}
}Guarde o corpo do pedido num ficheiro denominado request.json e execute o seguinte comando:
CURL
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/batchDeleteDocuments"Deve receber uma resposta JSON semelhante à seguinte:
{
"name": "projects/PROJECT_ID/locations/LOCATION/operations/OPERATION_ID"
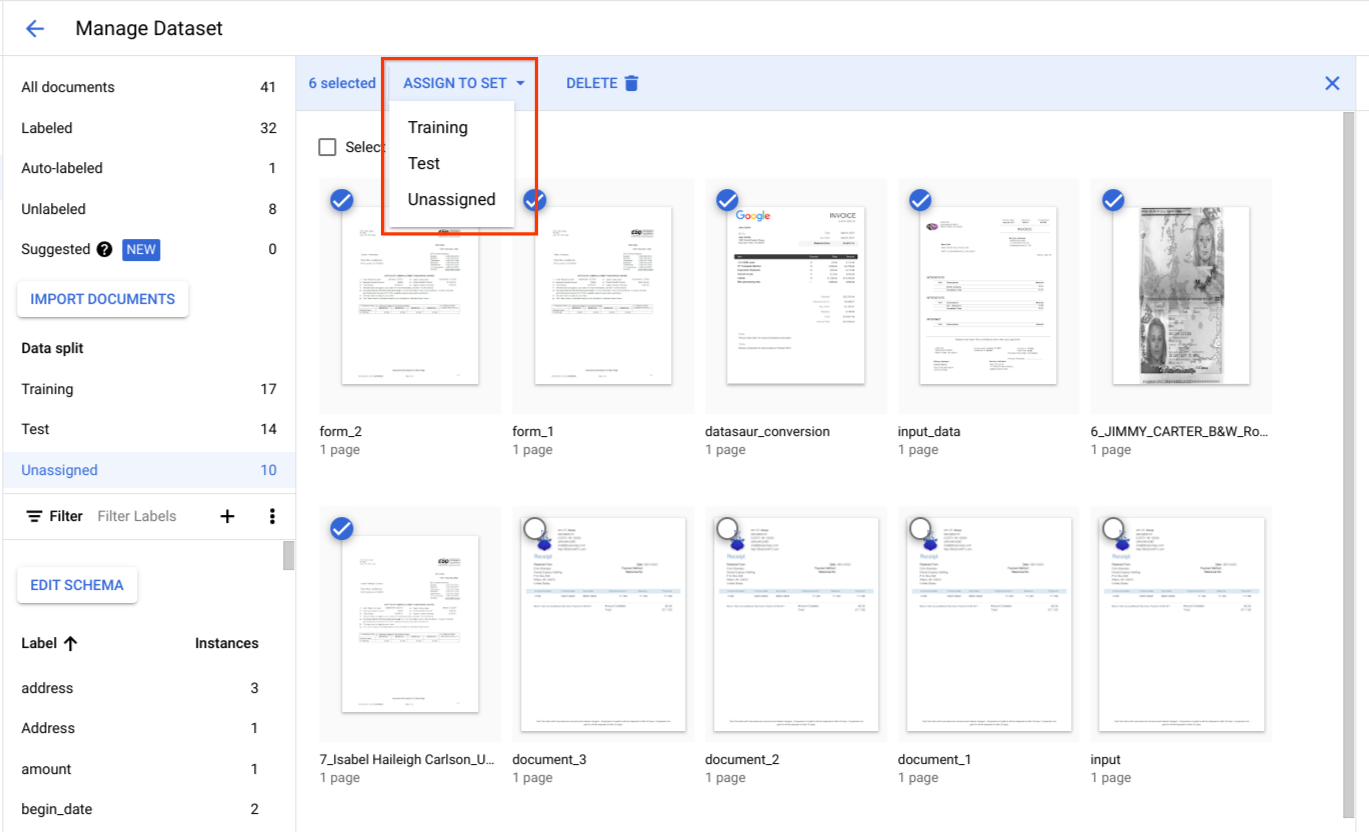
}Atribua documentos ao conjunto de dados de teste ou de preparação
Em Divisão de dados, selecione documentos e atribua-os ao conjunto de dados de treino, ao conjunto de dados de teste ou a nenhum dos dois.
Práticas recomendadas para o conjunto de testes
A qualidade do conjunto de testes determina a qualidade da avaliação.
O conjunto de testes deve ser criado no início do ciclo de desenvolvimento do processador e bloqueado para que possa acompanhar a qualidade do processador ao longo do tempo.
Recomendamos, pelo menos, 100 documentos por tipo de documento para o conjunto de testes. É fundamental garantir que o conjunto de testes é representativo dos tipos de documentos que os clientes estão a usar para o modelo que está a ser desenvolvido.
O conjunto de testes deve ser representativo do tráfego de produção em termos de frequência. Por exemplo, se estiver a processar formulários W2 e esperar que 70% sejam relativos ao ano de 2020 e 30% ao ano de 2019, ~70% do conjunto de testes deve ser composto por documentos W2 de 2020. Esta composição do conjunto de testes garante que é dada a importância adequada a cada subtipo de documento ao avaliar o desempenho do processador. Além disso, se estiver a extrair os nomes das pessoas de formulários internacionais, certifique-se de que o conjunto de testes inclui formulários de todos os países segmentados.
Práticas recomendadas para o conjunto de dados de treino
Todos os documentos que já foram incluídos no conjunto de testes não devem ser incluídos no conjunto de dados de treino.
Ao contrário do conjunto de testes, o conjunto de preparação final não tem de ser tão estritamente representativo da utilização do cliente em termos de diversidade ou frequência de documentos. Algumas etiquetas são mais difíceis de preparar do que outras. Assim, pode melhorar o desempenho ao inclinar o conjunto de dados de preparação para essas etiquetas.
No início, não existe uma boa forma de determinar que etiquetas são difíceis. Deve começar com um conjunto de preparação inicial pequeno e selecionado aleatoriamente usando a mesma abordagem descrita para o conjunto de teste. Este conjunto de dados de preparação inicial deve conter aproximadamente 10% do número total de documentos que planeia anotar. Em seguida, pode avaliar iterativamente a qualidade do processador (procurando padrões de erros específicos) e adicionar mais dados de preparação.
Defina o esquema do processador
Depois de criar um conjunto de dados, pode definir um esquema do processador antes ou depois de importar documentos.
O processador schema define as etiquetas, como o nome e a morada, a extrair dos seus documentos.
Selecione Editar esquema e, em seguida, crie, edite, ative e desative etiquetas conforme necessário.
Certifique-se de que seleciona Guardar quando terminar.
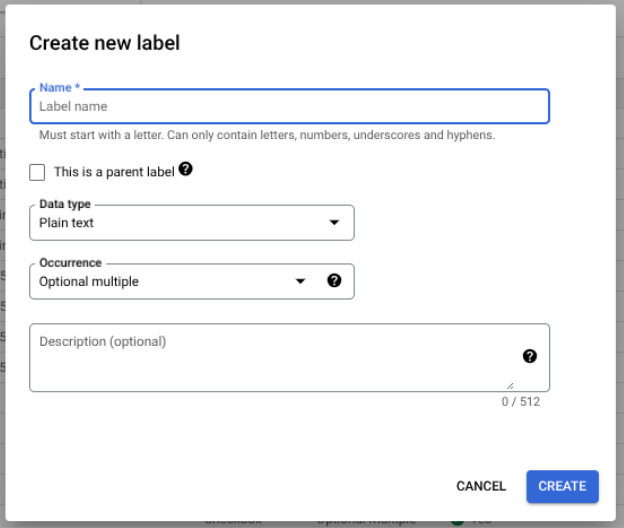
Notas sobre a gestão de etiquetas de esquemas:
Depois de criar uma etiqueta de esquema, não é possível editar o nome da etiqueta de esquema.
Uma etiqueta de esquema só pode ser editada ou eliminada quando não existirem versões do processador preparadas. Só é possível editar o tipo de dados e o tipo de ocorrência.
A desativação de uma etiqueta também não afeta a previsão. Quando envia um pedido de processamento, a versão do processador extrai todas as etiquetas que estavam ativas no momento da preparação.
Obtenha o esquema de dados
Este exemplo mostra como usar o conjunto de dados.
getDatasetSchema
para obter o esquema atual. DatasetSchema é um recurso singleton, que é criado automaticamente quando cria um recurso dataset.
Antes de usar qualquer um dos dados do pedido, faça as seguintes substituições:
LOCATION: Your processor location
PROJECT_ID: Your Google Cloud project ID
PROCESSOR_ID: The ID of your custom processor
Obtenha o esquema de dados
Método HTTP
GET https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/datasetSchemaCURL
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/datasetSchema"Deve receber uma resposta JSON semelhante à seguinte:
{
"name": "projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/datasetSchema",
"documentSchema": {
"entityTypes": [
{
"name": $SCHEMA_NAME,
"baseTypes": [
"document"
],
"properties": [
{
"name": $LABEL_NAME,
"valueType": $VALUE_TYPE,
"occurrenceType": $OCCURRENCE_TYPE,
"propertyMetadata": {}
},
],
"entityTypeMetadata": {}
}
]
}
}Atualize o esquema do documento
Este exemplo mostra como usar o comando
dataset.updateDatasetSchema
para atualizar o esquema atual. Este exemplo mostra um comando para atualizar o esquema do conjunto de dados de modo a ter uma etiqueta. Se quiser adicionar uma nova etiqueta, e não eliminar nem atualizar etiquetas existentes, pode chamar getDatasetSchema primeiro e fazer as alterações adequadas na respetiva resposta.
Antes de usar qualquer um dos dados do pedido, faça as seguintes substituições:
LOCATION: Your processor location
PROJECT_ID: Your Google Cloud project ID
PROCESSOR_ID: The ID of your custom processor
LABEL_NAME: The label name which you want to add
LABEL_DESCRIPTION: Describe what the label represents
DATA_TYPE: The type of the label. You can specify this as string, number, currency, money, datetime, address, boolean.
OCCURRENCE_TYPE: Describes the number of times this label is expected. Pick an enum value.
Atualize o esquema
Método HTTP
PATCH https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/datasetSchemaJSON do pedido:
{
"document_schema": {
"entityTypes": [
{
"name": $SCHEMA_NAME,
"baseTypes": [
"document"
],
"properties": [
{
"name": LABEL_NAME,
"description": LABEL_DESCRIPTION,
"valueType": DATA_TYPE,
"occurrenceType": OCCURRENCE_TYPE,
"propertyMetadata": {}
},
],
"entityTypeMetadata": {}
}
]
}
}Guarde o corpo do pedido num ficheiro denominado request.json e execute o seguinte comando:
CURL
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/datasetSchema"Escolha atributos de etiquetas
Tipo de dados
Plain text: um valor de string.Number: um número, inteiro ou de vírgula flutuante.Money: um valor monetário. Quando etiquetar, não inclua o símbolo da moeda.- Quando a entidade é extraída, é normalizada para
google.type.Money.
- Quando a entidade é extraída, é normalizada para
Currency: um símbolo monetário.Datetime: um valor de data ou hora.- Quando a entidade é extraída, é normalizada para o formato de texto
ISO 8601.
- Quando a entidade é extraída, é normalizada para o formato de texto
Address: um endereço de localização.- Quando a entidade é extraída, é normalizada e enriquecida com o EKG.
Checkbox: um valor booleanotrueoufalse.Signature: um valor booleanotrueoufalseemnormalized_value.signature_valueque indica se está presente uma assinatura. É compatível com os métodosderive.mention_text: um valor booleanoDetectedou vazio""emhas_signedque indica se está presente uma assinatura. É compatível com os métodosderive.normalized_value.text: um valor booleanoDetectedou vazio""emhas_signedque indica se está presente uma assinatura. É compatível com os métodosderive.normalized_value.boolean_valuenão está preenchido.
Método
- Quando a entidade é
extracted, tem os campostextAnchor,type,mentionTextepageAnchorpreenchidos. - Quando a entidade é
derived, os valores derivados podem não estar presentes no texto do documento. Não tem os campostextAnchorepageAnchor.pageRefs[].bounding_polypreenchidos.
Ocorrência
Escolha REQUIRED se uma entidade for sempre apresentada em documentos de um determinado tipo. Escolha OPTIONAL se não tiver essa expetativa.
Escolha ONCE se uma entidade tiver de ter um valor, mesmo que o mesmo valor apareça várias vezes no mesmo documento. Escolha MULTIPLE se uma entidade tiver vários valores.
Etiquetas principais e secundárias
As etiquetas principais/secundárias (também conhecidas como entidades tabulares) são usadas para etiquetar dados numa tabela. A tabela seguinte contém 3 linhas e 4 colunas.

Pode definir essas tabelas através de etiquetas principais/secundárias. Neste exemplo, a etiqueta principal line-item define uma linha da tabela.
Crie uma etiqueta principal
Na página Editar esquema, selecione Criar etiqueta.
Selecione a caixa de verificação Esta é uma etiqueta principal e introduza as outras informações. A etiqueta principal tem de ter uma ocorrência de
optional_multipleourequire_multiplepara que possa ser repetida para capturar todas as linhas na tabela.Selecione Guardar.
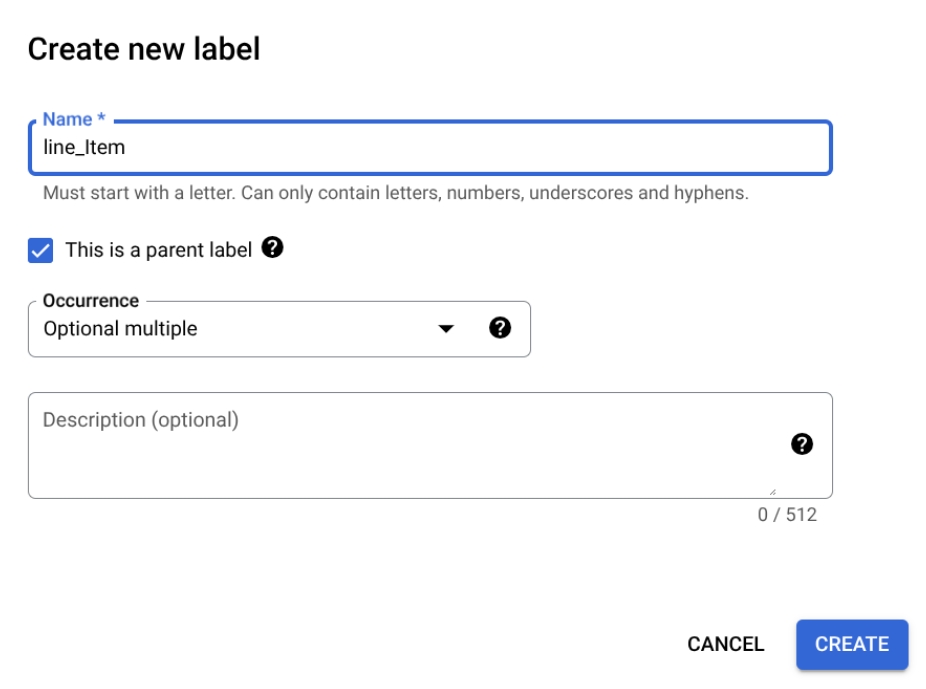
A etiqueta principal é apresentada na página Editar esquema, com uma opção Adicionar etiqueta secundária junto à mesma.
Para criar uma etiqueta secundária
Junto à etiqueta principal na página Editar esquema, selecione Adicionar etiqueta secundária.
Introduza as informações da etiqueta secundária.
Selecione Guardar.
Repita o procedimento para cada etiqueta secundária que quer adicionar.
As etiquetas secundárias aparecem com recuo abaixo da etiqueta principal na página Editar esquema.

As etiquetas pai-filho são uma funcionalidade de pré-visualização e só são suportadas para tabelas. A profundidade de aninhamento está limitada a 1, o que significa que as entidades secundárias não podem conter outras entidades secundárias.
Crie etiquetas de esquema a partir de documentos etiquetados
Crie automaticamente etiquetas de esquemas importando ficheiros JSON pré-etiquetados Document.
Enquanto a importação de Document estiver em curso, as etiquetas de esquema adicionadas recentemente são adicionadas ao editor de esquemas. Selecione "Editar esquema" para validar ou alterar o tipo de dados e o tipo de ocorrência das novas etiquetas do esquema. Após a confirmação, selecione as etiquetas de esquema e selecione Ativar.
Conjuntos de dados de amostragem
Estes podem ser usados para a atualização ou extratores personalizados, consoante o tipo de documento.
gs://cloud-samples-data/documentai/Custom/
gs://cloud-samples-data/documentai/Custom/1040/
gs://cloud-samples-data/documentai/Custom/Invoices/
gs://cloud-samples-data/documentai/Custom/Patents/
gs://cloud-samples-data/documentai/Custom/Procurement-Splitter/
gs://cloud-samples-data/documentai/Custom/W2-redacted/
gs://cloud-samples-data/documentai/Custom/W2/
gs://cloud-samples-data/documentai/Custom/W9/