
このドキュメントでは、Document AI の使用方法に関する基本的なコンセプトについて説明します。 他のドキュメントやクイックスタートに進む前に、このページをお読みください。
ドキュメント処理ワークフローを自動化する
世界中の企業が、情報を保存して伝達するためにドキュメントに大きく依存しています。この情報を活用するには、デジタル化が必要になることがよくあります。ただし、通常は時間のかかる手動プロセスで行われます。
次に例を示します。
- 電子書籍リーダー用の書籍のデジタル化。
- 医療機関での問診票の処理。
- 経費精算書の検証のための領収書と請求書の解析。
- 身分証明書に基づく本人確認。
- ローンの承認のための税務書類からの収入情報の抽出。
- 主要なビジネス契約条件の契約内容の把握。
これらのワークフローでは、ドキュメントから生のテキストを取得し、必要なデータ(フィールドまたはエンティティ)に対応する特定のテキストを抽出します。 ただし、ドキュメントの種類ごとに構造とレイアウトが異なり、フィールドのパターンは特定のユースケースによって異なります。
Document AI のコンポーネント
Document AI は、ドキュメント処理と理解 ドキュメントから非構造化データを取り出して 構造化データ(データベースに適した特定のフィールド)に変換し、ドキュメントを簡単に理解、分析、利用できるようにするプラットフォームです。
Document AI は、Vertex AI 内のプロダクトの上に構築されており、生成 AI を使用して、ML の専門知識がなくても、スケーラブルなエンドツーエンドのクラウドベースのドキュメント処理アプリケーションを作成できます。
Document AI を使用すると、次のことができます。
- OCR を使用してドキュメントをデジタル化 し、テキスト、レイアウト、さまざまなアドオン(画質検出(読みやすさ用)、傾き補正(完全自動))を取得します。
- ドキュメント ファイルからテキストとレイアウト情報を抽出 し、エンティティを正規化します。
- 構造化フォームと通常の表でKey-Value ペア(kvp)を識別 します。たとえば、
Name: Jill Smithは kvp です。 - ドキュメント タイプを分類 して、抽出や保存などのダウンストリーム プロセスを推進します。
- ドキュメントをタイプごとに分割 して分類します。たとえば、複数の実際のドキュメントを含む PDF ファイルなどです。
- ドキュメントと予測のレビューなどの自動ラベリング、スキーマ管理、データセット管理機能を使用して、ファインチューニングとモデル評価で使用するデータセットを準備 します。
- Cloud Storage、BigQuery、Agent Search などのプロダクトと統合 して、ドキュメントとメタデータの保存、検索、整理、管理、分析を行います。
この図は、Document AI でサポートされている主要なドキュメント処理ステップと、それらの接続方法を示しています。
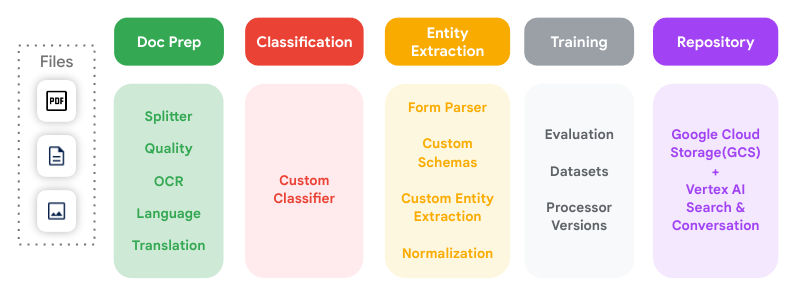
プロセッサ
Document AI プロセッサは、ドキュメント ファイルと、ドキュメント処理と理解のアクションを実行する ML モデルの間にあります。 プロセッサはドキュメントの分類、分割、解析、分析に使用されます。
プロジェクトごとに、独自のプロセッサ インスタンスを作成する必要があります。 Google Cloud
プロセッサは次のいずれかのカテゴリに分類されます。
- デジタル化: OCR。
- 抽出: カスタム エクストラクタ、Form パーサー、レイアウト パーサー、事前トレーニング済みパーサー。
- 分類: カスタム分類器とカスタム スプリッター。
Document AI で利用できる全 プロセッサ タイプについては、すべてのプロセッサと詳細の一覧をご確認ください。
どのプロセッサを使用するべきか?
特定のアプリケーションで使用するプロセッサ タイプを決定するための一般的なガイドラインは次のとおりです。
| カテゴリ | ユースケース | プロセッサ タイプ |
|---|---|---|
| デジタル化 | ドキュメントからテキストとレイアウト情報を抽出します。 | Enterprise Document OCR |
| ドキュメントのスキャン画像の品質(読みやすさ)を分析します。 | 画像品質分析 が有効になっている Enterprise Document OCR | |
| カスタム プロセッサの条件を満たさないカスタム ドキュメントからエンティティを抽出します。 | ||
| 抽出 | ドキュメント内の構造化フォームから表または kvp を抽出します。 | Form パーサー |
| ドキュメント内のテキスト、表、リストなどの要素を抽出し、コンテキストを認識したチャンクを返します。 | レイアウト パーサー | |
| カスタム プロセッサの条件を満たすカスタム ドキュメントからエンティティを抽出します。 | カスタム エクストラクタを作成する | |
| 特殊なドキュメント タイプからエンティティを抽出します。 | 事前トレーニング済みプロセッサ(品質を向上させるためにアップトレーニング)。 | |
| 分類 | ドキュメントを分類します。 | カスタム分類器を作成する |
| ドキュメントを分割します。 | カスタム スプリッターを作成する |
この図は、各ユースケースに最適なプロセッサを判断するのに役立ちます。
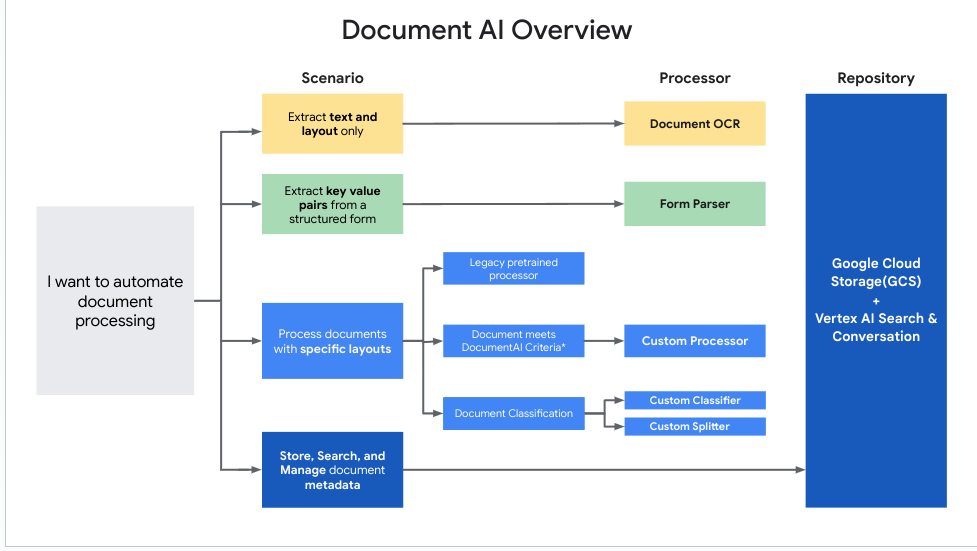
Document AI プロセッサを使用する
Document AI を使用してドキュメントの処理を開始する主な手順は次のとおりです。
ユースケースに適したプロセッサを選択 します。
- 各プロセッサの詳細については、すべてのプロセッサと詳細の一覧をご覧ください。
プロセッサを作成するには、 Google Cloud コンソールまたは Document AI API を使用します。
Document AI は、ドキュメントを送信できる予測エンドポイント を作成します。
詳細な手順については、プロセッサを作成するをご覧ください。
トレーニング データとテストデータを使用してプロセッサをトレーニング するか、既存のプロセッサの上に新しい(事前トレーニング済み)プロセッサ バージョンをアップトレーニングします。
- 詳細な手順については、プロセッサをトレーニングするをご覧ください。
処理するドキュメントを送信 します。
Document AI はドキュメントを処理し、抽出された構造化情報を含む 1 つ以上の
Documentオブジェクトを返します。詳細な手順については、処理リクエストを送信すると処理レスポンスを処理するをご覧ください。