
A resposta a um pedido de processamento contém um Document
objeto que contém tudo o que se sabe sobre o documento processado, incluindo todas as
informações estruturadas que a IA Documental conseguiu extrair.
Esta página explica o esquema do objeto Document através de documentos de exemplo e, em seguida, mapeia os aspetos dos resultados de OCR para os elementos específicos do JSON do objeto Document.
Também fornece bibliotecas cliente, exemplos de código e exemplos de código do SDK Document AI Toolbox.
Estes exemplos de código usam o processamento online, mas a análise de objetos Document funciona da mesma forma para o processamento em lote.
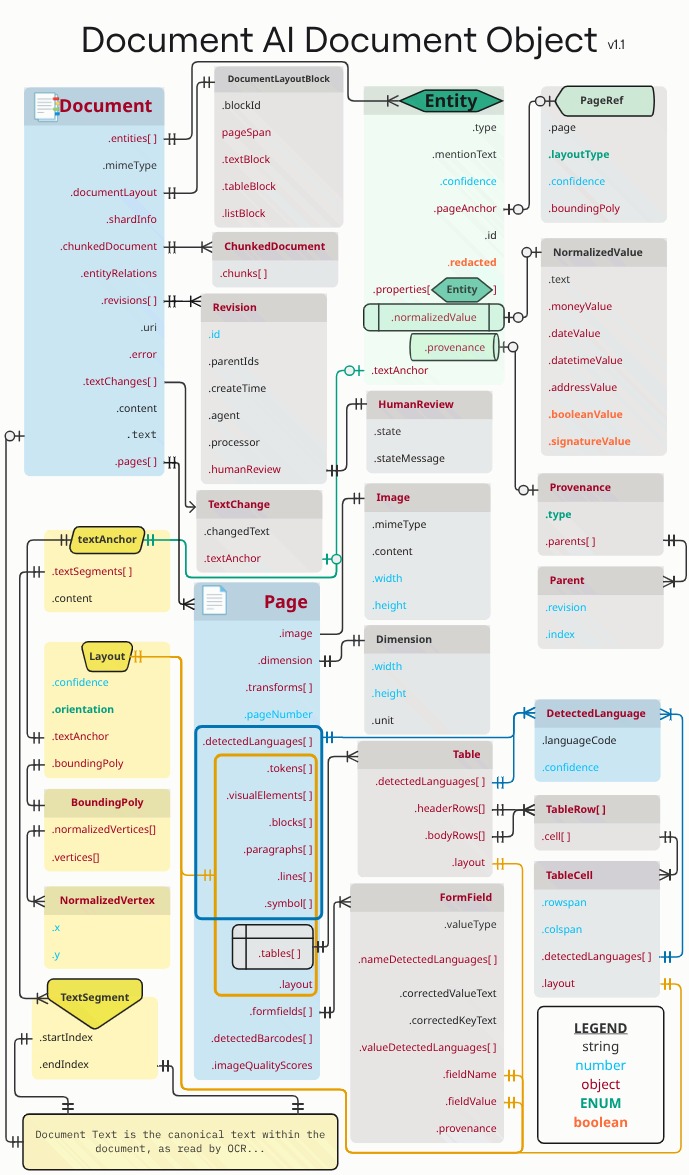
Os retângulos e as setas laranja e azuis representam que, respetivamente, pelo menos um campo dos objetos ligados é .layout ou detectedLanguage. O diagrama usa a notação de pé de galinha.
Use um visualizador JSON ou um utilitário de edição especificamente concebido para expandir ou reduzir elementos. A revisão de JSON não processado numa utilidade de texto simples é ineficiente.
Texto, esquema e índices de qualidade
Segue-se um exemplo de um documento de texto:

Segue-se o objeto de documento completo devolvido pelo processador Enterprise Document OCR:
Este resultado do OCR também está sempre incluído no resultado do processador do Document AI, uma vez que o OCR é executado pelos processadores. Usa os dados de OCR existentes, pelo que pode introduzir esses dados JSON através da opção de documento inline nos processadores do Document AI.
image=None, # all our samples pass this var
mime_type="application/json",
inline_document=document_response # pass OCR output to CDE input - undocumented
Seguem-se alguns dos campos importantes:
Texto não processado
O campo text contém o texto reconhecido pela IA Documental.
Este texto não contém nenhuma estrutura de esquema além de espaços, tabulações e
mudanças de linha. Este é o único campo que armazena informações textuais de um documento e serve como fonte de informações fidedignas do texto do documento. Outros campos podem referir-se a partes do campo de texto por posição (startIndex e endIndex).
{
text: "Sample Document\nHeading 1\nLorem ipsum dolor sit amet, ..."
}
Tamanho de página e idiomas
Cada page no objeto document corresponde a uma página física do documento de exemplo. O resultado JSON de exemplo contém uma página porque é uma única imagem PNG.
{
"pages:" [
{
"pageNumber": 1,
"dimension": {
"width": 679.0,
"height": 460.0,
"unit": "pixels"
},
}
]
}
- O campo
pages[].detectedLanguages[]contém os idiomas encontrados numa determinada página, juntamente com a pontuação de confiança.
{
"pages": [
{
"detectedLanguages": [
{
"confidence": 0.98009938,
"languageCode": "en"
},
{
"confidence": 0.01990064,
"languageCode": "und"
}
]
}
]
}
Dados de OCR
O OCR da Document AI deteta texto com vários níveis de detalhe ou organização na página, como blocos de texto, parágrafos, tokens e símbolos (o nível de símbolo é opcional, se estiver configurado para gerar dados ao nível do símbolo). Estes são todos os membros do objeto de página.
Cada elemento tem um layout correspondente que descreve a respetiva posição e texto. Os elementos visuais que não são texto (como caixas de verificação) também estão ao nível da página.
{
"pages": [
{
"paragraphs": [
{
"layout": {
"textAnchor": {
"textSegments": [
{
"endIndex": "16"
}
]
},
"confidence": 0.9939527,
"boundingPoly": {
"vertices": [ ... ],
"normalizedVertices": [ ... ]
},
"orientation": "PAGE_UP"
}
}
]
}
]
}
O texto não processado é referido no objeto textAnchor
que é indexado na string de texto principal com startIndex e endIndex.
Para
boundingPoly, o canto superior esquerdo da página é a origem(0,0). Os valores X positivos estão à direita e os valores Y positivos estão para baixo.O objeto
verticesusa as mesmas coordenadas que a imagem original, enquanto quenormalizedVerticesestão no intervalo[0,1]. Existe uma matriz de transformação que indica as medidas de correção da distorção e outros atributos da normalização da imagem.
- Para desenhar o
boundingPoly, desenhe segmentos de linha de um vértice para o seguinte. Em seguida, feche o polígono desenhando um segmento de linha do último vértice de volta ao primeiro. O elemento orientation do esquema indica se o texto foi rodado relativamente à página.
Para ajudar a visualizar a estrutura do documento, as seguintes imagens desenham polígonos delimitadores para page.paragraphs, page.lines e page.tokens.
Parágrafos

Linhas

Tokens

Blocos

O processador Enterprise Document OCR pode realizar uma avaliação de qualidade de um documento com base na respetiva legibilidade.
- Tem de definir o campo
processOptions.ocrConfig.enableImageQualityScorescomotruepara receber estes dados na resposta da API.
Esta avaliação de qualidade é um índice de qualidade em [0, 1], em que 1 significa qualidade perfeita.
O índice de qualidade é devolvido no campo Page.imageQualityScores.
Todos os defeitos detetados são apresentados como quality/defect_* e ordenados por ordem descendente
pelo valor de confiança.
Segue-se um PDF demasiado escuro e desfocado para ser lido confortavelmente:
Seguem-se as informações de qualidade do documento devolvidas pelo processador Enterprise Document OCR:
{
"pages": [
{
"imageQualityScores": {
"qualityScore": 0.7811847,
"detectedDefects": [
{
"type": "quality/defect_document_cutoff",
"confidence": 1.0
},
{
"type": "quality/defect_glare",
"confidence": 0.97849524
},
{
"type": "quality/defect_text_cutoff",
"confidence": 0.5
}
]
}
}
]
}
Exemplos de código
Os seguintes exemplos de código demonstram como enviar um pedido de processamento e, em seguida, ler e imprimir os campos no terminal:
Java
Para mais informações, consulte a documentação de referência da API Java Document AI.
Para se autenticar no Document AI, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para um ambiente de desenvolvimento local.
Node.js
Para mais informações, consulte a documentação de referência da API Node.js Document AI.
Para se autenticar no Document AI, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para um ambiente de desenvolvimento local.
Python
Para mais informações, consulte a documentação de referência da API Python Document AI.
Para se autenticar no Document AI, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para um ambiente de desenvolvimento local.
Formulários e tabelas
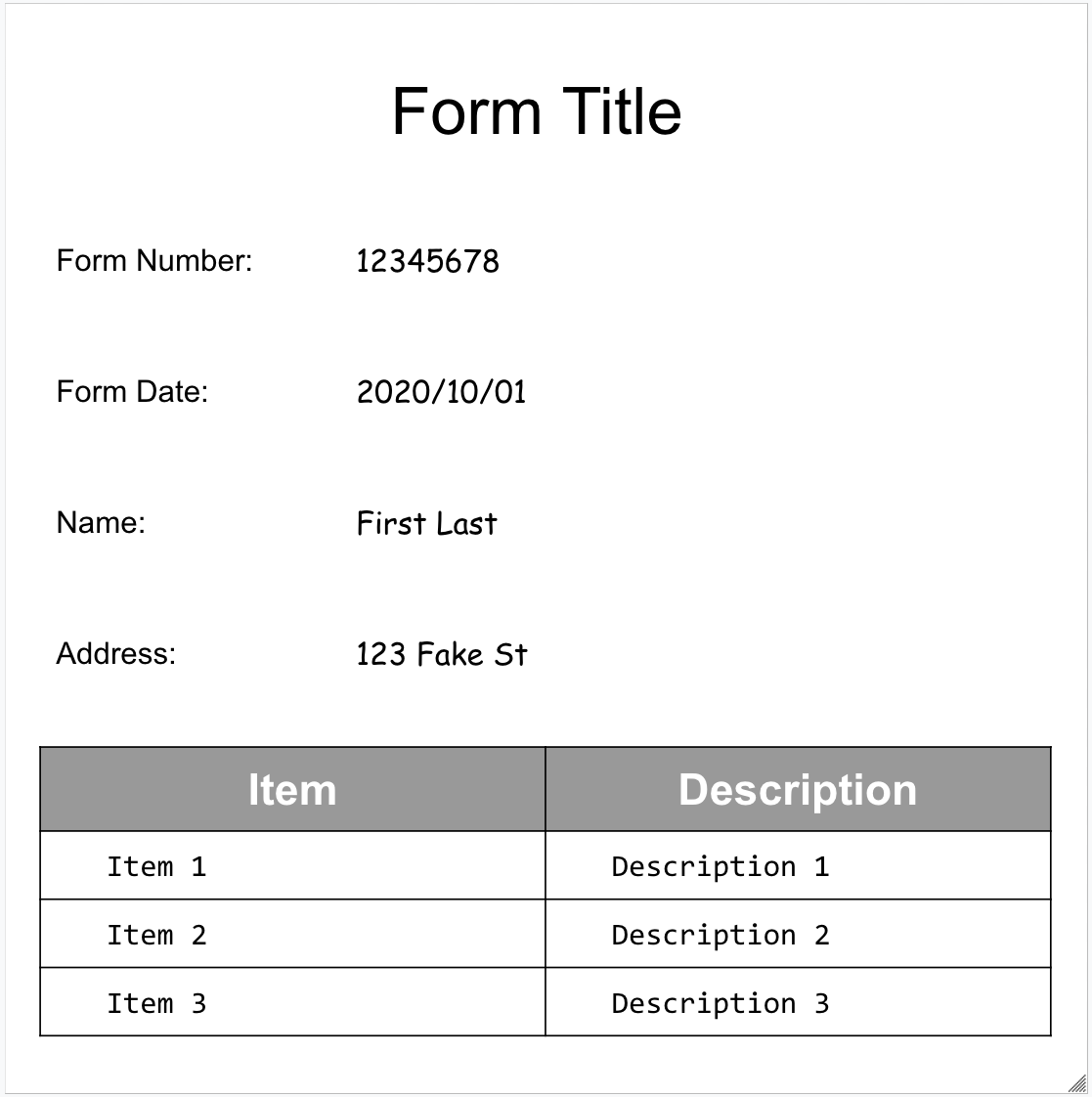
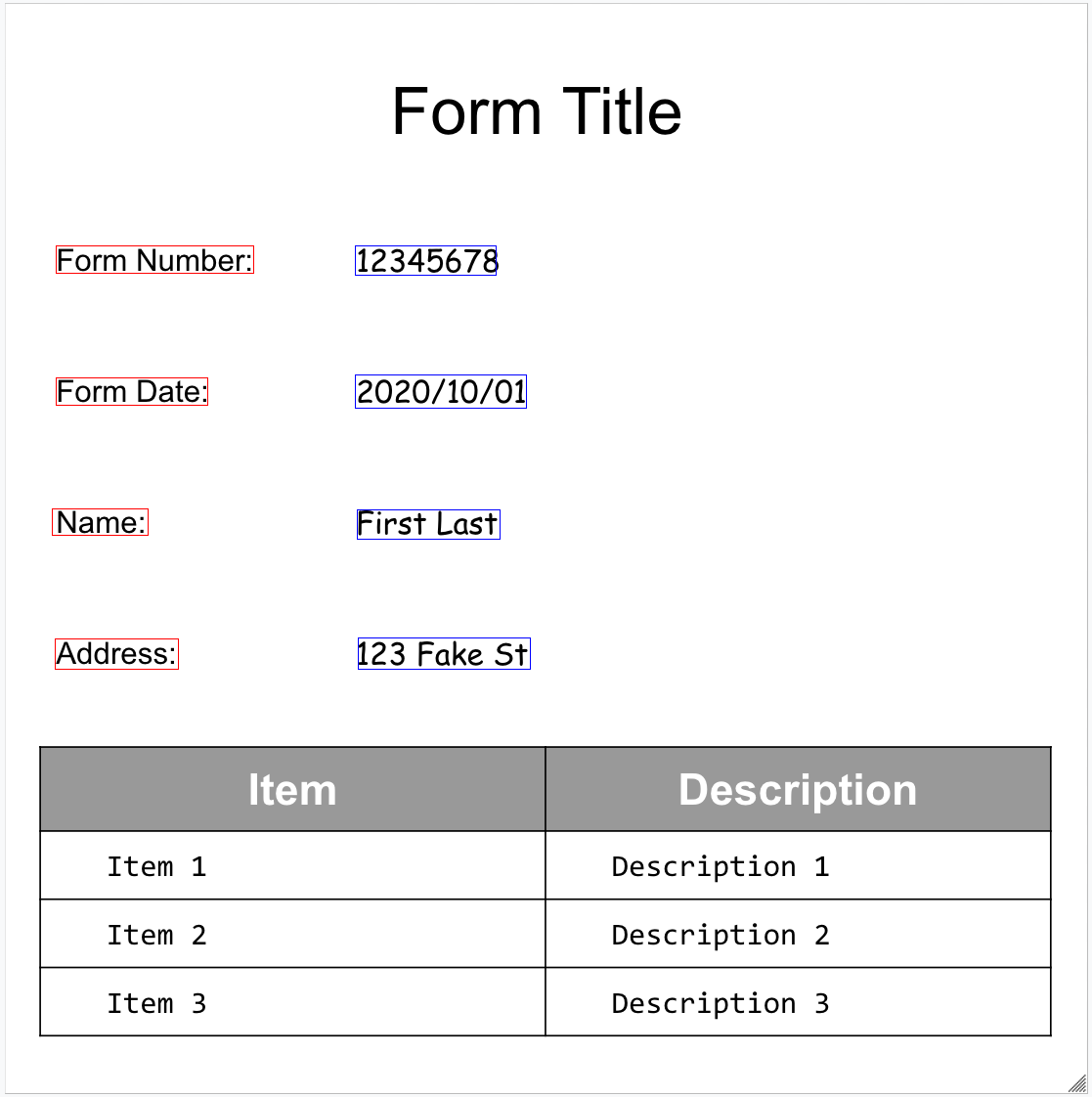
Segue-se o nosso formulário de exemplo:
Segue-se o objeto de documento completo devolvido pelo Form Parser:
Seguem-se alguns dos campos importantes:
O analisador de formulários consegue detetar FormFields
na página. Cada campo de formulário tem um nome e um valor. Estes também são denominados
pares de chave-valor (KVP). Tenha em atenção que os KVPs são diferentes das entidades (esquema) noutros extratores:
Os nomes das entidades estão configurados. As chaves nos PCVs são literalmente o texto da chave no documento.
{
"pages:" [
{
"formFields": [
{
"fieldName": { ... },
"fieldValue": { ... }
}
]
}
]
}
- A IA Documentos também pode detetar
Tablesna página.
{
"pages:" [
{
"tables": [
{
"layout": { ... },
"headerRows": [
{
"cells": [
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
},
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
}
]
}
],
"bodyRows": [
{
"cells": [
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
},
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
}
]
}
]
}
]
}
]
}
A extração de tabelas no analisador de formulários só reconhece tabelas convencionais, ou seja, sem células que abranjam linhas ou colunas. Assim, rowSpan e colSpan estão sempre 1.
A partir da versão do processador
pretrained-form-parser-v2.0-2022-11-10, o analisador de formulários também pode reconhecer entidades genéricas. Para mais informações, consulte o artigo Form Parser.Para ajudar a visualizar a estrutura do documento, as imagens seguintes desenham polígonos delimitadores para
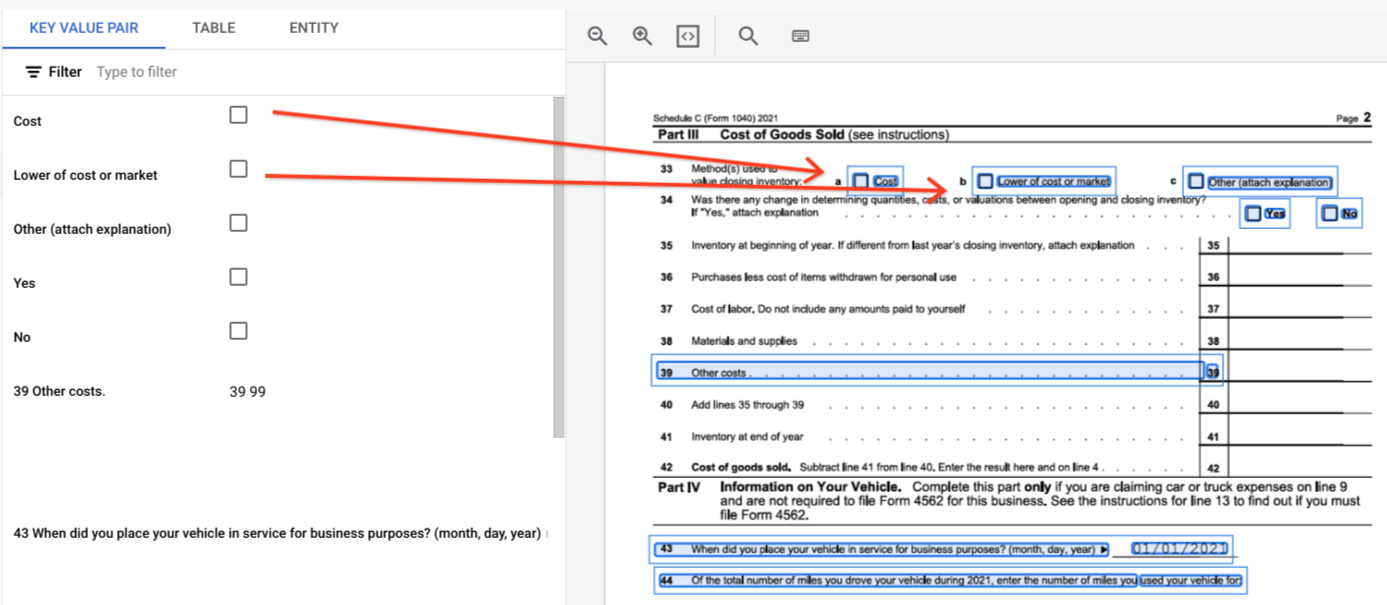
page.formFieldsepage.tables.Caixas de verificação em tabelas. O analisador de formulários consegue digitalizar caixas de verificação de imagens e PDFs como KVPs. Fornecer um exemplo de digitalização de caixas de verificação como um par de chave-valor.
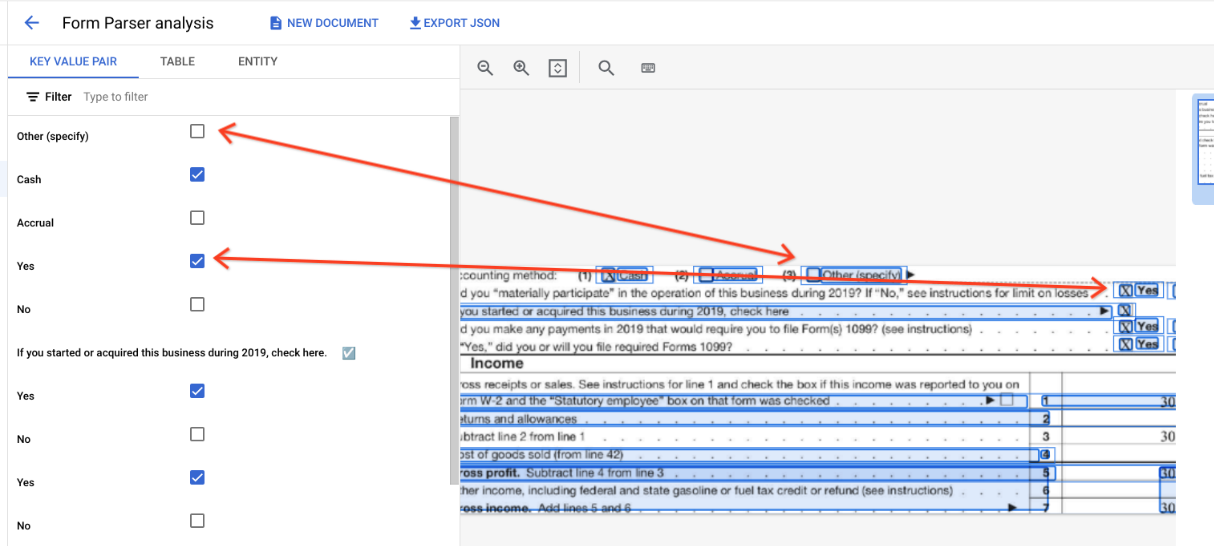
Fora das tabelas, as caixas de verificação são representadas como elementos visuais no analisador de formulários. Realçar as caixas quadradas com marcas de verificação na IU e o unicode ✓ no JSON.
"pages:" [
{
"tables": [
{
"layout": { ... },
"headerRows": [
{
"cells": [
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
},
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
}
]
}
],
"bodyRows": [
{
"cells": [
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
},
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
}
]
}
]
}
]
}
]
}
Nas tabelas, as caixas de verificação aparecem como carateres Unicode, como ✓ (selecionado) ou ☐ (desmarcado).
As caixas de verificação preenchidas têm o valor filled_checkbox:
under pages > x > formFields > x > fieldValue > valueType.. As caixas de verificação
desmarcadas têm o valor unfilled_checkbox.
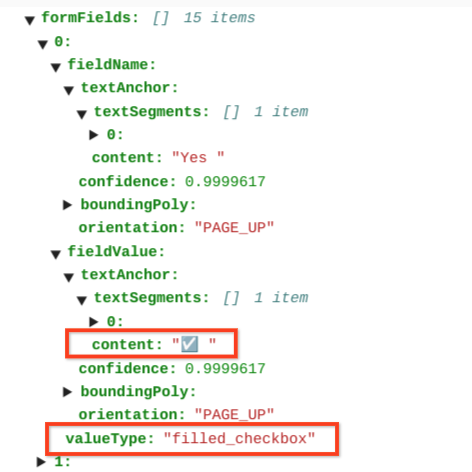
Os campos de conteúdo mostram o valor de conteúdo da caixa de verificação realçado com ✓ no caminho pages>formFields>x>fieldValue>textAnchor>content.
Para ajudar a visualizar a estrutura do documento, as imagens seguintes desenham polígonos delimitadores para page.formFields e page.tables.
Campos do formulário
Tabelas
Exemplos de código
Os seguintes exemplos de código demonstram como enviar um pedido de processamento e, em seguida, ler e imprimir os campos no terminal:
Java
Para mais informações, consulte a documentação de referência da API Java Document AI.
Para se autenticar no Document AI, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para um ambiente de desenvolvimento local.
Node.js
Para mais informações, consulte a documentação de referência da API Node.js Document AI.
Para se autenticar no Document AI, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para um ambiente de desenvolvimento local.
Python
Para mais informações, consulte a documentação de referência da API Python Document AI.
Para se autenticar no Document AI, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para um ambiente de desenvolvimento local.
Entidades, entidades aninhadas e valores normalizados
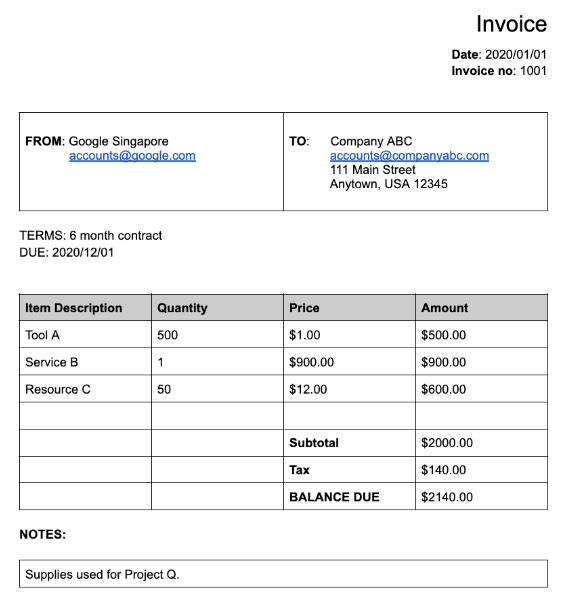
Muitos dos processadores especializados extraem dados estruturados baseados num esquema bem definido. Por exemplo, o analisador de faturas
deteta campos específicos, como invoice_date e supplier_name. Segue-se um exemplo de fatura:
Segue-se o objeto de documento completo devolvido pelo analisador de faturas:
Seguem-se algumas das partes importantes do objeto document:
Campos detetados:
Entitiescontém os campos que o processador conseguiu detetar, por exemplo, o campoinvoice_date:{ "entities": [ { "textAnchor": { "textSegments": [ { "startIndex": "14", "endIndex": "24" } ], "content": "2020/01/01" }, "type": "invoice_date", "confidence": 0.9938466, "pageAnchor": { ... }, "id": "2", "normalizedValue": { "text": "2020-01-01", "dateValue": { "year": 2020, "month": 1, "day": 1 } } } ] }Para determinados campos, o processador também normaliza o valor. Neste exemplo, a data foi normalizada de
2020/01/01para2020-01-01.Normalização: para muitos campos suportados específicos, o processador também normaliza o valor e também devolve um
entity. O camponormalizedValueé adicionado ao campo extraído não processado obtido através dotextAnchorde cada entidade. Assim, normaliza o texto literal, dividindo frequentemente o valor de texto em subcampos. Por exemplo, uma data como 1 de setembro de 2024 seria representada da seguinte forma:
normalizedValue": {
"text": "2020-09-01",
"dateValue": {
"year": 2024,
"month": 9,
"day": 1
}
Neste exemplo, a data foi normalizada de 2020/01/01 para 2020-01-01, um formato padronizado para reduzir o pós-processamento e permitir a conversão para o formato escolhido.
Os endereços também são frequentemente normalizados, o que divide os elementos do endereço em campos individuais. Os números são normalizados com um número inteiro ou de ponto flutuante como o normalizedValue.
- Enriquecimento: determinados processadores e campos também suportam o enriquecimento.
Por exemplo, o original
supplier_nameno documentoGoogle Singaporefoi normalizado em relação ao Enterprise Knowledge Graph paraGoogle Asia Pacific, Singapore. Tenha também em atenção que, uma vez que o gráfico de conhecimento empresarial contém informações sobre a Google, a IA Documentos infere osupplier_address, mesmo que não estivesse presente no documento de exemplo.
{
"entities": [
{
"textAnchor": {
"textSegments": [ ... ],
"content": "Google Singapore"
},
"type": "supplier_name",
"confidence": 0.39170802,
"pageAnchor": { ... },
"id": "12",
"normalizedValue": {
"text": "Google Asia Pacific, Singapore"
}
},
{
"type": "supplier_address",
"id": "17",
"normalizedValue": {
"text": "70 Pasir Panjang Rd #03-71 Mapletree Business City II Singapore 117371",
"addressValue": {
"regionCode": "SG",
"languageCode": "en-US",
"postalCode": "117371",
"addressLines": [
"70 Pasir Panjang Rd",
"#03-71 Mapletree Business City II"
]
}
}
}
]
}
Campos aninhados: pode criar um esquema (campos) aninhado declarando primeiro uma entidade como principal e, em seguida, criando entidades secundárias na entidade principal. A resposta de análise do elemento principal inclui os campos subordinados no elemento
propertiesdo campo principal. No exemplo seguinte,line_itemé um campo principal que tem dois campos secundários:line_item/descriptioneline_item/quantity.{ "entities": [ { "textAnchor": { ... }, "type": "line_item", "confidence": 1.0, "pageAnchor": { ... }, "id": "19", "properties": [ { "textAnchor": { "textSegments": [ ... ], "content": "Tool A" }, "type": "line_item/description", "confidence": 0.3461604, "pageAnchor": { ... }, "id": "20" }, { "textAnchor": { "textSegments": [ ... ], "content": "500" }, "type": "line_item/quantity", "confidence": 0.8077843, "pageAnchor": { ... }, "id": "21", "normalizedValue": { "text": "500" } } ] } ] }
Os seguintes analisadores sintáticos seguem-no:
- Extrair (extrator personalizado)
- Antigo
- Analisador de extratos de conta
- Analisador de despesas
- Analisador de faturas
- Analisador de recibos de vencimento
- Analisador W2
Exemplos de código
Os seguintes exemplos de código demonstram como enviar um pedido de processamento e, em seguida, ler e imprimir os campos de um processador especializado no terminal:
Java
Para mais informações, consulte a documentação de referência da API Java Document AI.
Para se autenticar no Document AI, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para um ambiente de desenvolvimento local.
Node.js
Para mais informações, consulte a documentação de referência da API Node.js Document AI.
Para se autenticar no Document AI, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para um ambiente de desenvolvimento local.
Python
Para mais informações, consulte a documentação de referência da API Python Document AI.
Para se autenticar no Document AI, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para um ambiente de desenvolvimento local.
Extrator de documentos personalizado
O processador Custom Document Extractor pode extrair entidades personalizadas de documentos que não têm um processador pré-treinado disponível. Isto pode ser conseguido através da preparação de um modelo personalizado ou da utilização de modelos básicos de IA generativa para extrair entidades com nomes sem qualquer preparação. Para mais informações, consulte o artigo Crie um extrator de documentos personalizado na consola.
- Se preparar um modelo personalizado, o processador pode ser usado exatamente da mesma forma que um processador de extração de entidades pré-preparado.
- Se usar um modelo base, pode criar uma versão do processador para extrair entidades específicas para cada pedido ou pode configurá-la por pedido.
Para ver informações sobre a estrutura de saída, consulte o artigo Entidades, entidades aninhadas e valores normalizados.
Exemplos de código
Se estiver a usar um modelo personalizado ou tiver criado uma versão do processador com um modelo de base, use os exemplos de código de extração de entidades.
O seguinte exemplo de código demonstra como configurar entidades específicas para um extrator de documentos personalizado de modelo base por pedido e imprimir as entidades extraídas:
Python
Para mais informações, consulte a documentação de referência da API Python Document AI.
Para se autenticar no Document AI, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para um ambiente de desenvolvimento local.
Resumo
O processador Summarizer usa modelos de base de IA generativa para resumir o texto extraído de um documento. Pode personalizar a duração e o formato da resposta das seguintes formas:
- Duração
BRIEF: um breve resumo de uma ou duas frasesMODERATE: um resumo com o comprimento de um parágrafoCOMPREHENSIVE: a opção mais longa disponível
- Formato
Pode criar uma versão do processador para um comprimento e um formato específicos ou pode configurá-la por pedido.
O texto resumido aparece em Document.entities.normalizedValue.text. Pode encontrar um ficheiro JSON de saída de exemplo completo em Saída do processador de exemplo.
Para mais informações, consulte o artigo Crie um resumidor de documentos na consola.
Exemplos de código
O seguinte exemplo de código demonstra como configurar um comprimento e um formato específicos num pedido de processamento e imprimir o texto resumido:
Python
Para mais informações, consulte a documentação de referência da API Python Document AI.
Para se autenticar no Document AI, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para um ambiente de desenvolvimento local.
Divisão e classificação
Segue-se um PDF composto de 10 páginas que contém diferentes tipos de documentos e formulários:
Segue-se o objeto de documento completo devolvido pelo separador e classificador de documentos de empréstimo:
Cada documento detetado pelo separador é representado por um elemento
entity. Por exemplo:
{
"entities": [
{
"textAnchor": {
"textSegments": [
{
"startIndex": "13936",
"endIndex": "21108"
}
]
},
"type": "1040se_2020",
"confidence": 0.76257163,
"pageAnchor": {
"pageRefs": [
{
"page": "6"
},
{
"page": "7"
}
]
}
}
]
}
Entity.pageAnchorindica que este documento tem 2 páginas. Tenha em atenção quepageRefs[].pagebaseia-se em zero e é o índice no campodocument.pages[].Entity.typeespecifica que este documento é um formulário 1040 Schedule SE. Para ver uma lista completa dos tipos de documentos que podem ser identificados, consulte a secção Tipos de documentos identificados na documentação do processador.
Para mais informações, consulte o artigo Comportamento dos divisores de documentos.
Exemplos de código
Os divisores identificam os limites das páginas, mas não dividem o documento de entrada para si. Pode usar a caixa de ferramentas da Document AI para dividir fisicamente um ficheiro PDF usando os limites das páginas. Os seguintes exemplos de código imprimem os intervalos de páginas sem dividir o PDF:
Java
Para mais informações, consulte a documentação de referência da API Java Document AI.
Para se autenticar no Document AI, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para um ambiente de desenvolvimento local.
Node.js
Para mais informações, consulte a documentação de referência da API Node.js Document AI.
Para se autenticar no Document AI, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para um ambiente de desenvolvimento local.
Python
Para mais informações, consulte a documentação de referência da API Python Document AI.
Para se autenticar no Document AI, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para um ambiente de desenvolvimento local.
Document processado.
Python
Para mais informações, consulte a documentação de referência da API Python Document AI.
Para se autenticar no Document AI, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para um ambiente de desenvolvimento local.
Caixa de ferramentas do Document AI
A caixa de ferramentas da IA Documental é um SDK para Python que fornece funções de utilidade para gerir, manipular e extrair informações da resposta do documento.
Cria um objeto de documento "wrapped" a partir de uma resposta de documento processada de ficheiros JSON no
Cloud Storage, ficheiros JSON locais ou saída diretamente do método process_document().
Pode realizar as seguintes ações:
- Combine ficheiros JSON
Documentfragmentados do processamento em lote num único documento "envolvido". - Exporte fragmentos como um
Documentunificado. -
Receba o resultado
Documentde: - Aceder a texto de
Pages,Lines,Paragraphs,FormFieldseTablessem processar informaçõesLayout. - Pesquise um
Pagesque contenha uma string de destino ou que corresponda a uma expressão regular. - Pesquise
FormFieldspelo nome. - Pesquise
Entitiespor tipo. - Converta
Tablesnum Dataframe do Pandas ou num ficheiro CSV. - Inserir
EntitieseFormFieldsnuma tabela do BigQuery. - Divida um ficheiro PDF com base no resultado de um processador divisor/classificador.
- Extrair imagem
EntitiesdeDocumentcaixas delimitadoras. -
Converta
Documentspara e a partir de formatos usados frequentemente:- Cloud Vision API
AnnotateFileResponse - hOCR
- Formatos de processamento de documentos de terceiros
- Cloud Vision API
- Crie lotes de documentos para processamento a partir de uma pasta do Cloud Storage.
Exemplos de código
Os exemplos de código seguintes demonstram como usar o Document AI Toolbox.