
La risposta a una richiesta di elaborazione contiene un oggetto Document che include tutte le informazioni note sul documento elaborato, comprese tutte le informazioni strutturate che Document AI è riuscita a estrarre.
Questa pagina spiega il layout dell'oggetto Document fornendo documenti di esempio
e quindi mappando gli aspetti dei risultati OCR agli elementi specifici del JSON dell'oggetto Document.
Fornisce inoltre esempi di codice delle librerie client e dell'SDK Document AI Toolbox.
Questi esempi di codice utilizzano l'elaborazione online, ma l'analisi dell'oggetto Document funziona
allo stesso modo per l'elaborazione batch.
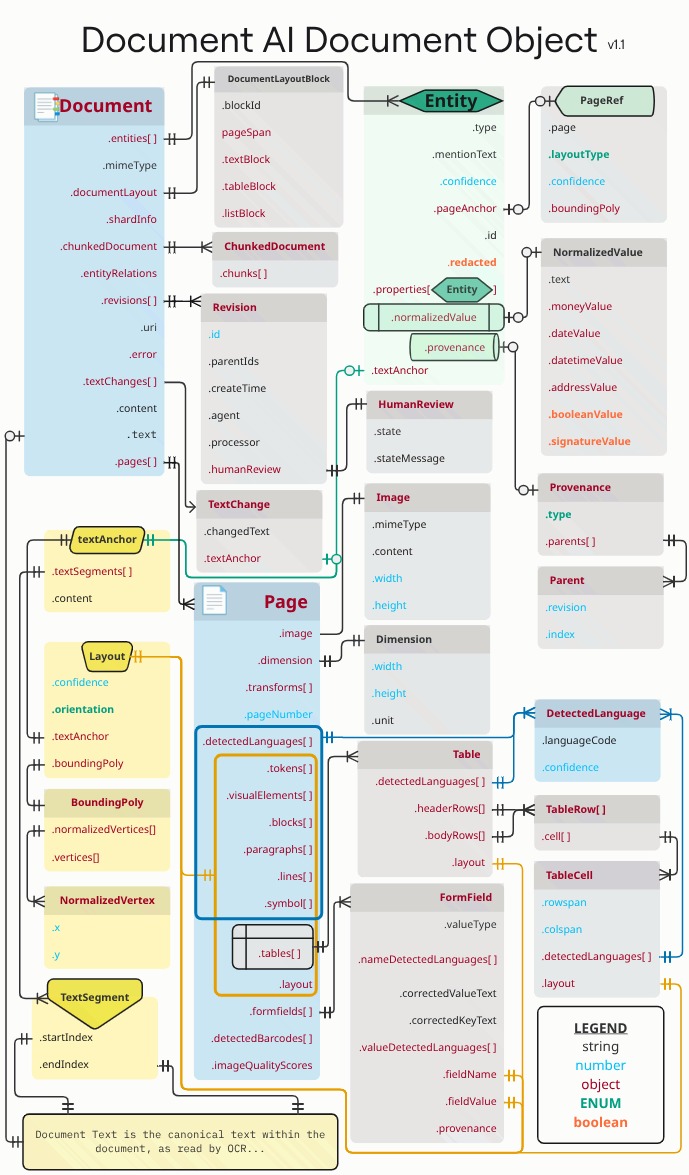
I rettangoli e le frecce arancioni e blu indicano che almeno un campo degli
oggetti collegati è .layout o detectedLanguage, rispettivamente. Il
diagramma utilizza la notazione
a zampa di gallina.
Utilizza un visualizzatore o un editor JSON progettato appositamente per espandere o comprimere gli elementi. La revisione del codice JSON non elaborato in un'utilità di testo normale è inefficiente.
Testo, layout e punteggi di qualità
Ecco un documento di testo di esempio:

Ecco l'oggetto documento completo restituito dal processore Enterprise Document OCR:
Questo output OCR è sempre incluso anche nell'output del processore Document AI, poiché l'OCR viene eseguito dai processori. Utilizza i dati OCR esistenti, motivo per cui puoi inserire questi dati JSON utilizzando l'opzione del documento in linea nei processori Document AI.
image=None, # all our samples pass this var
mime_type="application/json",
inline_document=document_response # pass OCR output to CDE input - undocumented
Ecco alcuni dei campi importanti:
Testo non elaborato
Il campo text contiene il testo riconosciuto da Document AI.
Questo testo non contiene alcuna struttura di layout diversa da spazi, tabulazioni e
avanzamenti di riga. Questo è l'unico campo che memorizza le informazioni
testuali di un documento e funge da fonte attendibile del testo del documento. Altri
campi possono fare riferimento a parti del campo di testo in base alla posizione (startIndex e endIndex).
{
text: "Sample Document\nHeading 1\nLorem ipsum dolor sit amet, ..."
}
Dimensioni pagina e lingue
Ogni page nell'oggetto documento corrisponde a una
pagina fisica del documento di esempio. L'output JSON di esempio contiene una
pagina perché è una singola immagine PNG.
{
"pages:" [
{
"pageNumber": 1,
"dimension": {
"width": 679.0,
"height": 460.0,
"unit": "pixels"
},
}
]
}
- Il campo
pages[].detectedLanguages[]contiene le lingue trovate in una determinata pagina, insieme al punteggio di affidabilità.
{
"pages": [
{
"detectedLanguages": [
{
"confidence": 0.98009938,
"languageCode": "en"
},
{
"confidence": 0.01990064,
"languageCode": "und"
}
]
}
]
}
Dati OCR
L'OCR di Document AI rileva il testo con vari livelli di granularità o organizzazione nella pagina, ad esempio blocchi di testo, paragrafi, token e simboli (il livello di simbolo è facoltativo, se configurato per restituire dati a livello di simbolo). Questi sono tutti i membri dell'oggetto pagina.
Ogni elemento ha un layout corrispondente che
ne descrive la posizione e il testo. Anche gli elementi visivi non di testo (come le caselle di controllo) si trovano a livello di pagina.
{
"pages": [
{
"paragraphs": [
{
"layout": {
"textAnchor": {
"textSegments": [
{
"endIndex": "16"
}
]
},
"confidence": 0.9939527,
"boundingPoly": {
"vertices": [ ... ],
"normalizedVertices": [ ... ]
},
"orientation": "PAGE_UP"
}
}
]
}
]
}
Il testo non elaborato viene indicato nell'oggetto textAnchor
che viene indicizzato nella stringa di testo principale con startIndex e endIndex.
Per
boundingPoly, l'origine è l'angolo in alto a sinistra della pagina(0,0). I valori X positivi si trovano a destra, mentre i valori Y positivi si trovano in basso.L'oggetto
verticesutilizza le stesse coordinate dell'immagine originale, mentrenormalizedVerticesrientrano nell'intervallo[0,1]. Esiste una matrice di trasformazione che indica le misure di correzione della distorsione e altri attributi della normalizzazione dell'immagine.
- Per disegnare il
boundingPoly, traccia segmenti di retta da un vertice all'altro. Quindi, chiudi il poligono tracciando un segmento di linea dall'ultimo vertice al primo. L'elemento orientation del layout indica se il testo è stato ruotato rispetto alla pagina.
Per aiutarti a visualizzare la struttura del documento, le seguenti immagini disegnano poligoni di delimitazione per page.paragraphs, page.lines e page.tokens.
Paragrafi

Righe

Token

Blocchi

Il processore Enterprise Document OCR può eseguire la valutazione della qualità di un documento in base alla sua leggibilità.
- Devi impostare il campo
processOptions.ocrConfig.enableImageQualityScoressutrueper ottenere questi dati nella risposta dell'API.
Questa valutazione della qualità è un punteggio di qualità in [0, 1], dove 1 indica una qualità perfetta.
Il punteggio di qualità viene restituito nel campo Page.imageQualityScores.
Tutti i difetti rilevati sono elencati come quality/defect_* e ordinati in ordine decrescente in base al valore di affidabilità.
Ecco un PDF troppo scuro e sfocato per essere letto comodamente:
Ecco le informazioni sulla qualità del documento restituite dal processore Enterprise Document OCR:
{
"pages": [
{
"imageQualityScores": {
"qualityScore": 0.7811847,
"detectedDefects": [
{
"type": "quality/defect_document_cutoff",
"confidence": 1.0
},
{
"type": "quality/defect_glare",
"confidence": 0.97849524
},
{
"type": "quality/defect_text_cutoff",
"confidence": 0.5
}
]
}
}
]
}
Esempi di codice
I seguenti esempi di codice mostrano come inviare una richiesta di elaborazione e poi leggere e stampare i campi nel terminale:
Java
Per saperne di più, consulta la documentazione di riferimento dell'API Document AI Java.
Per eseguire l'autenticazione in Document AI, configura le Credenziali predefinite dell'applicazione. Per saperne di più, consulta Configura l'autenticazione per un ambiente di sviluppo locale.
Node.js
Per saperne di più, consulta la documentazione di riferimento dell'API Document AI Node.js.
Per eseguire l'autenticazione in Document AI, configura le Credenziali predefinite dell'applicazione. Per saperne di più, consulta Configura l'autenticazione per un ambiente di sviluppo locale.
Python
Per saperne di più, consulta la documentazione di riferimento dell'API Document AI Python.
Per eseguire l'autenticazione in Document AI, configura le Credenziali predefinite dell'applicazione. Per saperne di più, consulta Configura l'autenticazione per un ambiente di sviluppo locale.
Moduli e tabelle
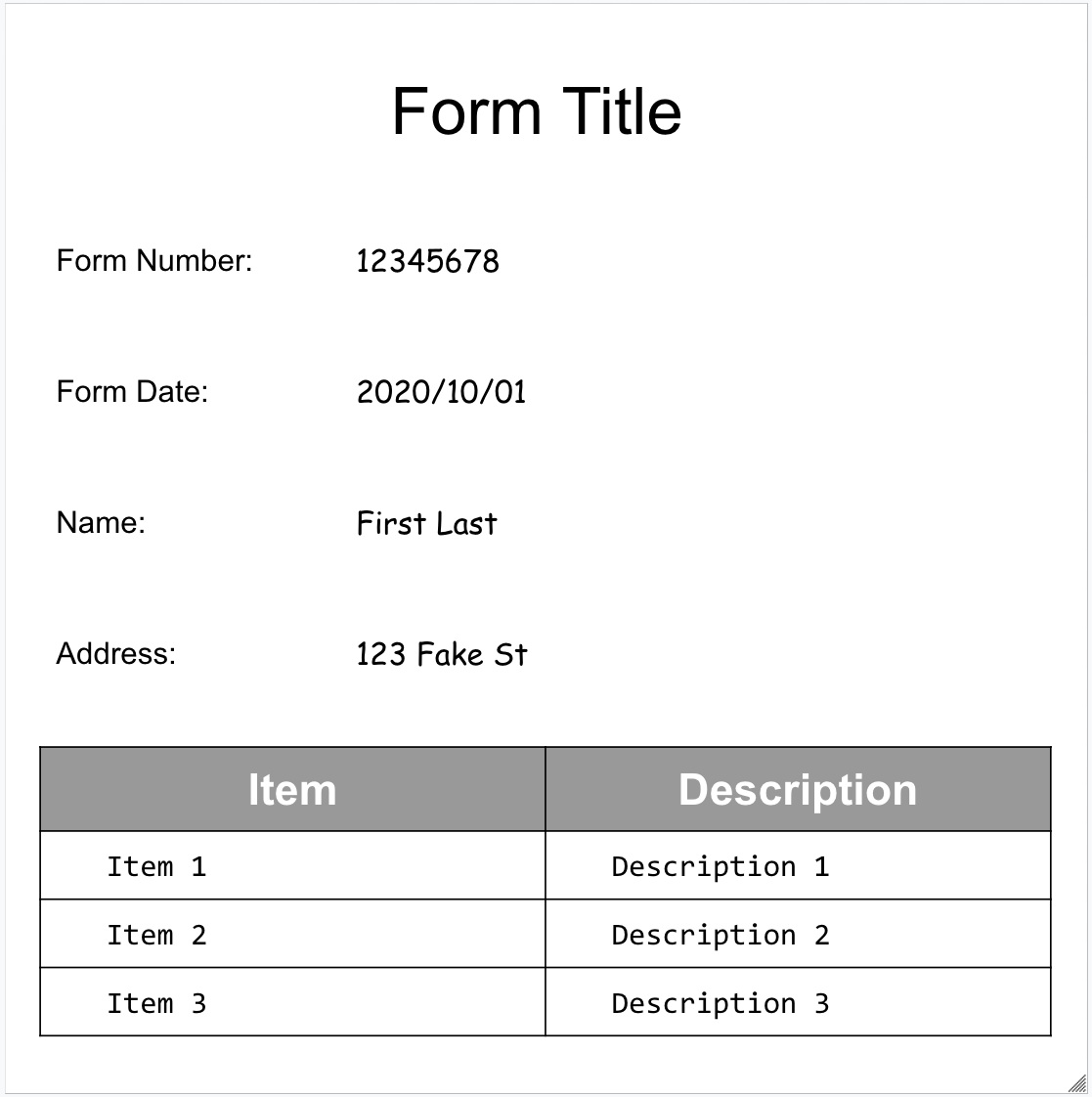
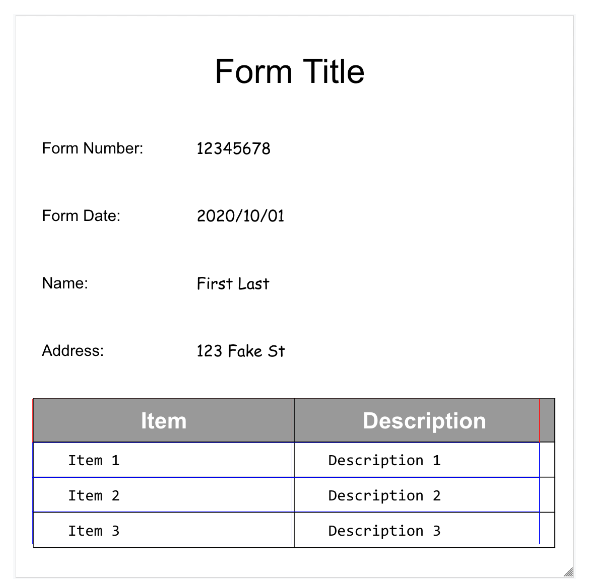
Ecco il nostro modulo di esempio:
Ecco l'oggetto documento completo restituito dal parser di moduli:
Ecco alcuni dei campi importanti:
L'analizzatore sintattico dei moduli è in grado di rilevare FormFields
nella pagina. Ogni campo del modulo ha un nome e un valore. Questi sono anche chiamati
coppie chiave-valore (KVP). Tieni presente che le coppie chiave-valore sono diverse dalle entità (schema) in
altri estrattori:
I nomi delle entità sono configurati. Le chiavi nelle coppie chiave-valore sono esattamente il testo della chiave nel documento.
{
"pages:" [
{
"formFields": [
{
"fieldName": { ... },
"fieldValue": { ... }
}
]
}
]
}
- Document AI può anche rilevare
Tablesnella pagina.
{
"pages:" [
{
"tables": [
{
"layout": { ... },
"headerRows": [
{
"cells": [
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
},
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
}
]
}
],
"bodyRows": [
{
"cells": [
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
},
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
}
]
}
]
}
]
}
]
}
L'estrazione delle tabelle all'interno di Form Parser riconosce solo le tabelle convenzionali,
ovvero quelle senza celle che si estendono su righe o colonne. Quindi rowSpan e colSpan sono sempre 1.
A partire dalla versione del processore
pretrained-form-parser-v2.0-2022-11-10, l'analizzatore sintattico di moduli può riconoscere anche le entità generiche. Per ulteriori informazioni, vedi Analizzatore di moduli.Per aiutarti a visualizzare la struttura del documento, le seguenti immagini disegnano poligoni di delimitazione per
page.formFieldsepage.tables.Caselle di controllo nelle tabelle. L'analizzatore sintattico di moduli è in grado di digitalizzare le caselle di controllo da immagini e PDF come coppie chiave-valore. Fornire un esempio di digitalizzazione della casella di controllo come coppia chiave-valore.

Al di fuori delle tabelle, le caselle di controllo sono rappresentate come elementi visivi all'interno di Form Parser. Evidenzia le caselle quadrate con i segni di spunta nell'interfaccia utente e il carattere Unicode ✓ nel file JSON.

"pages:" [
{
"tables": [
{
"layout": { ... },
"headerRows": [
{
"cells": [
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
},
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
}
]
}
],
"bodyRows": [
{
"cells": [
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
},
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
}
]
}
]
}
]
}
]
}
Nelle tabelle, le caselle di controllo vengono visualizzate come caratteri Unicode, ad esempio ✓ (selezionata) o ☐ (deselezionata).
Le caselle di controllo compilate hanno il valore filled_checkbox:
under pages > x > formFields > x > fieldValue > valueType.. Le caselle di controllo
deselezionate hanno il valore unfilled_checkbox.
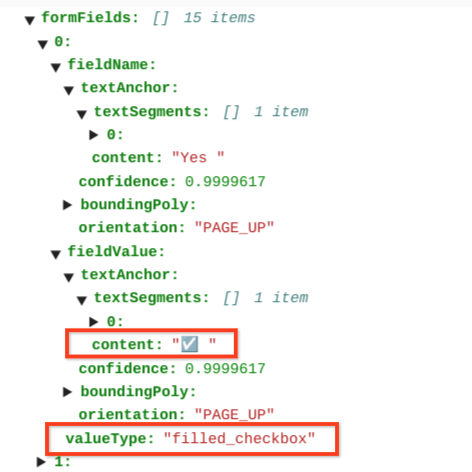
I campi dei contenuti mostrano il valore dei contenuti della casella di controllo evidenziato con ✓ nel percorso pages>formFields>x>fieldValue>textAnchor>content.
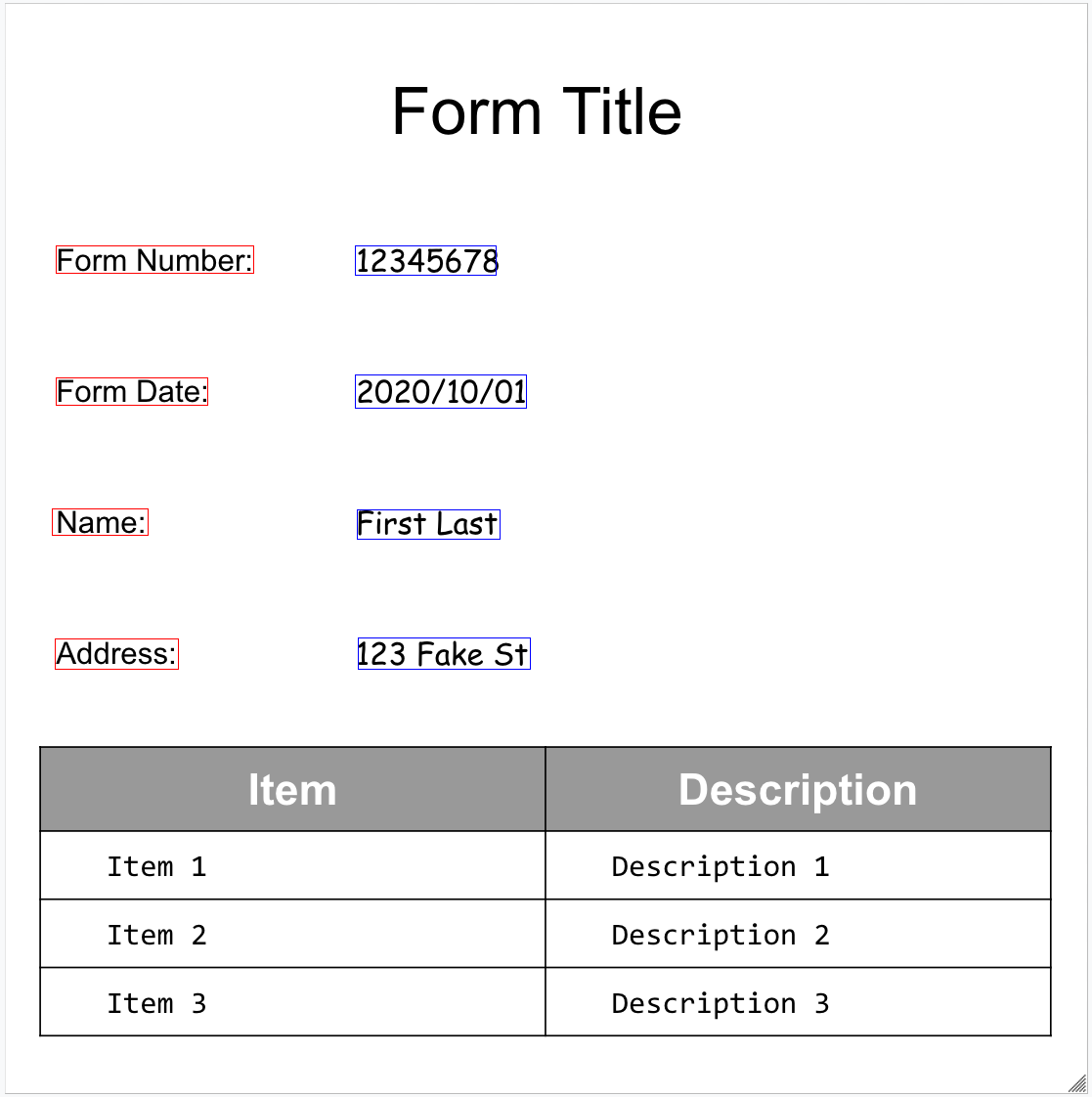
Per aiutarti a visualizzare la struttura del documento, le seguenti immagini disegnano poligoni di delimitazione
per page.formFields e page.tables.
Campi dei moduli
Tabelle
Esempi di codice
I seguenti esempi di codice mostrano come inviare una richiesta di elaborazione e poi leggere e stampare i campi nel terminale:
Java
Per saperne di più, consulta la documentazione di riferimento dell'API Document AI Java.
Per eseguire l'autenticazione in Document AI, configura le Credenziali predefinite dell'applicazione. Per saperne di più, consulta Configura l'autenticazione per un ambiente di sviluppo locale.
Node.js
Per saperne di più, consulta la documentazione di riferimento dell'API Document AI Node.js.
Per eseguire l'autenticazione in Document AI, configura le Credenziali predefinite dell'applicazione. Per saperne di più, consulta Configura l'autenticazione per un ambiente di sviluppo locale.
Python
Per saperne di più, consulta la documentazione di riferimento dell'API Document AI Python.
Per eseguire l'autenticazione in Document AI, configura le Credenziali predefinite dell'applicazione. Per saperne di più, consulta Configura l'autenticazione per un ambiente di sviluppo locale.
Entità, entità nidificate e valori normalizzati
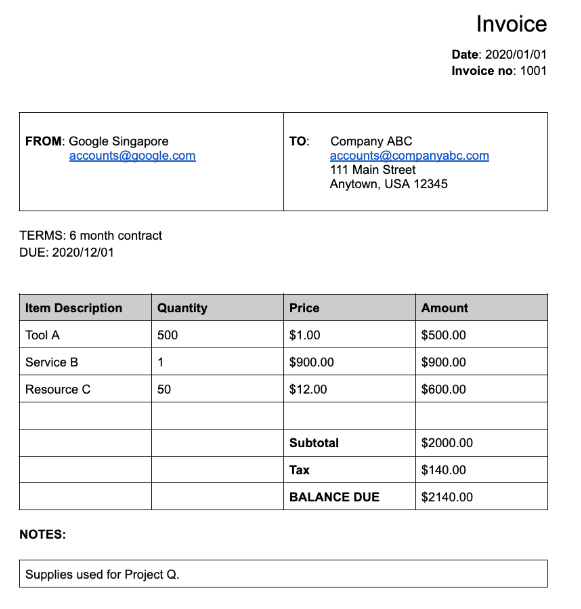
Molti dei processori specializzati estraggono dati strutturati basati su uno schema ben definito. Ad esempio, lo strumento di analisi delle fatture
rileva campi specifici come invoice_date e supplier_name. Ecco una
fattura di esempio:
Ecco l'oggetto documento completo restituito dal parser delle fatture:
Di seguito sono riportate alcune delle parti importanti dell'oggetto documento:
Campi rilevati:
Entitiescontiene i campi che il processore è riuscito a rilevare, ad esempioinvoice_date:{ "entities": [ { "textAnchor": { "textSegments": [ { "startIndex": "14", "endIndex": "24" } ], "content": "2020/01/01" }, "type": "invoice_date", "confidence": 0.9938466, "pageAnchor": { ... }, "id": "2", "normalizedValue": { "text": "2020-01-01", "dateValue": { "year": 2020, "month": 1, "day": 1 } } } ] }Per alcuni campi, il processore normalizza anche il valore. In questo esempio, la data è stata normalizzata da
2020/01/01a2020-01-01.Normalizzazione: per molti campi specifici supportati, il processore normalizza il valore e restituisce anche un
entity. Il camponormalizedValueviene aggiunto al campo estratto non elaborato ottenuto tramitetextAnchordi ogni entità. Pertanto, normalizza il testo letterale, spesso suddividendo il valore di testo in campi secondari. Ad esempio, una data come il 1° settembre 2024 verrebbe rappresentata come:
normalizedValue": {
"text": "2020-09-01",
"dateValue": {
"year": 2024,
"month": 9,
"day": 1
}
In questo esempio, la data è stata normalizzata da 01/01/2020 a 2020-01-01, un formato standardizzato per ridurre la post-elaborazione e consentire la conversione nel formato scelto.
Gli indirizzi vengono spesso normalizzati, il che suddivide gli elementi dell'indirizzo
in singoli campi. I numeri vengono normalizzati utilizzando un numero intero o in virgola mobile come normalizedValue.
- Arricchimento: alcuni processori e campi supportano anche l'arricchimento.
Ad esempio, il
supplier_nameoriginale nel documentoGoogle Singaporeè stato normalizzato rispetto a Enterprise Knowledge Graph inGoogle Asia Pacific, Singapore. Tieni presente inoltre che, poiché Enterprise Knowledge Graph contiene informazioni su Google, Document AI deduce ilsupplier_addressanche se non era presente nel documento di esempio.
{
"entities": [
{
"textAnchor": {
"textSegments": [ ... ],
"content": "Google Singapore"
},
"type": "supplier_name",
"confidence": 0.39170802,
"pageAnchor": { ... },
"id": "12",
"normalizedValue": {
"text": "Google Asia Pacific, Singapore"
}
},
{
"type": "supplier_address",
"id": "17",
"normalizedValue": {
"text": "70 Pasir Panjang Rd #03-71 Mapletree Business City II Singapore 117371",
"addressValue": {
"regionCode": "SG",
"languageCode": "en-US",
"postalCode": "117371",
"addressLines": [
"70 Pasir Panjang Rd",
"#03-71 Mapletree Business City II"
]
}
}
}
]
}
Campi nidificati: è possibile creare uno schema (campi) nidificato dichiarando prima un'entità come principale, quindi creando entità secondarie sotto la principale. La risposta all'analisi del genitore include i campi secondari nell'elemento
propertiesdel campo principale. Nell'esempio seguente,line_itemè un campo principale che ha due campi secondari:line_item/descriptioneline_item/quantity.{ "entities": [ { "textAnchor": { ... }, "type": "line_item", "confidence": 1.0, "pageAnchor": { ... }, "id": "19", "properties": [ { "textAnchor": { "textSegments": [ ... ], "content": "Tool A" }, "type": "line_item/description", "confidence": 0.3461604, "pageAnchor": { ... }, "id": "20" }, { "textAnchor": { "textSegments": [ ... ], "content": "500" }, "type": "line_item/quantity", "confidence": 0.8077843, "pageAnchor": { ... }, "id": "21", "normalizedValue": { "text": "500" } } ] } ] }
I seguenti parser lo seguono:
- Estrai (estrattore personalizzato)
- Legacy
- Analizzatore sintattico estratto conto bancario
- Parser spese
- Analizzatore sintattico delle fatture
- Analizzatore busta paga
- Analizzatore W2
Esempi di codice
I seguenti esempi di codice mostrano come inviare una richiesta di elaborazione e poi leggere e stampare i campi di un processore specializzato nel terminale:
Java
Per saperne di più, consulta la documentazione di riferimento dell'API Document AI Java.
Per eseguire l'autenticazione in Document AI, configura le Credenziali predefinite dell'applicazione. Per saperne di più, consulta Configura l'autenticazione per un ambiente di sviluppo locale.
Node.js
Per saperne di più, consulta la documentazione di riferimento dell'API Document AI Node.js.
Per eseguire l'autenticazione in Document AI, configura le Credenziali predefinite dell'applicazione. Per saperne di più, consulta Configura l'autenticazione per un ambiente di sviluppo locale.
Python
Per saperne di più, consulta la documentazione di riferimento dell'API Document AI Python.
Per eseguire l'autenticazione in Document AI, configura le Credenziali predefinite dell'applicazione. Per saperne di più, consulta Configura l'autenticazione per un ambiente di sviluppo locale.
Estrattore di documenti personalizzato
Il processore estrattore di documenti personalizzato può estrarre entità personalizzate da documenti per i quali non è disponibile un processore preaddestrato. Ciò può essere ottenuto addestrando un modello personalizzato o utilizzando i modelli di base di AI generativa per estrarre entità denominate senza alcun addestramento. Per saperne di più, consulta Crea un estrattore di documenti personalizzato nella console.
- Se addestri un modello personalizzato, il processore può essere utilizzato esattamente allo stesso modo di un processore di estrazione di entità preaddestrato.
- Se utilizzi un foundation model, puoi creare una versione del processore per estrarre entità specifiche per ogni richiesta oppure puoi configurarla in base a ogni richiesta.
Per informazioni sulla struttura dell'output, consulta Entità, entità nidificate e valori normalizzati.
Esempi di codice
Se utilizzi un modello personalizzato o hai creato una versione del processore utilizzando un foundation model, utilizza gli esempi di codice per l'estrazione di entità.
Il seguente esempio di codice mostra come configurare entità specifiche per un estrattore di documenti personalizzato del foundation model in base alla richiesta e stampare le entità estratte:
Python
Per saperne di più, consulta la documentazione di riferimento dell'API Document AI Python.
Per eseguire l'autenticazione in Document AI, configura le Credenziali predefinite dell'applicazione. Per saperne di più, consulta Configura l'autenticazione per un ambiente di sviluppo locale.
Riassunto
Il processore di riassunti utilizza i foundation model di AI generativa per riassumere il testo estratto da un documento. La lunghezza e il formato della risposta possono essere personalizzati nei seguenti modi:
- Lunghezza
BRIEF: un breve riepilogo di una o due frasiMODERATE: un riepilogo della lunghezza di un paragrafoCOMPREHENSIVE: l'opzione più lunga disponibile
- Formato
Puoi creare una versione del processore per una lunghezza e un formato specifici oppure puoi configurarla in base alla richiesta.
Il testo riepilogativo viene visualizzato in Document.entities.normalizedValue.text. Puoi trovare un file JSON di output di esempio completo in Output del processore di esempio.
Per saperne di più, consulta Creare un generatore di riassunti dei documenti nella console.
Esempi di codice
Il seguente esempio di codice mostra come configurare una lunghezza e un formato specifici in una richiesta di elaborazione e stampare il testo riepilogato:
Python
Per saperne di più, consulta la documentazione di riferimento dell'API Document AI Python.
Per eseguire l'autenticazione in Document AI, configura le Credenziali predefinite dell'applicazione. Per saperne di più, consulta Configura l'autenticazione per un ambiente di sviluppo locale.
Divisione e classificazione
Ecco un PDF composito di 10 pagine che contiene diversi tipi di documenti e moduli:
Ecco l'oggetto documento completo restituito dallo strumento di divisione e classificazione dei documenti creditizi:
Ogni documento rilevato dallo splitter è rappresentato da un
entity. Ad esempio:
{
"entities": [
{
"textAnchor": {
"textSegments": [
{
"startIndex": "13936",
"endIndex": "21108"
}
]
},
"type": "1040se_2020",
"confidence": 0.76257163,
"pageAnchor": {
"pageRefs": [
{
"page": "6"
},
{
"page": "7"
}
]
}
}
]
}
Entity.pageAnchorindica che il documento è composto da 2 pagine. Tieni presente chepageRefs[].pageè in base zero ed è l'indice del campodocument.pages[].Entity.typespecifica che questo documento è un modulo 1040 Schedule SE. Per un elenco completo dei tipi di documenti che possono essere identificati, consulta Tipi di documenti identificati nella documentazione del processore.
Per saperne di più, consulta Comportamento dei separatori di documenti.
Esempi di codice
I separatori identificano i limiti delle pagine, ma non dividono effettivamente il documento di input. Puoi utilizzare Document AI Toolbox per dividere fisicamente un file PDF utilizzando i limiti della pagina. I seguenti esempi di codice stampano gli intervalli di pagine senza dividere il PDF:
Java
Per saperne di più, consulta la documentazione di riferimento dell'API Document AI Java.
Per eseguire l'autenticazione in Document AI, configura le Credenziali predefinite dell'applicazione. Per saperne di più, consulta Configura l'autenticazione per un ambiente di sviluppo locale.
Node.js
Per saperne di più, consulta la documentazione di riferimento dell'API Document AI Node.js.
Per eseguire l'autenticazione in Document AI, configura le Credenziali predefinite dell'applicazione. Per saperne di più, consulta Configura l'autenticazione per un ambiente di sviluppo locale.
Python
Per saperne di più, consulta la documentazione di riferimento dell'API Document AI Python.
Per eseguire l'autenticazione in Document AI, configura le Credenziali predefinite dell'applicazione. Per saperne di più, consulta Configura l'autenticazione per un ambiente di sviluppo locale.
Document elaborato.
Python
Per saperne di più, consulta la documentazione di riferimento dell'API Document AI Python.
Per eseguire l'autenticazione in Document AI, configura le Credenziali predefinite dell'applicazione. Per saperne di più, consulta Configura l'autenticazione per un ambiente di sviluppo locale.
Document AI Toolbox
Document AI Toolbox è un SDK per Python che fornisce funzioni di utilità
per gestire, manipolare ed estrarre informazioni dalla risposta del documento.
Crea un oggetto documento "wrapped" da una risposta del documento elaborata dai file JSON in
Cloud Storage, dai file JSON locali o dall'output direttamente dal metodo process_document().
Può eseguire le seguenti azioni:
- Combina i file JSON
Documentframmentati dell'elaborazione batch in un unico documento "wrapped". - Esporta gli shard come un unico
Document. -
Ottieni l'output
Documentda: - Accedi al testo da
Pages,Lines,Paragraphs,FormFieldseTablessenza gestire le informazioniLayout. - Cerca un
Pagescontenente una stringa di destinazione o corrispondente a un'espressione regolare. - Cerca
FormFieldsper nome. - Cerca
Entitiesper tipo. - Converti
Tablesin un DataFrame Pandas o in un file CSV. - Inserisci
EntitieseFormFieldsin una tabella BigQuery. - Dividi un file PDF in base all'output di un processore Splitter/Classifier.
- Estrai l'immagine
EntitiesdaDocumentriquadri di delimitazione. -
Converti
Documentsin e da formati di uso comune:- API Cloud Vision
AnnotateFileResponse - hOCR
- Formati di elaborazione dei documenti di terze parti
- API Cloud Vision
- Crea batch di documenti da elaborare da una cartella Cloud Storage.
Esempi di codice
I seguenti esempi di codice mostrano come utilizzare Document AI Toolbox.