
O Document AI gera métricas de avaliação, como a precisão e a revocação, para ajudar a determinar o desempenho preditivo dos seus processadores.
Estas métricas de avaliação são geradas comparando as entidades devolvidas pelo processador (as previsões) com as anotações nos documentos de teste. Se o seu processador não tiver um conjunto de testes, tem primeiro de criar um conjunto de dados e etiquetar os documentos de teste.
Execute uma avaliação
É executada automaticamente uma avaliação sempre que forma ou atualiza uma versão do processador.
Também pode executar uma avaliação manualmente. Isto é necessário para gerar métricas atualizadas depois de modificar o conjunto de testes ou se estiver a avaliar uma versão do processador pré-treinado.
IU da Web
Na Google Cloud consola, aceda à página Processadores e escolha o seu processador.
No separador Avaliar e testar, selecione a versão do processador a avaliar e, de seguida, clique em Executar nova avaliação.
Quando estiver concluída, a página contém métricas de avaliação para todas as etiquetas e para cada etiqueta individual.
Python
Para mais informações, consulte a documentação de referência da API Python Document AI.
Para se autenticar no Document AI, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para um ambiente de desenvolvimento local.
Obtenha os resultados de uma avaliação
IU da Web
Na Google Cloud consola, aceda à página Processadores e escolha o seu processador.
No separador Avaliar e testar, selecione a Versão do processador para ver a avaliação.
Quando estiver concluída, a página contém métricas de avaliação para todas as etiquetas e para cada etiqueta individual.
Python
Para mais informações, consulte a documentação de referência da API Python Document AI.
Para se autenticar no Document AI, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para um ambiente de desenvolvimento local.
Apresenta todas as avaliações de uma versão do processador
Python
Para mais informações, consulte a documentação de referência da API Python Document AI.
Para se autenticar no Document AI, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para um ambiente de desenvolvimento local.
Métricas de avaliação para todas as etiquetas
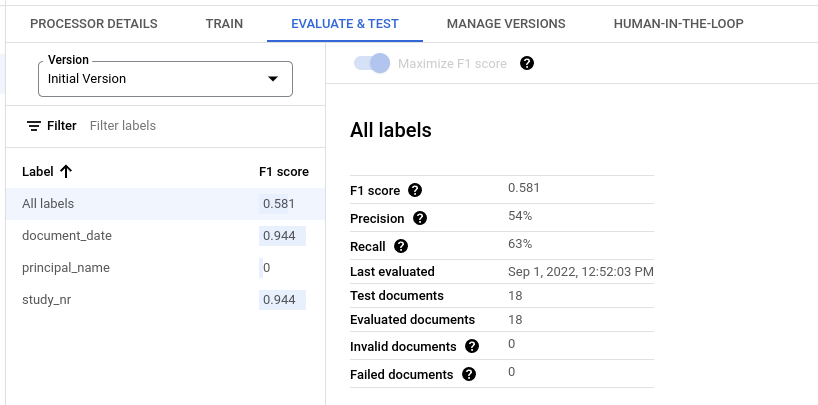
As métricas para Todas as etiquetas são calculadas com base no número de verdadeiros positivos, falsos positivos e falsos negativos no conjunto de dados em todas as etiquetas e, por isso, são ponderadas pelo número de vezes que cada etiqueta aparece no conjunto de dados. Para ver as definições destes termos, consulte o artigo Métricas de avaliação para etiquetas individuais.
Precisão: a proporção de previsões que correspondem às anotações no conjunto de testes. Definido como
True Positives / (True Positives + False Positives)Recuperação: a proporção de anotações no conjunto de testes que são corretamente previstas. Definido como
True Positives / (True Positives + False Negatives)Pontuação F1: o meio harmónico de precisão e revocação, que combina a precisão e a revocação numa única métrica, atribuindo igual importância a ambas. Definido como
2 * (Precision * Recall) / (Precision + Recall)
Métricas de avaliação para etiquetas individuais
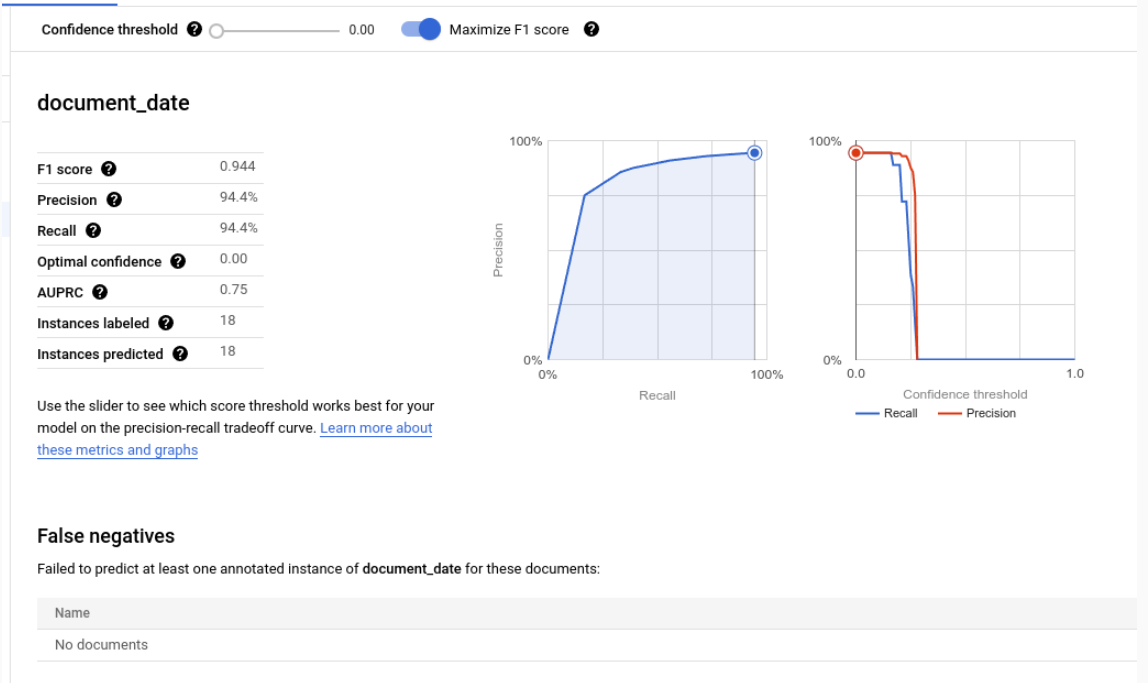
Verdadeiros positivos: as entidades previstas que correspondem a uma anotação no documento de teste. Para mais informações, consulte o artigo sobre o comportamento de correspondência.
Falsos positivos: as entidades previstas que não correspondem a nenhuma anotação no documento de teste.
Falsos negativos: as anotações no documento de teste que não correspondem a nenhuma das entidades previstas.
- Falsos negativos (abaixo do limite): as anotações no documento de teste que corresponderiam a uma entidade prevista, mas o valor de confiança da entidade prevista está abaixo do limite de confiança especificado.
Limite de confiança
A lógica de avaliação ignora todas as previsões com uma confiança inferior ao limite de confiança especificado, mesmo que a previsão esteja correta. A IA do Documento fornece uma lista de Falsos negativos (abaixo do limite), que são as anotações que teriam uma correspondência se o limite de confiança fosse definido como inferior.
A IA Documental calcula automaticamente o limite ideal, que maximiza a pontuação F1 e, por predefinição, define o limite de confiança para este valor ideal.
Pode escolher o seu próprio limiar de confiança movendo a barra de deslize. Em geral, um limite de confiança mais elevado resulta no seguinte:
- Maior precisão, porque é mais provável que as previsões estejam corretas.
- Uma precisão mais baixa, porque existem menos previsões.
Entidades tabulares
As métricas de uma etiqueta principal não são calculadas através da média direta das métricas secundárias, mas sim aplicando o limite de confiança da principal a todas as etiquetas secundárias e agregando os resultados.
O limite ideal para o elemento principal é o valor do limite de confiança que, quando aplicado a todos os elementos secundários, produz a pontuação F1 máxima para o elemento principal.
Comportamento de correspondência
Uma entidade prevista corresponde a uma anotação se:
- o tipo da entidade prevista
(
entity.type) corresponde ao nome da etiqueta da anotação - O valor da entidade prevista (
entity.mention_textouentity.normalized_value.text) corresponde ao valor de texto da anotação, sujeito à correspondência aproximada, se estiver ativada.
Tenha em atenção que o tipo e o valor de texto são tudo o que é usado para a correspondência. Não são usadas outras informações, como as âncoras de texto e as caixas delimitadoras (com exceção das entidades tabulares descritas abaixo).
Etiquetas de ocorrência única versus múltipla
As etiquetas de ocorrência única têm um valor por documento (por exemplo, o ID da fatura), mesmo que esse valor seja anotado várias vezes no mesmo documento (por exemplo, o ID da fatura aparece em todas as páginas do mesmo documento). Mesmo que as várias anotações tenham texto diferente, são consideradas iguais. Por outras palavras, se uma entidade prevista corresponder a alguma das anotações, é considerada uma correspondência. As anotações adicionais são consideradas menções duplicadas e não contribuem para nenhuma das contagens de verdadeiro positivo, falso positivo ou falso negativo.
As etiquetas de ocorrência múltipla podem ter vários valores diferentes. Assim, cada entidade e anotação prevista é considerada e correspondida separadamente. Se um documento contiver N anotações para uma etiqueta de ocorrências múltiplas, podem existir N correspondências com as entidades previstas. Cada entidade e anotação previstas são contabilizadas independentemente como um verdadeiro positivo, um falso positivo ou um falso negativo.
Correspondência semelhante
O botão Correspondência aproximada permite-lhe restringir ou flexibilizar algumas das regras de correspondência para diminuir ou aumentar o número de correspondências.
Por exemplo, sem a correspondência aproximada, a string ABC não corresponde a abc devido ao uso de maiúsculas. No entanto, com a correspondência semelhante, correspondem.
Quando a correspondência aproximada está ativada, as regras são alteradas da seguinte forma:
Normalização de espaços em branco: remove os espaços em branco à esquerda e à direita e condensa os espaços em branco intermediários consecutivos (incluindo novas linhas) em espaços únicos.
Remoção de pontuação à esquerda/direita: remove os seguintes carateres de pontuação à esquerda/direita
!,.:;-"?|.Correspondência não sensível a maiúsculas e minúsculas: converte todos os carateres em minúsculas.
Normalização de dinheiro: para etiquetas com o tipo de dados
money, remova os símbolos de moeda iniciais e finais.
Entidades tabulares
As entidades principais e as anotações não têm valores de texto e são correspondidas com base nas caixas delimitadoras combinadas dos respetivos elementos secundários. Se existir apenas um elemento principal previsto e um elemento principal anotado, estes são automaticamente correspondidos, independentemente das caixas delimitadoras.
Depois de os pais serem associados, os filhos são associados como se fossem entidades não tabulares. Se não for encontrada uma correspondência para os pais, o Document AI não tenta encontrar uma correspondência para os filhos. Isto significa que as entidades secundárias podem ser consideradas incorretas, mesmo com o mesmo conteúdo de texto, se as respetivas entidades principais não forem correspondentes.
As entidades principais / secundárias são uma funcionalidade de pré-visualização e só são suportadas para tabelas com uma camada de aninhamento.
Exporte métricas de avaliação
Na Google Cloud consola, aceda à página Processadores e escolha o seu processador.
No separador Avaliar e testar, clique em Transferir métricas para transferir as métricas de avaliação como um ficheiro JSON.
Painel de controlo de monitorização
O painel de controlo de monitorização na Google Cloud consola oferece uma forma útil de criar as suas próprias visualizações de monitorização para diferentes métricas e recursos usados nos processadores de IA de documentos.
Lista de métricas e respetivos campos: Número de páginas processadas com êxito e
Número total de documentos enviados para processamento. Ambas têm os seguintes campos:
location, processor type, processor_id, processor_version_id, status
e processing_type.
Latência de processamento de sincronização, Latência de processamento em lote por documento e
Contagem de operações de processamento em lote têm os seguintes campos: location,
processor_type, processor_id, processor_version_id e status.
Crie uma vista de monitorização
Pode monitorizar os seus processadores individual e coletivamente, com uma vista por processador e uma vista por projeto. Os passos para estas são os mesmos.
Na Google Cloud consola, na secção Document AI, aceda à página Processadores.
Opcional: se quiser monitorizar um processador específico, selecione-o na lista.
Use o painel de navegação para selecionar a opção Monitorização monitorização.
Defina o Intervalo de tempo.
Preencha as caixas de verificação das etiquetas de recursos e métricas selecionadas e selecione OK.
Opcional: pode ver mais opções para cada gráfico com a opção Menu .