
如要訓練、進階訓練或評估處理器版本,必須使用加上標籤的文件資料集。
本頁說明如何建立資料集、匯入文件及定義結構定義。如要標記匯入的文件,請參閱「標記文件」。
本頁假設您已建立支援訓練、進階訓練或評估的處理器。如果處理器受到支援,您會在 Google Cloud 控制台中看到「Train」(訓練) 分頁。
資料集儲存空間選項
您可以選擇下列兩種方式儲存資料集:
- Google 代管
- 自訂 Cloud Storage 位置
除非您有特殊需求 (例如將文件存放在一組啟用 CMEK 的資料夾中),否則建議您選擇較簡單的 Google 管理儲存空間選項。建立處理器後,就無法變更資料集儲存空間選項。
自訂 Cloud Storage 位置的資料夾或子資料夾必須從空白開始,且只能以唯讀方式處理。手動變更資料集內容可能會導致資料集無法使用,甚至遺失。Google 代管的儲存空間選項則沒有這項風險。
請按照下列步驟佈建儲存空間位置。
Google 代管的儲存空間 (建議)
建立新處理器時顯示進階選項。
將預設單選群組選項保留為 Google 代管 儲存空間。
選取「建立」。
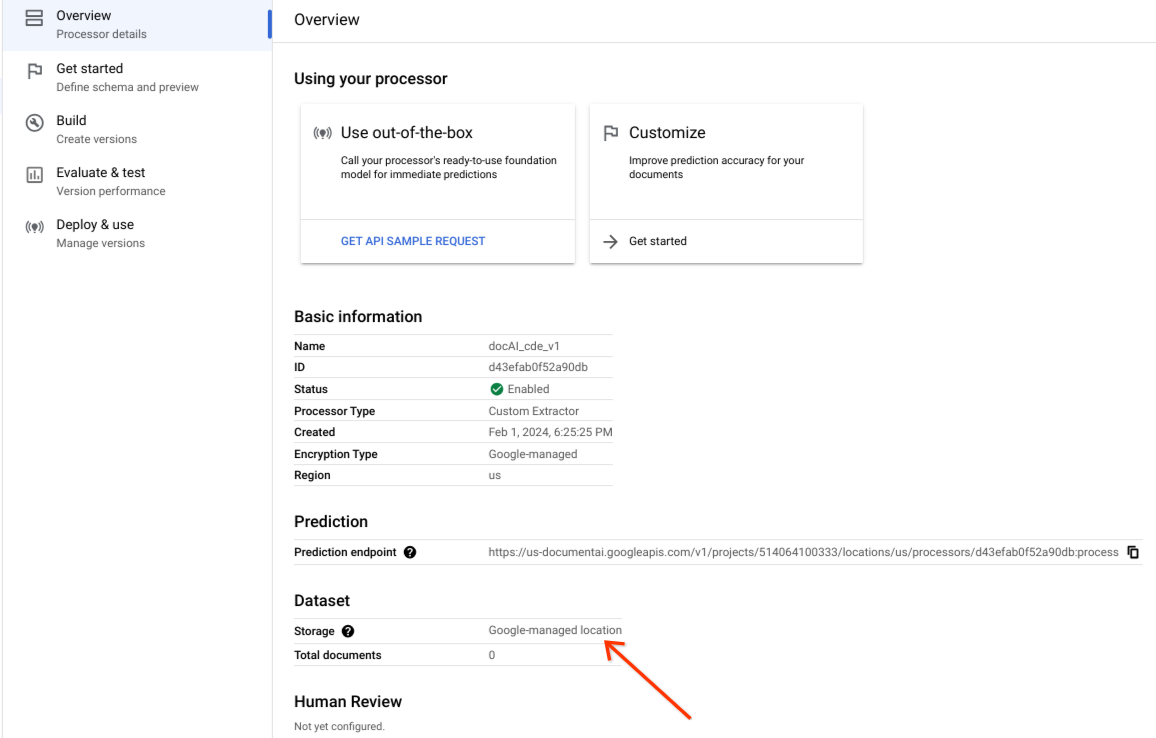
確認資料集已成功建立,且資料集位置為「Google 管理的位置」。
自訂儲存空間選項
開啟或關閉進階選項。
選取「自行指定儲存空間位置」。
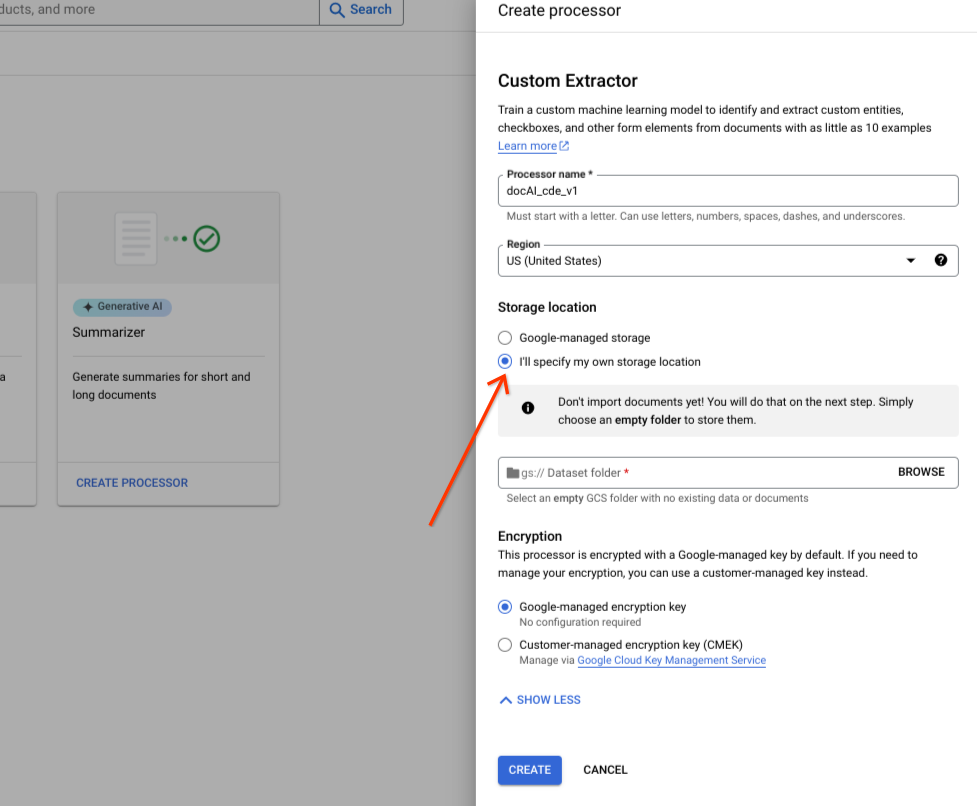
從輸入元件選擇 Cloud Storage 資料夾。
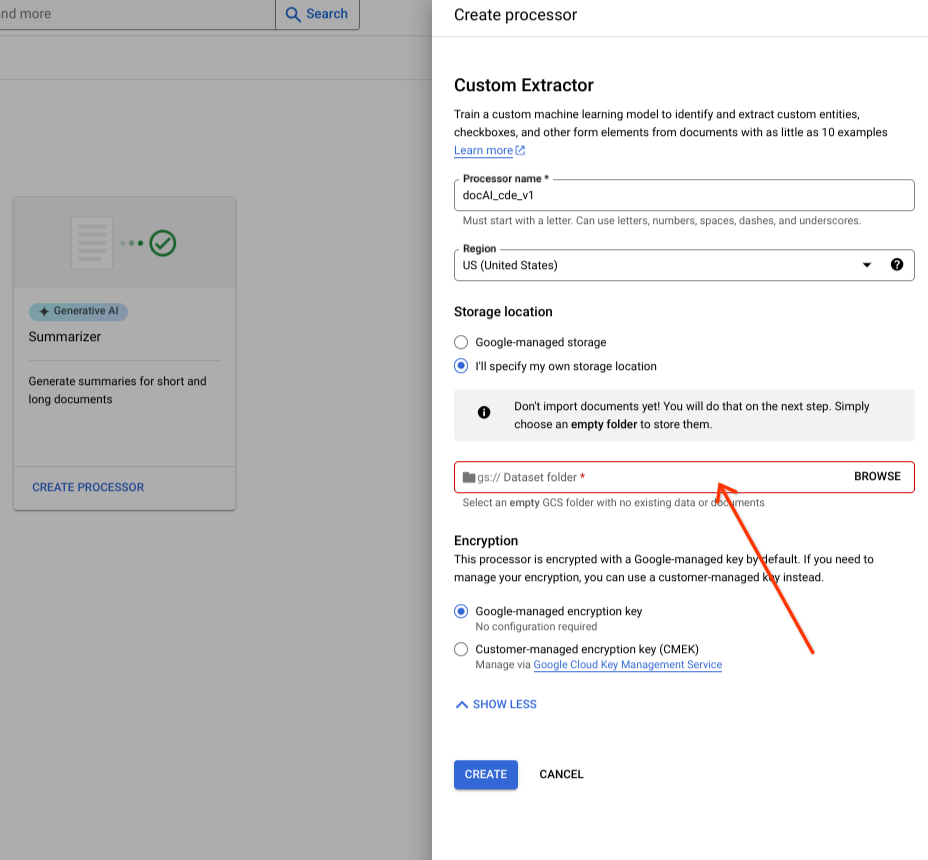
選取「建立」。
Dataset API (tf.data) 作業
這個範例說明如何使用 processors.updateDataset 方法建立資料集。資料集資源是處理器中的單一資源,也就是說,沒有建立資源 RPC。請改用 updateDataset RPC 設定偏好設定。Document AI 提供選項,可將資料集文件儲存在您提供的 Cloud Storage bucket 中,或由 Google 自動管理。
使用任何要求資料之前,請先替換以下項目:
LOCATION: Your processor location
PROJECT_ID: Your Google Cloud project ID
PROCESSOR_ID The ID of your custom processor
GCS_URI: Your Cloud Storage URI where dataset documents are stored
提供的 bucket
請按照後續步驟,使用您提供的 Cloud Storage bucket 建立資料集要求。
HTTP 方法
PATCH https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset要求 JSON:
{
"name":"projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset"
"gcs_managed_config" {
"gcs_prefix" {
"gcs_uri_prefix": "GCS_URI"
}
}
"spanner_indexing_config" {}
}Google 代管
如要建立 Google 管理的資料集,請更新下列資訊:
HTTP 方法
PATCH https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset要求 JSON:
{
"name":"projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset"
"unmanaged_dataset_config": {}
"spanner_indexing_config": {}
}如要傳送要求,可以使用 Curl:
將要求主體儲存在名為 request.json 的檔案中。執行下列指令:
CURL
curl -X PATCH \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset"您應該會收到如下的 JSON 回覆:
{
"name": "projects/PROJECT_ID/locations/LOCATION/operations/OPERATION_ID"
}匯入文件
新建立的資料集是空的。如要新增文件,請選取「匯入文件」,然後選取一或多個 Cloud Storage 資料夾,內含要新增至資料集的文件。
如果 Cloud Storage 位於其他 Google Cloud 專案,請務必授予存取權,允許 Document AI 從該位置讀取檔案。具體來說,您必須將「Storage 物件檢視者」角色授予 Document AI 的核心服務代理 service-{project-id}@gcp-sa-prod-dai-core.iam.gserviceaccount.com。詳情請參閱「服務代理程式」。
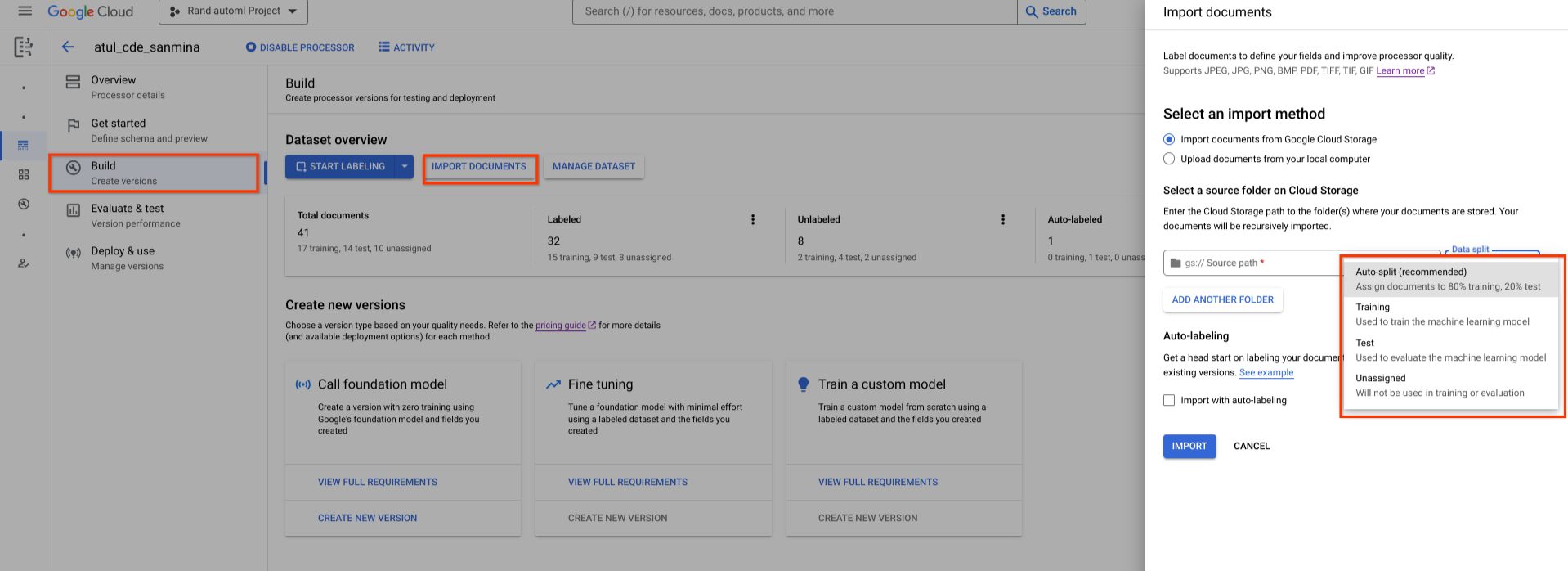
然後選擇下列其中一個指派選項:
- 訓練:指派給訓練集。
- 測試:指派給測試集。
- 自動分割:隨機重組訓練集和測試集中的文件。
- 未指派:不會用於訓練或評估。你稍後可以手動指派。
日後可隨時修改指派內容。
選取「匯入」後,Document AI 會將所有支援的檔案類型和 JSON Document 檔案匯入資料集。如果是 JSON Document 檔案,Document AI 會匯入文件並將 entities 轉換為標籤例項。
Document AI 不會修改匯入資料夾,也不會在匯入完成後從資料夾讀取資料。
選取頁面頂端的「活動」,開啟「活動」面板,其中會列出成功匯入的檔案,以及匯入失敗的檔案。
如果您已有處理器版本,可以在「匯入文件」對話方塊中,選取「使用自動加上標籤功能匯入」核取方塊。匯入文件時,系統會使用先前的處理器自動加上標籤。如未將自動加上標籤的文件標示為已加上標籤,則無法使用該文件訓練或進階訓練模型,也無法將該文件用於測試集。匯入自動加上標籤的文件後,請手動審查並修正這些文件。然後選取「儲存」,儲存修正內容並將文件標示為已加上標籤。然後視需要指派文件。請參閱「自動加上標籤」。
匯入文件 RPC
這個範例說明如何使用 dataset.importDocuments 方法將文件匯入資料集。
使用任何要求資料之前,請先替換以下項目:
LOCATION: Your processor location
PROJECT_ID: Your Google Cloud project ID
PROCESSOR_ID: The ID of your custom processor
GCS_URI: Your Cloud Storage URI where dataset documents are stored
DATASET_TYPE: The dataset type to which you want to add documents. The value should be either `DATASET_SPLIT_TRAIN` or `DATASET_SPLIT_TEST`.
TRAINING_SPLIT_RATIO: The ratio of documents which you want to autoassign to the training set.
訓練或測試資料集
如要將文件新增至訓練或測試資料集:
HTTP 方法
POST https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/importDocuments要求 JSON:
{
"batch_documents_import_configs": {
"dataset_split": DATASET_TYPE
"batch_input_config": {
"gcs_prefix": {
"gcs_uri_prefix": GCS_URI
}
}
}
}訓練和測試資料集
如要自動將文件分割為訓練和測試資料集,請按照下列步驟操作:
HTTP 方法
POST https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/importDocuments要求 JSON:
{
"batch_documents_import_configs": {
"auto_split_config": {
"training_split_ratio": TRAINING_SPLIT_RATIO
},
"batch_input_config": {
"gcs_prefix": {
"gcs_uri_prefix": "gs://test_sbindal/pdfs-1-page/"
}
}
}
}將要求主體儲存在名為 request.json 的檔案中,然後執行下列指令:
CURL
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/importDocuments"您應該會收到如下的 JSON 回覆:
{
"name": "projects/PROJECT_ID/locations/LOCATION/operations/OPERATION_ID"
}刪除文件 RPC
本範例說明如何使用 dataset.batchDeleteDocuments 方法,從資料集中刪除文件。
使用任何要求資料之前,請先替換以下項目:
LOCATION: Your processor location
PROJECT_ID: Your Google Cloud project ID
PROCESSOR_ID: The ID of your custom processor
DOCUMENT_ID: The document ID blob returned by <code>ImportDocuments</code> request
刪除文件
HTTP 方法
POST https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/batchDeleteDocuments要求 JSON:
{
"dataset_documents": {
"individual_document_ids": {
"document_ids": DOCUMENT_ID
}
}
}將要求主體儲存在名為 request.json 的檔案中,然後執行下列指令:
CURL
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/batchDeleteDocuments"您應該會收到如下的 JSON 回覆:
{
"name": "projects/PROJECT_ID/locations/LOCATION/operations/OPERATION_ID"
}將文件指派給訓練集或測試集
在「資料分割」下方選取文件,然後指派給訓練集、測試集或未指派。

測試集最佳做法
測試集的品質會決定評估結果的品質。
測試集應在處理器開發週期開始時建立並鎖定,以便追蹤處理器的品質變化。
建議每個文件類型至少要有 100 份測試集文件。請務必確保測試集能代表客戶用於開發模型的檔案類型。
就頻率而言,測試集應代表實際流量。舉例來說,如果您要處理 W2 表單,且預期 70% 的表單屬於 2020 年,30% 屬於 2019 年,則測試集應有約 70% 的 2020 年 W2 文件。這類測試集組成方式可確保評估處理器效能時,每個文件子類型都獲得適當的重要性。此外,如果您要從國際表單中擷取人名,請確保測試集包含所有指定國家/地區的表單。
訓練集的最佳做法
已納入測試集的文件不應納入訓練集。
與測試集不同,最終訓練集不需要在文件多元性或頻率方面,嚴格代表客戶使用情況。有些標籤比其他標籤更難訓練。因此,將訓練集偏向這些標籤,可能會獲得更佳成效。
一開始,您很難判斷哪些標籤較難辨識。您應先使用與測試集相同的方法,隨機取樣一小部分資料做為初始訓練集。這個初始訓練集應包含您預計註解的文件總數約 10%。接著,您可以反覆評估處理器品質 (尋找特定錯誤模式),並新增更多訓練資料。
定義處理器結構定義
建立資料集後,您可以在匯入文件之前或之後定義處理器結構定義。
處理器的schema會定義要從文件中擷取的標籤,例如姓名和地址。
選取「編輯結構定義」,然後視需要建立、編輯、啟用及停用標籤。
完成後,請務必選取「儲存」。
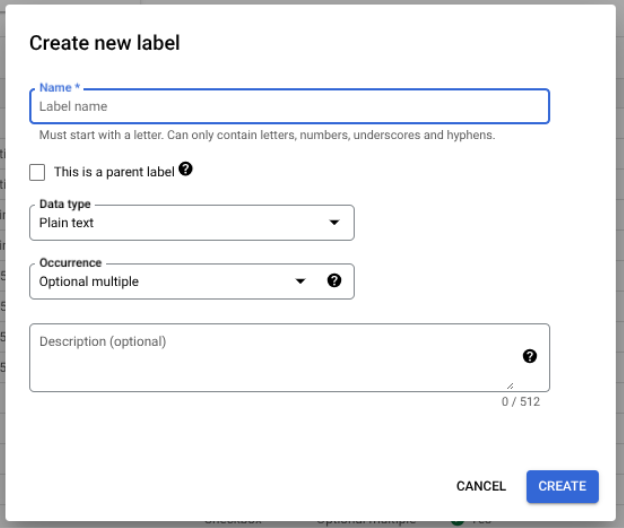
結構定義標籤管理注意事項:
結構定義標籤建立後,就無法編輯名稱。
如果沒有已訓練的處理器版本,您才能編輯或刪除結構定義標籤。只能編輯資料類型和發生類型。
停用標籤也不會影響預測。傳送處理要求時,處理器版本會擷取訓練時的所有有效標籤。
取得資料結構定義
本範例說明如何使用資料集。getDatasetSchema 可取得目前的結構定義。DatasetSchema 是單例資源,建立資料集資源時會自動建立。
使用任何要求資料之前,請先替換以下項目:
LOCATION: Your processor location
PROJECT_ID: Your Google Cloud project ID
PROCESSOR_ID: The ID of your custom processor
取得資料結構定義
HTTP 方法
GET https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/datasetSchemaCURL
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/datasetSchema"您應該會收到如下的 JSON 回覆:
{
"name": "projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/datasetSchema",
"documentSchema": {
"entityTypes": [
{
"name": $SCHEMA_NAME,
"baseTypes": [
"document"
],
"properties": [
{
"name": $LABEL_NAME,
"valueType": $VALUE_TYPE,
"occurrenceType": $OCCURRENCE_TYPE,
"propertyMetadata": {}
},
],
"entityTypeMetadata": {}
}
]
}
}更新文件結構定義
這個範例說明如何使用 dataset.updateDatasetSchema 更新目前的結構定義。這個範例顯示的指令可更新資料集結構定義,使其包含一個標籤。如要新增標籤,而非刪除或更新現有標籤,可以先呼叫 getDatasetSchema,然後在回應中進行適當變更。
使用任何要求資料之前,請先替換以下項目:
LOCATION: Your processor location
PROJECT_ID: Your Google Cloud project ID
PROCESSOR_ID: The ID of your custom processor
LABEL_NAME: The label name which you want to add
LABEL_DESCRIPTION: Describe what the label represents
DATA_TYPE: The type of the label. You can specify this as string, number, currency, money, datetime, address, boolean.
OCCURRENCE_TYPE: Describes the number of times this label is expected. Pick an enum value.
更新結構定義
HTTP 方法
PATCH https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/datasetSchema要求 JSON:
{
"document_schema": {
"entityTypes": [
{
"name": $SCHEMA_NAME,
"baseTypes": [
"document"
],
"properties": [
{
"name": LABEL_NAME,
"description": LABEL_DESCRIPTION,
"valueType": DATA_TYPE,
"occurrenceType": OCCURRENCE_TYPE,
"propertyMetadata": {}
},
],
"entityTypeMetadata": {}
}
]
}
}將要求主體儲存在名為 request.json 的檔案中,然後執行下列指令:
CURL
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/datasetSchema"選擇標籤屬性
資料類型
Plain text:字串值。Number:數字,可以是整數或浮點數。Money:金額價值。標示時請勿加上貨幣符號。- 實體擷取完畢後,會標準化為
google.type.Money。
- 實體擷取完畢後,會標準化為
Currency:貨幣符號。Datetime:日期或時間值。- 擷取實體後,系統會將其正規化為
ISO 8601文字格式。
- 擷取實體後,系統會將其正規化為
Address- 實體據點地址。- 系統擷取實體後,會使用 EKG 正規化及擴充實體。
Checkbox-true或false布林值。Signature-normalized_value.signature_value中的true或false布林值,指出是否有簽章。支援derive方法。mention_text-has_signed中的Detected或空白""布林值,指出是否有簽章。支援derive方法。normalized_value.text-has_signed中的Detected或空白""布林值,指出是否有簽章。支援derive方法。normalized_value.boolean_value不會填入。
方法
- 如果實體是
extracted,則會填入textAnchor、type、mentionText和pageAnchor欄位。 - 如果實體是
derived,衍生值可能不會出現在文件文字中。未填入textAnchor和pageAnchor.pageRefs[].bounding_poly欄位。
出現次數
如果實體一律會出現在特定類型的文件中,請選擇 REQUIRED。如果沒有這類期望,請選擇 OPTIONAL。
如果實體預期會有一個值,即使相同的值在同一份文件中出現多次,也請選擇 ONCE。如果實體預期會有多個值,請選擇 MULTIPLE。
父項和子項標籤
父項/子項標籤 (又稱表格實體) 用於標記表格中的資料。下表包含 3 個資料列和 4 個資料欄。

您可以使用父項/子項標籤定義這類資料表。在本範例中,父項標籤 line-item 會定義資料表中的資料列。
建立父項標籤
在「Edit schema」(編輯結構定義) 頁面中,選取「Create Label」(建立標籤)。
選取「這是母公司」核取方塊,然後輸入其他資訊。 父項標籤必須包含
optional_multiple或require_multiple,才能重複使用,擷取表格中的所有資料列。選取「儲存」。
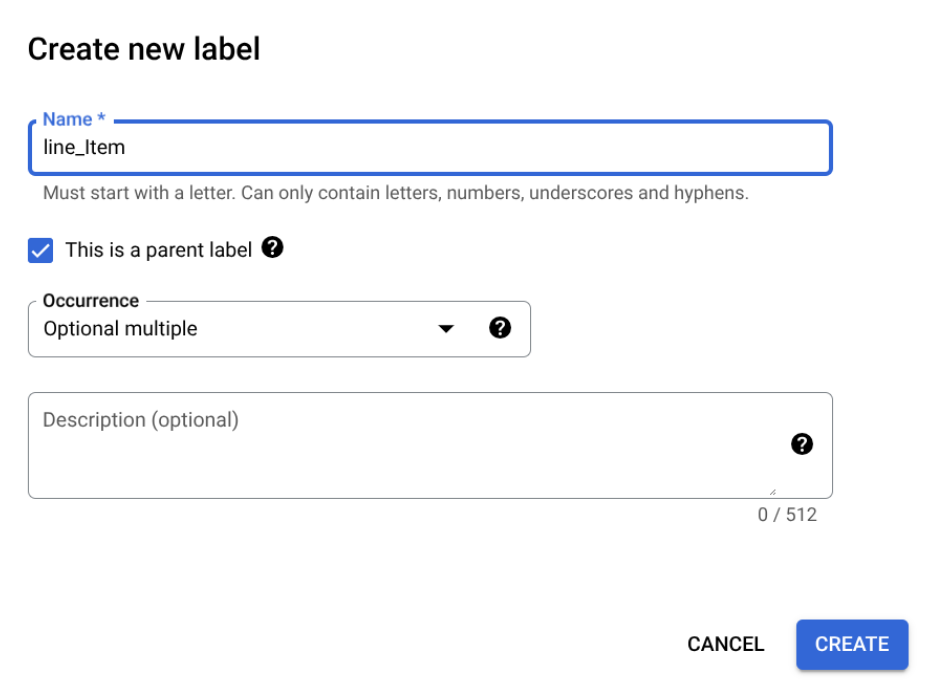
父項標籤會顯示在「編輯結構定義」頁面,旁邊有「新增子項標籤」選項。
如何建立子標籤
在「編輯結構定義」頁面,選取父項標籤旁的「新增子項標籤」。
輸入子標籤的資訊。
選取「儲存」。
針對要新增的每個子標籤重複上述步驟。
在「編輯結構定義」頁面中,子標籤會縮排顯示在父項標籤下方。

父項和子項標籤是預先發布版功能,僅支援表格。巢狀結構深度限制為 1,也就是說,子實體不得包含其他子實體。
從已加上標籤的文件建立結構定義標籤
匯入預先加上標籤的 Document JSON 檔案,自動建立結構定義標籤。
Document 匯入作業進行期間,系統會將新加入的結構定義標籤新增至結構定義編輯器。選取「編輯結構定義」,即可驗證或變更新結構定義標籤的資料類型和出現次數類型。確認後,選取結構化資料標籤,然後選取「啟用」。
範例資料集
為協助您開始使用 Document AI Workbench,我們在公開的 Cloud Storage bucket 中提供資料集,內含多種文件類型的預先標記和未標記範例 Document JSON 檔案。
視文件類型而定,這些資料可用於進階訓練或自訂擷取器。
gs://cloud-samples-data/documentai/Custom/
gs://cloud-samples-data/documentai/Custom/1040/
gs://cloud-samples-data/documentai/Custom/Invoices/
gs://cloud-samples-data/documentai/Custom/Patents/
gs://cloud-samples-data/documentai/Custom/Procurement-Splitter/
gs://cloud-samples-data/documentai/Custom/W2-redacted/
gs://cloud-samples-data/documentai/Custom/W2/
gs://cloud-samples-data/documentai/Custom/W9/