
Un ensemble de données contenant des documents étiquetés est requis pour entraîner, surentraîner ou évaluer une version du processeur.
Cette page explique comment créer un ensemble de données, importer des documents et définir un schéma. Pour étiqueter les documents importés, consultez la section Étiqueter des documents.
Cette page suppose que vous avez déjà créé un processeur compatible avec l'entraînement, le surentraînement ou l'évaluation. Si votre processeur est compatible, l'onglet Entraînement s'affiche dans la Google Cloud console.
Options de stockage des ensembles de données
Vous pouvez choisir entre deux options pour enregistrer votre ensemble de données :
- Géré par Google
- Emplacement Cloud Storage personnalisé
Sauf si vous avez des exigences particulières (par exemple, conserver des documents dans un ensemble de dossiers compatibles avec CMEK), nous vous recommandons l'option de stockage gérée par Google, qui est plus simple. Une fois l'option de stockage de l'ensemble de données créée, elle ne peut plus être modifiée pour le processeur.
Le dossier ou le sous-dossier d'un emplacement Cloud Storage personnalisé doit être vide au départ et être traité comme étant en lecture seule. Toute modification manuelle de son contenu peut rendre l'ensemble de données inutilisable et entraîner sa perte. L'option de stockage gérée par Google ne présente pas ce risque.
Suivez ces étapes pour provisionner votre emplacement de stockage.
Stockage géré par Google (recommandé)
Affichez les options avancées lors de la création d'un processeur.
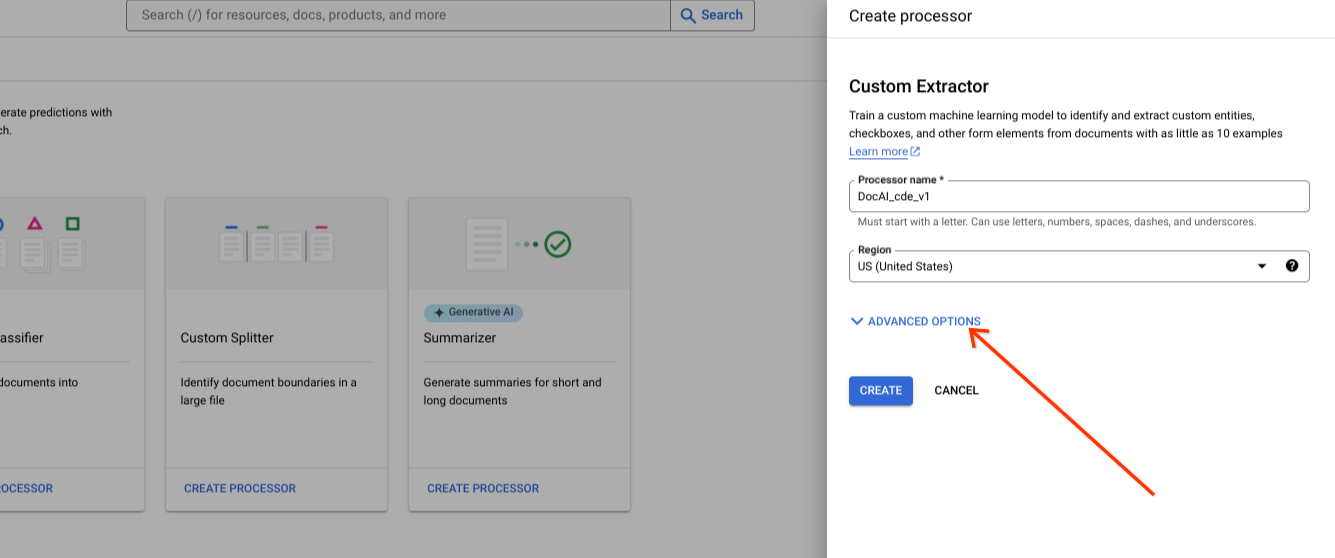
Conservez l'option de groupe de boutons radio par défaut pour le stockage géré par Google.
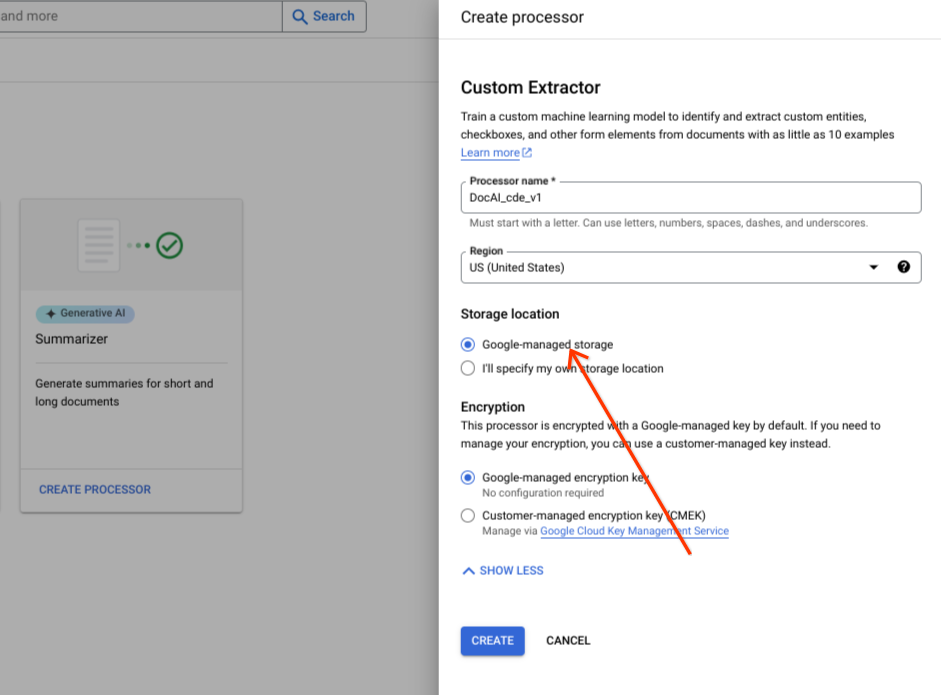
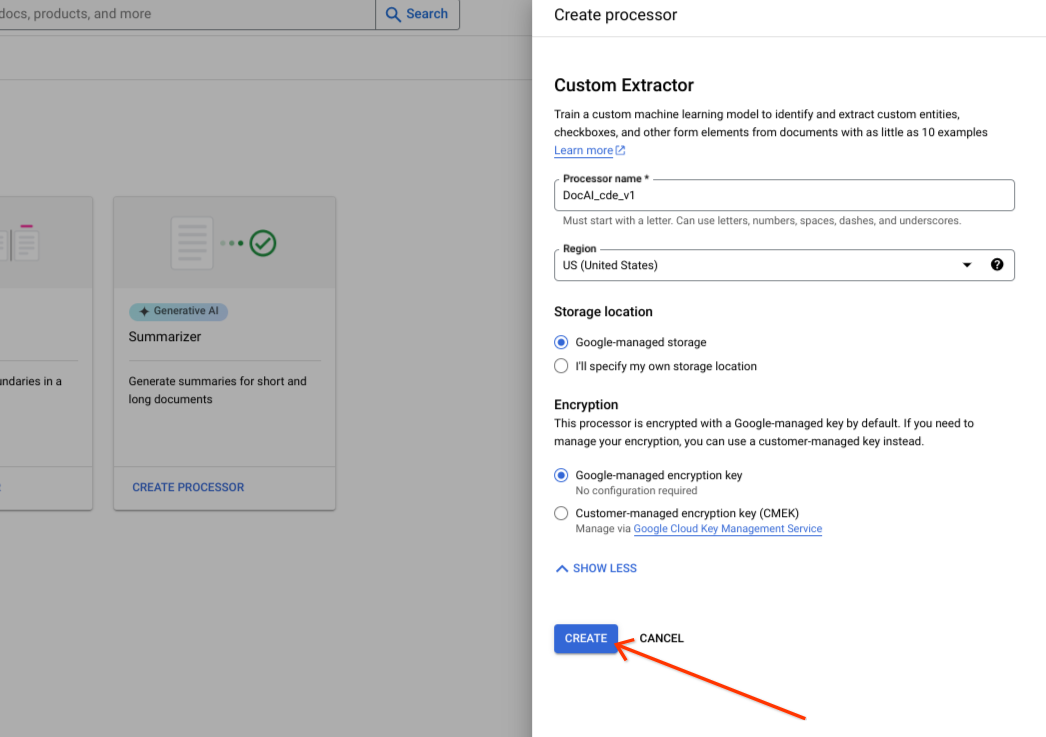
Sélectionnez Créer.
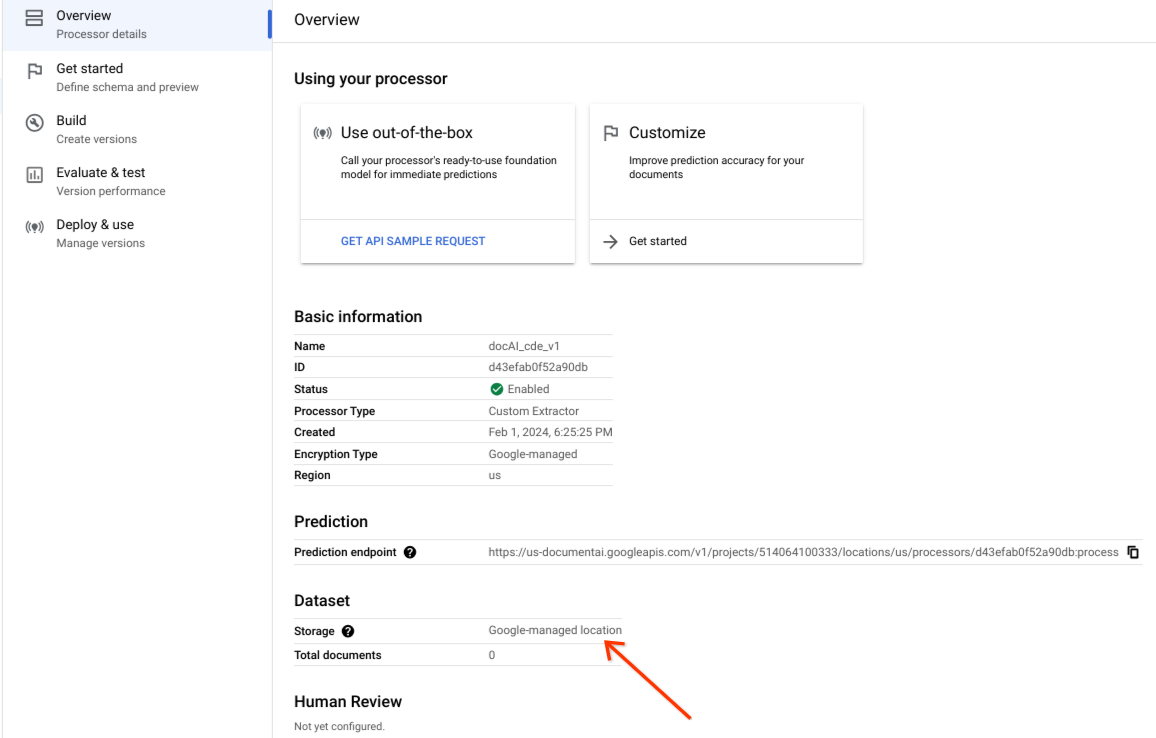
Vérifiez que l'ensemble de données a bien été créé et que son emplacement est géré par Google.
Option de stockage personnalisée
Activez ou désactivez les options avancées.
Sélectionnez Je vais spécifier mon propre emplacement de stockage.
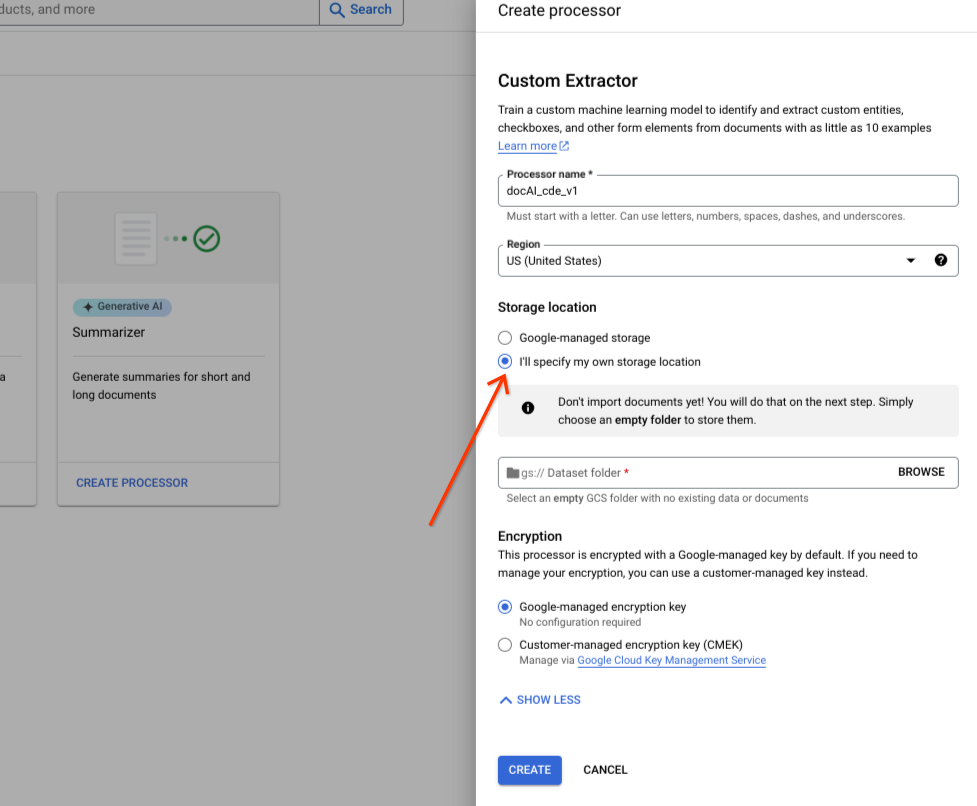
Choisissez un dossier Cloud Storage dans le composant d'entrée.
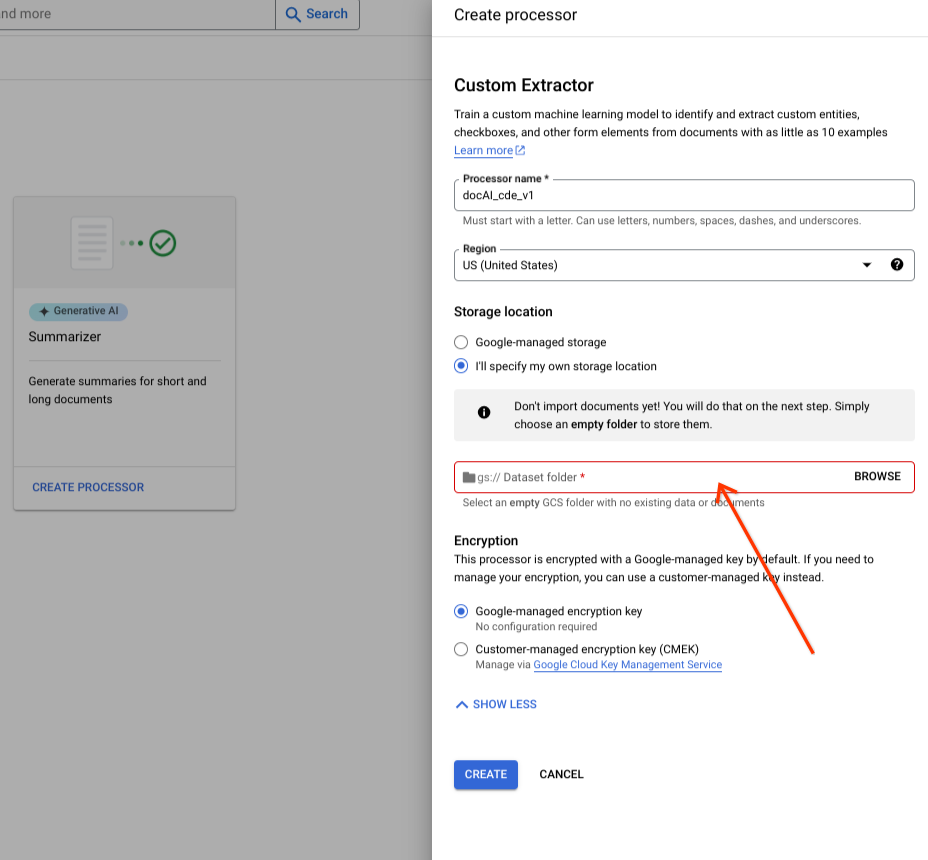
Sélectionnez Créer.

Opérations d'API d'ensemble de données
Cet exemple montre comment utiliser la méthode
processors.updateDataset
pour créer un ensemble de données. Une ressource d'ensemble de données est une ressource singleton dans un processeur, ce qui signifie qu'il n'existe pas de RPC de création de ressource. Vous pouvez utiliser le RPC updateDataset pour définir les préférences. Document AI permet de stocker les documents de l'ensemble de données dans un bucket Cloud Storage que vous fournissez ou de les faire gérer automatiquement par Google.
Avant d'utiliser les données de requête ci-dessous, effectuez les remplacements suivants :
LOCATION: Your processor location
PROJECT_ID: Your Google Cloud project ID
PROCESSOR_ID The ID of your custom processor
GCS_URI: Your Cloud Storage URI where dataset documents are stored
Bucket fourni
Suivez les étapes ci-dessous pour créer une requête d'ensemble de données avec un bucket Cloud Storage que vous fournissez.
Méthode HTTP
PATCH https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/datasetRequête JSON :
{
"name":"projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset"
"gcs_managed_config" {
"gcs_prefix" {
"gcs_uri_prefix": "GCS_URI"
}
}
"spanner_indexing_config" {}
}Géré par Google
Si vous souhaitez créer un ensemble de données géré par Google, mettez à jour les informations suivantes :
Méthode HTTP
PATCH https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/datasetRequête JSON :
{
"name":"projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset"
"unmanaged_dataset_config": {}
"spanner_indexing_config": {}
}Pour envoyer votre requête, vous pouvez utiliser Curl :
Enregistrez le corps de la requête dans un fichier nommé request.json. Exécutez la commande suivante :
CURL
curl -X PATCH \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset"Vous devriez recevoir une réponse JSON de ce type :
{
"name": "projects/PROJECT_ID/locations/LOCATION/operations/OPERATION_ID"
}Importer des documents
Un ensemble de données nouvellement créé est vide. Pour ajouter des documents, sélectionnez Importer des documents , puis un ou plusieurs dossiers Cloud Storage contenant les documents que vous souhaitez ajouter à votre ensemble de données.
Si votre Cloud Storage se trouve dans un autre Google Cloud projet, assurez-vous d'
accorder l'accès afin que Document AI soit autorisé à lire les fichiers à partir de cet
emplacement. Plus précisément, vous devez attribuer le
rôle Lecteur des objets de l'espace de stockage à l'agent de service principal de
Document AI
service-{project-id}@gcp-sa-prod-dai-core.iam.gserviceaccount.com. Pour plus d'
informations, consultez la section
Agents de service.

Sélectionnez ensuite l'une des options d'attribution suivantes :
- Entraînement : attribuer à l'ensemble d'entraînement.
- Test : attribuer à l'ensemble de test.
- Répartition automatique : répartit les documents de manière aléatoire entre les ensembles d'entraînement et de test.
- Non attribué : n'est pas utilisé pour l'entraînement ni l'évaluation. Vous pouvez attribuer manuellement plus tard.
Vous pouvez toujours modifier les attributions ultérieurement.
Lorsque vous sélectionnez Importer, Document AI importe tous les
types de fichiers compatibles, ainsi que les fichiers JSON
Document, dans l'
ensemble de données. Pour les fichiers JSON Document, Document AI importe le document et convertit ses entities
en instances d'étiquettes.
Document AI ne modifie pas le dossier d'importation et ne lit pas ses données une fois l'importation terminée.
Sélectionnez Activité en haut de la page pour ouvrir le panneau Activité, qui liste les fichiers qui ont été importés et ceux qui n'ont pas pu l'être.
Si vous disposez déjà d'une version de votre processeur, vous pouvez cocher la case Importer avec l'étiquetage automatique dans la boîte de dialogue Importer des documents. Les documents sont étiquetés automatiquement à l'aide du processeur précédent lors de leur importation. Vous ne pouvez pas entraîner ni surentraîner des documents étiquetés automatiquement, ni les utiliser dans l'ensemble de test, sans les marquer comme étiquetés. Après avoir importé des documents étiquetés automatiquement, examinez-les et corrigez-les manuellement. Sélectionnez ensuite Enregistrer pour enregistrer les corrections et marquer le document comme étiqueté. Vous pouvez ensuite attribuer les documents de manière appropriée. Consultez la section Étiquetage automatique.
RPC d'importation de documents
Cet exemple montre comment utiliser la méthode dataset.importDocuments pour importer des documents dans l'ensemble de données.
Avant d'utiliser les données de requête ci-dessous, effectuez les remplacements suivants :
LOCATION: Your processor location
PROJECT_ID: Your Google Cloud project ID
PROCESSOR_ID: The ID of your custom processor
GCS_URI: Your Cloud Storage URI where dataset documents are stored
DATASET_TYPE: The dataset type to which you want to add documents. The value should be either `DATASET_SPLIT_TRAIN` or `DATASET_SPLIT_TEST`.
TRAINING_SPLIT_RATIO: The ratio of documents which you want to autoassign to the training set.
Ensemble de données d'entraînement ou de test
Si vous souhaitez ajouter des documents à un ensemble de données d'entraînement ou de test :
Méthode HTTP
POST https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/importDocumentsRequête JSON :
{
"batch_documents_import_configs": {
"dataset_split": DATASET_TYPE
"batch_input_config": {
"gcs_prefix": {
"gcs_uri_prefix": GCS_URI
}
}
}
}Ensemble de données d'entraînement et de test
Si vous souhaitez répartir automatiquement les documents entre les ensembles de données d'entraînement et de test :
Méthode HTTP
POST https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/importDocumentsRequête JSON :
{
"batch_documents_import_configs": {
"auto_split_config": {
"training_split_ratio": TRAINING_SPLIT_RATIO
},
"batch_input_config": {
"gcs_prefix": {
"gcs_uri_prefix": "gs://test_sbindal/pdfs-1-page/"
}
}
}
}Enregistrez le corps de la requête dans un fichier nommé request.json, puis exécutez la commande suivante :
CURL
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/importDocuments"Vous devriez recevoir une réponse JSON de ce type :
{
"name": "projects/PROJECT_ID/locations/LOCATION/operations/OPERATION_ID"
}RPC de suppression de documents
Cet exemple montre comment utiliser la méthode dataset.batchDeleteDocuments pour supprimer des documents de l'ensemble de données.
Avant d'utiliser les données de requête ci-dessous, effectuez les remplacements suivants :
LOCATION: Your processor location
PROJECT_ID: Your Google Cloud project ID
PROCESSOR_ID: The ID of your custom processor
DOCUMENT_ID: The document ID blob returned by <code>ImportDocuments</code> request
Supprimer les documents
Méthode HTTP
POST https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/batchDeleteDocumentsRequête JSON :
{
"dataset_documents": {
"individual_document_ids": {
"document_ids": DOCUMENT_ID
}
}
}Enregistrez le corps de la requête dans un fichier nommé request.json, puis exécutez la commande suivante :
CURL
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/batchDeleteDocuments"Vous devriez recevoir une réponse JSON de ce type :
{
"name": "projects/PROJECT_ID/locations/LOCATION/operations/OPERATION_ID"
}Attribuer des documents à un ensemble d'entraînement ou de test
Sous Répartition des données, sélectionnez des documents et attribuez-les à l'ensemble d'entraînement, à l'ensemble de test ou à l'ensemble non attribué.
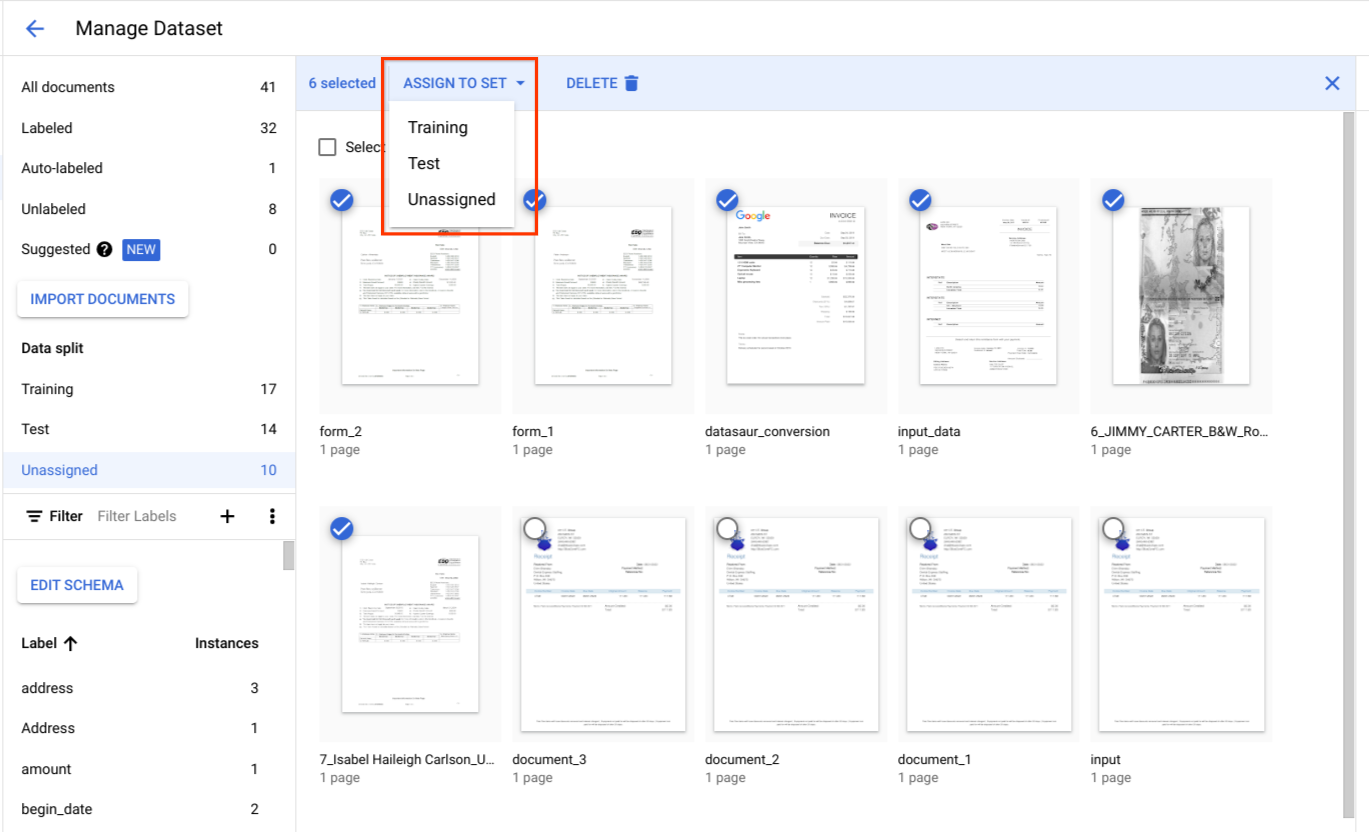
Bonnes pratiques pour l'ensemble de test
La qualité de votre ensemble de test détermine la qualité de votre évaluation.
L'ensemble de test doit être créé au début du cycle de développement du processeur et verrouillé afin que vous puissiez suivre la qualité du processeur au fil du temps.
Nous recommandons au moins 100 documents par type de document pour l'ensemble de test. Il est essentiel de s'assurer que l'ensemble de test est représentatif des types de documents que les clients utilisent pour le modèle en cours de développement.
L'ensemble de test doit être représentatif du trafic de production en termes de fréquence. Par exemple, si vous traitez des formulaires W2 et que vous prévoyez que 70% d'entre eux concernent l'année 2020 et 30% l'année 2019, environ 70% de l'ensemble de test doivent être constitués de documents W2 2020. Une telle composition de l'ensemble de test garantit qu'une importance appropriée est accordée à chaque sous-type de document lors de l'évaluation des performances du processeur. De plus, si vous extrayez des noms de personnes à partir de formulaires internationaux, assurez-vous que votre ensemble de test inclut des formulaires de tous les pays ciblés.
Bonnes pratiques pour l'ensemble d'entraînement
Les documents qui ont déjà été inclus dans l'ensemble de test ne doivent pas être inclus dans l'ensemble d'entraînement.
Contrairement à l'ensemble de test, l'ensemble d'entraînement final n'a pas besoin d'être aussi strictement représentatif de l'utilisation par le client en termes de diversité ou de fréquence des documents. Certaines étiquettes sont plus difficiles à entraîner que d'autres. Vous pouvez donc obtenir de meilleures performances en biaisant l'ensemble d'entraînement vers ces étiquettes.
Au début, il n'existe pas de moyen efficace de déterminer quelles étiquettes sont difficiles. Vous devez commencer par un petit ensemble d'entraînement initial échantillonné de manière aléatoire en utilisant la même approche que celle décrite pour l'ensemble de test. Cet ensemble d'entraînement initial doit contenir environ 10% du nombre total de documents que vous prévoyez d'annoter. Vous pouvez ensuite évaluer de manière itérative la qualité du processeur (en recherchant des modèles d'erreur spécifiques) et ajouter des données d'entraînement.
Définir le schéma de l'outil de traitement
Une fois que vous avez créé un ensemble de données, vous pouvez définir un schéma de processeur avant ou après l'importation de documents.
Le schema du processeur définit les étiquettes, telles que le nom et l'adresse, à extraire de vos documents.
Sélectionnez Modifier le schéma, puis créez, modifiez, activez et désactivez les étiquettes selon vos besoins.
Veillez à sélectionner Enregistrer lorsque vous avez terminé.

Remarques sur la gestion des étiquettes de schéma :
Une fois qu'une étiquette de schéma est créée, son nom ne peut plus être modifié.
Une étiquette de schéma ne peut être modifiée ou supprimée que s'il n'existe aucune version entraînée du processeur. Seuls le type de données et le type d'occurrence peuvent être modifiés.
La désactivation d'une étiquette n'affecte pas non plus la prédiction. Lorsque vous envoyez une requête de traitement, la version du processeur extrait toutes les étiquettes qui étaient actives au moment de l'entraînement.
Obtenir le schéma de données
Cet exemple montre comment utiliser dataset.
getDatasetSchema
pour obtenir le schéma actuel. DatasetSchema est une ressource singleton, qui est créée automatiquement lorsque vous créez une ressource d'ensemble de données.
Avant d'utiliser les données de requête ci-dessous, effectuez les remplacements suivants :
LOCATION: Your processor location
PROJECT_ID: Your Google Cloud project ID
PROCESSOR_ID: The ID of your custom processor
Obtenir le schéma de données
Méthode HTTP
GET https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/datasetSchemaCURL
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/datasetSchema"Vous devriez recevoir une réponse JSON de ce type :
{
"name": "projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/datasetSchema",
"documentSchema": {
"entityTypes": [
{
"name": $SCHEMA_NAME,
"baseTypes": [
"document"
],
"properties": [
{
"name": $LABEL_NAME,
"valueType": $VALUE_TYPE,
"occurrenceType": $OCCURRENCE_TYPE,
"propertyMetadata": {}
},
],
"entityTypeMetadata": {}
}
]
}
}Mettre à jour le schéma de document
Cet exemple montre comment utiliser les
dataset.updateDatasetSchema
pour mettre à jour le schéma actuel. Cet exemple montre une commande permettant de mettre à jour le schéma de l'ensemble de données afin qu'il ne comporte qu'une seule étiquette. Si vous souhaitez ajouter une étiquette, sans supprimer ni mettre à jour les étiquettes existantes, vous pouvez d'abord appeler getDatasetSchema et apporter les modifications appropriées dans sa réponse.
Avant d'utiliser les données de requête ci-dessous, effectuez les remplacements suivants :
LOCATION: Your processor location
PROJECT_ID: Your Google Cloud project ID
PROCESSOR_ID: The ID of your custom processor
LABEL_NAME: The label name which you want to add
LABEL_DESCRIPTION: Describe what the label represents
DATA_TYPE: The type of the label. You can specify this as string, number, currency, money, datetime, address, boolean.
OCCURRENCE_TYPE: Describes the number of times this label is expected. Pick an enum value.
Mettre à jour le schéma
Méthode HTTP
PATCH https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/datasetSchemaRequête JSON :
{
"document_schema": {
"entityTypes": [
{
"name": $SCHEMA_NAME,
"baseTypes": [
"document"
],
"properties": [
{
"name": LABEL_NAME,
"description": LABEL_DESCRIPTION,
"valueType": DATA_TYPE,
"occurrenceType": OCCURRENCE_TYPE,
"propertyMetadata": {}
},
],
"entityTypeMetadata": {}
}
]
}
}Enregistrez le corps de la requête dans un fichier nommé request.json, puis exécutez la commande suivante :
CURL
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/datasetSchema"Choisir les attributs d'étiquette
Type de données
Plain text: valeur de chaîne.Number: nombre entier ou à virgule flottante.Money: valeur monétaire. Lors de l'étiquetage, n'incluez pas le symbole de la devise.- Lorsque l'entité est extraite, elle est normalisée en
google.type.Money.
- Lorsque l'entité est extraite, elle est normalisée en
Currency: symbole de devise.Datetime: valeur de date ou d'heure.- Lorsque l'entité est extraite, elle est
normalisée au
ISO 8601format de texte.
- Lorsque l'entité est extraite, elle est
normalisée au
Address: adresse géographique.- Lorsque l'entité est extraite, elle est normalisée et enrichie avec EKG.
Checkbox: valeur booléennetrueoufalse.Signature: valeur booléennetrueoufalsedansnormalized_value.signature_valueindiquant si une signature est présente. Elle est compatible avec les méthodesderive.mention_text: valeur booléenneDetectedou""vide danshas_signedindiquant si une signature est présente. Elle est compatible avec les méthodesderive.normalized_value.text: valeur booléenneDetectedou""vide danshas_signedindiquant si une signature est présente. Elle est compatible avec les méthodesderive.normalized_value.boolean_valuen'est pas renseigné.
Méthode
- Lorsque l'entité est
extracted, les champstextAnchor,type,mentionText, etpageAnchorsont renseignés. - Lorsque l'entité est
derived, les valeurs dérivées peuvent ne pas être présentes dans le texte du document. Les champstextAnchoretpageAnchor.pageRefs[].bounding_polyne sont pas renseignés.
Occurrence
Choisissez REQUIRED si une entité est censée toujours apparaître dans les documents d'un type donné. Choisissez OPTIONAL si ce n'est pas le cas.
Choisissez ONCE si une entité est censée avoir une seule valeur, même si la même
valeur apparaît plusieurs fois dans le même document. Choisissez MULTIPLE si une entité est censée avoir plusieurs valeurs.
Étiquettes parentes et enfants
Les étiquettes parent-enfant (également appelées entités tabulaires) sont utilisées pour étiqueter des données dans un tableau. Le tableau suivant contient trois lignes et quatre colonnes.

Vous pouvez définir ces tableaux à l'aide d'étiquettes parent-enfant. Dans cet exemple, l'étiquette parente line-item définit une ligne du tableau.
Créer une étiquette parente
Sur la page Modifier le schéma, sélectionnez Créer une étiquette.
Cochez la case Il s'agit d'une étiquette parente, puis saisissez les autres informations. L'étiquette parente doit avoir une occurrence
optional_multipleourequire_multipleafin de pouvoir être répétée pour capturer toutes les lignes du tableau.Sélectionnez Enregistrer.
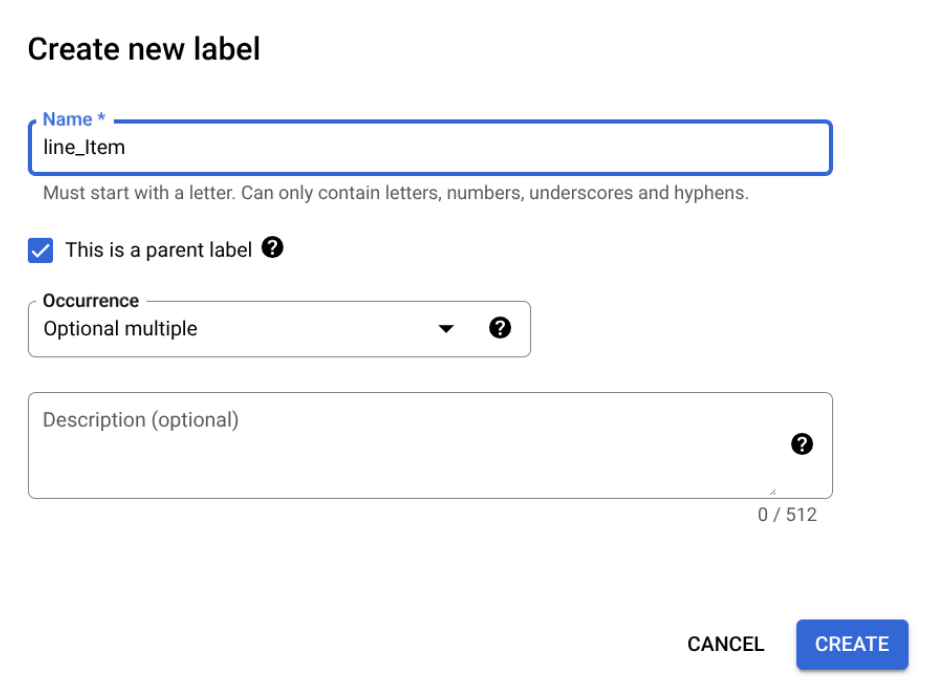
L'étiquette parente s'affiche sur la page Modifier le schéma, avec une option Ajouter une étiquette enfant à côté.
Pour créer une étiquette enfant
À côté de l'étiquette parente sur la page Modifier le schéma, sélectionnez Ajouter une étiquette enfant.
Saisissez les informations de l'étiquette enfant.
Sélectionnez Enregistrer.
Répétez l'opération pour chaque étiquette enfant que vous souhaitez ajouter.
Les étiquettes enfants apparaissent en retrait sous l'étiquette parente sur la page Modifier le schéma.

Les étiquettes parent-enfant sont une fonctionnalité en version bêta et ne sont compatibles qu'avec les tableaux. La profondeur d'imbrication est limitée à 1, ce qui signifie que les entités enfants ne peuvent pas contenir d'autres entités enfants.
Créer des étiquettes de schéma à partir de documents étiquetés
Créez automatiquement des étiquettes de schéma en important des fichiers JSON Document pré-étiquetés.
Pendant l'importation de Document, les étiquettes de schéma nouvellement ajoutées
sont ajoutées à l'éditeur de schéma. Sélectionnez "Modifier le schéma" pour vérifier ou modifier le type de données et le type d'occurrence des nouvelles étiquettes de schéma. Une fois confirmé, sélectionnez les étiquettes de schéma, puis Activer.
Exemples d'ensembles de données
Pour vous aider à commencer à utiliser Document AI Workbench, des ensembles de données sont fournis dans un
bucket Cloud Storage public. Ils incluent des exemples de fichiers JSON
Document étiquetés et non étiquetés de plusieurs types de documents.
Ils peuvent être utilisés pour le surentraînement ou les extracteurs personnalisés, selon le type de document.
gs://cloud-samples-data/documentai/Custom/
gs://cloud-samples-data/documentai/Custom/1040/
gs://cloud-samples-data/documentai/Custom/Invoices/
gs://cloud-samples-data/documentai/Custom/Patents/
gs://cloud-samples-data/documentai/Custom/Procurement-Splitter/
gs://cloud-samples-data/documentai/Custom/W2-redacted/
gs://cloud-samples-data/documentai/Custom/W2/
gs://cloud-samples-data/documentai/Custom/W9/