
O BigQuery integra-se com a Document AI para ajudar a criar estatísticas de documentos e exemplos de utilização da IA generativa. À medida que a transformação digital se acelera, as organizações estão a gerar grandes quantidades de texto e outros dados de documentos, que têm um enorme potencial para estatísticas e para impulsionar novos exemplos de utilização da IA generativa. Para ajudar a tirar partido destes dados, temos o prazer de anunciar uma integração entre o BigQuery e a IA Documental, que lhe permite extrair estatísticas de dados de documentos e criar novas aplicações de grandes modelos de linguagem (GMLs).
Vista geral
Os clientes do BigQuery podem agora criar extratores personalizados da Document AI, com tecnologia dos modelos de base de vanguarda da Google, que podem personalizar com base nos seus próprios documentos e metadados. Estes modelos personalizados podem, em seguida, ser invocados a partir do BigQuery para extrair dados estruturados de documentos de forma segura e regida, usando a simplicidade e o poder do SQL. Antes desta integração, alguns clientes tentaram criar pipelines de IA de documentos independentes, o que envolvia a organização manual da lógica de extração e do esquema. A falta de capacidades de integração incorporadas levou-os a desenvolver uma infraestrutura personalizada para sincronizar e manter a consistência dos dados. Isto transformou cada projeto de análise de documentos num empreendimento substancial que exigia um investimento significativo. Agora, com esta integração, os clientes podem criar modelos remotos no BigQuery para os respetivos extratores personalizados na IA Documental e usá-los para realizar análises de documentos e IA generativa em grande escala, o que inaugura uma nova era de estatísticas e inovação orientadas por dados.
Uma experiência de dados para IA unificada e regida
Pode criar um extrator personalizado na Document AI em três passos:
- Defina os dados que precisa de extrair dos seus documentos. Isto chama-se
document schema, é armazenado com cada versão do extrator personalizado e é acessível a partir do BigQuery. - Opcionalmente, envie documentos adicionais com anotações como exemplos da extração.
- Prepare o modelo para o extrator personalizado com base nos modelos fundamentais fornecidos na IA Documentos.
Além dos extratores personalizados que requerem preparação manual, a IA Documentos também oferece extratores prontos a usar para despesas, recibos, faturas, formulários fiscais, documentos de identificação emitidos por entidades governamentais e uma infinidade de outros cenários na galeria de processadores.
Em seguida, quando tiver o extrator personalizado pronto, pode passar para o BigQuery Studio para analisar os documentos através de SQL nos quatro passos seguintes:
- Registe um modelo remoto do BigQuery para o extrator através de SQL. O modelo pode compreender o esquema do documento (criado acima), invocar o extrator personalizado e analisar os resultados.
- Crie tabelas de objetos com SQL para os documentos armazenados no Cloud Storage. Pode governar os dados não estruturados nas tabelas definindo políticas de acesso ao nível da linha, o que limita o acesso dos utilizadores a determinados documentos e, por conseguinte, restringe o poder da IA para fins de privacidade e segurança.
- Use a função
ML.PROCESS_DOCUMENTna tabela de objetos para extrair campos relevantes fazendo chamadas de inferência para o ponto final da API. Também pode filtrar os documentos para as extrações com uma cláusulaWHEREfora da função. A função devolve uma tabela estruturada, em que cada coluna é um campo extraído. - Junte os dados extraídos a outras tabelas do BigQuery para combinar dados estruturados e não estruturados, gerando valores empresariais.
O exemplo seguinte ilustra a experiência do utilizador:
# Create an object table in BigQuery that maps to the document files stored in Cloud Storage.
CREATE OR REPLACE EXTERNAL TABLE `my_dataset.document`
WITH CONNECTION `my_project.us.example_connection`
OPTIONS (
object_metadata = 'SIMPLE',
uris = ['gs://my_bucket/path/*'],
metadata_cache_mode= 'AUTOMATIC',
max_staleness= INTERVAL 1 HOUR
);
# Create a remote model to register your Doc AI processor in BigQuery.
CREATE OR REPLACE MODEL `my_dataset.layout_parser`
REMOTE WITH CONNECTION `my_project.us.example_connection`
OPTIONS (
remote_service_type = 'CLOUD_AI_DOCUMENT_V1',
document_processor='PROCESSOR_ID'
);
# Invoke the registered model over the object table to parse PDF document
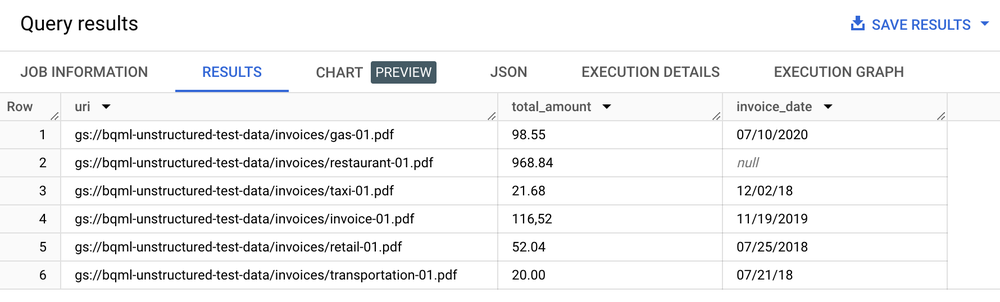
SELECT uri, total_amount, invoice_date
FROM ML.PROCESS_DOCUMENT(
MODEL `my_dataset.layout_parser`,
TABLE `my_dataset.document`,
PROCESS_OPTIONS => (
JSON '{"layout_config": {"chunking_config": {"chunk_size": 250}}}')
)
WHERE content_type = 'application/pdf';
Tabela de resultados
Análise de texto, resumo e outros exemplos de utilização de análise de documentos
Depois de extrair texto dos seus documentos, pode realizar a análise de documentos de algumas formas:
- Use o BigQuery ML para realizar análises de texto: o BigQuery ML suporta a preparação e a implementação de modelos de incorporação de várias formas. Por exemplo, pode usar o BigQuery ML para identificar a opinião dos clientes em chamadas de apoio técnico ou para classificar o feedback sobre produtos em diferentes categorias. Se for utilizador do Python, também pode usar os DataFrames do BigQuery para o pandas e APIs semelhantes ao scikit-learn para análise de texto nos seus dados.
- Use o
text-embedding-004LLM para gerar incorporações a partir dos documentos divididos em partes: O BigQuery tem uma funçãoML.GENERATE_EMBEDDINGque chama o modelotext-embedding-004para gerar incorporações. Por exemplo, pode usar uma IA Documental para extrair feedback dos clientes e resumir o feedback com o PaLM 2, tudo com o SQL do BigQuery. - Junte metadados de documentos com outros dados estruturados armazenados em tabelas do BigQuery:
Por exemplo, pode gerar incorporações com os documentos divididos em partes e usá-las para a pesquisa vetorial.
# Example 1: Parse the chunked data
CREATE OR REPLACE TABLE docai_demo.demo_result_parsed AS (SELECT
uri,
JSON_EXTRACT_SCALAR(json , '$.chunkId') AS id,
JSON_EXTRACT_SCALAR(json , '$.content') AS content,
JSON_EXTRACT_SCALAR(json , '$.pageFooters[0].text') AS page_footers_text,
JSON_EXTRACT_SCALAR(json , '$.pageSpan.pageStart') AS page_span_start,
JSON_EXTRACT_SCALAR(json , '$.pageSpan.pageEnd') AS page_span_end
FROM docai_demo.demo_result, UNNEST(JSON_EXTRACT_ARRAY(ml_process_document_result.chunkedDocument.chunks, '$')) json)
# Example 2: Generate embedding
CREATE OR REPLACE TABLE `docai_demo.embeddings` AS
SELECT * FROM ML.GENERATE_EMBEDDING(
MODEL `docai_demo.embedding_model`,
TABLE `docai_demo.demo_result_parsed`
);
Implemente exemplos de utilização da pesquisa e da IA generativa
Depois de extrair texto estruturado dos seus documentos, pode criar índices otimizados para consultas de agulha no palheiro, possibilitados pelas capacidades de pesquisa e indexação do BigQuery, desbloqueando uma poderosa capacidade de pesquisa. Esta integração também ajuda a desbloquear novas aplicações de LLM generativas, como a execução do processamento de ficheiros de texto para filtragem de privacidade, verificações de segurança do conteúdo e divisão em partes de tokens, usando SQL e modelos de IA Documentos personalizados. O texto extraído, combinado com outros metadados, simplifica a organização do conjunto de dados de preparação necessário para otimizar os grandes modelos de linguagem. Além disso, está a criar exemplos de utilização de MDIs em dados empresariais regidos que foram fundamentados através das capacidades de gestão de índices vetoriais e de geração de incorporações do BigQuery. Ao sincronizar este índice com a Vertex AI, pode implementar exemplos de utilização da geração aumentada de obtenção para uma experiência de IA mais regida e simplificada.
Aplicação de exemplo
Para ver um exemplo de uma aplicação ponto a ponto que usa o conetor da IA Documental:
- Consulte esta demonstração do relatório de despesas no GitHub.
- Leia a publicação no blogue associada.
- Veja um vídeo de análise detalhada do Google Cloud Next 2021.