
Muchas organizaciones implementan almacenes de datos en la nube para almacenar información sensible y, de esta forma, poder analizar los datos con diversos fines empresariales. En este documento se describe cómo puedes implementar el marco de controles clave de las funciones de gestión de datos en la nube (CDMC), gestionado por el Enterprise Data Management Council, en un almacén de datos de BigQuery.
El marco de controles clave de CDMC se publicó principalmente para proveedores de servicios en la nube y proveedores de tecnología. El framework describe 14 controles clave que los proveedores pueden implementar para que sus clientes gestionen y controlen de forma eficaz los datos sensibles en la nube. Los controles fueron redactados por el grupo de trabajo de CDMC, en el que participaron más de 300 profesionales de más de 100 empresas. Durante la redacción del marco de trabajo, el grupo de trabajo de CDMC tuvo en cuenta muchos de los requisitos legales y normativos vigentes.
Esta arquitectura de referencia de BigQuery y Data Catalog se ha evaluado y certificado según el framework de controles clave de CDMC como solución de nube certificada por CDMC. La arquitectura de referencia usa varios Google Cloud servicios y funciones, así como bibliotecas públicas, para implementar los controles de claves de CDMC y la automatización recomendada. En este documento se explica cómo puede implementar los controles clave para proteger los datos sensibles en un almacén de datos de BigQuery.
Arquitectura
La siguiente Google Cloud arquitectura de referencia se ajusta a las especificaciones de prueba de la versión 1.1.1 del marco de controles clave del CDMC. Los números del diagrama representan los controles de claves que se abordan con los servicios de Google Cloud .

La arquitectura de referencia se basa en el plan de almacén de datos seguro, que proporciona una arquitectura que te ayuda a proteger un almacén de datos de BigQuery que incluye información sensible. En el diagrama anterior, los proyectos de la parte superior (en gris) forman parte del plano técnico del almacén de datos seguro, y el proyecto de gestión de datos (en azul) incluye los servicios que se añaden para cumplir los requisitos del marco de controles clave de CDMC. Para implementar el marco de controles clave de CDMC, la arquitectura amplía el proyecto de gobierno de datos. El proyecto de gobernanza de datos proporciona controles como la clasificación, la gestión del ciclo de vida y la gestión de la calidad de los datos. El proyecto también ofrece una forma de auditar la arquitectura y generar informes sobre los resultados.
Para obtener más información sobre cómo implementar esta arquitectura de referencia, consulta la Google Cloud arquitectura de referencia de CDMC en GitHub.
Información general sobre el marco de controles clave de CDMC
En la siguiente tabla se resume el marco de controles de claves de CDMC.
| # | Control de claves de CDMC | Requisito de control de CDMC |
|---|---|---|
| 1 | Cumplimiento del control de datos | Se definen y se rigen los casos prácticos de gestión de datos en la nube. Todos los recursos de datos que contengan datos sensibles deben monitorizarse para comprobar que cumplen los controles clave del CDMC. Para ello, se deben usar métricas y notificaciones automatizadas. |
| 2 | Se establece la propiedad de los datos migrados y de los generados en la nube | El campo Propiedad de un catálogo de datos debe rellenarse para todos los datos sensibles o, de lo contrario, se debe informar de ellos a un flujo de trabajo definido. |
| 3 | La obtención y el consumo de datos se rigen y se admiten mediante la automatización | Se debe rellenar un registro de fuentes de datos autorizadas y puntos de aprovisionamiento para todos los recursos de datos que contengan datos sensibles o que deban comunicarse a un flujo de trabajo definido. |
| 4 | Se gestionan la soberanía de los datos y la transferencia transfronteriza de datos | La soberanía de los datos y la transferencia transfronteriza de datos sensibles deben registrarse, auditarse y controlarse de acuerdo con la política definida. |
| 5 | Los catálogos de datos se implementan, se usan y son interoperables | La catalogación debe automatizarse para todos los datos en el momento de la creación o la ingestión, con coherencia en todos los entornos. |
| 6 | Se definen y se usan clasificaciones de datos | La clasificación debe automatizarse para todos los datos en el momento de la creación o la ingestión, y debe estar siempre activada. La clasificación se automatiza en los siguientes casos:
|
| 7 | Las autorizaciones de datos se gestionan, se aplican y se monitorizan | Este control requiere lo siguiente:
|
| 8 | Se gestionan el acceso, el uso y los resultados éticos de los datos | El propósito del consumo de datos debe proporcionarse en todos los acuerdos de intercambio de datos que incluyan datos sensibles. El propósito debe especificar el tipo de datos que se requiere y, en el caso de las organizaciones globales, el ámbito del país o de la entidad jurídica. |
| 9 | Los datos están protegidos y los controles se demuestran | Este control requiere lo siguiente:
|
| 10 | Se ha definido y se aplica un marco de privacidad de los datos | Las evaluaciones de impacto sobre la protección de datos (EIPDs) deben activarse automáticamente para todos los datos personales según su jurisdicción. |
| 11 | Se planifica y gestiona el ciclo de vida de los datos | La conservación, el archivado y la purga de datos deben gestionarse de acuerdo con un calendario de conservación definido. |
| 12 | Se gestiona la calidad de los datos | La medición de la calidad de los datos debe estar habilitada para los datos sensibles con métricas distribuidas cuando estén disponibles. |
| 13 | Se establecen y aplican principios de gestión de costes | Se establecen y aplican principios de diseño técnico. Las métricas de costes que estén directamente asociadas al uso, el almacenamiento y el movimiento de datos deben estar disponibles en el catálogo. |
| 14 | Se entienden la procedencia y el linaje de los datos | La información sobre el linaje de datos debe estar disponible para todos los datos sensibles. Como mínimo, esta información debe incluir la fuente de la que se han ingerido los datos o en la que se han creado en un entorno de nube. |
1. Cumplimiento del control de datos
Este control requiere que pueda verificar que todos los datos sensibles se monitorizan para cumplir este marco mediante métricas.
La arquitectura usa métricas que muestran el grado de operatividad de cada uno de los controles clave. La arquitectura también incluye paneles de control que indican cuándo las métricas no cumplen los umbrales definidos.
La arquitectura incluye detectores que publican resultados y recomendaciones de corrección cuando los recursos de datos no cumplen un control clave. Estas conclusiones y recomendaciones están en formato JSON y se publican en un tema de Pub/Sub para distribuirlas a los suscriptores. Puedes integrar tu centro de asistencia interno o tus herramientas de gestión de servicios con el tema de Pub/Sub para que las incidencias se creen automáticamente en tu sistema de gestión de incidencias.
La arquitectura usa Dataflow para crear un suscriptor de ejemplo de los eventos de resultados, que se almacenan en una instancia de BigQuery que se ejecuta en el proyecto de gobernanza de datos. Con una serie de vistas proporcionadas, puedes consultar los datos con BigQuery Studio en la Google Cloud consola. También puedes crear informes con Looker Studio u otras herramientas de inteligencia empresarial compatibles con BigQuery. Entre los informes que puede consultar se incluyen los siguientes:
- Resumen de los resultados de la última ejecución
- Detalles de los resultados de la última ejecución
- Metadatos de la última ejecución
- Recursos de datos de la última ejecución incluidos
- Estadísticas del conjunto de datos de la última ejecución
En el siguiente diagrama se muestran los servicios a los que se aplica este control.

Para cumplir los requisitos de este control, la arquitectura utiliza los siguientes servicios:
- Pub/Sub publica las detecciones.
- Dataflow carga los resultados en una instancia de BigQuery.
- BigQuery almacena los datos de los resultados y proporciona vistas de resumen.
- Looker Studio ofrece paneles de control e informes.
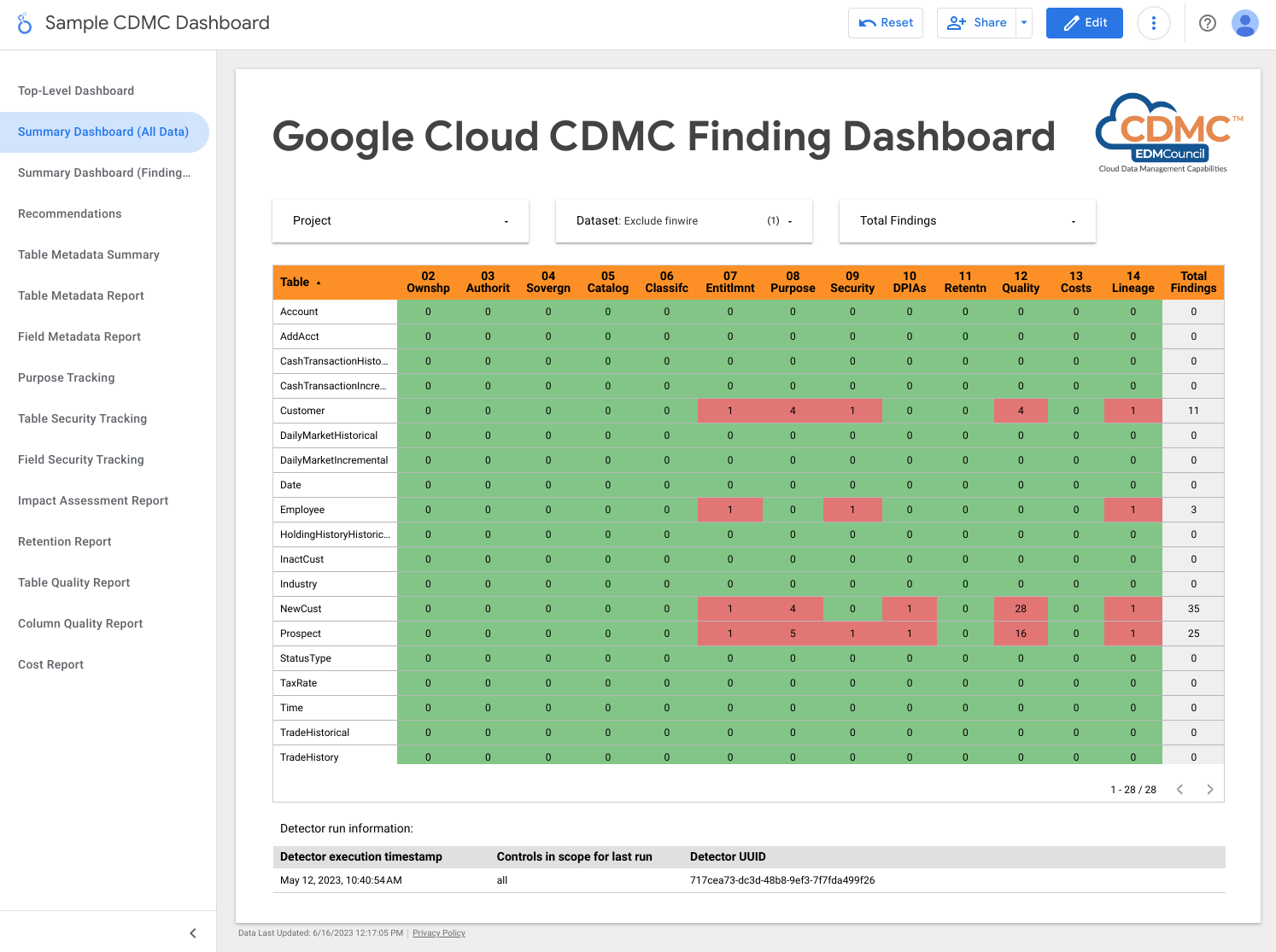
En la siguiente captura de pantalla se muestra un ejemplo de panel de control de resumen de Looker Studio.

En la siguiente captura de pantalla se muestra una vista de ejemplo de las detecciones por recurso de datos.
2. Se establece la propiedad de los datos migrados y de los generados en la nube
Para cumplir los requisitos de este control, la arquitectura revisa automáticamente los datos del almacén de datos de BigQuery y añade etiquetas de clasificación de datos que indican que se ha identificado a los propietarios de todos los datos sensibles.
Data Catalog gestiona dos tipos de metadatos: técnicos y empresariales. En un proyecto determinado, Data Catalog cataloga automáticamente los conjuntos de datos, las tablas y las vistas de BigQuery, y rellena los metadatos técnicos. La sincronización entre el catálogo y los recursos de datos se mantiene casi en tiempo real.
La arquitectura usa Tag Engine para añadir las siguientes etiquetas de metadatos empresariales a una plantilla de etiquetas CDMC controls en Data Catalog:
is_sensitive: si el recurso de datos contiene datos sensibles (consulta el control 6 para la clasificación de datos)owner_name: el propietario de los datosowner_email: la dirección de correo del propietario
Las etiquetas se rellenan con valores predeterminados que se almacenan en una tabla de BigQuery de referencia del proyecto de gobernanza de datos.
De forma predeterminada, la arquitectura define los metadatos de propiedad a nivel de tabla, pero puedes cambiarla para que los metadatos se definan a nivel de columna. Para obtener más información, consulta Etiquetas y plantillas de etiquetas de Data Catalog.
En el siguiente diagrama se muestran los servicios a los que se aplica este control.

Para cumplir los requisitos de este control, la arquitectura utiliza los siguientes servicios:
- Dos almacenes de datos de BigQuery: uno almacena los datos confidenciales y el otro, los valores predeterminados de la propiedad de los recursos de datos.
- Data Catalog almacena metadatos de propiedad mediante plantillas de etiquetas y etiquetas.
- Dos instancias de Cloud Run, como se indica a continuación:
- Una instancia ejecuta Report Engine, que comprueba si se han aplicado las etiquetas y publica los resultados.
- Otra instancia ejecuta Tag Engine, que etiqueta los datos del almacén de datos seguro.
- Pub/Sub publica las detecciones.
Para detectar problemas relacionados con este control, la arquitectura comprueba si los datos sensibles tienen asignada una etiqueta de nombre de propietario.
3. La automatización rige y admite la obtención y el consumo de datos
Este control requiere la clasificación de los recursos de datos y un registro de datos de fuentes autorizadas y distribuidores autorizados. La arquitectura usa Data Catalog para añadir la etiqueta is_authoritative a la plantilla de etiqueta CDMC
controls. Esta etiqueta define si el recurso de datos es
autoritativo.
Data Catalog cataloga conjuntos de datos, tablas y vistas de BigQuery con metadatos técnicos y empresariales. Los metadatos técnicos se rellenan automáticamente e incluyen la URL del recurso, que es la ubicación del punto de aprovisionamiento. Los metadatos empresariales se definen en el archivo de configuración de Tag Engine e incluyen la etiqueta is_authoritative.
Durante la siguiente ejecución programada, Tag Engine rellena la etiqueta is_authoritative de la plantilla de etiqueta CDMC controls con los valores predeterminados almacenados en una tabla de referencia de BigQuery.
En el siguiente diagrama se muestran los servicios a los que se aplica este control.

Para cumplir los requisitos de este control, la arquitectura utiliza los siguientes servicios:
- Dos almacenes de datos de BigQuery: uno almacena los datos confidenciales y el otro, los valores predeterminados de la fuente oficial del recurso de datos.
- Data Catalog almacena metadatos de fuentes autorizadas mediante etiquetas.
- Dos instancias de Cloud Run, como se indica a continuación:
- Una instancia ejecuta Report Engine, que comprueba si se han aplicado las etiquetas y publica los resultados.
- Otra instancia ejecuta Tag Engine, que etiqueta los datos del almacén de datos seguro.
- Pub/Sub publica las detecciones.
Para detectar problemas relacionados con este control, la arquitectura comprueba si los datos sensibles tienen asignada la etiqueta de fuente autorizada.
4. Se gestionan la soberanía de los datos y la transferencia transfronteriza de datos
Este control requiere que la arquitectura inspeccione el registro de datos para comprobar los requisitos de almacenamiento específicos de cada región y aplique las reglas de uso. Un informe describe la ubicación geográfica de los recursos de datos.
La arquitectura usa Data Catalog para añadir la etiqueta approved_storage_location a la plantilla de etiqueta CDMC controls. Esta etiqueta define la ubicación geográfica en la que se permite almacenar el recurso de datos.
La ubicación real de los datos se almacena como metadatos técnicos en los detalles de la tabla de BigQuery. BigQuery no permite que los administradores cambien la ubicación de un conjunto de datos o una tabla. En su lugar, si los administradores quieren cambiar la ubicación de los datos, deben copiar el conjunto de datos.
La restricción del servicio de políticas de la organización de ubicaciones de recursos
define las Google Cloud regiones en las que puedes almacenar datos. De forma predeterminada, la arquitectura establece la restricción en el proyecto de datos confidenciales, pero puedes definirla a nivel de organización o carpeta si lo prefieres. Tag Engine replica las ubicaciones permitidas en la plantilla de etiqueta de Data Catalog y almacena la ubicación en la etiqueta approved_storage_location. Si activas el nivel Premium de Security Command Center y alguien actualiza la restricción del servicio de políticas de la organización de las ubicaciones de los recursos, Security Command Center generará resultados de vulnerabilidades de los recursos almacenados fuera de la política actualizada.
Administrador de contextos de acceso define la ubicación geográfica en la que deben estar los usuarios para poder acceder a los recursos de datos. Con los niveles de acceso, puedes especificar las regiones desde las que se pueden enviar las solicitudes. A continuación, añade la política de acceso al perímetro de Controles de Servicio de VPC del proyecto de datos confidenciales.
Para monitorizar el movimiento de datos, BigQuery mantiene un registro de auditoría completo de cada trabajo y consulta de cada conjunto de datos. El registro de auditoría se almacena en la vista Jobs de Information Schema de BigQuery.
En el siguiente diagrama se muestran los servicios a los que se aplica este control.

Para cumplir los requisitos de este control, la arquitectura utiliza los siguientes servicios:
- El servicio de políticas de organización define y aplica la restricción de ubicaciones de recursos.
- Administrador de contextos de acceso define las ubicaciones desde las que los usuarios pueden acceder a los datos.
- Dos almacenes de datos de BigQuery: uno almacena los datos confidenciales y el otro aloja una función remota que se usa para inspeccionar la política de ubicación.
- Data Catalog almacena las ubicaciones de almacenamiento aprobadas como etiquetas.
- Dos instancias de Cloud Run, como se indica a continuación:
- Una instancia ejecuta Report Engine, que comprueba si se han aplicado las etiquetas y publica los resultados.
- Otra instancia ejecuta Tag Engine, que etiqueta los datos del almacén de datos seguro.
- Pub/Sub publica las detecciones.
- Cloud Logging escribe los registros de auditoría.
- Security Command Center informa de cualquier hallazgo relacionado con la ubicación de los recursos o el acceso a los datos.
Para detectar problemas relacionados con este control, la arquitectura incluye un resultado que indica si la etiqueta de ubicaciones aprobadas incluye la ubicación de los datos sensibles.
5. Los catálogos de datos se implementan, se usan y son interoperables
Este control requiere que exista un catálogo de datos y que la arquitectura pueda analizar los recursos nuevos y actualizados para añadir metadatos según sea necesario.
Para cumplir los requisitos de este control, la arquitectura usa Data Catalog. Data Catalog registra automáticamente losGoogle Cloud recursos, incluidos los conjuntos de datos, las tablas y las vistas de BigQuery. Cuando creas una tabla en BigQuery, Data Catalog registra automáticamente los metadatos técnicos y el esquema de la tabla. Cuando actualizas una tabla en BigQuery, Data Catalog actualiza sus entradas casi al instante.
En el siguiente diagrama se muestran los servicios a los que se aplica este control.

Para cumplir los requisitos de este control, la arquitectura utiliza los siguientes servicios:
- Dos almacenes de datos de BigQuery: uno almacena los datos confidenciales y el otro, los no confidenciales.
- Data Catalog almacena los metadatos técnicos de las tablas y los campos.
De forma predeterminada, en esta arquitectura, Data Catalog almacena metadatos técnicos de BigQuery. Si es necesario, puede integrar Data Catalog con otras fuentes de datos.
6. Se definen y se usan clasificaciones de datos
Para llevar a cabo esta evaluación, los datos deben clasificarse en función de su sensibilidad, como si se trata de información personal identificable, si identifican a los clientes o si cumplen algún otro estándar definido por tu organización. Para cumplir los requisitos de este control, la arquitectura crea un informe de los recursos de datos y su sensibilidad. Puede usar este informe para verificar si la configuración de sensibilidad es correcta. Además, cada nuevo recurso de datos o cambio en un recurso de datos ya existente provoca una actualización del catálogo de datos.
Las clasificaciones se almacenan en la etiqueta sensitive_category de la plantilla de etiqueta de Data Catalog a nivel de tabla y de columna. Una tabla de referencia de clasificación te permite clasificar los tipos de información
(infoTypes) de Protección de Datos Sensibles disponibles. Cuanto más sensible sea el contenido, mayor será la clasificación.
Para cumplir los requisitos de este control, la arquitectura usa Sensitive Data Protection, Data Catalog y Tag Engine para añadir las siguientes etiquetas a las columnas sensibles de las tablas de BigQuery:
is_sensitive: indica si el recurso de datos contiene información sensible.sensitive_category: la categoría de los datos. Puede ser una de las siguientes:- Información personal identificable sensible
- Información personal identificable
- Información personal sensible
- Información personal
- Información pública
Puedes cambiar las categorías de datos para que se ajusten a tus necesidades. Por ejemplo, puede añadir la clasificación de información no pública importante (MNPI).
Después de que Protección de Datos Sensibles inspeccione los datos, Tag Engine lee las tablas DLP results por recurso para compilar los hallazgos. Si una tabla contiene columnas con uno o varios infoTypes sensibles, se determina el infoType más destacado y tanto las columnas sensibles como la tabla completa se etiquetan con la categoría que tenga el rango más alto. Tag Engine también asigna una etiqueta de política correspondiente a la columna y asigna la etiqueta booleana is_sensitive a la tabla.
Puedes usar Cloud Scheduler para automatizar la inspección de Protección de Datos Sensibles.
En el siguiente diagrama se muestran los servicios a los que se aplica este control.

Para cumplir los requisitos de este control, la arquitectura utiliza los siguientes servicios:
- Cuatro almacenes de datos de BigQuery almacenan la siguiente información:
- Datos confidenciales
- Información sobre los resultados de Protección de Datos Sensibles
- Datos de referencia de clasificación de datos
- Información de exportación de etiquetas
- Data Catalog almacena las etiquetas de clasificación.
- Protección de Datos Sensibles inspecciona los recursos en busca de infoTypes sensibles.
- Compute Engine ejecuta la secuencia de comandos Inspect Datasets, que activa un trabajo de Protección de Datos Sensibles para cada conjunto de datos de BigQuery.
- Dos instancias de Cloud Run, como se indica a continuación:
- Una instancia ejecuta Report Engine, que comprueba si se han aplicado las etiquetas y publica los resultados.
- Otra instancia ejecuta Tag Engine, que etiqueta los datos del almacén de datos seguro.
- Pub/Sub publica las detecciones.
Para detectar problemas relacionados con este control, la arquitectura incluye los siguientes hallazgos:
- Si los datos sensibles tienen asignada una etiqueta de categoría sensible.
- Si a los datos sensibles se les ha asignado una etiqueta de tipo de sensibilidad a nivel de columna.
7. Las autorizaciones de datos se gestionan, se aplican y se monitorizan
De forma predeterminada, solo los creadores y los propietarios tienen derechos y acceso a datos sensibles. Además, este control requiere que la arquitectura registre todo el acceso a datos sensibles.
Para cumplir los requisitos de este control, la arquitectura usa la taxonomía de etiquetas de política cdmc
sensitive data classification en BigQuery para controlar el acceso a las columnas que contienen datos confidenciales en las tablas de BigQuery. La taxonomía incluye las siguientes etiquetas de política:
- Información personal identificable sensible
- Información personal identificable
- Información personal sensible
- Información personal
Las etiquetas de política te permiten controlar quién puede ver las columnas sensibles de las tablas de BigQuery. La arquitectura asigna estas etiquetas de política a clasificaciones de sensibilidad que se han derivado de los infoTypes de Protección de Datos Sensibles. Por ejemplo, la etiqueta de la sensitive_personal_identifiable_informationpolítica
AGE y la categoría sensible se asignan a infoTypes como DATE_OF_BIRTH, PHONE_NUMBER, EMAIL_ADDRESS y sensitive_personal_identifiable_information.
La arquitectura usa la gestión de identidades y accesos (IAM) para gestionar los grupos, los usuarios y las cuentas de servicio que requieren acceso a los datos. Los permisos de IAM se conceden a un recurso concreto para acceder a nivel de tabla. Además, el acceso a nivel de columna basado en etiquetas de política permite un acceso pormenorizado a los recursos de datos sensibles. De forma predeterminada, los usuarios no tienen acceso a las columnas que tienen etiquetas de política definidas.
Para asegurarte de que solo los usuarios autenticados puedan acceder a los datos,Google Cloud usa Cloud Identity, que puedes federar con tus proveedores de identidades para autenticar a los usuarios.
Este control también requiere que la arquitectura compruebe periódicamente si hay recursos de datos que no tengan derechos definidos. El detector, que gestiona Cloud Scheduler, comprueba los siguientes casos:
- Un recurso de datos incluye una categoría sensible, pero no tiene una etiqueta de política relacionada.
- Una categoría no coincide con la etiqueta de política.
Cuando se dan estas situaciones, el detector genera resultados que se publican mediante Pub/Sub y, a continuación, Dataflow los escribe en la tabla events de BigQuery. A continuación, puedes distribuir los resultados a tu herramienta de corrección, tal como se describe en el paso 1. Cumplimiento de los controles de datos.
En el siguiente diagrama se muestran los servicios a los que se aplica este control.

Para cumplir los requisitos de este control, la arquitectura utiliza los siguientes servicios:
- Un almacén de datos de BigQuery almacena los datos confidenciales y los enlaces de etiquetas de política para los controles de acceso pormenorizados.
- La gestión de identidades y accesos gestiona el acceso.
- Data Catalog almacena las etiquetas a nivel de tabla y de columna de la categoría sensible.
- Dos instancias de Cloud Run, como se indica a continuación:
- Una instancia ejecuta Report Engine, que comprueba si se han aplicado las etiquetas y publica los resultados.
- Otra instancia ejecuta Tag Engine, que etiqueta los datos del almacén de datos seguro.
Para detectar problemas relacionados con este control, la arquitectura comprueba si los datos sensibles tienen una etiqueta de política correspondiente.
8. Se gestionan el acceso, el uso y los resultados éticos de los datos
Este control requiere que la arquitectura almacene acuerdos de intercambio de datos tanto del proveedor como de los consumidores de datos, incluida una lista de finalidades de consumo aprobadas. El propósito de consumo de los datos sensibles se asigna a los derechos almacenados en BigQuery mediante etiquetas de consulta.
Cuando un consumidor consulta datos sensibles en BigQuery, debe especificar un propósito válido que coincida con su derecho (por ejemplo, SET @@query_label = “use:3”;).
La arquitectura usa Data Catalog para añadir las siguientes etiquetas a la plantilla de etiqueta CDMC controls. Estas etiquetas representan el acuerdo de intercambio de datos con el proveedor de datos:
approved_use: el uso o los usuarios aprobados del recurso de datossharing_scope_geography: la lista de ubicaciones geográficas en las que se puede compartir el recurso de datossharing_scope_legal_entity: la lista de entidades acordadas que pueden compartir el recurso de datos
Un almacén de datos de BigQuery independiente incluye el conjunto de datos entitlement_management con las siguientes tablas:
provider_agreement: el acuerdo de intercambio de datos con el proveedor de datos, incluida la entidad jurídica y el ámbito geográfico acordados. Estos datos son los valores predeterminados de las etiquetasshared_scope_geographyysharing_scope_legal_entity.consumer_agreement: el acuerdo de intercambio de datos con el consumidor de datos, incluida la entidad jurídica y el ámbito geográfico acordados. Cada acuerdo está asociado a un enlace de gestión de identidades y accesos para el recurso de datos.use_purpose: el propósito del consumo, como la descripción del uso y las operaciones permitidas para el recurso de datos.data_asset: información sobre el recurso de datos, como el nombre del recurso y detalles sobre el propietario de los datos.
Para auditar los acuerdos de uso compartido de datos, BigQuery mantiene un registro de auditoría completo de cada tarea y consulta de cada conjunto de datos. El registro de auditoría se almacena en la vista Information Schema Jobs de BigQuery. Después de asociar una etiqueta de consulta a una sesión y ejecutar consultas en ella, puedes recoger registros de auditoría de las consultas con esa etiqueta. Para obtener más información, consulta la referencia de los registros de auditoría de BigQuery.
En el siguiente diagrama se muestran los servicios a los que se aplica este control.

Para cumplir los requisitos de este control, la arquitectura utiliza los siguientes servicios:
- Dos almacenes de datos de BigQuery: uno almacena los datos confidenciales y el otro, los datos de derechos, que incluyen los acuerdos de uso compartido de datos entre proveedores y consumidores, así como el propósito de uso aprobado.
- Data Catalog almacena la información del acuerdo de compartición de datos del proveedor como etiquetas.
- Dos instancias de Cloud Run, como se indica a continuación:
- Una instancia ejecuta Report Engine, que comprueba si se han aplicado las etiquetas y publica los resultados.
- Otra instancia ejecuta Tag Engine, que etiqueta los datos del almacén de datos seguro.
- Pub/Sub publica las detecciones.
Para detectar problemas relacionados con este control, la arquitectura incluye los siguientes hallazgos:
- Indica si hay una entrada para un recurso de datos en el conjunto de datos
entitlement_management. - Indica si se realiza una operación en una tabla sensible con un caso práctico caducado (por ejemplo, si ha pasado el
valid_until_dateen elconsumer_agreement table). - Si se realiza una operación en una tabla sensible con una clave de etiqueta incorrecta.
- Indica si se realiza una operación en una tabla sensible con un valor de etiqueta de caso práctico en blanco o no aprobado.
- Si se consulta una tabla sensible con un método de operación no aprobado (por ejemplo,
SELECToINSERT). - Si el propósito registrado que ha especificado el consumidor al consultar los datos sensibles coincide con el acuerdo de compartición de datos.
9. Los datos están protegidos y los controles se documentan
Este control requiere la implementación del cifrado y la anonimización de datos para proteger los datos sensibles y proporcionar un registro de estos controles.
Esta arquitectura se basa en la seguridad predeterminada de Google, que incluye el cifrado en reposo. Además, la arquitectura te permite gestionar tus propias claves mediante claves de cifrado gestionadas por el cliente (CMEK). Cloud KMS te permite encriptar tus datos con claves de encriptado respaldadas por software o módulos de seguridad de hardware (HSMs) con validación FIPS 140-2 de nivel 3.
La arquitectura usa el enmascaramiento dinámico de datos a nivel de columna, que se configura mediante etiquetas de políticas, y almacena los datos confidenciales en un perímetro de Controles de Servicio de VPC independiente. También puedes añadir la anonimización a nivel de aplicación, que puedes implementar de forma local o como parte de la canalización de ingestión de datos.
De forma predeterminada, la arquitectura implementa el cifrado con CMEK y HSMs, pero también admite Cloud External Key Manager (Cloud EKM).
En la siguiente tabla se describe la política de seguridad de ejemplo que implementa la arquitectura para la región us-central1. Puede adaptar la política a sus necesidades, por ejemplo, añadiendo políticas diferentes para distintas regiones.
| Sensibilidad de los datos | Método de cifrado predeterminado | Otros métodos de cifrado permitidos | Método de desidentificación predeterminado | Otros métodos de anonimización permitidos |
|---|---|---|---|---|
| Información pública | Cifrado predeterminado | Cualquiera | Ninguno | Cualquiera |
| Información personal identificable sensible | CMEK con HSM | EKM | Anular | Hash SHA-256 o valor de enmascaramiento predeterminado |
| Información personal identificable | CMEK con HSM | EKM | Hash SHA-256 | Anular o enmascarar el valor predeterminado |
| Información personal sensible | CMEK con HSM | EKM | Valor de enmascaramiento predeterminado | Hash SHA-256 o anulación |
| Información personal | CMEK con HSM | EKM | Valor de enmascaramiento predeterminado | Hash SHA-256 o anulación |
La arquitectura usa Data Catalog para añadir la etiqueta encryption_method a la plantilla de etiqueta CDMC controls a nivel de tabla. encryption_method
define el método de cifrado que usa el recurso de datos.
Además, la arquitectura crea una etiqueta security policy template para identificar qué método de desidentificación se aplica a un campo concreto. La arquitectura usa el platform_deid_method, que se aplica mediante el enmascaramiento dinámico de datos. Puedes añadir el app_deid_method y rellenarlo con las
canalizaciones de ingestión de datos de Dataflow y Protección de Datos Sensibles que se incluyen en
el plano técnico del almacén de datos seguro.
En el siguiente diagrama se muestran los servicios a los que se aplica este control.

Para cumplir los requisitos de este control, la arquitectura utiliza los siguientes servicios:
- Dos instancias opcionales de Dataflow: una realiza la desidentificación a nivel de aplicación y la otra, la reidentificación.
- Tres almacenes de datos de BigQuery: uno almacena los datos confidenciales, otro los no confidenciales y el tercero, la política de seguridad.
- Data Catalog almacena las plantillas de etiquetas de encriptado y desidentificación.
- Dos instancias de Cloud Run, como se indica a continuación:
- Una instancia ejecuta Report Engine, que comprueba si se han aplicado las etiquetas y publica los resultados.
- Otra instancia ejecuta Tag Engine, que etiqueta los datos del almacén de datos seguro.
- Resultados publicados de Pub/Sub.
Para detectar problemas relacionados con este control, la arquitectura incluye los siguientes hallazgos:
- El valor de la etiqueta del método de cifrado no coincide con los métodos de cifrado permitidos para la sensibilidad y la ubicación especificadas.
- Una tabla contiene columnas sensibles, pero la etiqueta de plantilla de política de seguridad contiene un método de desidentificación no válido a nivel de plataforma.
- Una tabla contiene columnas sensibles, pero falta la etiqueta de plantilla de política de seguridad.
10. Se ha definido y se aplica un marco de privacidad de los datos
Este control requiere que la arquitectura inspeccione el catálogo de datos y las clasificaciones para determinar si debes crear un informe de evaluación del impacto en la protección de datos (EIPD) o un informe de evaluación del impacto en la privacidad (EIP). Las evaluaciones de privacidad varían significativamente entre las zonas geográficas y los organismos reguladores. Para determinar si es necesaria una evaluación del impacto, la arquitectura debe tener en cuenta la residencia de los datos y la residencia del interesado.
La arquitectura usa Data Catalog para añadir las siguientes etiquetas a la plantilla de etiquetas Impact assessment:
subject_locations: la ubicación de los sujetos a los que se hace referencia en los datos de este recurso.is_dpia: indica si se ha completado una evaluación de impacto relativa a la protección de datos (EIPD) para este recurso.is_pia: si se ha completado una evaluación del impacto en la privacidad (EIP) para este recurso.impact_assessment_reports: enlace externo a la ubicación donde se almacena el informe de evaluación del impacto.most_recent_assessment: fecha de la evaluación de impacto más reciente.oldest_assessment: la fecha de la primera evaluación de impacto.
Etiquetador de Engine añade estas etiquetas a cada recurso de datos sensibles, tal como se define en el control 6. El detector valida estas etiquetas con una tabla de políticas de BigQuery, que incluye combinaciones válidas de residencia de datos, ubicación del interesado, sensibilidad de los datos (por ejemplo, si se trata de IPI) y el tipo de evaluación de impacto (EIP o EIPD) que se requiere.
En el siguiente diagrama se muestran los servicios a los que se aplica este control.

Para cumplir los requisitos de este control, la arquitectura utiliza los siguientes servicios:
- Cuatro almacenes de datos de BigQuery almacenan la siguiente información:
- Datos confidenciales
- Datos no confidenciales
- Política de evaluación del impacto y marcas de tiempo de los derechos
- Exportaciones de etiquetas que se usan en el panel de control
- Data Catalog almacena los detalles de la evaluación del impacto en etiquetas de plantillas de etiquetas.
- Dos instancias de Cloud Run, como se indica a continuación:
- Una instancia ejecuta Report Engine, que comprueba si se han aplicado las etiquetas y publica los resultados.
- Otra instancia ejecuta Tag Engine, que etiqueta los datos del almacén de datos seguro.
- Pub/Sub publica las detecciones.
Para detectar problemas relacionados con este control, la arquitectura incluye los siguientes hallazgos:
- Hay datos sensibles sin una plantilla de evaluación de impacto.
- Hay datos sensibles sin un enlace a un informe de EIPD o EIP.
- Las etiquetas no cumplen los requisitos de la tabla de la política.
- La evaluación del impacto es anterior al derecho más reciente aprobado para el recurso de datos en la tabla de acuerdos de consumidor.
11. Se planifica y gestiona el ciclo de vida de los datos
Este control requiere la capacidad de inspeccionar todos los recursos de datos para determinar que existe una política de ciclo de vida de los datos y que se cumple.
La arquitectura usa Data Catalog para añadir las siguientes etiquetas a la plantilla de etiquetas CDMC controls:
retention_period: el tiempo, en días, que se conservará la tabla.expiration_action: si se debe archivar o eliminar la tabla cuando finalice el periodo de conservación
De forma predeterminada, la arquitectura usa el siguiente periodo de conservación y acción de vencimiento:
| Categoría de datos | Periodo de conservación, en días | Acción de caducidad |
|---|---|---|
| Información personal identificable sensible | 60 | Eliminar |
| Información personal identificable | 90 | Archivar |
| Información personal sensible | 180 | Archivar |
| Información personal | 180 | Archivar |
Record Manager, un recurso de código abierto para BigQuery, automatiza la purga y el archivado de tablas de BigQuery en función de los valores de las etiquetas anteriores y de un archivo de configuración. El procedimiento de purga establece una fecha de vencimiento en una tabla y crea una tabla de instantánea con un tiempo de vencimiento que se define en la configuración de Record Manager. De forma predeterminada, el tiempo de caducidad es de 30 días. Durante el periodo de eliminación lógica, puedes recuperar la tabla. El procedimiento de archivado crea una tabla externa para cada tabla de BigQuery que supera su periodo de conservación. La tabla se almacena en Cloud Storage en formato Parquet y se actualiza a una tabla BigLake, lo que permite etiquetar el archivo externo con metadatos en Data Catalog.
En el siguiente diagrama se muestran los servicios a los que se aplica este control.

Para cumplir los requisitos de este control, la arquitectura utiliza los siguientes servicios:
- Dos almacenes de datos de BigQuery: uno almacena los datos confidenciales y el otro, la política de conservación de datos.
- Dos instancias de Cloud Storage: una proporciona almacenamiento de archivos y la otra almacena registros.
- Data Catalog almacena el periodo de conservación y la acción en las plantillas de etiquetas y en las etiquetas.
- Dos instancias de Cloud Run: una ejecuta el gestor de registros y la otra implementa los detectores.
- Tres instancias de Cloud Run, como se indica a continuación:
- Una instancia ejecuta Report Engine, que comprueba si se han aplicado las etiquetas y publica los resultados.
- Otra instancia ejecuta Tag Engine, que etiqueta los datos del almacén de datos seguro.
- Otra instancia ejecuta Record Manager, que automatiza la purga y el archivado de tablas de BigQuery.
- Pub/Sub publica las detecciones.
Para detectar problemas relacionados con este control, la arquitectura incluye los siguientes hallazgos:
- En el caso de los recursos sensibles, asegúrate de que el método de conservación se ajuste a la política de la ubicación del recurso.
- En el caso de los recursos sensibles, asegúrate de que el periodo de conservación se ajuste a la política de la ubicación del recurso.
12. Se gestiona la calidad de los datos
Este control requiere la capacidad de medir la calidad de los datos en función de la creación de perfiles de datos o de métricas definidas por el usuario.
La arquitectura incluye la posibilidad de definir reglas de calidad de los datos para un valor individual o agregado, así como de asignar umbrales a una columna de una tabla específica. Incluye plantillas de etiquetas para comprobar que son correctas y completas. Data Catalog añade las siguientes etiquetas a cada plantilla de etiqueta:
column_name: el nombre de la columna a la que se aplica la métricametric: el nombre de la métrica o la regla de calidadrows_validated: número de filas validadassuccess_percentage: el porcentaje de valores que cumplen esta métrica.acceptable_threshold: umbral aceptable de esta métrica.meets_threshold: indica si el nivel de calidad (el valorsuccess_percentage) cumple el umbral aceptable.most_recent_run: la hora más reciente en la que se ejecutó la métrica o la regla de calidad.
En el siguiente diagrama se muestran los servicios a los que se aplica este control.

Para cumplir los requisitos de este control, la arquitectura utiliza los siguientes servicios:
- Tres almacenes de datos de BigQuery: uno almacena los datos sensibles, otro los datos no sensibles y el tercero las métricas de las reglas de calidad.
- Data Catalog almacena los resultados de la calidad de los datos en plantillas de etiquetas y etiquetas.
- Cloud Scheduler define cuándo se ejecuta Cloud Data Quality Engine.
- Tres instancias de Cloud Run, como se indica a continuación:
- Una instancia ejecuta Report Engine, que comprueba si se han aplicado las etiquetas y publica los resultados.
- Otra instancia ejecuta Tag Engine, que etiqueta los datos del almacén de datos seguro.
- La tercera instancia ejecuta Cloud Data Quality Engine.
- Cloud Data Quality Engine define reglas de calidad de los datos y programa comprobaciones de calidad de los datos para tablas y columnas.
- Pub/Sub publica las detecciones.
Un panel de control de Looker Studio muestra los informes de calidad de los datos de los niveles de tabla y de columna.
Para detectar problemas relacionados con este control, la arquitectura incluye los siguientes hallazgos:
- Los datos son sensibles, pero no se han aplicado plantillas de etiquetas de calidad de datos (corrección e integridad).
- Los datos son sensibles, pero la etiqueta de calidad de los datos no se ha aplicado a la columna sensible.
- Los datos son sensibles, pero los resultados de calidad de los datos no superan el umbral definido en la regla.
- Los datos no son sensibles y los resultados de calidad de los datos no están dentro del umbral definido por la regla.
Como alternativa a Cloud Data Quality Engine, puede configurar tareas de calidad de los datos de Dataplex Universal Catalog.
13. Se establecen y aplican principios de gestión de costes
Este control requiere la capacidad de inspeccionar los activos de datos para confirmar el uso de los costes, en función de los requisitos de las políticas y la arquitectura de datos. Las métricas de costes deben ser completas y no limitarse al uso y al movimiento del almacenamiento.
La arquitectura usa Data Catalog para añadir las siguientes etiquetas a la plantilla de etiquetas cost_metrics:
total_query_bytes_billed: número total de bytes de consulta que se han facturado por este recurso de datos desde principios del mes actual.total_storage_bytes_billed: número total de bytes de almacenamiento que se han facturado por este recurso de datos desde principios del mes actual.total_bytes_transferred: suma de los bytes transferidos entre regiones a este recurso de datos.estimated_query_cost: coste estimado de las consultas, en dólares estadounidenses, del recurso de datos del mes actual.estimated_storage_cost: coste de almacenamiento estimado, en dólares estadounidenses, del recurso de datos del mes en curso.estimated_egress_cost: estimación de la salida de datos en dólares estadounidenses del mes actual en el que se ha usado el recurso de datos como tabla de destino.
La arquitectura exporta la información de precios de Facturación de Cloud a una tabla de BigQuery llamada cloud_pricing_export.
En el siguiente diagrama se muestran los servicios a los que se aplica este control.

Para cumplir los requisitos de este control, la arquitectura utiliza los siguientes servicios:
- Facturación de Cloud proporciona información de facturación.
- Data Catalog almacena la información de costes en plantillas de etiquetas y etiquetas.
- BigQuery almacena la información de precios exportada y la información histórica de las tareas de consulta a través de su vista INFORMATION_SCHEMA integrada.
- Dos instancias de Cloud Run, como se indica a continuación:
- Una instancia ejecuta Report Engine, que comprueba si se han aplicado las etiquetas y publica los resultados.
- Otra instancia ejecuta Tag Engine, que etiqueta los datos del almacén de datos seguro.
- Pub/Sub publica las detecciones.
Para detectar problemas relacionados con este control, la arquitectura comprueba si existen recursos de datos sensibles sin métricas de costes asociadas.
14. Se entienden la procedencia y el linaje de los datos
Este control requiere la capacidad de inspeccionar la trazabilidad del recurso de datos desde su origen y cualquier cambio en el linaje del recurso de datos.
Para mantener la información sobre la procedencia y el linaje de los datos, la arquitectura usa las funciones de linaje de datos integradas de Data Catalog. Además, las secuencias de comandos de ingestión de datos definen la fuente final y la añaden como un nodo adicional al gráfico de linaje de datos.
Para cumplir los requisitos de este control, la arquitectura usa Data Catalog para añadir la etiqueta ultimate_source a la plantilla de etiqueta CDMC
controls. La etiqueta ultimate_source define la fuente de este recurso de datos.
En el siguiente diagrama se muestran los servicios a los que se aplica este control.

Para cumplir los requisitos de este control, la arquitectura utiliza los siguientes servicios:
- Dos almacenes de datos de BigQuery: uno almacena los datos confidenciales y el otro, los datos de origen definitivos.
- Data Catalog almacena la fuente definitiva en plantillas de etiquetas y etiquetas.
- Las secuencias de comandos de ingestión de datos cargan los datos de Cloud Storage, definen la fuente final y añaden la fuente al gráfico de linaje de datos.
- Dos instancias de Cloud Run, como se indica a continuación:
- Una instancia ejecuta Report Engine, que comprueba si se han aplicado las etiquetas y publica los resultados.
- Otra instancia ejecuta Tag Engine, que etiqueta los datos del almacén de datos seguro.
- Pub/Sub publica las detecciones.
Para detectar problemas relacionados con este control, la arquitectura incluye las siguientes comprobaciones:
- Los datos sensibles se identifican sin una etiqueta de fuente definitiva.
- El gráfico de linaje no se rellena en el caso de los recursos de datos sensibles.
Referencia de etiqueta
En esta sección se describen las plantillas de etiquetas y las etiquetas que usa esta arquitectura para cumplir los requisitos de los controles clave de CDMC.
Plantillas de etiquetas de control de CDMC a nivel de tabla
En la siguiente tabla se indican las etiquetas que forman parte de la plantilla de etiqueta de control de CDMC y que se aplican a las tablas.
| Etiqueta | ID de etiqueta | Control de claves aplicable |
|---|---|---|
| Ubicación de almacenamiento aprobada | approved_storage_location |
4 |
| Uso aprobado | approved_use |
8 |
| Correo del propietario de los datos | data_owner_email |
2 |
| Nombre del propietario de los datos | data_owner_name |
2 |
| Método de cifrado | encryption_method |
9 |
| Acción de caducidad | expiration_action |
11 |
| Is Authoritative | is_authoritative |
3 |
| Is Sensitive | is_sensitive |
6 |
| Categoría sensible | sensitive_category |
6 |
| Compartir la geografía del ámbito | sharing_scope_geography |
8 |
| Entidad legal del ámbito de uso compartido | sharing_scope_legal_entity |
8 |
| Periodo de conservación | retention_period |
11 |
| Ultimate Source | ultimate_source |
14 |
Plantilla de etiqueta de evaluación del impacto
En la siguiente tabla se enumeran las etiquetas que forman parte de la plantilla de etiqueta de evaluación del impacto y que se aplican a las tablas.
| Etiqueta | ID de etiqueta | Control de claves aplicable |
|---|---|---|
| Ubicaciones del sujeto | subject_locations |
10 |
| ¿Es una evaluación del impacto de la EIPD? | is_dpia |
10 |
| Evaluación del impacto de la PIA | is_pia |
10 |
| Informes de evaluación del impacto | impact_assessment_reports |
10 |
| Evaluación de impacto más reciente | most_recent_assessment |
10 |
| Evaluación de impacto más antigua | oldest_assessment |
10 |
Plantilla de etiqueta Métricas de costes
En la siguiente tabla se enumeran las etiquetas que forman parte de la plantilla de etiqueta de métricas de costes y que se aplican a las tablas.
| Etiqueta | ID de pestaña | Control de claves aplicable |
|---|---|---|
| Coste de consulta estimado | estimated_query_cost |
13 |
| Coste de almacenamiento estimado | estimated_storage_cost |
13 |
| Coste de salida estimado | estimated_egress_cost |
13 |
| Total de bytes de consulta facturados | total_query_bytes_billed |
13 |
| Total de bytes de almacenamiento facturados | total_storage_bytes_billed |
13 |
| Total de bytes transferidos | total_bytes_transferred |
13 |
Plantilla de etiqueta de sensibilidad de los datos
En la siguiente tabla se indican las etiquetas que forman parte de la plantilla de etiqueta Sensibilidad de los datos y que se aplican a los campos.
| Etiqueta | ID de etiqueta | Control de claves aplicable |
|---|---|---|
| Campo sensible | sensitive_field |
6 |
| Tipo de información sensible | sensitive_category |
6 |
Plantilla de etiqueta de política de seguridad
En la siguiente tabla se enumeran las etiquetas que forman parte de la plantilla de etiqueta de política de seguridad y que se aplican a los campos.
| Etiqueta | ID de etiqueta | Control de claves aplicable |
|---|---|---|
| Método de desidentificación de aplicaciones | app_deid_method |
9 |
| Método de desidentificación de la plataforma | platform_deid_method |
9 |
Plantillas de etiquetas de calidad de los datos
En la siguiente tabla se enumeran las etiquetas que forman parte de las plantillas de etiquetas de calidad de datos de integridad y exactitud, y que se aplican a los campos.
| Etiqueta | ID de etiqueta | Control de claves aplicable |
|---|---|---|
| Umbral aceptable | acceptable_threshold |
12 |
| Nombre de la columna | column_name |
12 |
| Cumple el umbral | meets_threshold |
12 |
| Métrica | metric |
12 |
| Carrera más reciente | most_recent_run |
12 |
| Filas validadas | rows_validated |
12 |
| Porcentaje de éxito | success_percentage |
12 |
Etiquetas de política de CDMC a nivel de campo
En la siguiente tabla se enumeran las etiquetas de política que forman parte de la taxonomía de etiquetas de política de clasificación de datos sensibles de CDMC y que se aplican a los campos. Estas etiquetas de política restringen el acceso a nivel de campo y habilitan la desidentificación de datos a nivel de plataforma.
| Clasificación de datos | Nombre de la etiqueta | Control de claves aplicable |
|---|---|---|
| Información personal identificable | personal_identifiable_information |
7 |
| Información personal | personal_information |
7 |
| Información personal identificable sensible | sensitive_personal_identifiable_information |
7 |
| Información personal sensible | sensitive_personal_data |
7 |
Metadatos técnicos rellenados automáticamente
En la siguiente tabla se enumeran los metadatos técnicos que se sincronizan de forma predeterminada en Data Catalog para todos los recursos de datos de BigQuery.
| Metadatos | Control de claves aplicable |
|---|---|
| Tipo de recurso | — |
| Hora de creación | — |
| Fecha de caducidad | 11 |
| Ubicación | 4 |
| URL de recurso | 3 |
Siguientes pasos
- Más información sobre CDMC
- Consulta información sobre los controles de seguridad que se usan en el modelo de almacén de datos seguro.
- Descubre Data Catalog.
- Más información sobre Dataplex Universal Catalog
- Más información sobre Tag Engine
- Implementa esta solución con la Google Cloud arquitectura de referencia de CDMC en GitHub.