
Este documento descreve como implantar seus aplicativos, incluindo serviços, jobs e pools de trabalhadores do Cloud Run.
Com o Cloud Deploy, é possível implantar suas cargas de trabalho baseadas em contêineres em qualquer serviço, job ou pool de trabalhadores do Cloud Run. Todos os recursos do Cloud Deploy são compatíveis quando você implanta em destinos do Cloud Run para serviços ou pools de trabalhadores do Cloud Run, mas as implantações canário não são compatíveis com jobs do Cloud Run.
Este documento descreve as três principais configurações que você precisa concluir para implantar no Cloud Run:
- Criar a configuração de destino
- Criar sua configuração do Skaffold
- Crie suas definições de serviço, definições de job ou definições de pool de workers do Cloud Run.
Limitações
Só é possível implantar um serviço, job ou pool de workers do Cloud Run por destino.
Não é possível executar uma implantação canário em um job do Cloud Run.
No entanto, os serviços do Cloud Run e os pools de workers podem usar uma implantação canário.
Para implantar uma função do Cloud Run usando o Cloud Deploy, é necessário modificar seu fluxo de trabalho de CI para criar a função em um contêiner e implantá-la como um serviço do Cloud Run.
Antes de começar
Verifique se você está usando a CLI gcloud na versão
541.0.0ou mais recente.
Crie sua configuração de destino
O destino pode ser configurado no YAML do pipeline de entrega ou em um arquivo separado. Além disso, é possível configurar mais de uma meta no mesmo arquivo.
Os destinos precisam ser definidos no mesmo projeto e região que o pipeline de entrega. No entanto, os serviços, jobs ou pools de workers em que os destinos são implantados podem estar em projetos e regiões diferentes, desde que a conta de serviço tenha acesso a esses projetos.
Na definição de destino, crie uma estrofe run para identificar o local em que o serviço do Cloud Run será criado.
A sintaxe para especificar o serviço, o job ou o pool de trabalhadores do Cloud Run na definição de destino é a seguinte:
run:
location: projects/[project_name]/locations/[region_name]
Esse identificador de recurso usa os seguintes elementos:
project_nameé o nome do projeto Google Cloud em que o serviço, o job ou o pool de workers do Cloud Run será criado.Faça isso para cada meta. Recomendamos um projeto diferente para cada serviço, job ou pool de workers do Cloud Run. Se você quiser mais de um serviço, job ou pool de workers no mesmo projeto, use perfis do Skaffold no arquivo de configuração
skaffold.yaml.region_nameé a região em que o serviço, o job ou o pool de workers será criado. Seu serviço, job ou pool de workers pode estar em qualquer região compatível com o Cloud Run.
Confira a seguir um exemplo de configuração de destino, definindo o serviço, job ou pool de workers do Cloud Run a ser criado:
apiVersion: deploy.cloud.google.com/v1
kind: Target
metadata:
name: dev
description: development service
run:
location: projects/my-app/locations/us-central1
É possível definir esse destino em uma definição de pipeline de entrega do Cloud Deploy ou separadamente. De qualquer forma, é necessário registrar o destino antes de criar a versão para implantar seu serviço, trabalho ou pool de workers do Cloud Run.
Criar a configuração do Skaffold
Confira a seguir um exemplo de arquivo skaffold.yaml para uma implantação do Cloud Run:
apiVersion: skaffold/v4beta7
kind: Config
metadata:
name: cloud-run-application
manifests:
rawYaml:
- service.yaml
deploy:
cloudrun: {}
Neste arquivo skaffold.yaml...
manifests.rawYamlfornece os nomes das definições de serviço do Cloud Run.Neste exemplo,
service.yamlé o arquivo que define um serviço do Cloud Run que o Skaffold vai implantar. O nome do arquivo pode ser qualquer coisa, mas por convenção éservice.yamlpara um serviço,job.yamlpara um job eworkerpool.yamlpara um pool de workers.A seção
deployespecifica como você quer que o manifesto seja implantado, especificamente, o projeto e o local. O campodeployé obrigatório.Recomendamos que você deixe o
{}vazio. O Cloud Deploy preenche isso durante a renderização, com base no projeto e no local da definição de destino.No entanto, para desenvolvimento local, você pode fornecer valores aqui. No entanto, o Cloud Deploy sempre usa o projeto e o local da definição de destino, independente de os valores serem fornecidos aqui.
Criar as definições de serviço do Cloud Run
Para criar uma definição de serviço do Cloud Run, crie uma manualmente ou copie de um serviço atual. Ambos são descritos nesta seção.
Opção 1: criar um novo service.yaml do Cloud Run
O arquivo service.yaml define seu serviço do Cloud Run. Quando você cria um lançamento, o Skaffold usa essa definição para implantar seu serviço.
Confira um exemplo simplificado:
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: [SERVICE_NAME]
spec:
template:
spec:
containers:
- image: [IMAGE_PATH]
Em que:
[SERVICE_NAME]é um nome para esse serviço do Cloud Run.[IMAGE_PATH]aponta para a imagem ou imagens do contêiner que você está implantando com esse serviço.
Opção 2: copiar um service.yaml de um serviço atual usando o console Google Cloud
É possível criar um serviço usando o console Google Cloud ou usar um já existente e copiar seu service.yaml de lá.
Para receber o service.yaml usando a Google Cloud CLI:
gcloud run services describe [service_name] --format=export
Para extrair o service.yaml do console Google Cloud :
No console do Google Cloud , acesse a página "Serviços do Cloud Run".
Selecione o serviço atual cuja definição você quer usar.
Ou crie uma e selecione. Ao selecionar o serviço, a página de detalhes do serviço é mostrada:
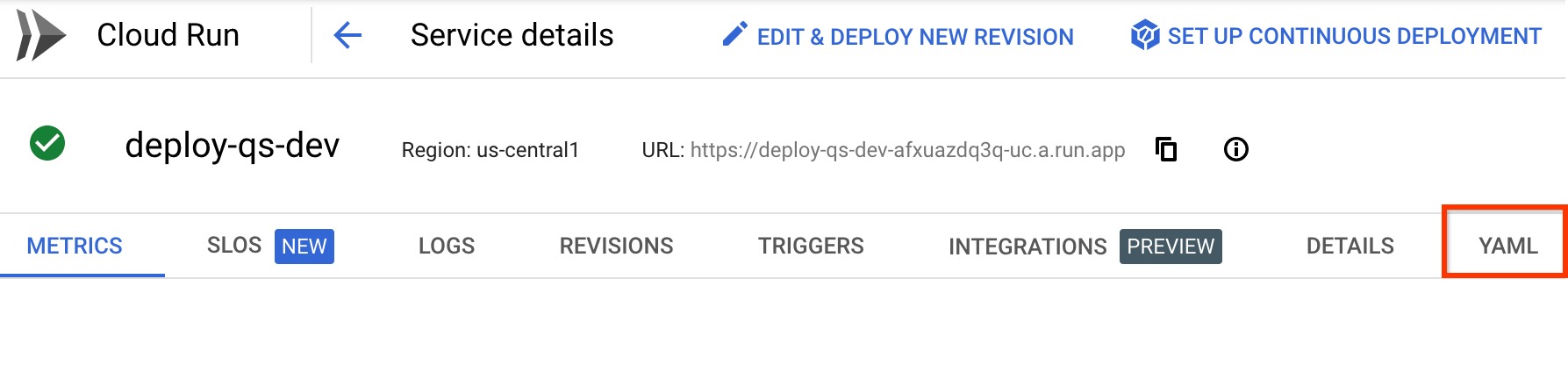
Selecione a guia YAML.
Clique em Editar e copie o conteúdo do YAML para um novo arquivo chamado
service.yamlno seu sistema de arquivos para que o Skaffold possa usá-lo quando você criar um lançamento.
Criar as definições de job do Cloud Run
Para implantar uma definição de job do Cloud Run, crie uma manualmente ou copie de um job atual. Ambos são descritos nesta seção.
Os jobs não são necessariamente executados quando implantados pelo Cloud Deploy. Isso é diferente dos serviços, que são aplicativos em execução após a implantação. A forma como um job é invocado depende dele mesmo.
Opção 1: criar um novo job.yaml do Cloud Run
O arquivo job.yaml define seu job do Cloud Run. Ao criar um lançamento, o Skaffold usa essa definição para implantar o job.
Confira um exemplo simplificado:
apiVersion: run.googleapis.com/v1
kind: Job
metadata:
name: [JOB_NAME]
spec:
template:
spec:
containers:
- image: [IMAGE_PATH]
Em que:
[JOB_NAME]é um nome para esse job do Cloud Run.[IMAGE_PATH]aponta para a imagem do contêiner que você está implantando para este job.
Opção 2: copiar um job.yaml de um job atual usando o console Google Cloud
É possível criar um job usando o console Google Cloud ou usar um já existente
e copiar seu job.yaml de lá.
Para receber o job.yaml usando a Google Cloud CLI:
gcloud run jobs describe [job_name] --format=export
Para extrair o job.yaml do console Google Cloud :
No console do Google Cloud , acesse a página "Jobs do Cloud Run".
Selecione o job atual cuja definição você quer usar.
Ou crie uma e selecione. Ao selecionar o job, a página de detalhes do job é mostrada:
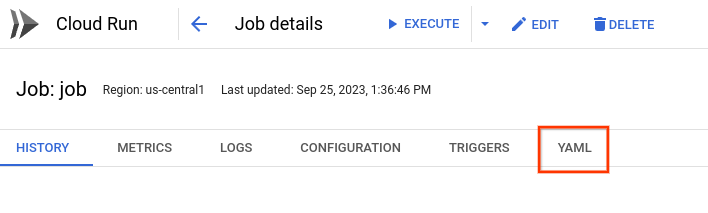
Selecione a guia YAML.
Clique em Editar e copie o conteúdo do YAML para um novo arquivo chamado
job.yamlno seu sistema de arquivos para que o Skaffold possa usá-lo quando você criar um lançamento.
Criar as definições do pool de workers do Cloud Run
Para implantar uma definição de pool de workers do Cloud Run, crie uma manualmente ou copie de um pool de workers existente. Ambos são descritos nesta seção.
Opção 1: criar um novo workerpool.yaml do Cloud Run
O arquivo workerpool.yaml define seu pool de workers do Cloud Run. Quando você cria um lançamento, o Skaffold usa essa definição para implantar o pool de workers.
Confira um exemplo simplificado:
apiVersion: run.googleapis.com/v1
kind: WorkerPool
metadata:
name: [WORKERPOOL_NAME]
annotations:
run.googleapis.com/launch-stage: BETA
spec:
template:
spec:
containers:
- image: [IMAGE_PATH]
Em que:
[WORKERPOOL_NAME]é o nome desse pool de workers do Cloud Run.[IMAGE_PATH]aponta para a imagem do contêiner que você está implantando para este pool de workers.
Opção 2: copiar um workerpool.yaml de um pool de workers usando o console Google Cloud
É possível criar um pool de workers usando o console Google Cloud ou usar um já existente
e copiar seu workerpool.yaml de lá.
Para receber o workerpool.yaml usando a Google Cloud CLI:
gcloud beta run worker-pools describe [workerpool_name] --format=export
Para extrair o workerpool.yaml do console Google Cloud :
No console Google Cloud , acesse a página "Pools de trabalhadores do Cloud Run".
Selecione o pool de worker atual cuja definição você quer usar.
Ou crie uma e selecione. Ao selecionar o pool de workers, a página de detalhes do pool de workers é mostrada:
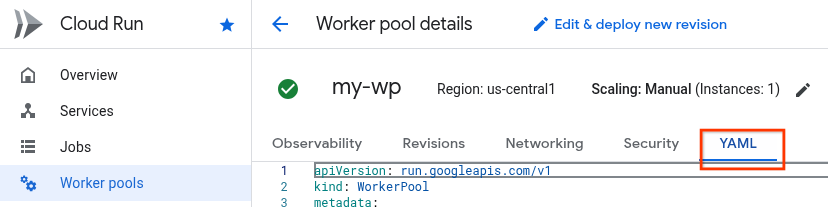
Selecione a guia YAML.
Copie o conteúdo do YAML para um novo arquivo chamado
workerpool.yamlno seu sistema de arquivos para que o Skaffold possa usá-lo ao criar um lançamento.
Como tudo funciona em conjunto
Agora que você tem a definição de serviço, job ou pool de workers do Cloud Run, a configuração skaffold.yaml e a definição de destino do Cloud Deploy, e registrou o destino como um recurso do Cloud Deploy, é possível invocar o pipeline de entrega para criar um lançamento e progredir na progressão de destinos definidos no pipeline.
O guia de início rápido Implantar um app no Cloud Run usando o Cloud Deploy mostra tudo isso em ação.
Comportamento dos serviços em todas as revisões
Quando você implanta novamente um serviço, a nova revisão é baseada no service.yaml recém-implantado. Nada da revisão anterior é mantido, a menos que seja igual no YAML recém-implantado. Por exemplo, se houver configurações ou rótulos na revisão anterior que não estão no novo YAML, eles não vão aparecer na nova revisão.
Como acionar jobs do Cloud Run
Depois de implantar um job, é possível acioná-lo conforme descrito na documentação do Cloud Run.
Implantação de serviços, jobs e pools de workers do Cloud Run em vários projetos
Se você precisar implantar serviços, jobs ou pools de workers que estão em projetos diferentes, sua conta de serviço de execução precisará de permissão para acessar os projetos em que esses serviços, jobs ou pools de workers estão definidos.
Consulte Conta de serviço de execução do Cloud Deploy e Papéis e permissões do Identity and Access Management para mais informações.
Como implantar o Cloud Run functions
O Cloud Run functions cria seu código-fonte sempre que uma função é implantada. Por isso, cada ambiente de execução de destino no pipeline pode receber um artefato ligeiramente diferente. Isso é contrário às práticas recomendadas do Cloud Deploy. Em vez disso, sugerimos usar um serviço do Cloud Run diretamente. Isso permite criar um único artefato e promovê-lo em todos os seus ambientes.
Verifique o
service.yamlda função do Cloud Run.Para isso, execute o comando a seguir:
gcloud run services describe FUNCTION_NAME \ --format=export \ --region=REGION \ --project=PROJECTRemova as seguintes anotações, se estiverem presentes:
run.googleapis.com/build-base-imagerun.googleapis.com/build-namerun.googleapis.com/build-source-locationrun.googleapis.com/build-enable-automatic-updates
Substitua o valor em
spec.spec.containers.imageporIMAGE_TAG.Crie seu pipeline de entrega e destinos, com o serviço do Cloud Run como destino.
Separe as etapas de build e implantação no seu processo de CI. Em vez de usar a Google Cloud CLI para implantar a função, siga estas etapas:
Crie a função em um contêiner usando o Cloud Build:
gcloud builds submit --pack image=REGION-docker.pkg.dev/PROJECT/cloud-run-source-deploy/IMAGE_NAME \ --project=PROJECT \ --region=REGIONCrie uma versão usando o Cloud Deploy:
gcloud deploy releases create RELEASE_NAME \ --project=DEPLOY_PROJECT \ --region=REGION \ --delivery-pipeline=DELIVERY_PIPELINE \ --images=IMAGE_TAG=REGION-docker.pkg.dev/PROJECT/cloud-run-source-deploy/IMAGE_NAMENeste comando...
RELEASE_NAMEé um nome que será atribuído à versão. O nome precisa ser exclusivo entre todas as versões do pipeline de entrega.DEPLOY_PROJECTé o ID do projeto em que você criou o pipeline de implantação.DELIVERY_PIPELINEé o nome do pipeline de entrega que gerenciará a implantação dessa versão por meio da progressão de destinos. Esse nome precisa corresponder ao camponamena definição do pipeline.REGIONé o nome da região em que você está criando a versão, por exemplo,us-central1. Obrigatório.IMAGE_NAMEé o nome que você deu à imagem na etapa anterior, quando criou a função.
A seguir
Confira o guia de início rápido: implantar um aplicativo no Cloud Run
Saiba mais sobre como configurar destinos do Cloud Deploy
Saiba mais sobre os ambientes de execução do Cloud Deploy.
Saiba mais sobre o suporte do Skaffold para o Cloud Run.
Saiba mais sobre o Cloud Run