
Hinweis
Richten Sie ein Google Cloud -Projekt und zwei (2) Cloud Storage-Buckets ein, falls Sie dies noch nicht getan haben.
Projekt einrichten
- Melden Sie sich in Ihrem Google Cloud -Konto an. Wenn Sie mit Google Cloudnoch nicht vertraut sind, erstellen Sie ein Konto, um die Leistungsfähigkeit unserer Produkte in der Praxis sehen und bewerten zu können. Neukunden erhalten außerdem ein Guthaben von 300 $, um Arbeitslasten auszuführen, zu testen und bereitzustellen.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc, Compute Engine, Cloud Storage, and Cloud Run functions APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
Installieren Sie die Google Cloud CLI.
-
Wenn Sie einen externen Identitätsanbieter (IdP) verwenden, müssen Sie sich zuerst mit Ihrer föderierten Identität in der gcloud CLI anmelden.
-
Führen Sie den folgenden Befehl aus, um die gcloud CLI zu initialisieren:
gcloud init -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc, Compute Engine, Cloud Storage, and Cloud Run functions APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
Installieren Sie die Google Cloud CLI.
-
Wenn Sie einen externen Identitätsanbieter (IdP) verwenden, müssen Sie sich zuerst mit Ihrer föderierten Identität in der gcloud CLI anmelden.
-
Führen Sie den folgenden Befehl aus, um die gcloud CLI zu initialisieren:
gcloud init
Zwei Cloud Storage-Buckets in Ihrem Projekt erstellen oder verwenden
Sie benötigen zwei Cloud Storage-Buckets in Ihrem Projekt: einen für Eingabedateien und einen für die Ausgabe.
- Wechseln Sie in der Google Cloud Console unter „Cloud Storage“ zur Seite Buckets.
- Klicken Sie auf Erstellen.
- Geben Sie auf der Seite Bucket erstellen die Bucket-Informationen ein. Klicken Sie auf Weiter, um mit dem nächsten Schritt fortzufahren.
-
Führen Sie im Abschnitt Einstieg die folgenden Schritte aus:
- Geben Sie einen global eindeutigen Namen ein, der den Anforderungen für Bucket-Namen entspricht.
- So fügen Sie ein Bucket-Label hinzu: Maximieren Sie den Abschnitt Labels (), klicken Sie auf add_box
Label hinzufügen und geben Sie
keyundvaluefür Ihr Label an.
-
Gehen Sie im Bereich Speicherort für Daten auswählen so vor:
- Standorttyp auswählen.
- Wählen Sie im Drop-down-Menü Standorttyp einen Standort aus, an dem die Daten Ihres Buckets dauerhaft gespeichert werden.
- Wenn Sie den Standorttyp Dual-Region auswählen, können Sie auch die Turboreplikation aktivieren, indem Sie das entsprechende Kästchen anklicken.
- Wenn Sie die Bucket-übergreifende Replikation einrichten möchten, wählen Sie Bucket-übergreifende Replikation über Storage Transfer Service hinzufügen aus und führen Sie die folgenden Schritte aus:
Bucket-übergreifende Replikation einrichten
- Wählen Sie im Menü Bucket einen Bucket aus.
Klicken Sie im Bereich Replikationseinstellungen auf Konfigurieren, um die Einstellungen für den Replikationsjob zu konfigurieren.
Der Bereich Bucket-übergreifende Replikation konfigurieren wird angezeigt.
- Wenn Sie die zu replizierenden Objekte nach dem Objektnamenspräfix filtern möchten, geben Sie ein Präfix ein, mit dem Sie Objekte ein- oder ausschließen möchten, und klicken Sie dann auf Präfix hinzufügen.
- Wenn Sie eine Speicherklasse für die replizierten Objekte festlegen möchten, wählen Sie im Menü Speicherklasse eine Speicherklasse aus. Wenn Sie diesen Schritt überspringen, wird für replizierte Objekte standardmäßig die Speicherklasse des Ziel-Buckets verwendet.
- Klicken Sie auf Fertig.
-
Gehen Sie im Bereich Speicherort für Daten auswählen so vor:
- Wählen Sie eine Standardspeicherklasse für den Bucket oder Autoclass für die automatische Speicherklassenverwaltung der Daten Ihres Buckets aus.
- Wenn Sie den hierarchischen Namespace aktivieren möchten, wählen Sie im Bereich Speicher für datenintensive Arbeitslasten optimieren die Option Hierarchischen Namespace für diesen Bucket aktivieren aus.
- Wählen Sie im Abschnitt Zugriff auf Objekte steuern aus, ob der Bucket Verhinderung des öffentlichen Zugriffs durchsetzt, und wählen Sie eine Zugriffssteuerungsmethode für die Objekte Ihres Buckets aus.
-
Führen Sie im Bereich Auswählen, wie Objektdaten geschützt werden die folgenden Schritte aus:
- Wählen Sie unter Datenschutz die gewünschten Optionen für Ihren Bucket aus.
- Wenn Sie Vorläufiges Löschen aktivieren möchten, klicken Sie das Kästchen Richtlinie für vorläufiges Löschen (zur Datenwiederherstellung) an und geben Sie die Anzahl der Tage an, die Objekte nach dem Löschen beibehalten werden sollen.
- Wenn Sie die Objektversionsverwaltung festlegen möchten, klicken Sie das Kästchen Objektversionsverwaltung (zur Datenwiederherstellung) an und geben Sie die maximale Anzahl von Versionen pro Objekt und die Anzahl der Tage an, nach denen die nicht aktuellen Versionen ablaufen.
- Klicken Sie das Kästchen Aufbewahrung (für Compliance) an, um die Aufbewahrungsrichtlinie für Objekte und Buckets zu aktivieren, und gehen Sie dann so vor:
- Klicken Sie auf das Kästchen Objektaufbewahrung aktivieren, um die Objektaufbewahrungssperre zu aktivieren.
- Wenn Sie Bucket Lock aktivieren möchten, klicken Sie das Kästchen Bucket-Aufbewahrungsrichtlinie festlegen an und wählen Sie eine Zeiteinheit und eine Zeitdauer für die Aufbewahrungsdauer aus.
- Um auszuwählen, wie Ihre Objektdaten verschlüsselt werden, maximieren Sie den Bereich Datenverschlüsselung () und wählen Sie eine Methode für die Datenverschlüsselung aus.
- Wählen Sie unter Datenschutz die gewünschten Optionen für Ihren Bucket aus.
-
Führen Sie im Abschnitt Einstieg die folgenden Schritte aus:
- Klicken Sie auf Erstellen.
Workflow-Vorlage erstellen
Um eine Workflow-Vorlage zu erstellen und zu definieren, kopieren Sie die folgenden Befehle und führen Sie sie in einem lokalen Terminalfenster oder in Cloud Shell aus.
- Erstellen Sie die Workflow-Vorlage.
gcloud dataproc workflow-templates create wordcount-template \ --region=us-central1
- Fügen Sie der Workflow-Vorlage den Wordcount-Job hinzu.
-
Geben Sie output-bucket-name an, bevor Sie den Befehl ausführen. Die Funktion stellt den Eingabe-Bucket bereit.
Nachdem Sie den Namen des Ausgabe-Buckets eingegeben haben, sollte das Argument des Ausgabe-Buckets so lauten:
gs://your-output-bucket/wordcount-output". -
Die Schritt-ID „count“ ist erforderlich und identifiziert den hinzugefügten Hadoop-Job.
gcloud dataproc workflow-templates add-job hadoop \ --workflow-template=wordcount-template \ --step-id=count \ --jar=file:///usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar \ --region=us-central1 \ -- wordcount gs://input-bucket gs://output-bucket-name/wordcount-output
-
Geben Sie output-bucket-name an, bevor Sie den Befehl ausführen. Die Funktion stellt den Eingabe-Bucket bereit.
Nachdem Sie den Namen des Ausgabe-Buckets eingegeben haben, sollte das Argument des Ausgabe-Buckets so lauten:
- Führen Sie den Workflow mit einem verwalteten Einzelknoten aus. Dataproc erstellt den Cluster, führt den Workflow aus und löscht den Cluster, wenn der Workflow abgeschlossen ist.
gcloud dataproc workflow-templates set-managed-cluster wordcount-template \ --cluster-name=wordcount \ --single-node \ --region=us-central1 - Klicken Sie in der Google Cloud Console auf der Dataproc-Seite Workflows auf den Namen
wordcount-template, um die Seite Workflow-Vorlagendetails zu öffnen. Bestätigen Sie die Wordcount-template-Attribute.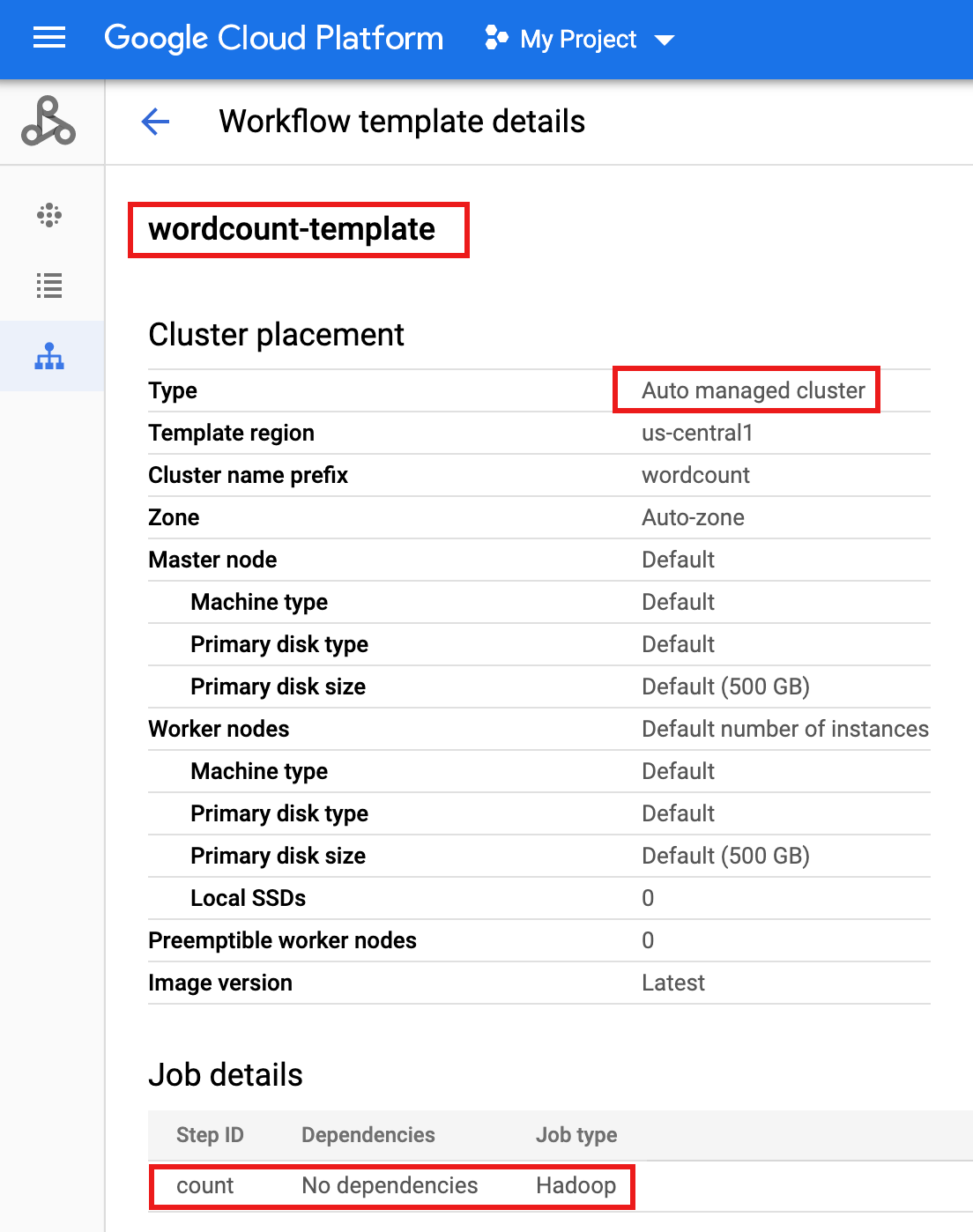
Workflow-Vorlage parametrisieren
Parametrisieren Sie die Eingabe-Bucket-Variable, die an die Workflow-Vorlage übergeben werden soll.
- Exportieren Sie die Workflow-Vorlage zur Parametrisierung in eine
wordcount.yaml-Textdatei.gcloud dataproc workflow-templates export wordcount-template \ --destination=wordcount.yaml \ --region=us-central1
- Öffnen Sie in einem Texteditor
wordcount.yamlund fügen Sie am Ende der YAML-Datei einenparameters-Block hinzu, damit der Cloud Storage-INPUT_BUCKET_URI alsargs[1]an die Wordcount-Binärdatei übergeben werden kann, wenn der Workflow ausgelöst wird.Unten sehen Sie ein Beispiel für eine exportierte YAML-Datei. Sie haben zwei Möglichkeiten, Ihre Vorlage zu aktualisieren:
- Kopieren Sie dann die gesamte Datei und fügen Sie sie ein, um die exportierte Datei
wordcount.yamlzu ersetzen, nachdem Sie your-output_bucket durch den Namen des Ausgabe-Buckets ersetzt haben, ODER - Kopieren Sie den Abschnitt
parametersund fügen Sie ihn an das Ende der exportiertenwordcount.yaml-Datei ein.
jobs: - hadoopJob: args: - wordcount - gs://input-bucket - gs://your-output-bucket/wordcount-output mainJarFileUri: file:///usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar stepId: count placement: managedCluster: clusterName: wordcount config: softwareConfig: properties: dataproc:dataproc.allow.zero.workers: 'true' parameters: - name: INPUT_BUCKET_URI description: wordcount input bucket URI fields: - jobs['count'].hadoopJob.args[1] - Kopieren Sie dann die gesamte Datei und fügen Sie sie ein, um die exportierte Datei
- Importieren Sie die parametrisierte
wordcount.yaml-Textdatei. Geben Sie "Y" ein, wenn Sie aufgefordert werden, die Vorlage zu überschreiben.gcloud dataproc workflow-templates import wordcount-template \ --source=wordcount.yaml \ --region=us-central1
Cloud Functions-Funktion erstellen
Öffnen Sie in derGoogle Cloud -Konsole die Seite Cloud Run-Funktionen und klicken Sie auf FUNKTION ERSTELLEN.
Geben Sie auf der Seite Funktion erstellen die folgenden Informationen ein oder wählen Sie sie aus:
- Name: Wortzahl
- Zugewiesener Speicher:Behalten Sie die Standardauswahl bei.
- Trigger:
- cl
- Ereignistyp: Abschluss/Erstellen
- Bucket: Wählen Sie Ihren Eingabe-Bucket aus (siehe Cloud Storage-Bucket im Projekt erstellen). Wenn Sie diesem Bucket eine Datei hinzufügen, löst die Funktion den Workflow aus. Der Workflow führt die Wordcount-Anwendung aus, mit der alle Textdateien im Bucket verarbeitet werden.
Quellcode:
- Inline-Editor
- Laufzeit: Node.js 8
- Tab
INDEX.JS: Ersetzen Sie das Standard-Code-Snippet durch den folgenden Code und bearbeiten Sie die Zeileconst projectId, um Ihre -your-project-id- (ohne einen voran- oder nachgestellten "-") anzugeben.
const dataproc = require('@google-cloud/dataproc').v1; exports.startWorkflow = (data) => { const projectId = '-your-project-id-' const region = 'us-central1' const workflowTemplate = 'wordcount-template' const client = new dataproc.WorkflowTemplateServiceClient({ apiEndpoint: `${region}-dataproc.googleapis.com`, }); const file = data; console.log("Event: ", file); const inputBucketUri = `gs://${file.bucket}/${file.name}`; const request = { name: client.projectRegionWorkflowTemplatePath(projectId, region, workflowTemplate), parameters: {"INPUT_BUCKET_URI": inputBucketUri} }; client.instantiateWorkflowTemplate(request) .then(responses => { console.log("Launched Dataproc Workflow:", responses[1]); }) .catch(err => { console.error(err); }); };- Tab
PACKAGE.JSON: Ersetzen Sie das Standard-Code-Snippet durch den folgenden Code.
{ "name": "dataproc-workflow", "version": "1.0.0", "dependencies":{ "@google-cloud/dataproc": ">=1.0.0"} }- Auszuführende Funktion: Eingabe: "startWorkflow".
Klicken Sie auf ERSTELLEN.
Funktion testen
Kopieren Sie die öffentliche Datei
rose.txtin Ihren Bucket, um die Funktion auszulösen. Fügen Sie in den Befehl your-input-bucket-name (den Bucket, der zum Auslösen der Funktion verwendet wird) ein.gcloud storage cp gs://pub/shakespeare/rose.txt gs://your-input-bucket-name
Warten Sie 30 Sekunden und führen Sie dann den folgenden Befehl aus, um zu prüfen, ob die Funktion erfolgreich ausgeführt wurde.
gcloud functions logs read wordcount
... Function execution took 1348 ms, finished with status: 'ok'
Wenn Sie die Funktionslogs von der Listenseite Funktionen in der Google Cloud -Console aus aufrufen möchten, klicken Sie auf den Funktionsnamen
wordcountund dann auf der Seite Funktionsdetails auf „LOGS ANZEIGEN“.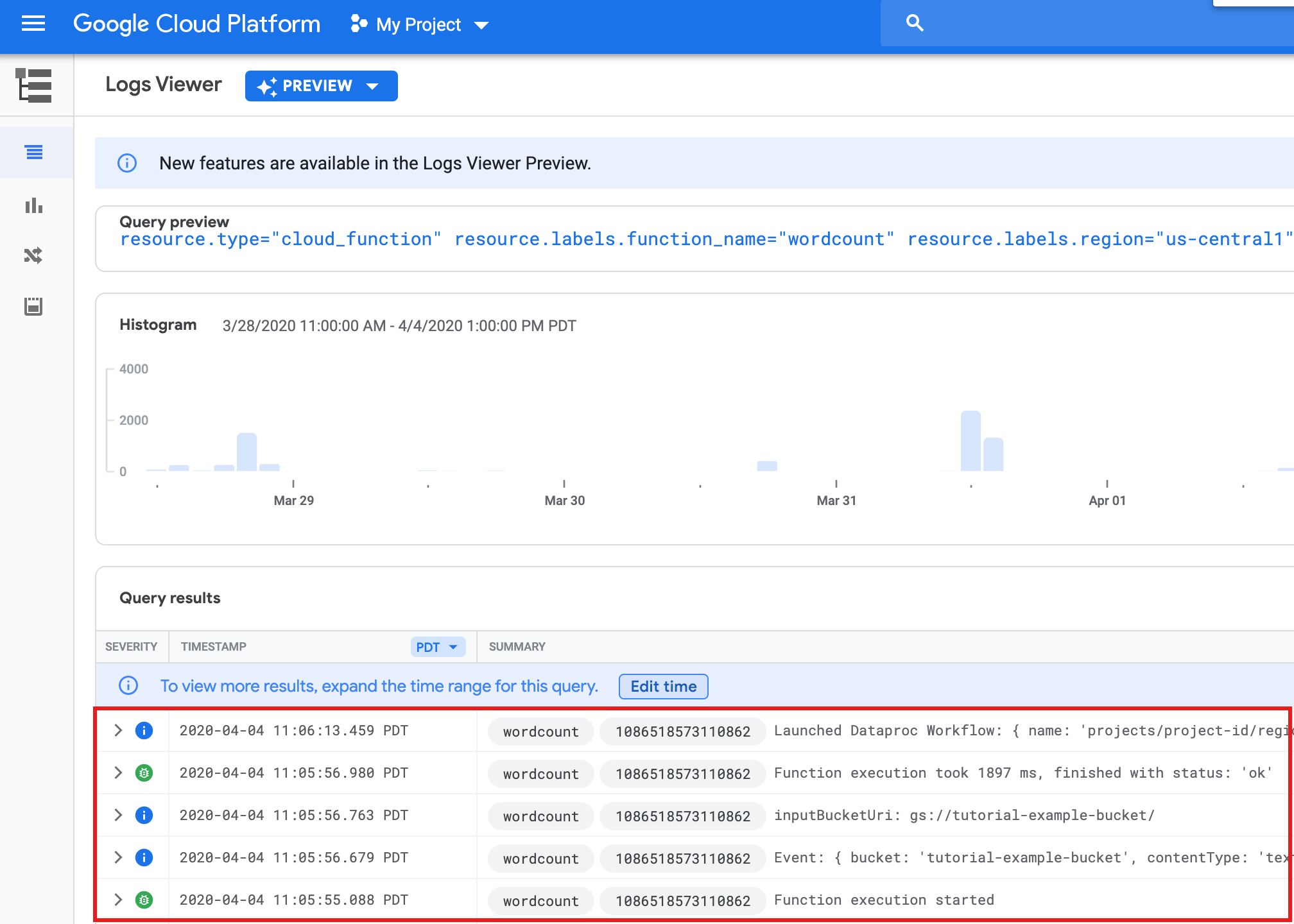
Sie können den Ordner
wordcount-outputin Ihrem Ausgabe-Bucket auf der Seite Storage-Browser in derGoogle Cloud Console ansehen.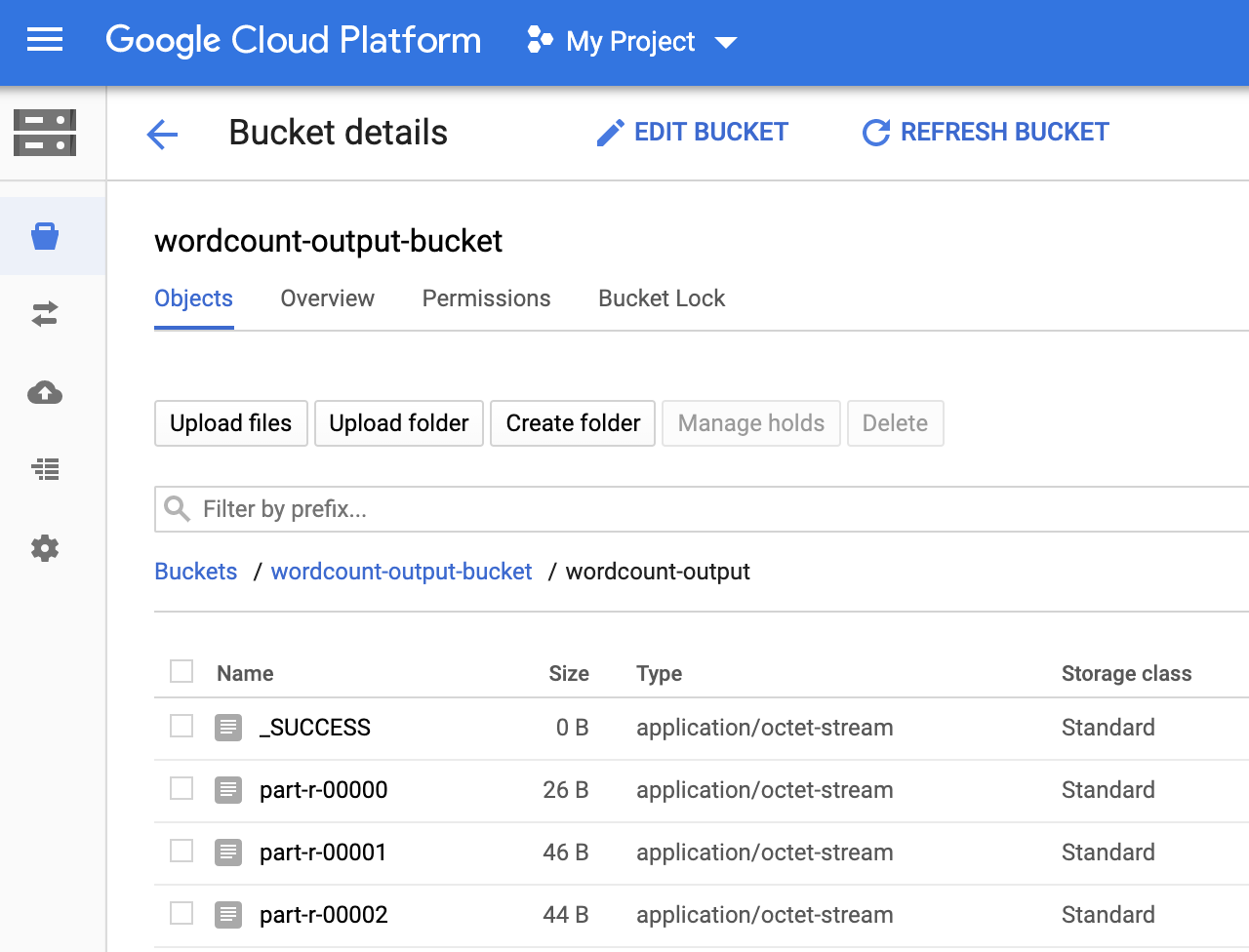
Nach Abschluss des Workflows bleiben die Jobdetails in derGoogle Cloud -Konsole erhalten. Klicken Sie auf den
count...-Job, der auf der Dataproc-Seite Jobs aufgeführt ist, um Details zum Workflow-Job anzuzeigen.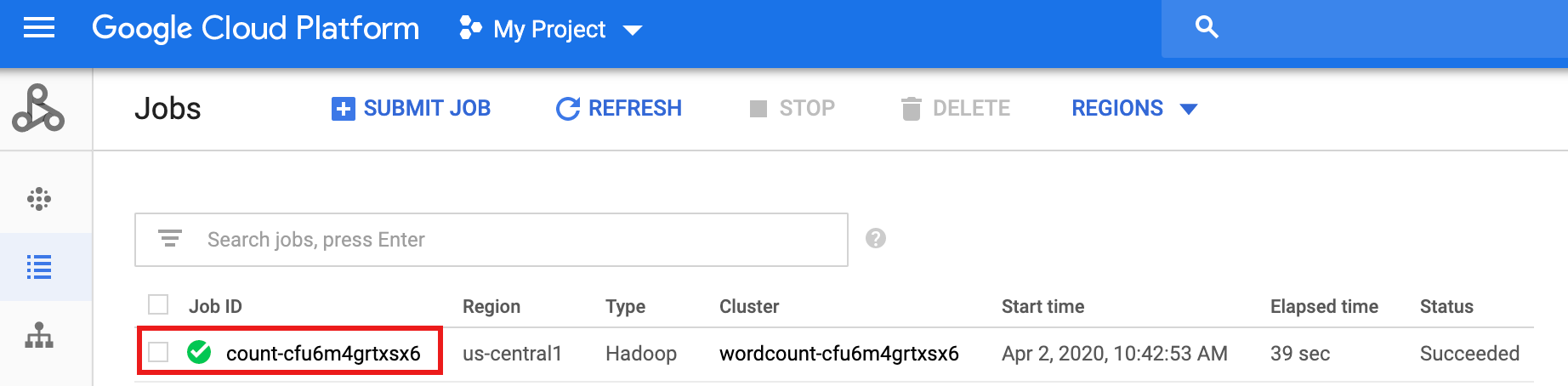
Bereinigen
Der Workflow in dieser Anleitung löscht den verwalteten Cluster, wenn der Workflow abgeschlossen ist. Sie können andere Ressourcen aus dieser Anleitung löschen, um wiederkehrende Kosten zu vermeiden.
Projekt löschen
- Wechseln Sie in der Google Cloud -Console zur Seite Ressourcen verwalten.
- Wählen Sie in der Projektliste das Projekt aus, das Sie löschen möchten, und klicken Sie dann auf Löschen.
- Geben Sie im Dialogfeld die Projekt-ID ein und klicken Sie auf Shut down (Beenden), um das Projekt zu löschen.
Cloud Storage-Buckets löschen
- Wechseln Sie in der Google Cloud Console unter „Cloud Storage“ zur Seite Buckets.
- Klicken Sie auf das Kästchen neben dem Bucket, der gelöscht werden soll.
- Klicken Sie zum Löschen des Buckets auf Löschen und folgen Sie der Anleitung.
Workflow-Vorlage löschen
gcloud dataproc workflow-templates delete wordcount-template \ --region=us-central1
Cloud Functions-Funktion löschen
Öffnen Sie in der Google Cloud Console die Seite Cloud Run-Funktionen, klicken Sie auf das Kästchen links neben der Funktion wordcount und klicken Sie dann auf Löschen.
Nächste Schritte
- Weitere Informationen finden Sie unter Übersicht über Dataproc-Workflow-Vorlagen.
- Weitere Informationen finden Sie unter Lösungen für die Workflow-Planung.