
Avant de commencer
Si ce n'est pas déjà fait, configurez un projet Google Cloud et deux (2) buckets Cloud Storage.
Configurer votre projet
- Connectez-vous à votre compte Google Cloud . Si vous débutez sur Google Cloud, créez un compte pour évaluer les performances de nos produits en conditions réelles. Les nouveaux clients bénéficient également de 300 $de crédits sans frais pour exécuter, tester et déployer des charges de travail.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc, Compute Engine, Cloud Storage, and Cloud Run functions APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
Installez la Google Cloud CLI.
-
Si vous utilisez un fournisseur d'identité (IdP) externe, vous devez d'abord vous connecter à la gcloud CLI avec votre identité fédérée.
-
Pour initialiser la gcloud CLI, exécutez la commande suivante :
gcloud init -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc, Compute Engine, Cloud Storage, and Cloud Run functions APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
Installez la Google Cloud CLI.
-
Si vous utilisez un fournisseur d'identité (IdP) externe, vous devez d'abord vous connecter à la gcloud CLI avec votre identité fédérée.
-
Pour initialiser la gcloud CLI, exécutez la commande suivante :
gcloud init
Créer ou utiliser deux buckets Cloud Storage dans votre projet
Vous aurez besoin de deux buckets Cloud Storage dans votre projet : un pour les fichiers d'entrée et un pour les fichiers de sortie.
- Dans la console Google Cloud , accédez à la page Buckets Cloud Storage.
- Cliquez sur Créer.
- Sur la page Créer un bucket, saisissez les informations concernant votre bucket. Pour passer à l'étape suivante, cliquez sur Continuer.
-
Dans la section Premiers pas, procédez comme suit :
- Saisissez un nom unique qui répond aux exigences relatives aux noms des buckets.
- Pour ajouter une étiquette de bucket, développez la section Étiquettes (), cliquez sur add_box
Ajouter une étiquette, puis spécifiez un élément
keyetvaluepour votre étiquette.
-
Dans la section Choisir l'emplacement de stockage de vos données, procédez comme suit :
- Sélectionnez un type d'emplacement.
- Choisissez un emplacement où les données de votre bucket seront stockées de manière permanente dans le menu déroulant Type d'emplacement.
- Si vous sélectionnez le type d'emplacement birégional, vous pouvez également choisir d'activer la réplication turbo à l'aide de la case à cocher correspondante.
- Pour configurer la réplication entre buckets, sélectionnez Ajouter une réplication entre buckets via le service de transfert de stockage et suivez ces étapes :
Configurer la réplication entre buckets
- Dans le menu Bucket, sélectionnez un bucket.
Dans la section Paramètres de réplication, cliquez sur Configurer pour configurer les paramètres du job de réplication.
Le volet Configurer la réplication entre buckets s'affiche.
- Pour filtrer les objets à répliquer en fonction du préfixe de leur nom, saisissez le préfixe avec lequel vous souhaitez inclure ou exclure des objets, puis cliquez sur Ajouter un préfixe.
- Pour définir une classe de stockage pour les objets répliqués, sélectionnez-en une dans le menu Classe de stockage. Si vous ignorez cette étape, les objets répliqués utiliseront la classe de stockage par défaut du bucket de destination.
- Cliquez sur OK.
-
Dans la section Choisir comment stocker vos données, procédez comme suit :
- Sélectionnez une classe de stockage par défaut pour le bucket ou classe automatique pour gérer automatiquement les classes de stockage des données de votre bucket.
- Pour activer l'espace de noms hiérarchique, dans la section Optimiser l'espace de stockage pour les charges de travail utilisant beaucoup de données, sélectionnez Activer l'espace de noms hiérarchique sur ce bucket.
- Dans la section Choisir comment contrôler l'accès aux objets, indiquez si votre bucket applique ou non la protection contre l'accès public et sélectionnez une méthode de contrôle des accès pour les objets de votre bucket.
-
Dans la section Choisir comment protéger les données d'objet, procédez comme suit :
- Sous Protection des données, sélectionnez les options que vous souhaitez définir pour votre bucket.
- Pour activer la suppression réversible, cochez la case Règle de suppression réversible (pour la récupération de données), puis spécifiez le nombre de jours pendant lesquels vous souhaitez conserver les objets après leur suppression.
- Pour configurer la gestion des versions d'objets, cochez la case Gestion des versions des objets (pour le contrôle des versions), puis spécifiez le nombre maximal de versions par objet et le nombre de jours après lesquels les versions obsolètes expirent.
- Pour activer la règle de conservation sur les objets et les buckets, cochez la case Conservation (pour la conformité), puis procédez comme suit :
- Pour activer le verrou de conservation des objets, cochez la case Activer la conservation des objets.
- Pour activer le verrou de bucket, cochez la case Définir une règle de conservation du bucket, puis choisissez une unité de temps et une durée pour votre période de conservation.
- Pour choisir comment vos données d'objet seront chiffrées, développez la section Chiffrement des données (), puis sélectionnez une méthode de chiffrement des données.
- Sous Protection des données, sélectionnez les options que vous souhaitez définir pour votre bucket.
-
Dans la section Premiers pas, procédez comme suit :
- Cliquez sur Créer.
Créer un modèle de flux de travail
Pour créer et définir un modèle de workflow, copiez et exécutez les commandes suivantes dans une fenêtre de terminal local ou dans Cloud Shell.
- Créez le modèle de workflow.
gcloud dataproc workflow-templates create wordcount-template \ --region=us-central1
- Ajoutez la tâche WordCount au modèle de workflow.
-
Spécifiez le nom output-bucket-name avant d'exécuter la commande (votre fonction fournira le bucket d'entrée).
Une fois le nom du bucket de sortie inséré, l'argument de ce bucket doit se présenter comme suit :
gs://your-output-bucket/wordcount-output". -
L'ID de l'étape "count" est obligatoire et identifie la tâche Hadoop ajoutée.
gcloud dataproc workflow-templates add-job hadoop \ --workflow-template=wordcount-template \ --step-id=count \ --jar=file:///usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar \ --region=us-central1 \ -- wordcount gs://input-bucket gs://output-bucket-name/wordcount-output
-
Spécifiez le nom output-bucket-name avant d'exécuter la commande (votre fonction fournira le bucket d'entrée).
Une fois le nom du bucket de sortie inséré, l'argument de ce bucket doit se présenter comme suit :
- Utilisez un cluster géré à nœud unique pour exécuter le workflow. Managed Service for Apache Spark crée le cluster, y exécute le workflow, puis le supprime une fois le workflow terminé.
gcloud dataproc workflow-templates set-managed-cluster wordcount-template \ --cluster-name=wordcount \ --single-node \ --region=us-central1 - Cliquez sur le nom
wordcount-templatesur la page Workflows Managed Service for Apache Spark dans la console Google Cloud pour ouvrir la page Détails du modèle de workflow. Confirmez les attributs du modèle Wordcount.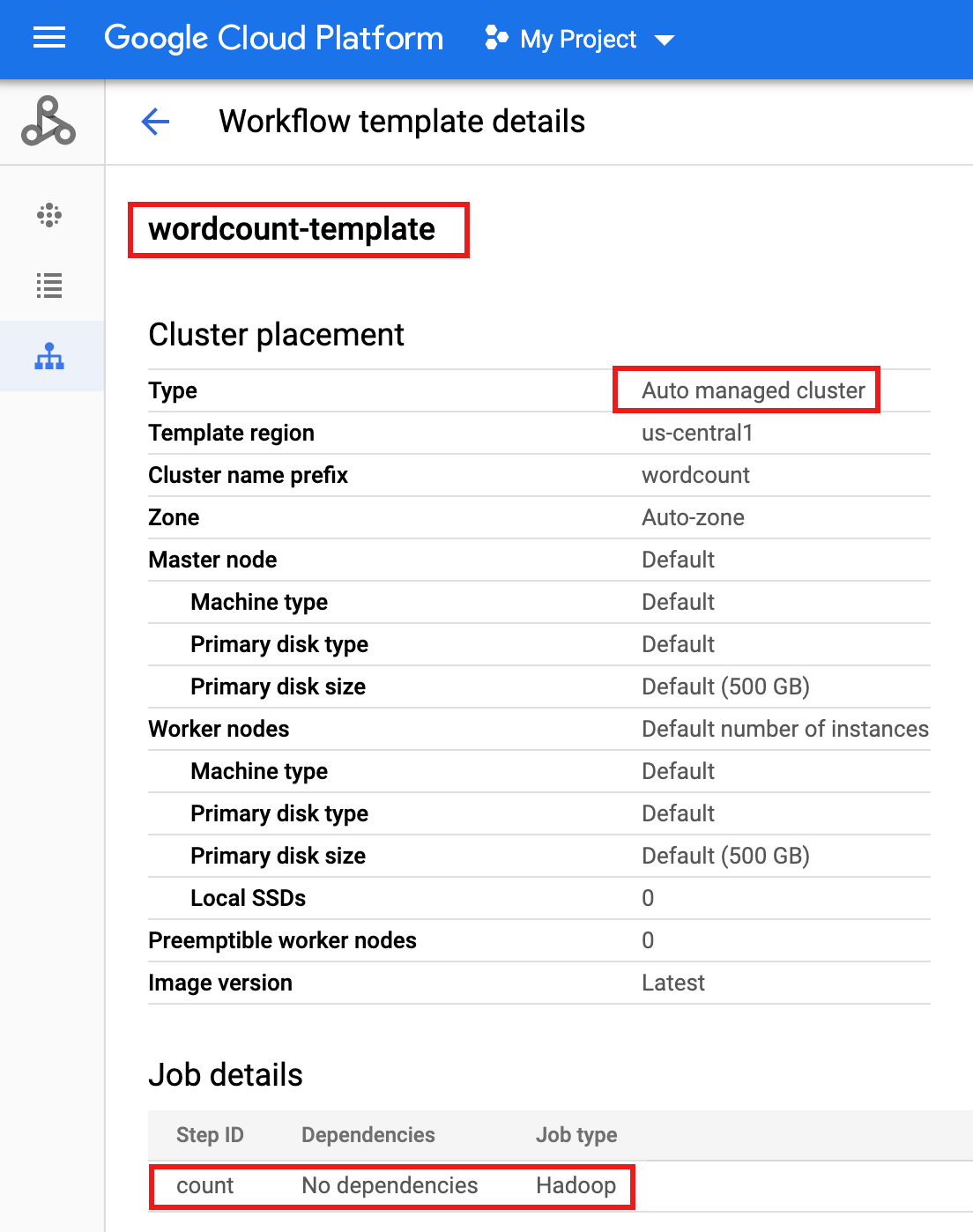
Paramétrer le modèle de workflow
Paramétrez la variable du bucket d'entrée à transmettre au modèle de workflow.
- Exportez le modèle de workflow dans un fichier texte
wordcount.yamlpour le paramétrage.gcloud dataproc workflow-templates export wordcount-template \ --destination=wordcount.yaml \ --region=us-central1
- À l'aide d'un éditeur de texte, ouvrez le fichier
wordcount.yaml, puis ajoutez un blocparametersà la fin du fichier YAML pour que l'élément "INPUT_BUCKET_URI" Cloud Storage puisse être transmis en tant queargs[1]au fichier binaire WordCount lors du déclenchement du workflow.Vous trouverez ci-dessous un exemple de fichier YAML exporté. Vous pouvez adopter l'une des deux méthodes suivantes pour mettre à jour votre modèle :
- Copiez, puis collez l'intégralité du fichier pour remplacer le fichier
wordcount.yamlexporté après avoir remplacé your-output_bucket par le nom du bucket de sortie. OU - Copiez, puis collez uniquement la section
parametersà la fin du fichierwordcount.yamlexporté.
jobs: - hadoopJob: args: - wordcount - gs://input-bucket - gs://your-output-bucket/wordcount-output mainJarFileUri: file:///usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar stepId: count placement: managedCluster: clusterName: wordcount config: softwareConfig: properties: dataproc:dataproc.allow.zero.workers: 'true' parameters: - name: INPUT_BUCKET_URI description: wordcount input bucket URI fields: - jobs['count'].hadoopJob.args[1] - Copiez, puis collez l'intégralité du fichier pour remplacer le fichier
- Importez le fichier texte
wordcount.yamlparamétré. Saisissez "Y" (Oui) lorsque vous êtes invité à écraser le modèle.gcloud dataproc workflow-templates import wordcount-template \ --source=wordcount.yaml \ --region=us-central1
Créer une fonction Cloud
Ouvrez la page Cloud Run Functions dans la consoleGoogle Cloud , puis cliquez sur CRÉER UNE FONCTION.
Sur la page Créer une fonction, saisissez ou sélectionnez les informations suivantes :
- Nom : wordcount
- Mémoire allouée : conservez la valeur sélectionnée par défaut.
- Déclencheur :
- Cloud Storage
- Type d'événement : finaliser/créer
- Bucket : sélectionnez votre bucket d'entrée (consultez la section Créer un bucket Cloud Storage dans votre projet). Lorsqu'un fichier est ajouté à ce bucket, la fonction déclenche le workflow. Le workflow exécutera l'application WordCount, qui traitera tous les fichiers texte du bucket.
Code source :
- Éditeur intégré
- runtime : nodej.js 8
- Onglet
INDEX.JS: remplacez l'extrait de code par défaut par le code suivant, puis modifiez la ligneconst projectIdpour fournir -your-project-id- (sans ajouter "-" au début ou à la fin).
const dataproc = require('@google-cloud/dataproc').v1; exports.startWorkflow = (data) => { const projectId = '-your-project-id-' const region = 'us-central1' const workflowTemplate = 'wordcount-template' const client = new dataproc.WorkflowTemplateServiceClient({ apiEndpoint: `${region}-dataproc.googleapis.com`, }); const file = data; console.log("Event: ", file); const inputBucketUri = `gs://${file.bucket}/${file.name}`; const request = { name: client.projectRegionWorkflowTemplatePath(projectId, region, workflowTemplate), parameters: {"INPUT_BUCKET_URI": inputBucketUri} }; client.instantiateWorkflowTemplate(request) .then(responses => { console.log("Launched Dataproc Workflow:", responses[1]); }) .catch(err => { console.error(err); }); };- Onglet
PACKAGE.JSON: remplacez l'extrait de code par défaut par le code suivant.
{ "name": "dataproc-workflow", "version": "1.0.0", "dependencies":{ "@google-cloud/dataproc": ">=1.0.0"} }- Fonction à exécuter : insérer "startWorkflow".
Cliquez sur CREATE (Créer).
Tester votre fonction
Copiez le fichier public
rose.txtdans votre bucket pour déclencher la fonction. Insérez your-input-bucket-name (le bucket utilisé pour déclencher votre fonction) dans la commande.gcloud storage cp gs://pub/shakespeare/rose.txt gs://your-input-bucket-name
Patientez 30 secondes, puis exécutez la commande suivante pour vérifier que la fonction s'est bien exécutée.
gcloud functions logs read wordcount
... Function execution took 1348 ms, finished with status: 'ok'
Pour afficher les journaux de la fonction à partir de la page de liste Fonctions de la console Google Cloud , cliquez sur le nom de la fonction
wordcount, puis sur "AFFICHER LES JOURNAUX" sur la page Détails de la fonction.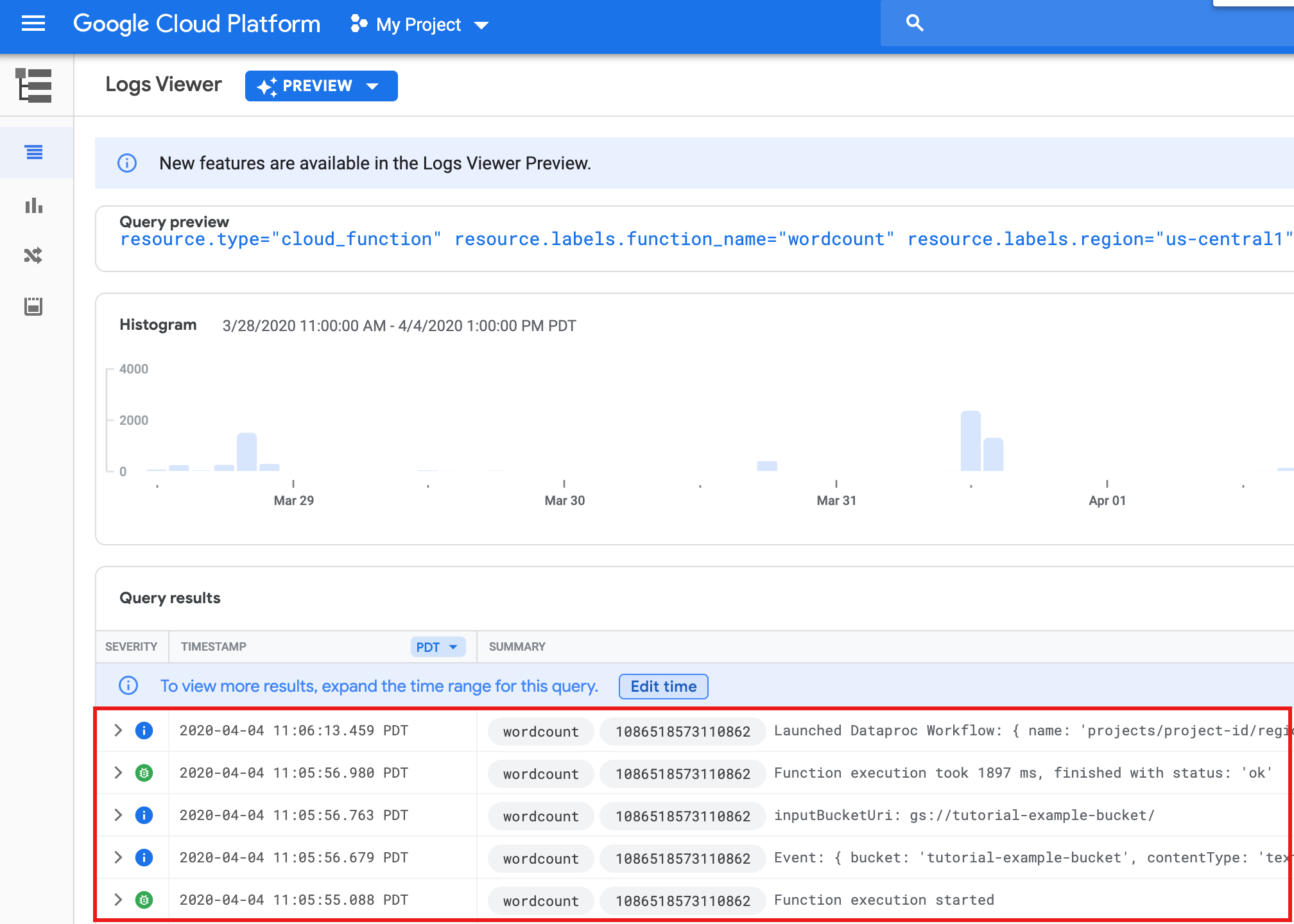
Vous pouvez afficher le dossier
wordcount-outputdans votre bucket de sortie à partir de la page Navigateur Storage de la consoleGoogle Cloud .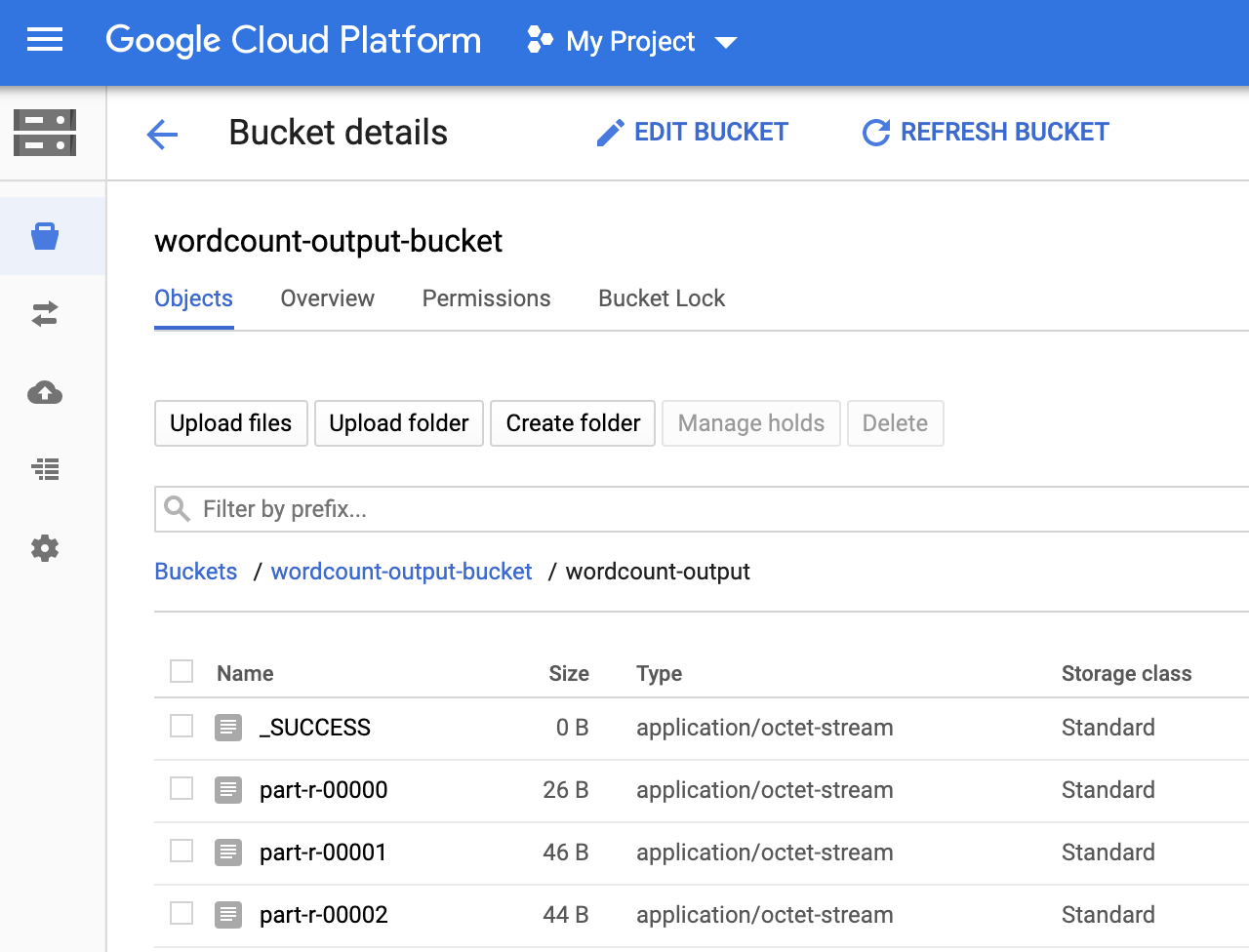
Une fois le workflow terminé, les détails de la tâche sont conservés dans la consoleGoogle Cloud . Cliquez sur le job
count...listé sur la page Jobs (Jobs) de Managed Service for Apache Spark pour afficher les détails du job de workflow.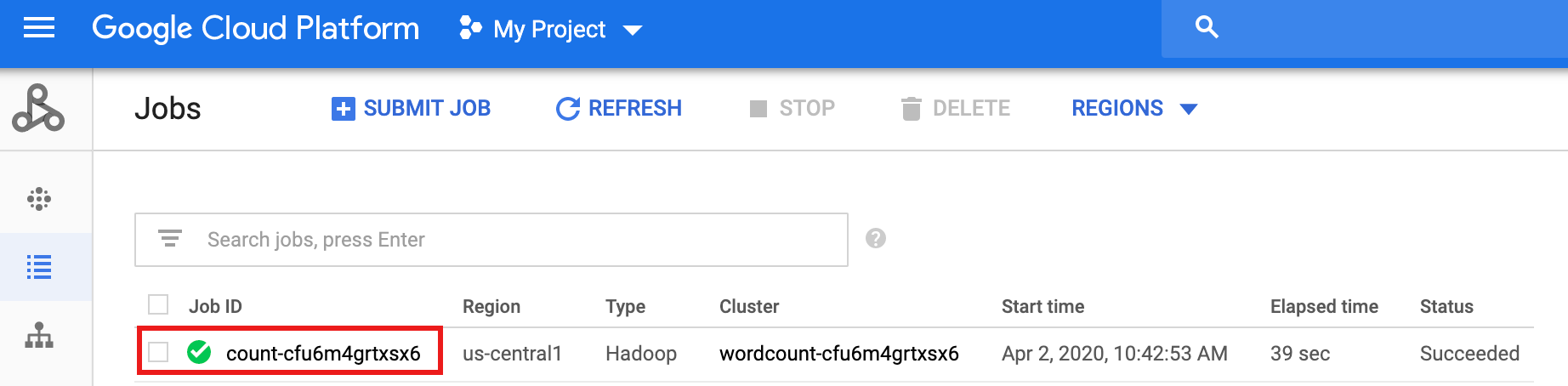
Effectuer un nettoyage
Une fois terminé, le workflow de ce tutoriel supprime son cluster géré. Pour éviter les frais récurrents, vous pouvez supprimer d'autres ressources associées à ce tutoriel.
Supprimer un projet
- Dans la console Google Cloud , accédez à la page Gérer les ressources.
- Dans la liste des projets, sélectionnez le projet que vous souhaitez supprimer, puis cliquez sur Supprimer.
- Dans la boîte de dialogue, saisissez l'ID du projet, puis cliquez sur Arrêter pour supprimer le projet.
Supprimer les buckets Cloud Storage
- Dans la console Google Cloud , accédez à la page Buckets de Cloud Storage.
- Cochez la case correspondant au bucket que vous souhaitez supprimer.
- Pour supprimer le bucket, cliquez sur Supprimer , puis suivez les instructions.
Supprimer votre modèle de workflow
gcloud dataproc workflow-templates delete wordcount-template \ --region=us-central1
Supprimer votre fonction Cloud
Ouvrez la page Cloud Run Functions dans la console Google Cloud , cochez la case à gauche de la fonction wordcount, puis cliquez sur Supprimer.
Étapes suivantes
- Consultez la présentation des modèles de workflow Managed Service pour Apache Spark.
- Consultez Solutions de planification des workflows.