
Trino (sebelumnya Presto) adalah mesin kueri SQL terdistribusi yang dirancang untuk membuat kueri set data besar yang didistribusikan melalui satu atau beberapa sumber data heterogen. Trino dapat membuat kueri Hive, MySQL, Kafka, dan sumber data lainnya melalui konektor. Tutorial ini menunjukkan kepada Anda cara untuk:
- Menginstal layanan Trino di cluster Managed Service for Apache Spark
- Membuat kueri data publik dari klien Trino yang diinstal di komputer lokal Anda yang berkomunikasi dengan layanan Trino di cluster Anda
- Jalankan kueri dari aplikasi Java yang berkomunikasi dengan layanan Trino di cluster Anda melalui driver JDBC Java Trino.
Tujuan
- Mengekstrak data dari BigQuery
- Muat data ke Cloud Storage sebagai file CSV
- Transformasikan data:
- Mengekspos data sebagai tabel eksternal Hive agar data dapat dikueri oleh Trino
- Konversi data dari format CSV ke format Parquet untuk membuat kueri lebih cepat
Biaya
Dalam dokumen ini, Anda akan menggunakan komponen Google Cloudyang dapat ditagih berikut:
Untuk membuat perkiraan biaya berdasarkan proyeksi penggunaan Anda,
gunakan kalkulator harga.
Sebelum memulai
Jika belum melakukannya, buat Google Cloud project dan bucket Cloud Storage untuk menyimpan data yang digunakan dalam tutorial ini. 1. Menyiapkan project Anda- Login ke akun Google Cloud Anda. Jika Anda baru menggunakan Google Cloud, buat akun untuk mengevaluasi performa produk kami dalam skenario dunia nyata. Pelanggan baru juga mendapatkan kredit gratis senilai $300 untuk menjalankan, menguji, dan men-deploy workload.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc, Compute Engine, Cloud Storage, and BigQuery APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
Instal Google Cloud CLI.
-
Jika Anda menggunakan penyedia identitas (IdP) eksternal, Anda harus login ke gcloud CLI dengan identitas gabungan Anda terlebih dahulu.
-
Untuk melakukan inisialisasi gcloud CLI, jalankan perintah berikut:
gcloud init -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc, Compute Engine, Cloud Storage, and BigQuery APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
Instal Google Cloud CLI.
-
Jika Anda menggunakan penyedia identitas (IdP) eksternal, Anda harus login ke gcloud CLI dengan identitas gabungan Anda terlebih dahulu.
-
Untuk melakukan inisialisasi gcloud CLI, jalankan perintah berikut:
gcloud init
- Di konsol Google Cloud , buka halaman Buckets Cloud Storage.
- Klik Create.
- Di halaman Buat bucket, masukkan informasi bucket Anda. Untuk melanjutkan ke
langkah berikutnya, klik Lanjutkan.
-
Di bagian Mulai, lakukan tindakan berikut:
- Masukkan nama yang unik secara global yang memenuhi persyaratan penamaan bucket.
- Untuk menambahkan
label bucket,
luaskan bagian Label (),
klik add_box
Tambahkan label, lalu tentukan
keydanvalueuntuk label Anda.
-
Di bagian Pilih tempat untuk menyimpan data Anda, lakukan tindakan berikut:
- Pilih Jenis lokasi.
- Pilih lokasi tempat data bucket Anda disimpan secara permanen dari menu drop-down Location type.
- Jika memilih jenis lokasi dual-region, Anda juga dapat memilih untuk mengaktifkan replikasi turbo dengan menggunakan kotak centang yang relevan.
- Untuk menyiapkan replikasi lintas bucket, pilih
Add cross-bucket replication via Storage Transfer Service dan
ikuti langkah-langkah berikut:
Menyiapkan replikasi lintas bucket
- Di menu Bucket, pilih bucket.
Di bagian Setelan replikasi, klik Konfigurasi untuk mengonfigurasi setelan bagi tugas replikasi.
Panel Konfigurasi replikasi lintas bucket akan muncul.
- Untuk memfilter objek yang akan direplikasi menurut awalan nama objek, masukkan awalan yang ingin Anda sertakan atau kecualikan objeknya, lalu klik Tambahkan awalan.
- Untuk menetapkan kelas penyimpanan bagi objek yang direplikasi, pilih kelas penyimpanan dari menu Kelas penyimpanan. Jika Anda melewati langkah ini, objek yang direplikasi akan menggunakan kelas penyimpanan bucket tujuan secara default.
- Klik Done.
-
Di bagian Choose how to store your data, lakukan tindakan berikut:
- Pilih kelas penyimpanan default untuk bucket atau Autoclass untuk pengelolaan kelas penyimpanan otomatis untuk data bucket Anda.
- Untuk mengaktifkan namespace hierarkis, di bagian Optimalkan penyimpanan untuk beban kerja intensif data, pilih Aktifkan namespace hierarkis di bucket ini.
- Di bagian Pilih cara mengontrol akses ke objek, pilih apakah bucket Anda menerapkan pencegahan akses publik atau tidak, lalu pilih metode kontrol akses untuk objek bucket Anda.
-
Di bagian Pilih cara melindungi data objek, lakukan
tindakan berikut:
- Pilih salah satu opsi di bagian Perlindungan data yang ingin Anda tetapkan untuk bucket Anda.
- Untuk mengaktifkan penghapusan sementara, klik kotak centang Kebijakan penghapusan sementara (Untuk pemulihan data), dan tentukan jumlah hari Anda ingin mempertahankan objek setelah penghapusan.
- Untuk menyetel Pembuatan Versi Objek, klik kotak centang Pembuatan versi objek (Untuk kontrol versi), dan tentukan jumlah maksimum versi per objek dan jumlah hari setelah versi lama berakhir.
- Untuk mengaktifkan kebijakan retensi pada objek dan bucket, klik kotak centang Retensi (Untuk kepatuhan), lalu lakukan hal berikut:
- Untuk mengaktifkan Penguncian Retensi Objek, centang kotak Aktifkan retensi objek.
- Untuk mengaktifkan Bucket Lock, centang kotak Setel kebijakan retensi bucket, lalu pilih satuan waktu dan durasi untuk periode retensi data Anda.
- Untuk memilih cara mengenkripsi data objek Anda, luaskan bagian Enkripsi data (), lalu pilih metode Enkripsi data.
- Pilih salah satu opsi di bagian Perlindungan data yang ingin Anda tetapkan untuk bucket Anda.
-
Di bagian Mulai, lakukan tindakan berikut:
- Klik Create.
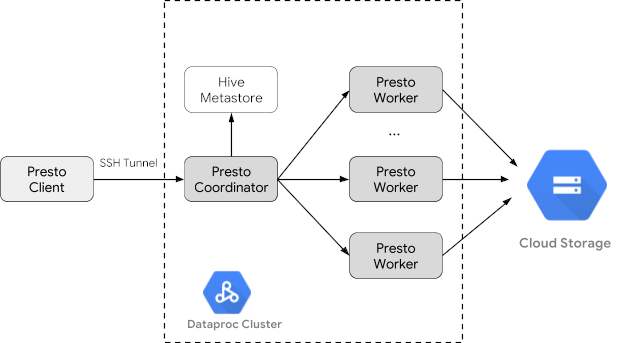
Membuat cluster Managed Service untuk Apache Spark
Buat cluster Managed Service for Apache Spark menggunakan flag optional-components
(tersedia di versi image 2.1 dan yang lebih baru) untuk menginstal
komponen opsional Trino di
cluster dan flag enable-component-gateway untuk mengaktifkan
Component Gateway agar Anda dapat mengakses UI Web Trino dari konsol Google Cloud .
- Tetapkan variabel lingkungan:
- PROJECT: project ID Anda
- BUCKET_NAME: nama bucket Cloud Storage yang Anda buat di Sebelum memulai
- REGION: region tempat cluster yang digunakan dalam tutorial ini akan dibuat, misalnya, "us-west1"
- PEKERJA: 3 - 5 pekerja direkomendasikan untuk tutorial ini
export PROJECT=project-id export WORKERS=number export REGION=region export BUCKET_NAME=bucket-name
- Jalankan Google Cloud CLI di komputer lokal Anda untuk
membuat cluster.
gcloud beta dataproc clusters create trino-cluster \ --project=${PROJECT} \ --region=${REGION} \ --num-workers=${WORKERS} \ --scopes=cloud-platform \ --optional-components=TRINO \ --image-version=2.1 \ --enable-component-gateway
Menyiapkan data
Ekspor set data bigquery-public-data chicago_taxi_trips
ke Cloud Storage sebagai file CSV, lalu buat tabel eksternal Hive
untuk mereferensikan data.
- Di mesin lokal Anda, jalankan perintah berikut untuk mengimpor data taksi dari
BigQuery sebagai file CSV tanpa header ke bucket Cloud Storage
yang Anda buat di Sebelum memulai.
bq --location=us extract --destination_format=CSV \ --field_delimiter=',' --print_header=false \ "bigquery-public-data:chicago_taxi_trips.taxi_trips" \ gs://${BUCKET_NAME}/chicago_taxi_trips/csv/shard-*.csv - Buat tabel eksternal Hive yang didukung oleh file CSV dan Parquet di bucket Cloud Storage Anda.
- Buat tabel eksternal Hive
chicago_taxi_trips_csv.gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute " CREATE EXTERNAL TABLE chicago_taxi_trips_csv( unique_key STRING, taxi_id STRING, trip_start_timestamp TIMESTAMP, trip_end_timestamp TIMESTAMP, trip_seconds INT, trip_miles FLOAT, pickup_census_tract INT, dropoff_census_tract INT, pickup_community_area INT, dropoff_community_area INT, fare FLOAT, tips FLOAT, tolls FLOAT, extras FLOAT, trip_total FLOAT, payment_type STRING, company STRING, pickup_latitude FLOAT, pickup_longitude FLOAT, pickup_location STRING, dropoff_latitude FLOAT, dropoff_longitude FLOAT, dropoff_location STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE location 'gs://${BUCKET_NAME}/chicago_taxi_trips/csv/';" - Verifikasi pembuatan
tabel eksternal Hive.
gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute "SELECT COUNT(*) FROM chicago_taxi_trips_csv;" - Buat tabel eksternal Hive lain
chicago_taxi_trips_parquetdengan kolom yang sama, tetapi dengan data yang disimpan dalam format Parquet untuk performa kueri yang lebih baik.gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute " CREATE EXTERNAL TABLE chicago_taxi_trips_parquet( unique_key STRING, taxi_id STRING, trip_start_timestamp TIMESTAMP, trip_end_timestamp TIMESTAMP, trip_seconds INT, trip_miles FLOAT, pickup_census_tract INT, dropoff_census_tract INT, pickup_community_area INT, dropoff_community_area INT, fare FLOAT, tips FLOAT, tolls FLOAT, extras FLOAT, trip_total FLOAT, payment_type STRING, company STRING, pickup_latitude FLOAT, pickup_longitude FLOAT, pickup_location STRING, dropoff_latitude FLOAT, dropoff_longitude FLOAT, dropoff_location STRING) STORED AS PARQUET location 'gs://${BUCKET_NAME}/chicago_taxi_trips/parquet/';" - Muat data dari tabel CSV Hive ke
tabel Parquet Hive.
gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute " INSERT OVERWRITE TABLE chicago_taxi_trips_parquet SELECT * FROM chicago_taxi_trips_csv;" - Pastikan data dimuat dengan benar.
gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute "SELECT COUNT(*) FROM chicago_taxi_trips_parquet;"
- Buat tabel eksternal Hive
Menjalankan kueri
Anda dapat menjalankan kueri secara lokal dari Trino CLI atau dari aplikasi.
Kueri Trino CLI
Bagian ini menunjukkan cara mengkueri set data taksi Hive Parquet menggunakan Trino CLI.
- Jalankan perintah berikut di mesin lokal Anda untuk melakukan SSH ke node master cluster Anda. Terminal lokal akan berhenti merespons selama eksekusi perintah.
gcloud compute ssh trino-cluster-m
- Di jendela terminal SSH pada node master cluster Anda, jalankan
CLI Trino, yang terhubung ke server Trino yang berjalan di node
master.
trino --catalog hive --schema default
- Pada perintah
trino:default, pastikan Trino dapat menemukan tabel Hive.show tables;
Table ‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐ chicago_taxi_trips_csv chicago_taxi_trips_parquet (2 rows)
- Jalankan kueri dari perintah
trino:default, dan bandingkan performa kueri data Parquet versus CSV.- Kueri data Parquet
select count(*) from chicago_taxi_trips_parquet where trip_miles > 50;
_col0 ‐‐‐‐‐‐‐‐ 117957 (1 row)
Query 20180928_171735_00006_2sz8c, FINISHED, 3 nodes Splits: 308 total, 308 done (100.00%) 0:16 [113M rows, 297MB] [6.91M rows/s, 18.2MB/s] - Kueri data CSV
select count(*) from chicago_taxi_trips_csv where trip_miles > 50;
_col0 ‐‐‐‐‐‐‐‐ 117957 (1 row)
Query 20180928_171936_00009_2sz8c, FINISHED, 3 nodes Splits: 881 total, 881 done (100.00%) 0:47 [113M rows, 41.5GB] [2.42M rows/s, 911MB/s]
- Kueri data Parquet
Kueri aplikasi Java
Untuk menjalankan kueri dari aplikasi Java melalui driver JDBC Java Trino:
1. Download
driver JDBC Java Trino.
1. Tambahkan dependensi trino-jdbc di
Maven pom.xml.
<dependency> <groupId>io.trino</groupId> <artifactId>trino-jdbc</artifactId> <version>376</version> </dependency>
package dataproc.codelab.trino;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.Properties;
public class TrinoQuery {
private static final String URL = "jdbc:trino://trino-cluster-m:8080/hive/default";
private static final String SOCKS_PROXY = "localhost:1080";
private static final String USER = "user";
private static final String QUERY =
"select count(*) as count from chicago_taxi_trips_parquet where trip_miles > 50";
public static void main(String[] args) {
try {
Properties properties = new Properties();
properties.setProperty("user", USER);
properties.setProperty("socksProxy", SOCKS_PROXY);
Connection connection = DriverManager.getConnection(URL, properties);
try (Statement stmt = connection.createStatement()) {
ResultSet rs = stmt.executeQuery(QUERY);
while (rs.next()) {
int count = rs.getInt("count");
System.out.println("The number of long trips: " + count);
}
}
} catch (SQLException e) {
e.printStackTrace();
}
}
}Logging dan pemantauan
Logging
Log Trino berada di /var/log/trino/ pada node master dan worker cluster.
UI Web
Lihat Melihat dan Mengakses URL Component Gateway untuk membuka UI Web Trino yang berjalan di node master cluster di browser lokal Anda.
Pemantauan
Trino mengekspos informasi runtime cluster melalui tabel runtime.
Dalam sesi Trino (dari prompt trino:default),
jalankan kueri berikut untuk melihat data tabel runtime:
select * FROM system.runtime.nodes;
Pembersihan
Setelah menyelesaikan tutorial, Anda dapat membersihkan resource yang dibuat agar tidak lagi menggunakan kuota dan menimbulkan tagihan. Bagian berikut menjelaskan cara menghapus atau menonaktifkan resource ini.
Menghapus project
Cara termudah untuk menghilangkan penagihan adalah dengan menghapus project yang Anda buat untuk tutorial.
Untuk menghapus project:
- Di Konsol Google Cloud , buka halaman Manage resources.
- Pada daftar project, pilih project yang ingin Anda hapus, lalu klik Delete.
- Pada dialog, ketik project ID, lalu klik Shut down untuk menghapus project.
Menghapus cluster
- Untuk menghapus cluster Anda:
gcloud dataproc clusters delete --project=${PROJECT} trino-cluster \ --region=${REGION}
Menghapus bucket
- Untuk menghapus bucket Cloud Storage yang Anda buat di
Sebelum Anda memulai, termasuk file data yang disimpan di bucket:
gcloud storage rm gs://${BUCKET_NAME} --recursive