
Objectifs
Ce tutoriel vous explique comment :
- Créer un cluster Managed Service pour Apache Spark, en installant Apache HBase et Apache ZooKeeper sur le cluster
- Créer une table HBase à l'aide du shell HBase exécuté sur le nœud maître du cluster Managed Service pour Apache Spark
- Utilisez Cloud Shell pour envoyer un job Spark Java ou PySpark au service Managed Service pour Apache Spark, qui écrit des données dans la table HBase, puis les lit.
Coûts
Dans ce document, vous utilisez les composants facturables suivants de Google Cloud :
Pour obtenir une estimation des coûts en fonction de votre utilisation prévue, utilisez le simulateur de coût.
Avant de commencer
Si ce n'est pas déjà fait, créez un projet Google Cloud Platform.
- Connectez-vous à votre compte Google Cloud . Si vous débutez sur Google Cloud, créez un compte pour évaluer les performances de nos produits en conditions réelles. Les nouveaux clients bénéficient également de 300 $de crédits sans frais pour exécuter, tester et déployer des charges de travail.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc and Compute Engine APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc and Compute Engine APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.
Créer un cluster Managed Service pour Apache Spark
Exécutez la commande suivante dans un terminal de session Cloud Shell pour :
- Installez les composants HBase et ZooKeeper.
- Provisionnez trois nœuds de calcul (trois à cinq nœuds de calcul sont recommandés pour exécuter le code de ce tutoriel).
- Activez la passerelle des composants.
- Utiliser la version d'image 2.0
- Utilisez l'indicateur
--propertiespour ajouter la configuration et la bibliothèque HBase aux chemins de classe du pilote et de l'exécuteur Spark.
gcloud dataproc clusters create cluster-name \ --region=region \ --optional-components=HBASE,ZOOKEEPER \ --num-workers=3 \ --enable-component-gateway \ --image-version=2.0 \ --properties='spark:spark.driver.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*,spark:spark.executor.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*'
Vérifier l'installation du connecteur
À partir de la console Google Cloud ou d'un terminal de session Cloud Shell, connectez-vous en SSH au nœud maître du cluster Managed Service pour Apache Spark.
Vérifiez l'installation du connecteur Apache HBase Spark sur le nœud maître :
ls -l /usr/lib/spark/jars | grep hbase-spark
-rw-r--r-- 1 root root size date time hbase-spark-connector.version.jar
Laissez le terminal de session SSH ouvert pour :
- Créer une table HBase
- (Utilisateurs Java) Exécutez des commandes sur le nœud maître du cluster pour déterminer les versions des composants installés sur le cluster.
- Analysez votre table HBase après avoir exécuté le code.
Créer une table HBase
Exécutez les commandes listées dans cette section dans le terminal de la session SSH du nœud maître que vous avez ouvert à l'étape précédente.
Ouvrez l'interface système HBase :
hbase shell
Créez une table HBase "my-table" avec une famille de colonnes "cf" :
create 'my_table','cf'
- Pour confirmer la création de la table, dans la console Google Cloud , cliquez sur HBase dans les liens de la passerelle des composants de la consoleGoogle Cloud pour ouvrir l'interface utilisateur Apache HBase.
my-tableest listé dans la section Tables de la page Accueil.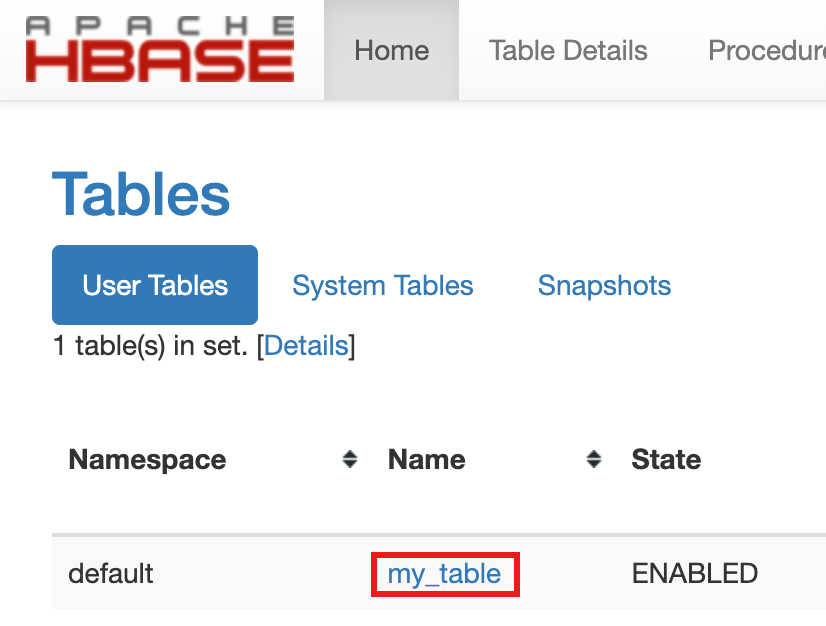
- Pour confirmer la création de la table, dans la console Google Cloud , cliquez sur HBase dans les liens de la passerelle des composants de la consoleGoogle Cloud pour ouvrir l'interface utilisateur Apache HBase.
Afficher le code Spark
Java
Python
Exécuter le code
Ouvrez un terminal de session Cloud Shell.
Clonez le dépôt GitHub GoogleCloudDataproc/cloud-dataproc dans le terminal de votre session Cloud Shell :
git clone https://github.com/GoogleCloudDataproc/cloud-dataproc.git
Accédez au répertoire
cloud-dataproc/spark-hbase:cd cloud-dataproc/spark-hbase
user-name@cloudshell:~/cloud-dataproc/spark-hbase (project-id)$
Envoyez le job Managed Service pour Apache Spark.
Java
- Définissez les versions des composants dans le fichier
pom.xml.- La page des versions 2.0.x de Managed Service pour Apache Spark liste les versions des composants Scala, Spark et HBase installés avec les quatre dernières versions mineures de l'image 2.0 et la plus récente.
- Pour trouver la version mineure de votre cluster de version d'image 2.0, cliquez sur le nom du cluster sur la page Clusters de la consoleGoogle Cloud pour ouvrir la page Détails du cluster, où la version de l'image du cluster est indiquée.
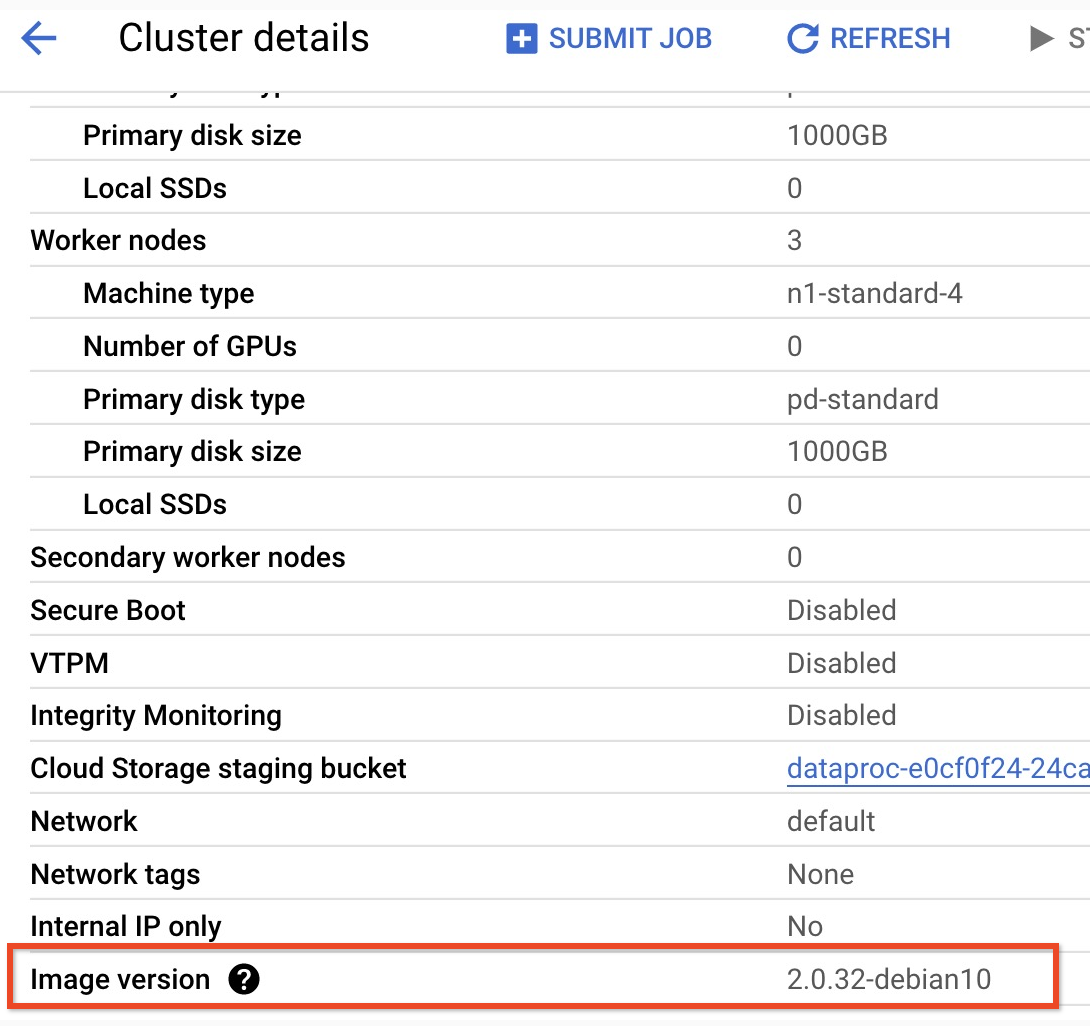
- Pour trouver la version mineure de votre cluster de version d'image 2.0, cliquez sur le nom du cluster sur la page Clusters de la consoleGoogle Cloud pour ouvrir la page Détails du cluster, où la version de l'image du cluster est indiquée.
- Vous pouvez également exécuter les commandes suivantes dans un terminal de session SSH à partir du nœud maître de votre cluster pour déterminer les versions des composants :
- Vérifiez la version de Scala :
scala -version
- Vérifiez la version de Spark (appuyez sur Ctrl+D pour quitter) :
spark-shell
- Vérifiez la version de HBase :
hbase version
- Identifiez les dépendances de version Spark, Scala et HBase dans le Maven
pom.xml:<properties> <scala.version>scala full version (for example, 2.12.14)</scala.version> <scala.main.version>scala main version (for example, 2.12)</scala.main.version> <spark.version>spark version (for example, 3.1.2)</spark.version> <hbase.client.version>hbase version (for example, 2.2.7)</hbase.client.version> <hbase-spark.version>1.0.0(the current Apache HBase Spark Connector version)> </properties>
hbase-spark.versioncorrespond à la version actuelle du connecteur Spark HBase. Ne modifiez pas ce numéro de version.
- Vérifiez la version de Scala :
- Modifiez le fichier
pom.xmldans l'éditeur Cloud Shell pour insérer les numéros de version corrects de Scala, Spark et HBase. Cliquez sur Ouvrir le terminal lorsque vous avez terminé de modifier le fichier pour revenir à la ligne de commande du terminal Cloud Shell.cloudshell edit .
- Passez à Java 8 dans Cloud Shell. Cette version du JDK est nécessaire pour compiler le code (vous pouvez ignorer les messages d'avertissement des plug-ins) :
sudo update-java-alternatives -s java-1.8.0-openjdk-amd64 && export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
- Vérifiez l'installation de Java 8 :
java -version
openjdk version "1.8..."
- La page des versions 2.0.x de Managed Service pour Apache Spark liste les versions des composants Scala, Spark et HBase installés avec les quatre dernières versions mineures de l'image 2.0 et la plus récente.
- Créez le fichier
jar:mvn clean package
.jarest placé dans le sous-répertoire/target(par exemple,target/spark-hbase-1.0-SNAPSHOT.jar). Envoyez le job.
gcloud dataproc jobs submit spark \ --class=hbase.SparkHBaseMain \ --jars=target/filename.jar \ --region=cluster-region \ --cluster=cluster-name
--jars: insérez le nom de votre fichier.jaraprès "target/" et avant ".jar".- Si vous n'avez pas défini les chemins d'accès aux classes HBase du pilote et de l'exécuteur Spark lorsque vous avez créé votre cluster, vous devez les définir à chaque envoi de job en incluant l'indicateur
‑‑propertiessuivant dans votre commande d'envoi de job :--properties='spark.driver.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*,spark.executor.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*'
Affichez la sortie de la table HBase dans la sortie du terminal de la session Cloud Shell :
Waiting for job output... ... +----+----+ | key|name| +----+----+ |key1| foo| |key2| bar| +----+----+
Python
Envoyez le job.
gcloud dataproc jobs submit pyspark scripts/pyspark-hbase.py \ --region=cluster-region \ --cluster=cluster-name
- Si vous n'avez pas défini les chemins d'accès aux classes HBase du pilote et de l'exécuteur Spark lorsque vous avez créé votre cluster, vous devez les définir à chaque envoi de job en incluant l'indicateur
‑‑propertiessuivant dans votre commande d'envoi de job :--properties='spark.driver.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*,spark.executor.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*'
- Si vous n'avez pas défini les chemins d'accès aux classes HBase du pilote et de l'exécuteur Spark lorsque vous avez créé votre cluster, vous devez les définir à chaque envoi de job en incluant l'indicateur
Affichez la sortie de la table HBase dans la sortie du terminal de la session Cloud Shell :
Waiting for job output... ... +----+----+ | key|name| +----+----+ |key1| foo| |key2| bar| +----+----+
Analyser la table HBase
Vous pouvez analyser le contenu de votre table HBase en exécutant les commandes suivantes dans le terminal de la session SSH du nœud maître que vous avez ouvert dans Vérifier l'installation du connecteur :
- Ouvrez l'interface système HBase :
hbase shell
- Analyser "my-table" :
scan 'my_table'
ROW COLUMN+CELL key1 column=cf:name, timestamp=1647364013561, value=foo key2 column=cf:name, timestamp=1647364012817, value=bar 2 row(s) Took 0.5009 seconds
Effectuer un nettoyage
Une fois le tutoriel terminé, vous pouvez procéder au nettoyage des ressources que vous avez créées afin qu'elles ne soient plus comptabilisées dans votre quota et qu'elles ne vous soient plus facturées. Dans les sections suivantes, nous allons voir comment supprimer ou désactiver ces ressources.
Supprimer le projet
Le moyen le plus simple d'empêcher la facturation est de supprimer le projet que vous avez créé pour ce tutoriel.
Pour supprimer le projet :
- Dans la console Google Cloud , accédez à la page Gérer les ressources.
- Dans la liste des projets, sélectionnez le projet que vous souhaitez supprimer, puis cliquez sur Supprimer.
- Dans la boîte de dialogue, saisissez l'ID du projet, puis cliquez sur Arrêter pour supprimer le projet.
Supprimer le cluster
- Pour supprimer le cluster :
gcloud dataproc clusters delete cluster-name \ --region=${REGION}