
Ziele
In dieser Anleitung wird Folgendes erläutert:
- Erstellen Sie einen Managed Service for Apache Spark-Cluster und installieren Sie Apache HBase und Apache ZooKeeper im Cluster.
- HBase-Tabelle mit der HBase-Shell erstellen, die auf dem Masterknoten des Managed Service for Apache Spark-Clusters ausgeführt wird
- Mit Cloud Shell einen Java- oder PySpark-Spark-Job an den Managed Service for Apache Spark senden, der Daten in die HBase-Tabelle schreibt und dann Daten daraus liest
Kosten
In diesem Dokument verwenden Sie die folgenden kostenpflichtigen Komponenten von Google Cloud:
Mit dem Preisrechner können Sie eine Kostenschätzung für Ihre voraussichtliche Nutzung vornehmen.
Hinweis
Erstellen Sie ein Google Cloud Platform-Projekt, falls dies noch nicht geschehen ist.
- Melden Sie sich in Ihrem Google Cloud -Konto an. Wenn Sie mit Google Cloudnoch nicht vertraut sind, erstellen Sie ein Konto, um die Leistungsfähigkeit unserer Produkte in der Praxis sehen und bewerten zu können. Neukunden erhalten außerdem ein Guthaben von 300 $, um Arbeitslasten auszuführen, zu testen und bereitzustellen.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc and Compute Engine APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc and Compute Engine APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.
Managed Service for Apache Spark-Cluster erstellen
Führen Sie den folgenden Befehl in einem Cloud Shell-Sitzungsterminal aus, um:
- Installieren Sie die Komponenten HBase und ZooKeeper.
- Stellen Sie drei Worker-Knoten bereit. Für das Ausführen des Codes in dieser Anleitung werden drei bis fünf Worker empfohlen.
- Aktivieren Sie das Component Gateway.
- Image-Version 2.0 verwenden
- Verwenden Sie das Flag
--properties, um die HBase-Konfiguration und die HBase-Bibliothek den Klassenpfaden von Spark-Treiber und -Executor hinzuzufügen.
gcloud dataproc clusters create cluster-name \ --region=region \ --optional-components=HBASE,ZOOKEEPER \ --num-workers=3 \ --enable-component-gateway \ --image-version=2.0 \ --properties='spark:spark.driver.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*,spark:spark.executor.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*'
Connector-Installation prüfen
Prüfen Sie die Installation des Apache HBase Spark-Connectors auf dem Masterknoten:
ls -l /usr/lib/spark/jars | grep hbase-spark
-rw-r--r-- 1 root root size date time hbase-spark-connector.version.jar
Lassen Sie das Terminal der SSH-Sitzung geöffnet, um:
- HBase-Tabelle erstellen
- (Java-Nutzer): Befehle auf dem Masterknoten des Clusters ausführen, um die Versionen der auf dem Cluster installierten Komponenten zu ermitteln
- HBase-Tabelle scannen, nachdem Sie den Code ausgeführt haben
HBase-Tabelle erstellen
Führen Sie die in diesem Abschnitt aufgeführten Befehle im SSH-Sitzungsterminal des Masterknotens aus, das Sie im vorherigen Schritt geöffnet haben.
HBase-Shell öffnen:
hbase shell
Erstellen Sie eine HBase-Tabelle namens „my-table“ mit der Spaltenfamilie „cf“:
create 'my_table','cf'
- Klicken Sie in der Google Cloud Console in den Google Cloud Links zum Component Gateway in der Console auf HBase, um die Apache HBase-Benutzeroberfläche zu öffnen und die Tabellenerstellung zu bestätigen.
my-tablewird auf der Startseite im Bereich Tabellen aufgeführt.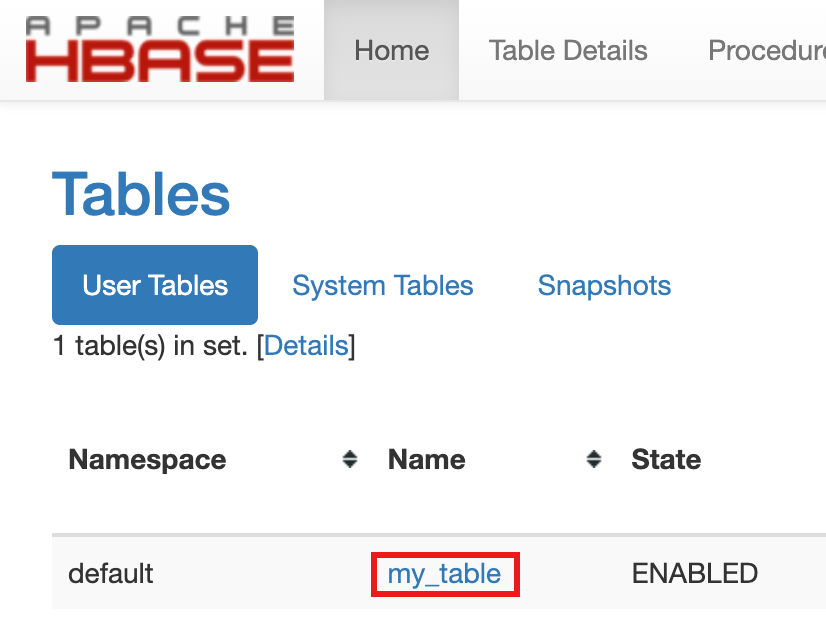
- Klicken Sie in der Google Cloud Console in den Google Cloud Links zum Component Gateway in der Console auf HBase, um die Apache HBase-Benutzeroberfläche zu öffnen und die Tabellenerstellung zu bestätigen.
Spark-Code ansehen
Java
Python
Code ausführen
Öffnen Sie ein Terminal für eine Cloud Shell-Sitzung.
Klonen Sie das GitHub-Repository GoogleCloudDataproc/cloud-dataproc in das Terminal Ihrer Cloud Shell-Sitzung:
git clone https://github.com/GoogleCloudDataproc/cloud-dataproc.git
Wechseln Sie in das Verzeichnis
cloud-dataproc/spark-hbase:cd cloud-dataproc/spark-hbase
user-name@cloudshell:~/cloud-dataproc/spark-hbase (project-id)$
Senden Sie den Managed Service for Apache Spark-Job.
Java
- Legen Sie die Komponentenversionen in der Datei
pom.xmlfest.- Auf der Seite 2.0.x-Releaseversionen für Managed Service for Apache Spark sind die Scala-, Spark- und HBase-Komponentenversionen aufgeführt, die mit den neuesten und den letzten vier untergeordneten Versionen des Image 2.0 installiert wurden.
- Wenn Sie die untergeordnete Version Ihres Clusters mit Imageversion 2.0 aufrufen möchten, klicken Sie in derGoogle Cloud -Konsole auf der Seite Cluster auf den Clusternamen, um die Seite Clusterdetails zu öffnen. Dort wird die Imageversion des Clusters aufgeführt.
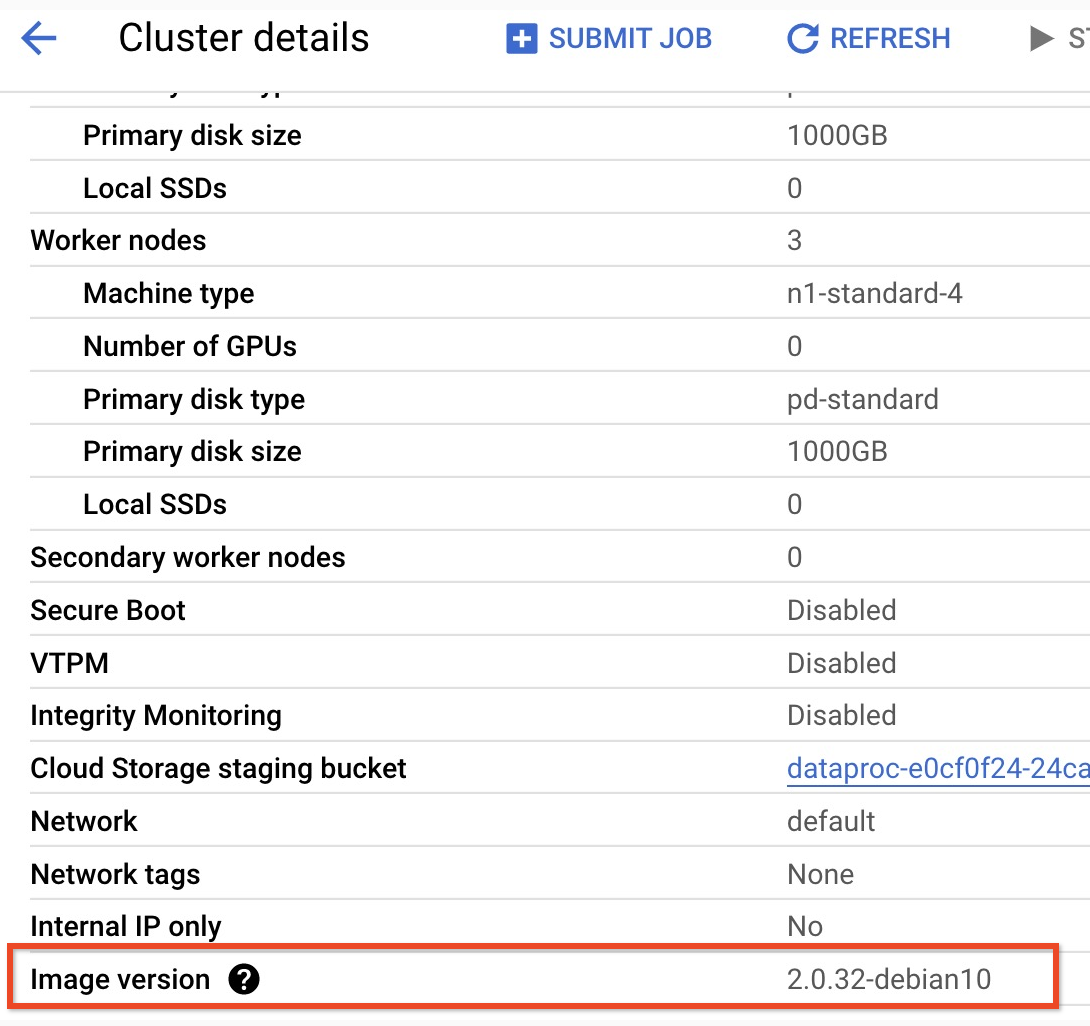
- Wenn Sie die untergeordnete Version Ihres Clusters mit Imageversion 2.0 aufrufen möchten, klicken Sie in derGoogle Cloud -Konsole auf der Seite Cluster auf den Clusternamen, um die Seite Clusterdetails zu öffnen. Dort wird die Imageversion des Clusters aufgeführt.
- Alternativ können Sie die folgenden Befehle in einem SSH-Sitzungsterminal vom Masterknoten Ihres Clusters aus ausführen, um die Komponentenversionen zu ermitteln:
- Scala-Version prüfen:
scala -version
- Spark-Version prüfen (mit Strg+D beenden):
spark-shell
- HBase-Version prüfen:
hbase version
- Ermitteln Sie die Versionsabhängigkeiten von Spark, Scala und HBase in der Maven-Datei
pom.xml:<properties> <scala.version>scala full version (for example, 2.12.14)</scala.version> <scala.main.version>scala main version (for example, 2.12)</scala.main.version> <spark.version>spark version (for example, 3.1.2)</spark.version> <hbase.client.version>hbase version (for example, 2.2.7)</hbase.client.version> <hbase-spark.version>1.0.0(the current Apache HBase Spark Connector version)> </properties>
hbase-spark.versionist die aktuelle Version des Spark HBase-Connectors. Lassen Sie diese Versionsnummer unverändert.
- Scala-Version prüfen:
- Bearbeiten Sie die Datei
pom.xmlim Cloud Shell-Editor, um die richtigen Versionsnummern für Scala, Spark und HBase einzufügen. Klicken Sie nach Abschluss der Bearbeitung auf Terminal öffnen, um zur Befehlszeile des Cloud Shell-Terminals zurückzukehren.cloudshell edit .
- Wechseln Sie in Cloud Shell zu Java 8. Diese JDK-Version ist zum Erstellen des Codes erforderlich. Sie können alle Plug-in-Warnmeldungen ignorieren:
sudo update-java-alternatives -s java-1.8.0-openjdk-amd64 && export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
- Java 8-Installation prüfen:
java -version
openjdk version "1.8..."
- Auf der Seite 2.0.x-Releaseversionen für Managed Service for Apache Spark sind die Scala-, Spark- und HBase-Komponentenversionen aufgeführt, die mit den neuesten und den letzten vier untergeordneten Versionen des Image 2.0 installiert wurden.
- Erstellen Sie die Datei
jar:mvn clean package
.jarwird im Unterverzeichnis/targetabgelegt (z. B.target/spark-hbase-1.0-SNAPSHOT.jar). Senden Sie den Job.
gcloud dataproc jobs submit spark \ --class=hbase.SparkHBaseMain \ --jars=target/filename.jar \ --region=cluster-region \ --cluster=cluster-name
--jars: Fügen Sie den Namen Ihrer.jar-Datei nach „target/“ und vor „.jar“ ein.- Wenn Sie die HBase-Klassenpfade für Spark-Treiber und -Executor beim Erstellen des Clusters nicht festgelegt haben, müssen Sie sie bei jeder Jobübergabe festlegen, indem Sie das folgende
‑‑properties-Flag in den Befehl zum Übergeben des Jobs einfügen:--properties='spark.driver.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*,spark.executor.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*'
HBase-Tabellenausgabe in der Terminalausgabe der Cloud Shell-Sitzung ansehen:
Waiting for job output... ... +----+----+ | key|name| +----+----+ |key1| foo| |key2| bar| +----+----+
Python
Senden Sie den Job.
gcloud dataproc jobs submit pyspark scripts/pyspark-hbase.py \ --region=cluster-region \ --cluster=cluster-name
- Wenn Sie die HBase-Klassenpfade für Spark-Treiber und -Executor beim Erstellen des Clusters nicht festgelegt haben, müssen Sie sie bei jeder Jobübergabe festlegen, indem Sie das folgende
‑‑properties-Flag in den Befehl zum Übergeben des Jobs einfügen:--properties='spark.driver.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*,spark.executor.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*'
- Wenn Sie die HBase-Klassenpfade für Spark-Treiber und -Executor beim Erstellen des Clusters nicht festgelegt haben, müssen Sie sie bei jeder Jobübergabe festlegen, indem Sie das folgende
HBase-Tabellenausgabe in der Terminalausgabe der Cloud Shell-Sitzung ansehen:
Waiting for job output... ... +----+----+ | key|name| +----+----+ |key1| foo| |key2| bar| +----+----+
HBase-Tabelle scannen
Sie können den Inhalt Ihrer HBase-Tabelle scannen, indem Sie die folgenden Befehle im Terminal der SSH-Sitzung des Masterknotens ausführen, die Sie in Installation des Connectors bestätigen geöffnet haben:
- HBase-Shell öffnen:
hbase shell
- Tabelle „my-table“ scannen:
scan 'my_table'
ROW COLUMN+CELL key1 column=cf:name, timestamp=1647364013561, value=foo key2 column=cf:name, timestamp=1647364012817, value=bar 2 row(s) Took 0.5009 seconds
Bereinigen
Nachdem Sie die Anleitung abgeschlossen haben, können Sie die erstellten Ressourcen bereinigen, damit sie keine Kontingente mehr nutzen und keine Gebühren mehr anfallen. In den folgenden Abschnitten erfahren Sie, wie Sie diese Ressourcen löschen oder deaktivieren.
Projekt löschen
Am einfachsten vermeiden Sie weitere Kosten durch Löschen des für die Anleitung erstellten Projekts.
So löschen Sie das Projekt:
- Wechseln Sie in der Google Cloud -Console zur Seite Ressourcen verwalten.
- Wählen Sie in der Projektliste das Projekt aus, das Sie löschen möchten, und klicken Sie dann auf Löschen.
- Geben Sie im Dialogfeld die Projekt-ID ein und klicken Sie auf Shut down (Beenden), um das Projekt zu löschen.
Cluster löschen
- So löschen Sie den Cluster:
gcloud dataproc clusters delete cluster-name \ --region=${REGION}