
Objetivos
Neste tutorial, mostramos como instalar o componente Jupyter do Serviço Gerenciado para Apache Spark em um novo cluster e, em seguida, se conectar à UI do notebook Jupyter em execução no cluster a partir do navegador local usando o gateway de componentesdo Serviço Gerenciado para Apache Spark.
Custos
Neste documento, você usará os seguintes componentes faturáveis do Google Cloud:
Para gerar uma estimativa de custo baseada na projeção de uso,
use a calculadora de preços.
Antes de começar
Se ainda não tiver feito isso, crie um Google Cloud projeto e um bucket doCloud Storage.
Configurar o projeto
- Faça login na sua Google Cloud conta do. Se você não conhece o Google Cloud, crie uma conta para avaliar a performance dos nossos produtos em cenários reais. Clientes novos também recebem US $300 em créditos para executar, testar e implantar cargas de trabalho.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc, Compute Engine, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the
serviceusage.services.enablepermission. If you created the project, then you likely already have this permission through the Owner role (roles/owner). Otherwise, you can get this permission through the Service Usage Admin role (roles/serviceusage.serviceUsageAdmin). Learn how to grant roles.-
Instale a Google Cloud CLI.
-
Ao usar um provedor de identidade (IdP) externo, primeiro faça login na CLI gcloud com sua identidade federada.
-
Para inicializar a CLI gcloud, execute o seguinte comando:
gcloud init -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc, Compute Engine, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the
serviceusage.services.enablepermission. If you created the project, then you likely already have this permission through the Owner role (roles/owner). Otherwise, you can get this permission through the Service Usage Admin role (roles/serviceusage.serviceUsageAdmin). Learn how to grant roles.-
Instale a Google Cloud CLI.
-
Ao usar um provedor de identidade (IdP) externo, primeiro faça login na CLI gcloud com sua identidade federada.
-
Para inicializar a CLI gcloud, execute o seguinte comando:
gcloud init
Como criar um bucket do Cloud Storage no projeto para armazenar todos os notebooks criados neste tutorial.
- No Google Cloud console, acesse a página Buckets do Cloud Storage.
- Clique em Criar.
- Na página Criar um bucket, insira as informações do seu bucket. Para ir à próxima
etapa, clique em Continuar.
-
Na seção Começar, faça o seguinte:
- Insira um nome globalmente exclusivo que atenda aos requisitos de nome de bucket.
- Para adicionar um
rótulo de bucket,
abra a seção Rótulos (),
clique em add_box
Adicionar rótulo e especifique uma
keye umvaluepara o rótulo.
-
Na seção Escolha onde armazenar seus dados, faça o seguinte:
- Selecione um tipo de local.
- Escolha um local em que os dados do bucket serão armazenados permanentemente no menu suspenso Tipo de local.
- Se você selecionar o tipo de local birregional, também poderá ativar a replicação turbo usando a caixa de seleção relevante.
- Para configurar a replicação entre buckets, selecione
Adicionar replicação entre buckets usando o Serviço de transferência do Cloud Storage e
siga estas etapas:
Configurar a replicação entre buckets
- No menu Bucket, selecione um bucket.
Na seção Configurações de replicação, clique em Configurar para definir as configurações do job de replicação.
O painel Configurar a replicação entre buckets é exibido.
- Para filtrar objetos a serem replicados por prefixo de nome de objeto, digite um prefixo que você quer incluir ou excluir objetos e clique em Adicionar um prefixo.
- Para definir uma classe de armazenamento para os objetos replicados, selecione uma classe de armazenamento no menu Classe de armazenamento. Se você pular essa etapa, os objetos replicados vão usar a classe de armazenamento do bucket de destino por padrão.
- Clique em Concluído.
-
Na seção Escolha como armazenar seus dados, faça o seguinte:
- Selecione uma classe de armazenamento padrão para o bucket ou Classe automática para gerenciamento automático da classe de armazenamento dos dados do bucket.
- Para ativar o namespace hierárquico, na seção Otimizar o armazenamento para cargas de trabalho com uso intensivo de dados, selecione Ativar namespace hierárquico neste bucket.
- Na seção Escolha como controlar o acesso a objetos, selecione se o bucket aplica ou não a prevenção de acesso público, e selecione um método de controle de acesso para os objetos do bucket.
-
Na seção Escolha como proteger os dados de objetos, faça o
seguinte:
- Selecione qualquer uma das opções em Proteção de dados que você
quer definir para o bucket.
- Para ativar a exclusão reversível, clique na caixa de seleção Política de exclusão reversível (para recuperação de dados) e especifique o número de dias em que você quer reter objetos após a exclusão.
- Para definir o Controle de versão de objetos, clique na caixa de seleção Controle de versão de objetos (para controle de versão), e especifique o número máximo de versões por objeto e o número de dias após os quais as versões não atuais expiram.
- Para ativar a política de retenção em objetos e buckets, clique na caixa de seleção Retenção (para conformidade) e faça o seguinte:
- Para ativar o bloqueio de retenção de objetos, clique na caixa de seleção Ativar retenção de objetos.
- Para ativar o bloqueio de bucket, clique na caixa de seleção Definir política de retenção de bucket e escolha uma unidade e um período para o período de armazenamento.
- Para escolher como os dados dos objetos serão criptografados, abra a seção Criptografia de dados () e selecione um método de Criptografia de dados.
- Selecione qualquer uma das opções em Proteção de dados que você
quer definir para o bucket.
-
Na seção Começar, faça o seguinte:
- Clique em Criar. Seus blocos de notas serão armazenados no Cloud Storage em
gs://bucket-name/notebooks/jupyter.
Criar um cluster e instalar o componente Jupyter
Crie um cluster com o componente Jupyter instalado.
Abrir as IUs do Jupyter e do JupyterLab
Clique nos links de gateway de componente do Google Cloud console no Google Cloud console para abrir o notebook do Jupyter ou as IUs do JupyterLab em execução no cluster.
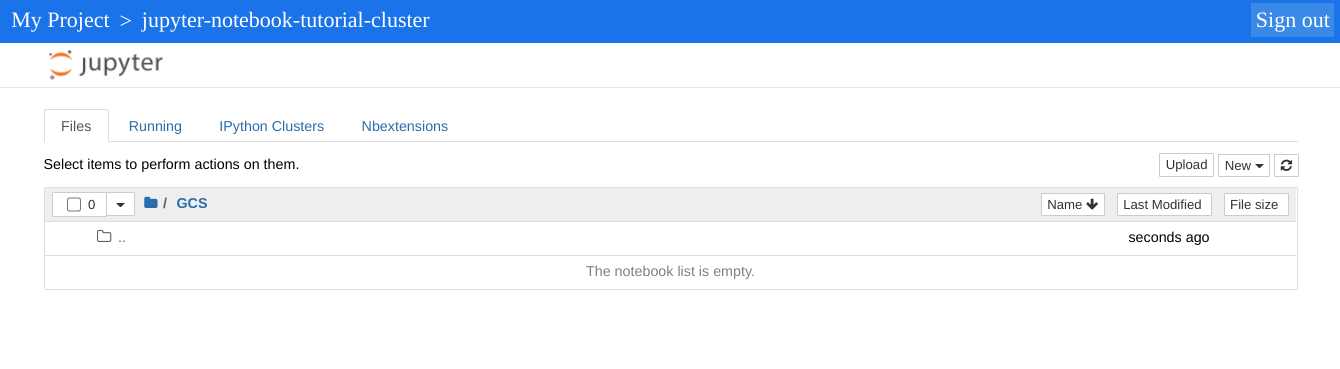
O diretório de nível superior exibido pela instância do Jupyter é um diretório virtual que permite ver o conteúdo do bucket do Cloud Storage ou do sistema de arquivos local. Escolha um dos locais clicando no link GCS do Cloud Storage ou em Disco local para o sistema de arquivos local do nó mestre no cluster.
- Clique no link GCS. A UI da Web do notebook Jupyter exibe
os notebooks armazenados no bucket do Cloud Storage, incluindo os
notebooks criados neste tutorial.
Limpar
Depois de concluir o tutorial, você pode limpar os recursos que criou para que eles parem de usar a cota e gerar cobranças. Nas seções a seguir, você aprenderá a excluir e desativar esses recursos.
Exclua o projeto
O jeito mais fácil de evitar cobranças é excluindo o projeto que você criou para o tutorial.
Para excluir o projeto:
- No Google Cloud console, acesse a página Gerenciar recursos.
- Na lista de projetos, selecione o projeto que você quer excluir e clique em Excluir.
- Na caixa de diálogo, digite o ID do projeto e clique em Encerrar para excluí-lo.
excluir o cluster
- Para excluir o cluster:
gcloud dataproc clusters delete cluster-name \ --region=${REGION}
Excluir o bucket
- Para excluir o bucket do Cloud Storage criado em
Antes de começar, siga a etapa 2, incluindo os notebooks
armazenados no bucket:
gcloud storage rm gs://${BUCKET_NAME} --recursive
A seguir
- Gerenciar o ciclo de vida da carga de trabalho de dados no VS Code usando o kit de agente de dados do Google Cloud
- Criar pipelines de dados com o kit de agente de dados
- Consulte o Guia de início rápido do Jupyter/IPython Notebook